什么是配准,为什么进行配准
通过阅读了几篇图像配准方面的论文和查找资料,对配准这一样工作的定义及意义,进行了简要的说明,特别是针对为什么要进行配准,而不是分别对两幅图像按照坐标点进行对照提取信息这一问题,进行的回答。但是对于毕业论文来说,大多数以公式的形式讲解配准的工作原理,所以以下总结有我个人的理解成分,不一定是正确的。
参考论文:
红外与可见光图像配准与融合算法研究 电子科技大学 龙勇志
基于共性特征的红外与可见光图像配准算法研究与应用 电子科技大学 李俊廷
面向红外与可见光图像配准的深度学习特征表征方法研究 西安电子科技大学 郑涵
基于生成对抗网络的非刚性医学图像配准 扬州大学 宋枭
可见光与SAR遥感图像配准关键技术研究 中国科学院大学 谢志华
正文部分:
一、什么是配准
图像配准旨在有效的将多幅具有相似场景内容的图像建立变换模型,估计其变换参数,利用平移,旋转,及尺度缩放等相关图像处理,从而达到像素(体素)空间上的精准对齐,实现多幅图像变换到同一空间坐标系中,使得图像中的共有场景信息达到最大程度匹配。
(配准是一项前端工作,并不能将两配准后图像直接使用,还需要融合等处理步骤,我们用来使用的图像,大多数是融合后的图像)
二、配准这项工作如果按作用目标的维数来分类,可以分为三类:
2D/2D , 2D/3D , 3D/3D .
1. 对于3D/3D的配准,以医学图像为代表,简述其意义:医学图像配准是指将两幅(或多幅)医学图像进行空间变换,使对应点在同一空间中坐标一致,医学图像采集过程中存在模态、时间以及主体姿态间的差异,这些差异必然会导致最终采集的医学图像的组织器官产生一定的形变,而这些形变图像之间的空间变换无法用简单的线性变换实现,因此需要更加复杂的非线性变换。
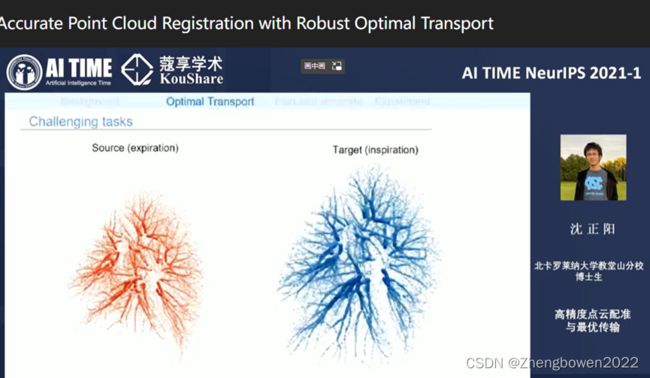

这两幅图是对于肺部的树状结构图,他们之间的形变不是简单的线性变换可以描述的,而我们如果想要观察对应部位,在两幅图像间是否发生了病变等问题,就需要来把他配准,融合,加以观察,而不能用之前 子超师兄 所提到的,让机器人利用自己的视觉系统 分别对与两幅图像中的点 或某个区域 进行对应观察, 观察完左图,观察右图,因为点,体现不了这种信息,截取固定区域观察,有复杂形变 ,是看不出来的,那样是达不到 发现病变 这一目的的。目前是可以让机器自己来通过发现特征的不同,查找病变,但是绝大多数情况下还是配准融合后,由专业的医生来看,很明显对于人来说 拿融合后的一幅图像观察,比拿融合前的两幅图像观察,要轻松和准确的多。
2. 对于2D/3D,我也选择用医学领域来举例说明(因为医学对于图像配准的使用确实特别广泛):
参考以前所阅读过的一篇文章:
论文题目:VoxelMorph: A Learning Framework forDeformable Medical Image Registration
《VoxelMorph一个可变性医学图像配准的学习架构》
在医学手术这一工作中,手术前期,需要在术前对于操作部位,或病变部位的组织,进行3D图像获取(具体手段可能是扫描),对这个高分辨率的3D图像进行标注,确认手术部位,以及各组织的位置,而在手术过程中,要对术中情况进行低分辨率2D照片获取,并于之前的3D图像进行配准,进行指导手术,那这项工作同样也是必须进行配准的,而不是对两幅图像进行点对点观察就可以做到。
3. 2D/2D,以我们目前所做的工作,红外与可见光图像配准来说:
2D/2D以可以延申到 单模态配准与多模态配准
单模态配准可以是在遥感图像方面,将不同时期不同角度拍摄的图像进行比对,观察地貌变化等等。
但多模态配准,不仅有不同时间,不同视角,还有不同传感器这一条件,传感器的不同,使得到的图像所包含的信息也不同,包括 分辨率,纹理信息,明暗程度都不同。
针对红外与可见光图像配准的问题具体来说,我们之所以要进行配准,是为了后续的工作,图像融合,图像融合是一种图像增强的方法,是理解图像和计算机视觉领域重要的技术,将多源数据进行融合,可以实现比单一传感器数据决策更精确,融合出来的图像也更符合人和机器的视觉特性,也有利于对图像进行目标识别和检测。(通俗的来讲,我们为什么不能把两幅图像放在那里,让机器人自己对照着坐标点看完左边,看右边,因为这样不仅不符合机器的视觉特性,也不符合人类的观察方式,图像形变一旦复杂,两幅图像的像素差异,纹理差异,明暗度差异一旦过大,机器看不懂,人也看不懂,没法进行后续的分析,所以配准是一项辅助工作,它本身的意义就是让图像更好的融合,融合后,可以识别,可以检测,可以可视化,但一切的前提是,先把他配准。)
以上,进行总结,配准工作涉及到多源问题、冗余信息、复杂模型结构等问题,处理工作量会变得很大很大,使用深度学习来干这个事情,可以做的更好,更精确,更符合机器处理图像的方式、更符合对人类进行可视化展示。所以 我们选择用神经网络来做。