Redis缓存雪崩、击穿、穿透、双写一致性、并发竞争、热点key重建优化、BigKey的优化 等解决方案
一. 缓存雪崩
1. 含义
同一时刻,大量的缓存同时过期失效。

2. 产生原因和后果
(1). 原因:由于开发人员经验不足或失误,大量热点缓存设置了统一的过期时间。
(2). 产生后果:恰逢秒杀高峰,缓存过期,瞬间海量的QPS(每秒查询次数)直接打到DB上,如果系统架构没有熔断机制,直接将导致系统全线崩溃。
3. 处理方案
(1). 设置不同的缓存失效时间,比如可以在缓存过期时间后面加个随机数,这样就避免同一时刻缓存大量过期失效。
setRedis(key,value,time + Math.random() * 9999);(2). 针对系统的一些热点数据, 可以设置缓存永不过期。 (或者定时更新)
(3). 设置二级缓存架构C1、C2,C1在前,C2在后,C1的缓存可以设置不同的过期时间,C2缓存与DB保持强一致性,实现数据同步。
PS:该二级缓存架构,同样也适用于解决下面的缓存击穿。
(4). 从架构层面来说:Redis做集群,将热点数据分配在不同的master上,减轻单点压力,同时master要对应多个slave,保证高可用; 系统架构要有快速熔断策略,减轻系统的压力。
二. 缓存击穿
1. 含义
某热点Key扛着大量的并发请求,当key失效的一瞬间,大量的QPS打到DB上,导致系统瘫痪。
PS:缓存击穿和缓存雪崩类似,击穿是某些热点key失效一瞬间大量请求打到DB上,缓存雪崩是指缓存面积失效导致大量请求打到DB上。所以二者的处理方案类似。
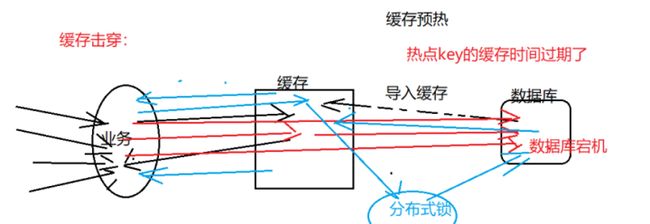
2. 处理方案
(1). 热点key过期时间后加随机数 。
(2). 热点key缓存永不过期(但是value需要开个子线程去更新)
(3). 二级缓存架构策略。(详见上面)
(4). 采用互斥锁更新,保证同一进程针对相同的数据不会并发打到DB上,从而减轻DB的压力。
(5). 缓存失效的时候随机sleep一个很短的时间,再次查询,如果失败则执行更新操作。
三. 缓存穿透
1. 含义
业务请求中数据缓存中没有,DB中也没有,导致类似请求直接跨过缓存,反复在DB中查询,与此同时缓存也不会得到更新。
举个例子:
商品表中的id是自增,并且以id为缓存的key,商品库存为value事先存在redis中。但此时过来的请求id均为负数,-1,-2,-3,缓存没有,DB中也没有,造成类似请求直接跨过缓存,打在DB上。
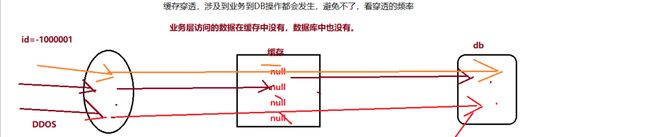
2.处理方案
(1). cache null策略:DB查询的结果即使为null,也给缓存的value设置为null,同时可以设置一个较短的过期时间,这样就避免不存在的数据跨过缓存直接打到DB上。
伪代码思路分享:
Public String get(String key) {
//从缓存中获取数据
String cacheValue = cache.get(key);
//缓存为空
if (StringUtils.isBlank(cacheValue)) {
// 从DB中获取
String storageValue = db.get(key);
cache.set(key, storageValue);
//如果存储数据为空,需要设置一个过期时间(300秒)
if (storageValue == null) {
cache.expire(key, 60 * 5);
}
return storageValue;
} else {
// 缓存非空
return cacheValue;
}
}剖析:
该方案不是并不是最佳方案,还是上面的例子,比如我用不同的id进行请求,例如 id=-1,-2,。。。。-10000,会导致缓存中存在大量的null,当数量达到一定值的时候,根据缓存淘汰策略,会导致正常的key失效。
(2). 布隆过滤器:
事先把存在的key都放到redis的BloomFilter 过滤器中,他的用途就是存在性检测,如果 BloomFilter 中不存在,那么数据一定不存在;如果 BloomFilter 中存在,实际数据也有可能会不存在。
剖析:
布隆过滤器可能会误判,当不影响整体,所以目前该方案是处理此类问题最佳方案。
更多C++后台开发技术点知识内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,音视频开发,Linux内核,TCP/IP,协程,DPDK多个高级知识点。
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
【文章福利】另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以点击领取
四. 双写一致性
1. 含义
双写一致性的含义就是:保证缓存中的数据 和 DB中数据一致。
2. 单线程下的解决方案
单线程下实际上就是指并发不大,或者说对 缓存和DB数据一致性要求不是很高的情况。
该问题就是经典的:缓存+数据库读写的模式,就是 Cache Aside Pattern
解决思路:
(1). 查询的时候,先查缓存,缓存中有数据,直接返回;缓存中没有数据,去查询数据库,然后更新缓存。
(2). 更新DB的后,删除缓存。
剖析:
(1). 为什么更新DB后,是删除缓存,而不是更新缓存呢?
举个例子,比如该DB更新的频率很高,比如1min中内更新100次把,如果更新缓存,缓存也对应了更新了100次,但缓存在这一分钟内根本没被调用,或者说该缓存10min才可能会被查询一次,那么频繁更新缓存是不是就产生了很多不必要的开销呢。
所以我们这里的思路是:用到缓存的时候,才去计算缓存。
(2). 该方案高并发场景下是否适用?
不适用
比如更新DB后,还有没有来得及删除缓存,别的请求就已经读取到缓存的数据了,此时读取的数据和DB中的实际的数据是不一致的。
3. 高并发下的解决方案
使用内存队列解决,把 读请求 和 写请求 都放到队列中,按顺序执行(即串行化的方式解决)。(要定义多个队列,不同的商品放到不同的队列中,换言之,同一个队列中只有一类商品)
剖析:
这种方案也有弊端,当并发量高了,队列容易阻塞,这个队列的位置,反而成了整个系统的瓶颈了,所以说100%完美的方案不存在,只有最适合的方案,没有最完美的方案。

五. 并发竞争
1. 含义
多个微服务系统要同时操作redis的同一个key,比如正确的顺序是 A→B→C,A执行的时候,突然网络抖动了一下,导致B,C先执行了,从而导致整个流程业务错误。
2. 解决方案
引入分布式锁(zookeeper 或 redis自身)
每个系统在操作之前,都要先通过 Zookeeper 获取分布式锁,确保同一时间,只能有一个系统实例在操作这个个 Key,别系统都不允许读和写。
六. 热点缓存key的重建优化
1. 背景
开发人员使用“缓存+过期时间”的策略既可以加速数据读写, 又保证数据的定期更新, 这种模式基本能够满足绝大部分需求。 但是有两个问题如果同时出现, 可能就会对应用造成致命的危害:
(1). 当前key是一个热点key(例如一个热门的娱乐新闻),并发量非常大。
(2). 重建缓存不能在短时间完成, 可能是一个复杂计算, 例如复杂的SQL、 多次IO、 多个依赖等。
在缓存失效的瞬间, 有大量线程来重建缓存, 造成后端负载加大, 甚至可能会让应用崩溃。
2. 解决方案
要解决这个问题主要就是要避免大量线程同时重建缓存。
我们可以利用互斥锁来解决,此方法只允许一个线程重建缓存, 其他线程等待重建缓存的线程执行完, 重新从缓存获取数据即可。
代码思路分享:
String get(String key) {
// 从Redis中获取数据
String value = redis.get(key);
// 如果value为空, 则开始重构缓存
if (value == null) {
// 只允许一个线程重建缓存, 使用nx, 并设置过期时间ex
String mutexKey = "mutext:key:" + key;
if (redis.set(mutexKey, "1", "ex 180", "nx")) {
// 从数据源获取数据
value = db.get(key);
// 回写Redis, 并设置过期时间
redis.setex(key, timeout, value);
// 删除key_mutex
redis.delete(mutexKey);
}
else {
//其它线程休息50ms,重写递归获取
Thread.sleep(50);
get(key);
}
}
return value;
}七. BigKey的危害及优化
1. 什么是BigKey
在Redis中,一个字符串最大512MB,一个二级数据结构(例如hash、list、set、zset)可以存储大约40亿个(2^32-1)个元素,但实际中如果下面两种情况,我就会认为它是bigkey。
(1). 字符串类型:它的big体现在单个value值很大,一般认为超过10KB就是bigkey。
(2). 非字符串类型:哈希、列表、集合、有序集合,它们的big体现在元素个数太多。
一般来说,string类型控制在10KB以内,hash、list、set、zset元素个数不要超过5000。反例:一个包含200万个元素的list。非字符串的bigkey,不要使用del删除,使用hscan、sscan、zscan方式渐进式删除,同时要注意防止bigkey过期时间自动删除问题(例如一个200万的zset设置1小时过期,会触发del操作,造成阻塞)
2. BigKey的危害
(1). 导致redis阻塞
(2). 网络拥塞
bigkey也就意味着每次获取要产生的网络流量较大,假设一个bigkey为1MB,客户端每秒访问量为1000,那么每秒产生1000MB的流量,对于普通的千兆网卡(按照字节算是128MB/s)的服务器来说简直是灭顶之灾,而且一般服务器会采用单机多实例的方式来部署,也就是说一个bigkey
可能会对其他实例也造成影响,其后果不堪设想。
(3). 过期删除
有个bigkey,它安分守己(只执行简单的命令,例如hget、lpop、zscore等),但它设置了过期时间,当它过期后,会被删除,如果没有使用Redis 4.0的过期异步删除(lazyfree-lazy-expire yes),就会存在阻塞Redis的可能性。
3. BigKey的产生
一般来说,bigkey的产生都是由于程序设计不当,或者对于数据规模预料不清楚造成的,来看几个例子:
(1) 社交类:粉丝列表,如果某些明星或者大v不精心设计下,必是bigkey。
(2) 统计类:例如按天存储某项功能或者网站的用户集合,除非没几个人用,否则必是bigkey。
(3) 缓存类:将数据从数据库load出来序列化放到Redis里,这个方式非常常用,但有两个地方需注意:第一,是不是有必要把所有字段都缓存;第二,有没有相关关联的数据,有的同学为了图方便把相关数据都存一个key下,产生bigkey。
4. BigKey的优化
(1). 拆
big list: list1、list2、...listN
big hash:可以将数据分段存储,比如一个大的key,假设存了1百万的用户数据,可以拆分成200个key,每个key下面存放5000个用户数据
(2). 合理采用数据结构
如果bigkey不可避免,也要思考一下要不要每次把所有元素都取出来(例如有时候仅仅需要hmget,而不是hgetall),删除也是一样,尽量使用优雅的方式来处理.
反例:
set user:1:name tom set user:1:age 19 set user:1:favor football
推荐hash存对象:
hmset user:1 name tom age 19 favor football
(3). 控制key的生命周期,redis不是垃圾桶。
建议使用expire设置过期时间(条件允许可以打散过期时间,防止集中过期)。
原文链接:第三节:Redis缓存雪崩、击穿、穿透、双写一致性、并发竞争、热点key重建优化、BigKey的优化 等解决方案