Redis数据持久化机制(备份恢复)、缓存淘汰策略、主从同步原理、常见规范与优化详解
一. 数据持久化
1. 含义
Redis 提供了 RDB 和 AOF 两种持久化方式,默认开启的是RDB,如果需要AOF,需要手动修改配置文件进行开启。
RDB:是一种对Redis存在内存中的数据周期性的持久化机制,将内存中的数据以快照的形式硬盘,实质上是fork了一个子进程在执行数据存储,采用的是二进制压缩的存储模式。
如图:
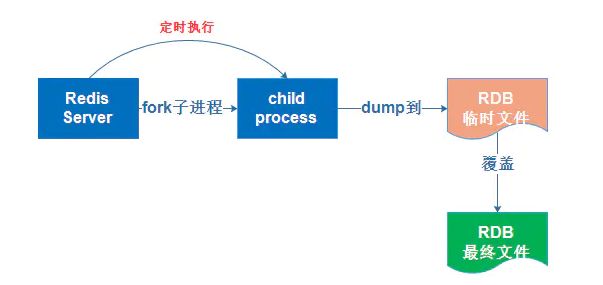
AOF:是以文本日志的形式记录Redis的每一个写入、删除请求(查询请求不处理),它是以追加的方式(append-only)写入,没有磁盘寻址的开销,所以写入速度非常快(类似mysql的binlog)。
如图:

2. 优缺点对比
(1). RDB优点
生成多个数据文件,每个文件代表某一时刻redis的数据,而且RDB是fork一个子进程做持久化,所以RDB对Redis性能影响非常小,而且他在数据恢复的时候也比AOF快。
(2). RDB缺点
A. RDB通常是每隔一段时间查看key变化数量从而决定是否持久化一次数据,比如5min分钟1次吧,如果这期间宕机或断电,丢失的就是这5min的数据了,而AOF最多丢失一秒。
B. RDB如果生成的快照文件非常大,客户端会卡顿 几毫秒或者几秒,恰逢当时是高并发期间,绝壁出问题!
(3). AOF优点
A. AOF通常设置1s通过后台线程去追加一次,所以最多丢失1s数据,数据的完整性比RDB要高。
B. AOF是appendonly追加的方式,少了磁盘寻址的开销,所以写入性能很高,文件也不易损坏。
C. 可以对数据误删进行紧急恢复。
(4). AOF缺点
A. 同样的数据,AOF文件要比RDB文件大的多。
B. 开启AOF存储后,整个Redis的QPS要下降,但依旧比关系型数据库要高。
3. 适用场景及如何选择
RDB适合做冷备,AOF适合做热备。
在生产环境中,通常是冷备和热备一起上,RDB中bgsave做全量持久化,AOF做增量持久化,在redis重启的时候,使用rdb持久化的文件重新构建内存,再使用aof恢复最近操作数据,从而实现完整的服务到重启之前的状态。
(单独用RDB你会丢失很多数据,你单独用AOF,你数据恢复没RDB来的快,所以在生产环境中,第一时间用RDB恢复,然后AOF做数据补全,冷备热备一起上,才是互联网时代一个高健壮性系统的王道。)

4. rdb持久化中save和bgsave的区别
save和 bgsave 两个命令都会调用 rdbSave 函数,但它们调用的方式各有不同:
(1). save 直接调用 rdbSave ,阻塞 Redis 主进程,直到保存完成为止,在主进程阻塞期间,服务器不能处理客户端的任何请求。
(2). bgsave 则 fork 出一个子进程,子进程负责调用 rdbSave ,并在保存完成之后向主进程发送信号,通知保存已完成,Redis 服务器在 bgsave 执行期间仍然可以继续处理客户端的请求。
(bgsave的本质就是 fork 和 cow,fork是指redis通过创建子进程来进行bgsave操作,cow指的是copy on write,子进程创建后,父子进程共享数据段,父进程继续提供读写服务,写进的页面数据会逐渐和子进程分离开来)
总结:save是阻塞方式的;bgsave是非阻塞方式的。

5. 相关代码配置
#一. RDB存储
#1. 下面配置为默认配置,默认就是开启的,在一定的间隔时间中,检测key的变化情况,然后持久化数据
save 900 1 #900s后至少1个key发生变化则进行存储
save 300 10 #300s后至少10个key发生变化则进行存储
save 60 10000 #60s后至少10000个key发生变化则进行存储
#2. rdb文件的存储路径(默认当前目录下,文件名为dump.rdb)
dbfilename dump.rdb
dir ./
#二. AOF存储
#1.默认是关闭的,日志记录的方式,可以记录每一条命令的操作。可以每一次命令操作后,持久化数据,启用的话通常使用每隔一秒持久化一次的策略
appendonly no(默认no) --> appendonly yes (开启aof)
# appendfsync always #每一次操作都进行持久化
appendfsync everysec #每隔一秒进行一次持久化
# appendfsync no # 不进行持久化
#2. aof文件路径 (默认为当前目录下,文件名为 appendonly.aof)
appendfilename "appendonly.aof"
dir ./ (同上)
#3. 控制触发自动重写机制频率
# auto-aof-rewrite-min-size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大
# auto-aof-rewrite-percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
#三. 混合持久化
#1. 开启混合持久化配置 (5.0版本默认就是yes)
aof-use-rdb-preamble yes
#2. rdb和aof自身的配置也都需要开启6. aof持久化文件详解
(1). aof文件长什么样?
通常我们配置aof持久化为everysec,即为每秒写一次,这里我们先把混合持久化关掉 【aof-use-rdb-preamble no】来进行演示。
演示步骤:先清空所有数据,然后把appendonly.aof文件删掉(需要重启一下),多次对name1和name2设置不同的值,如下:
#先清空所有数据,然后吧
flushdb
#对name1多次设置值
set name1 ypf1
set name1 ypf11
#对name2多次设置值
set name2 ypf2
set name2 ypf22
set name2 ypf222aof文件中的内容如下:每条set指令都会aof文件中追加记录。如下图:

剖析:
每条指令都会追加记录,但对于同一个key,实际上我们只需要最新值,比如name2,我们需要的是ypf222,前面的记录用处不大,而且很占空间,所以redis内部有aof重写机制(定期根据内存的最新数据生成aof文件),来处理这个问题。
更多C++后台开发技术点知识内容包括C/C++,Linux,Nginx,ZeroMQ,MySQL,Redis,MongoDB,ZK,流媒体,音视频开发,Linux内核,TCP/IP,协程,DPDK多个高级知识点。
C/C++Linux服务器开发高级架构师/C++后台开发架构师免费学习地址
【文章福利】另外还整理一些C++后台开发架构师 相关学习资料,面试题,教学视频,以及学习路线图,免费分享有需要的可以点击领取

(2). aof重写机制
A. 自动重写
AOF文件里可能有太多没用指令,所以AOF会定期根据内存的最新数据生成aof文件。
通过下面的配置,可以控制aof自动重写的频率
#3. 控制触发自动重写机制频率 # auto-aof-rewrite-min-size 64mb //aof文件至少要达到64M才会自动重写,文件太小恢复速度本来就很快,重写的意义不大 # auto-aof-rewrite-percentage 100 //aof文件自上一次重写后文件大小增长了100%则再次触发重写
B. 手动重写
运行指令【bgrewriteaof】,后台会fork一个子进程去重写,对于redis正常进程操作影响很小,下面演示一下手动重写后aof文件中的内容。

7. 混合持久化详解
(1). 概念
重启 Redis 时,我们很少使用 RDB来恢复内存状态,因为会丢失大量数据。我们通常使用 AOF 日志恢复,但是使用 AOF 日志性能相对 RDB来说要慢很多,这样在 Redis 实例很大的情况下,启动需要花费很长的时间。
Redis 4.0 为了解决这个问题,带来了一个新的持久化选项——混合持久化。
(2). 原理
如果开启了混合持久化,AOF在重写时,不再是单纯将内存数据转换为RESP命令写入AOF文件,而是将重写这一刻之前的内存做RDB快照处理(重写期间执行的指令和之后的指令仍然是转换成resp指令吸入aof文件),并且将RDB快照内容和增量的AOF修改内存数据的命令存在一起,都写入新的AOF文件,新的文件一开始不叫appendonly.aof,等到重写完新的AOF文件才会进行改名,会覆盖原有的AOF文件,完成新旧两个AOF文件的替换。
于是在 Redis 重启的时候,可以先加载 RDB 的内容,然后再重放增量 AOF 日志就可以完全替代之前的AOF 全量文件重放,因此重启效率大幅得到提升。
(3). 演示
A. 开启混合持久化机制 【aof-use-rdb-preamble yes】
B. 运行指令【bgrewriteaof】手动进行aof重写(前提内存中有内容),此时查看aof文件中的内容,类似乱码的东西,就是rdb快照处理。

C. 再任意执行几个set指令,然后查看aof文件中内容。

8. 数据备份恢复
(前言: 上面的代码配置RDB和AOF都是自动进行持久化存储的,下面我们进行介绍手动进行备份恢复)
(1). RDB模式
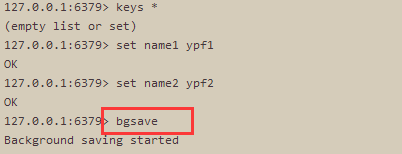
比如当没有达到RDB持久化的条件,而此时我又想把内存中的数据持久化到硬盘上,这个时候可以运行bgsave指令进行后台持久化。(save命令也可以,但会阻塞主线程)
(下面步骤在关闭aof存储的模式下进行,即appendonly no,rdb使用默认配置即可,为了演示效果,可以临时删除dump.rdb,实际是不需要的,数据会覆盖的)
A. 运行【 bgsave】 指令 ,默认配置下会在redis的根目录下生成一个名为 dump.rdb的数据文件。
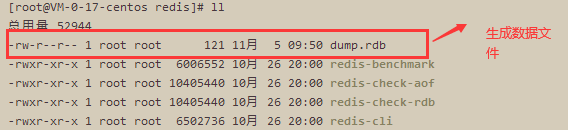
B. 可以通过指令 【config get dir】获取数据存放的路径,【config get dbfilename】获取生成的rdb文件名称。

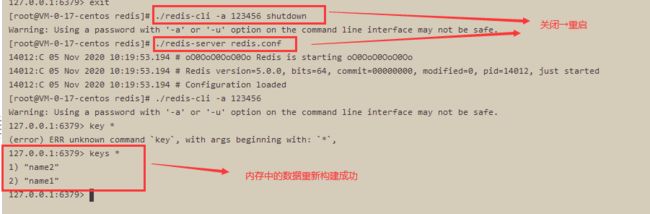
C. 关闭服务【./redis-cli -a 123456 shutdown】,重新启动redis服务【./redis-server redis.conf】,将自动初始化rdb中的内容到内存(因为默认数据存储目录和启动目录是一致的)。

(2). AOF模式
(下面步骤在开启aof存储的模式下进行,即appendonly yes,关闭rdb存储,即 3个save全部注释掉,然后 sava "" )
save ""
#save 900 1
#save 300 10
#save 60 10000A. 运行【 bgrewriteaof】 指令 ,默认配置下会在redis的根目录下生成一个名为 appendonly.aof的数据文件。
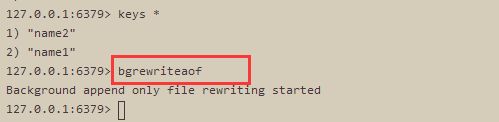
B. 关闭服务【./redis-cli -a 123456 shutdown】,重新启动redis服务【./redis-server redis.conf】,将自动初始化aof中的内容到内存(因为默认数据存储目录和启动目录是一致的)。
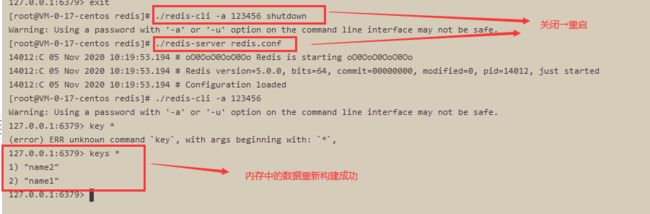
(3). RDB和AOF模式同时开启
(默认redis里没有任何数据)
A. 先写入 name1 和 name2,然后运行【bgsave】,然后写入name3,运行【bgrewriteaof】指令,然后写入name4
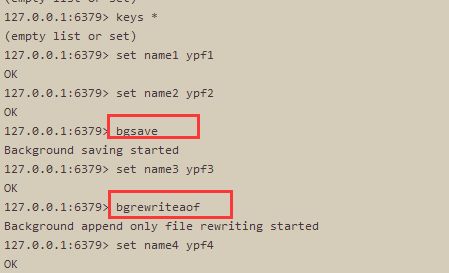
B. 关闭服务【./redis-cli -a 123456 shutdown】,重新启动redis服务【./redis-server redis.conf】,发现内存中的数据为 name1-4都有,说明同时开启的时候,初始化内存数据的时候,使用的是AOF模式。
PS:
1. 只开启rdb, 重启的时候加载rdb文件进行恢复数据。
2. 只开启aof,重启的时候加载aof文件进行恢复数据。
3. 同时开始rdb和aof,重启的时候依旧是使用aof文件进行恢复数据。
二. 缓存淘汰策略
1. 背景
Redis对于过期键有三种清除策略:
(1). 被动删除:设置一个key过期时间后,当该key过期了,不会马上从内存中删除,当对其 读/写一个已经过期的key时,会触发惰性删除策略,直接删除掉这个过期key .
(2). 主动删除:由于惰性删除策略无法保证冷数据被及时删掉,所以Redis会定期主动淘汰一批已过期的key .
(3). 缓存淘汰策略:当前已用内存超过maxmemory限定时,触发主动清理策略当REDIS运行在主从模式时,只有主结点才会执行被动和主动这两种过期删除策略,然后把删除操作”del key”同步到从结点。(大量的key定期没有删除,而且也没惰性删除(查询的时候删除),这个时候要适用缓存淘汰策略了。)
2. 淘汰策略种类
当前已用内存超过redis.cnf配置文件中 # maxmemory
redis5.0相关配置如下:
############################## MEMORY MANAGEMENT ################################
# Set a memory usage limit to the specified amount of bytes.
# When the memory limit is reached Redis will try to remove keys
# according to the eviction policy selected (see maxmemory-policy).
#
# If Redis can't remove keys according to the policy, or if the policy is
# set to 'noeviction', Redis will start to reply with errors to commands
# that would use more memory, like SET, LPUSH, and so on, and will continue
# to reply to read-only commands like GET.
#
# This option is usually useful when using Redis as an LRU or LFU cache, or to
# set a hard memory limit for an instance (using the 'noeviction' policy).
#
# WARNING: If you have replicas attached to an instance with maxmemory on,
# the size of the output buffers needed to feed the replicas are subtracted
# from the used memory count, so that network problems / resyncs will
# not trigger a loop where keys are evicted, and in turn the output
# buffer of replicas is full with DELs of keys evicted triggering the deletion
# of more keys, and so forth until the database is completely emptied.
#
# In short... if you have replicas attached it is suggested that you set a lower
# limit for maxmemory so that there is some free RAM on the system for replica
# output buffers (but this is not needed if the policy is 'noeviction').
#
# maxmemory
# MAXMEMORY POLICY: how Redis will select what to remove when maxmemory
# is reached. You can select among five behaviors:
#
# volatile-lru -> Evict using approximated LRU among the keys with an expire set.
# allkeys-lru -> Evict any key using approximated LRU.
# volatile-lfu -> Evict using approximated LFU among the keys with an expire set.
# allkeys-lfu -> Evict any key using approximated LFU.
# volatile-random -> Remove a random key among the ones with an expire set.
# allkeys-random -> Remove a random key, any key.
# volatile-ttl -> Remove the key with the nearest expire time (minor TTL)
# noeviction -> Don't evict anything, just return an error on write operations.
#
# LRU means Least Recently Used
# LFU means Least Frequently Used
#
# Both LRU, LFU and volatile-ttl are implemented using approximated
# randomized algorithms.
#
# Note: with any of the above policies, Redis will return an error on write
# operations, when there are no suitable keys for eviction.
#
# At the date of writing these commands are: set setnx setex append
# incr decr rpush lpush rpushx lpushx linsert lset rpoplpush sadd
# sinter sinterstore sunion sunionstore sdiff sdiffstore zadd zincrby
# zunionstore zinterstore hset hsetnx hmset hincrby incrby decrby
# getset mset msetnx exec sort
#
# The default is:
#
# maxmemory-policy noeviction
# LRU, LFU and minimal TTL algorithms are not precise algorithms but approximated
# algorithms (in order to save memory), so you can tune it for speed or
# accuracy. For default Redis will check five keys and pick the one that was
# used less recently, you can change the sample size using the following
# configuration directive.
#
# The default of 5 produces good enough results. 10 Approximates very closely
# true LRU but costs more CPU. 3 is faster but not very accurate.
#
# maxmemory-samples 5
# Starting from Redis 5, by default a replica will ignore its maxmemory setting
# (unless it is promoted to master after a failover or manually). It means
# that the eviction of keys will be just handled by the master, sending the
# DEL commands to the replica as keys evict in the master side.
#
# This behavior ensures that masters and replicas stay consistent, and is usually
# what you want, however if your replica is writable, or you want the replica to have
# a different memory setting, and you are sure all the writes performed to the
# replica are idempotent, then you may change this default (but be sure to understand
# what you are doing).
#
# Note that since the replica by default does not evict, it may end using more
# memory than the one set via maxmemory (there are certain buffers that may
# be larger on the replica, or data structures may sometimes take more memory and so
# forth). So make sure you monitor your replicas and make sure they have enough
# memory to never hit a real out-of-memory condition before the master hits
# the configured maxmemory setting.
#
# replica-ignore-maxmemory yes 配置说明:
(1). LRU means Least Recently Used: 最近最少使用
(2). LFU means Least Frequently Used: 最不经常使用(表示按最近的访问频率进行淘汰,它比 LRU 更加精准地表示了一个 key 被访问的热度)
volatile-lru:超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
allkeys-lru:超过最大内存后,在过期键中使用lru算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
volatile-lfu: 超过最大内存后,在过期键中使用lfu算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
allkeys-lfu : 超过最大内存后,在过期键中使用lfu算法进行key的剔除,保证不过期数据不被删除,但是可能会出现OOM问题。
allkeys-random:随机删除所有键,直到腾出足够空间为止。
volatile-random: 随机删除过期键,直到腾出足够空间为止。
volatile-ttl:根据键值对象的ttl属性,删除最近将要过期数据,如果没有,回退到noeviction策略。
noeviction:不会剔除任何数据,拒绝所有写入操作并返回客户端错误信息"(error)OOM command not allowed when used memory",此时Redis只响应读操作。PS: 位于上述配置文件的位置,默认配置的是noeviction
# maxmemory-policy noeviction三. 主从同步原理
1. 主从的背景
这里的主从架构是redis的第一代架构模式,即一个master对应多个slave,它的出现主要是为了实现读写分离,让主节点之负责写,从节点负责读的请求,从而分摊压力。
后续的架构,无论是哨兵还是cluster,都是在主从架构的基础上进行改进和升级的。
2. 主从同步原理
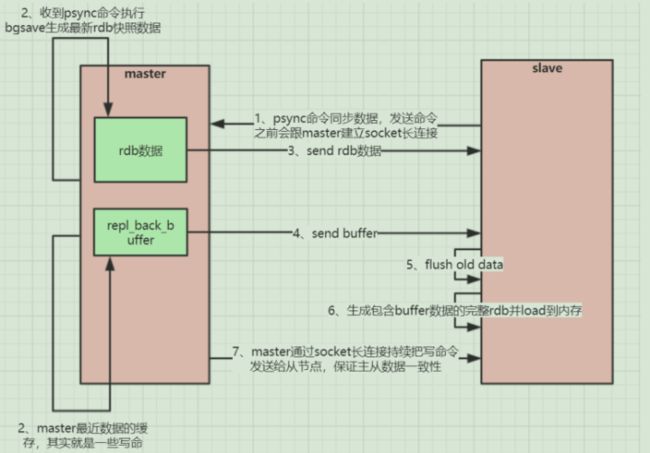
(1). 全量复制
A. slave第一次启动时,连接master,发送PSYNC命令,
B. master收到psync命令后,会执行bgsave命令进行全量复制生成rdb快照文件,持久化期间,所有写命令都被缓存在内存中。
C. master bgsave执行完毕,向slave发送rdb文件
D. slave收到rdb文件,删掉之前所有旧数据,开始载入rdb文件
E. rdb文件同步结束之后,master将之前缓冲区中命令发送给slave。
F. 此后 master 每执行一个写命令,就向slave发送相同的写命令。
注:
(1). 当master与slave之间的连接由于某些原因而断开时,slave能够自动重连Master,如果master收到了多个slave并发连接请求,它只会进行一次持久化,而不是一个连接一次,然后再把这一份持久化的数据发送给多个并发连接的slave。
(2). 当master和slave断开重连后,一般都会对整份数据进行复制。但从redis2.8版本开始,master和slave断开重连后支持部分复制。
流程图如下:
(2). 增量复制(部分复制)
如果出现网络闪断或者命令丢失等异常情况,从节点之前保存了自身已复制的偏移量和主节点的运行ID,主节点会根据偏移量把复制积压缓冲区里的数据发送给从节点,保证主从复制进入正常状态。
详细说明:
从2.8版本开始,slave与master能够在网络连接断开重连后只进行部分数据复制。
master会在其内存中创建一个复制数据用的缓存队列,缓存最近一段时间的数据,master和它所有的slave都维护了复制的数据下标offset(偏移量)和master的进程id,因此,当网络连接断开后,slave会请求master继续进行未完成的复制,从所记录的数据下标开始。如果master进程id变化了,或者从节点数据下标offset太旧,已经不在master的缓存队列里了,那么将会进行一次全量数据的复制。
流程图如下:
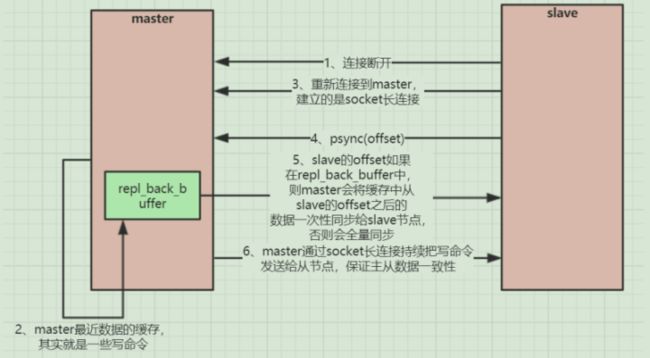
3. 同步过程中宕机怎么办?
(1). 会自动重连的,自动补充缺少的数据。
(2). 如同上面主从同步原理所说的,master生成rdb文件期间,所有的写命令都被缓存在内存中,这些命令并不会丢失。
四. 常见规范和优化
1. key的命名设计
(1). 可读性和可管理性
以业务名(或数据库名)为前缀(防止key冲突),用冒号分隔,比如业务名:表名:id
trade:order:1
(2). 简洁性
保证语义的前提下,控制key的长度,当key较多时,内存占用也不容忽视,例如:
user:{uid}:friends:messages:{mid} 简化为 u:{uid}:fr:m:{mid}
(3). 不要包含特殊字符
反例:包含空格、换行、单双引号以及其他转义字符
2. 命令的使用
(1).O(N)命令关注N的数量
例如hgetall、lrange、smembers、zrange、sinter等并非不能使用,但是需要明确N的值。有遍历的需求可以使用hscan、sscan、zscan代替。
(2).禁用命令
禁止线上使用keys、flushall、flushdb等,通过redis的rename机制禁掉命令,或者使用scan的方式渐进式处理。
(3).合理使用select
redis的多数据库较弱,使用数字进行区分,很多客户端支持较差,同时多业务用多数据库实际还是单线程处理,会有干扰。
(4).使用批量操作提高效率
原生命令:例如mget、mset。
非原生命令:可以使用pipeline提高效率。
注:
1. 原生是原子操作,pipeline是非原子操作。
2. pipeline可以打包不同的命令,原生做不到
3. pipeline需要客户端和服务端同时支持。
(5). Redis事务功能较弱,不建议过多使用,可以用lua替代
3. 线程池最大连接数设计

原文链接:第四节:Redis数据持久化机制(备份恢复)、缓存淘汰策略、主从同步原理、常见规范与优化详解 - Yaopengfei - 博客园