sklearn中的特征选择feature_selection
特征选择
概念:就是从所有的特征中,选择出有意义,对模型有帮助的特征,以避免必须将所有特征都导入模型去训练的情况。
特征选择常用的方法有:过滤法,嵌入法,包装法,和降维算法
过滤法
sklearn.feature_selection.VarianceThreshold 方差阈值法
sklearn.feature_selection.VarianceThreshold 方差阈值法,用于特征选择,过滤器法的一种,去掉那些方差没有达到阈值的特征。默认情况下,删除零方差的特征。
若数据维度较高,并且需要剔除一些特征,那么依据每个特征所携带的信息熵进行过滤是一种简便快速的特征筛选方法。
from sklearn.feature_selection import VarianceThreshold
from sklearn.datasets import load_iris
iris = load_iris()
print(iris.data[0:5])
#方差选择法,返回值为特征选择后的数据 #参数threshold为方差的阈值
selector = VarianceThreshold(threshold=1).fit(iris.data, iris.target)
data = selector.transform(iris.data)
print(data[0:5])
print(selector.variances_)
from sklearn.feature_selection import VarianceThreshold
import numpy as np
X = [[0, 2, 0, 3], [0, 1, 4, 3], [0, 1, 1, 3]]
X=np.array(X)
print('原始数据',X.shape)
selector = VarianceThreshold()
data=selector.fit_transform(X)
print('过滤后的数据',data.shape)
print('方差',selector.variances_)
根据方差的中位数进行过滤
import numpy as np
from sklearn.datasets import make_blobs
from sklearn.feature_selection import VarianceThreshold
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
print('数据的维度',data.shape)
print('标签的维度',label.shape)
# print('数据的方差',data.var(axis=0))
print('数据方差的中位数',np.median(data.var(axis=0)))
selector = VarianceThreshold(np.median(data.var(axis=0))) #实例化,不填参数默认方差为0
new_data=selector.fit_transform(data)
print('新数据的维度',new_data.shape) 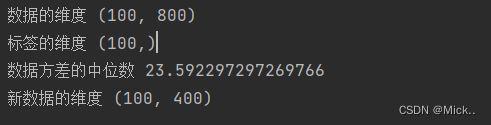
方差过滤对模型的影响
- 最近邻算法KNN,单棵决策树,支持向量机SVM,神经网络,回归算法,都需要遍历特征或升维来进行运算,所以他们本身的运算量就很大,需要的时间就很长,因此方差过滤这样的特征选择对他们来说就尤为重要。
- 但对于不需要遍历特征的算法,比如随机森林,它随机选取特征进行分枝,本身运算就非常快速,因此特征选择对它来说效果平平。
过滤法的主要对象是:需要遍历特征或升维的算法们;
过滤法的主要目的是:在维持算法表现的前提下,帮助算法们降低计算成本。
如果过滤之后模型的效果反而变差了,那么被过滤掉的特征中有很多是有效特征,就需要放弃过滤
相关性过滤
方差挑选完毕之后,我们就要考虑下一个问题:相关性了。我们希望选出与标签相关且有意义的特征,因为这样的特征能够为我们提供大量信息。如果特征与标签无关,那只会白白浪费我们的计算,可能还会给模型带来噪音。在sklearn当中,我们有三种常用的方法来评判特征与标签之间的相关性:卡方,F检验,互信息。
卡方过滤
卡方过滤是专门针对离散型标签(即分类问题)的相关性过滤。卡方检验类feature_selection.chi2计算每个非负特征和标签之间的卡方统计量,并依照卡方统计量由高到低为特征排名。再结合feature_selection.SelectKBest这个可以输入”评分标准“来选出前K个分数最高的特征的类,我们可以借此除去最可能独立于标签,与我们分类目的无关的特征
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import numpy as np
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
#这里因为卡方检验feature_selection.chi2 计算的是非负特征与标签的卡方统计量
print('小于0的个数',np.sum(data<0))
data[data<0]=0
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#卡方过滤
new_data=SelectKBest(chi2,k=200).fit_transform(data,label)
print('新数据的维度',new_data.shape)
#验证一下卡方过滤后的效果
print('卡方过滤后模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
print('未过滤模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),data,label,cv=5).mean())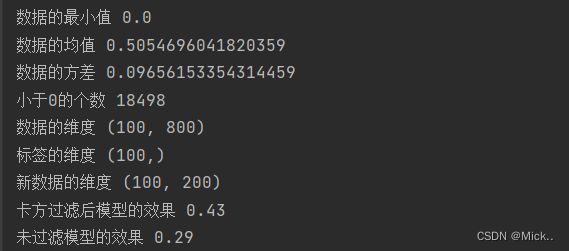
选取超参数K
卡方检验的本质是推测两组数据之间的差异,其检验的原假设是”两组数据是相互独立的”。卡方检验返回卡方值和P值两个统计量,我们可以根据P值进行筛选,p<=0.05或0.01,说明两组数据是相关的。
从特征工程的角度,我们希望选取卡方值很大,p值小于0.05的特征,即和标签是相关联的特征。
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
#这里因为卡方检验feature_selection.chi2 计算的是非负特征与标签的卡方统计量
print('小于0的个数',np.sum(data<0))
data[data<0]=0
print('数据的维度',data.shape)
print('标签的维度',label.shape)
##返回卡方值,p值,p<=0.05或0.01,说明两组数据是相关的
chivalue,pvalues_chi=chi2(data,label)
print('卡方值',chivalue)
print('p值',pvalues_chi)
#k取多少?我们想要消除所有p值大于设定值,比如0.05或0.01的特征:
#chivalue.shape[0]就是取出特征总个数,pvalues_chi > 0.05返回TRUE Flase,False=0,TRUE=1,所以就是总特征数减去所以p>0.05的特征,就是想保留的特征的数量
k = chivalue.shape[0] - (pvalues_chi > 0.05).sum()
print('K的值',k)
#卡方过滤
new_data=SelectKBest(chi2,k=k).fit_transform(data,label)
print('新数据的维度',new_data.shape)
#验证一下卡方过滤后的效果
print('卡方过滤后模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
print('未过滤模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),data,label,cv=5).mean())

或者是遍历一下
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
#这里因为卡方检验feature_selection.chi2 计算的是非负特征与标签的卡方统计量
print('小于0的个数',np.sum(data<0))
data[data<0]=0
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#卡方过滤
new_data=SelectKBest(chi2,k=200).fit_transform(data,label)
print('新数据的维度',new_data.shape)
#验证一下卡方过滤后的效果
print('卡方过滤后模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
print('未过滤模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),data,label,cv=5).mean())
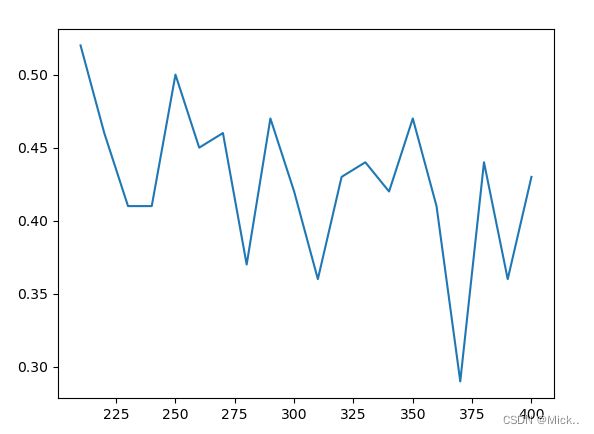
#超参数k的选择
score=[]
for i in range(400,200,-10):
new_data = SelectKBest(chi2, k=i).fit_transform(data, label)
score.append(cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
plt.plot(range(400,200,-10),score)
plt.show()
F检验
F检验,又称ANOVA,方差齐性检验,是用来捕捉每个特征与标签之间的线性关系的过滤方法。它即可以做回归也可以做分类,因此包含feature_selection.f_classif(F检验分类)和feature_selection.f_regression(F检验回归)两个类。它返回F值和p值两个统计量。和卡方过滤一样,选取p值小于0.05或0.01的特征,这些特征与标签时显著线性相关的。
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import numpy as np
from sklearn.feature_selection import f_classif
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#F检验
F, pvalues_f = f_classif(data,label)
k = F.shape[0] - (pvalues_f > 0.05).sum()
new_data = SelectKBest(f_classif, k=k).fit_transform(data, label)
print('新数据的维度',new_data.shape)
#验证一下F检验后的效果
print('F检测后模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
print('原始模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),data,label,cv=5).mean()) 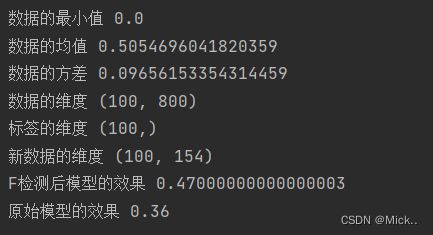
互信息法
互信息法是用来捕捉每个特征与标签之间的任意关系(包括线性和非线性关系)的过滤方法。和F检验相似,它既可以做回归也可以做分类,并且包含两个类feature_selection.mutual_info_classif(互信息分类)和feature_selection.mutual_info_regression(互信息回归)。
它返回“每个特征与目标之间的互信息量的估计”,这个估计量在[0,1]之间取值,为0则表示两个变量独立,为1则表示两个变量完全相关。
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectKBest
from sklearn.preprocessing import MinMaxScaler
import numpy as np
from sklearn.feature_selection import mutual_info_classif as MIC
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#互信息方法
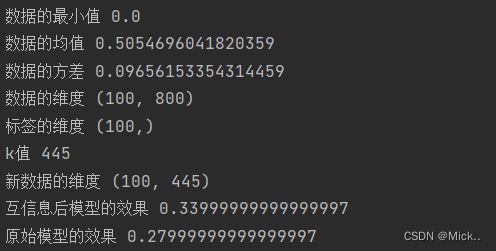
result=MIC(data,label)
k=result.shape[0]-np.sum(result<=0)
print('k值',k)
new_data = SelectKBest(MIC, k=k).fit_transform(data, label)
print('新数据的维度',new_data.shape)
#验证一下F检验后的效果
print('互信息后模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),new_data,label,cv=5).mean())
print('原始模型的效果',cross_val_score(RFC(n_estimators=10,random_state=0),data,label,cv=5).mean())
Embedded嵌入法
feature_selection.SelectFromModel
嵌入法是一种让算法自己决定使用哪些特征的方法,即特征选择和算法训练同时进行
class sklearn.feature_selection.SelectFromModel (estimator, threshold=None, prefit=False, norm_order=1,max_features=None)参数:
estimator:使用的模型评估器,只要是带feature_importances_或者coef_属性,或带有l1和l2惩罚项的模型都可以使用。
threshold:特征重要性的阈值,重要性低于这个阈值的特征都将被删除
打印特征的重要性
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_selection import SelectFromModel
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#首先实例化随机森林
RFC_=RFC(n_estimators=10,random_state=1218)
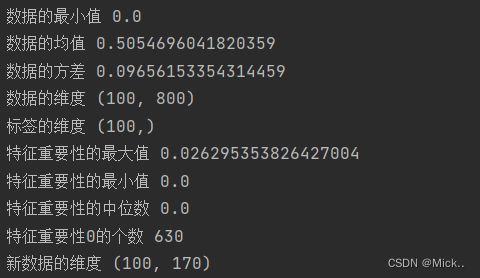
feature_importance=RFC_.fit(data,label).feature_importances_
# print('特征的重要性',feature_importance)
print('特征重要性的最大值',feature_importance.max())
print('特征重要性的最小值',feature_importance.min())
print('特征重要性的中位数',np.median(feature_importance))
print('特征重要性0的个数',np.sum(feature_importance==0))
new_data = SelectFromModel(RFC_,threshold=0.001).fit_transform(data,label) #这个是嵌入法的实例化
print('新数据的维度',new_data.shape)
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_selection import SelectFromModel
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#首先实例化随机森林
RFC_=RFC(n_estimators=10,random_state=1218)
new_data = SelectFromModel(RFC_,threshold=0.005).fit_transform(data,label) #这个是嵌入法的实例化
print('新数据的维度',new_data.shape)
# 绘制threshold的学习曲线
threshold = np.linspace(0,(RFC_.fit(data,label).feature_importances_).max(),20) #让阈值的取值在0到最大值之间取出20个数
score = []
for i in threshold:
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(data,label)
once = cross_val_score(RFC_,X_embedded,label,cv=5).mean()
score.append(once)
plt.plot(threshold,score)
plt.show() 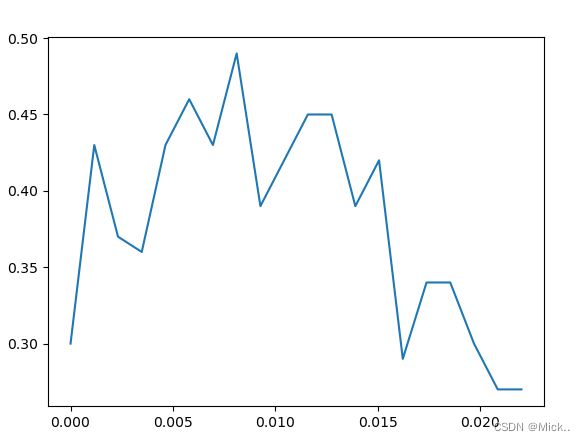
可见,随着阈值越来越高,模型的效果逐渐变差,被删除的特征越来越多,信息损失也逐渐变大
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
import numpy as np
import matplotlib.pyplot as plt
from sklearn.feature_selection import SelectFromModel
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
#首先实例化随机森林
RFC_=RFC(n_estimators=10,random_state=1218)
new_data = SelectFromModel(RFC_,threshold=0.005).fit_transform(data,label) #这个是嵌入法的实例化
print('新数据的维度',new_data.shape)
score = []
for i in np.linspace(0,0.002,20):
X_embedded = SelectFromModel(RFC_,threshold=i).fit_transform(data,label)
once = cross_val_score(RFC_,X_embedded,label,cv=5).mean()
score.append(once)
plt.figure(figsize=[20,5])
plt.plot(np.linspace(0,0.002,20),score)
plt.xticks(np.linspace(0,0.002,20))
plt.show()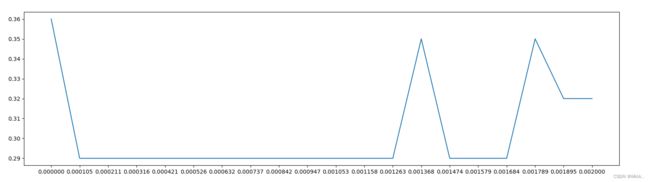
Wrapper包装法
包装法也是一个特征选择和算法训练同时进行的方法,但我们往往使用一个目标函数作为黑盒来帮助我们选取特征,而不是自己输入某个评估指标或统计量的阈值。。区别于过滤法和嵌入法的一次训练解决所有问题,包装法要使用特征子集进行多次训练,计算成本位于嵌入法和过
class sklearn.feature_selection.RFE (estimator, n_features_to_select=None, step=1, verbose=0)参数estimator是需要填写的实例化后的评估器,n_features_to_select是想要选择的特征个数,step表示每次迭代中希望移除的特征个数。
除此之外,RFE类有两个很重要的属性,.support_:返回所有的特征的是否最后被选中的布尔矩阵,以及.ranking_返回特征的按数次迭代中综合重要性的排名。
from sklearn.datasets import make_blobs
from sklearn.ensemble import RandomForestClassifier as RFC
from sklearn.model_selection import cross_val_score
from sklearn.preprocessing import MinMaxScaler
import numpy as np
from sklearn.feature_selection import RFE
data,label=make_blobs(n_features=800,n_samples=100,centers=4,random_state=1218)
#将数据缩放到0-1之间
scaler=MinMaxScaler(feature_range=(0,1))
data=scaler.fit_transform(data)
print('数据的最小值',data.min())
print('数据的均值',data.mean())
print('数据的方差',data.var())
##加入高斯噪声 生成随机正太分布
noise=np.random.normal(loc=1,scale=2,size=(100,800))
data=data+noise
print('数据的维度',data.shape)
print('标签的维度',label.shape)
RFC_ = RFC(n_estimators =10,random_state=0) #实例化RFC
#n_features_to_select是模型选择的个数,step每迭代一次删除50个特征
selector = RFE(RFC_, n_features_to_select=332, step=50).fit(data, label) #RFE的实例化和训练 332是上述模型效果最好时的特征数
print(selector.support_.sum()) #support_返回特征是否被选中的布尔矩阵,求和其实就是n_features_to_select
print(selector.ranking_) #返回特征的重要性排名
X_wrapper = selector.transform(data)
#交叉验证验证模型
cross_val_score(RFC_,X_wrapper,label,cv=5).mean()
特征选择总结
- 当数据量很大的时候,优先使用方差过滤和互信息法调整,再上其他特征选择方法。
- 使用逻辑回归时,优先使用嵌入法。
- 使用支持向量机时,优先使用包装法。