支持向量机之核函数(三)
在前两节中,我们探讨了线性可分情况下如何将求解分类函数问题转化为求最大分类间隔问题,再转化为凸优化问题。再基于强对偶性,将凸优化问题转化为对偶问题,并推导出KKT条件。在求解对偶问题的过程中,将w,b转化为对对偶变量a的求解,下一节我们将探讨如何用SMO算法求解a。
但是在讲解SMO算法之前,我们将在本节中探讨SVM的精髓所在——核函数。
1、核函数
事实上,大部分时候数据并不是线性可分的,这个时候满足这样条件的超平面就根本不存在。在上文中,我们已经了解到了SVM处理线性可分的情况,那对于非线性的数据SVM咋处理呢?对于非线性的情况,SVM 的处理方法是选择一个核函数 K(⋅,⋅) ,通过将数据映射到高维空间,来解决在原始空间中线性不可分的问题。
具体来说,在线性不可分的情况下,支持向量机首先在低维空间中完成计算,然后通过核函数将输入空间映射到高维特征空间,最终在高维特征空间中构造出最优分离超平面,从而把平面上本身不好分的非线性数据分开。如图所示,一堆数据在二维空间无法划分,从而映射到三维空间里划分:
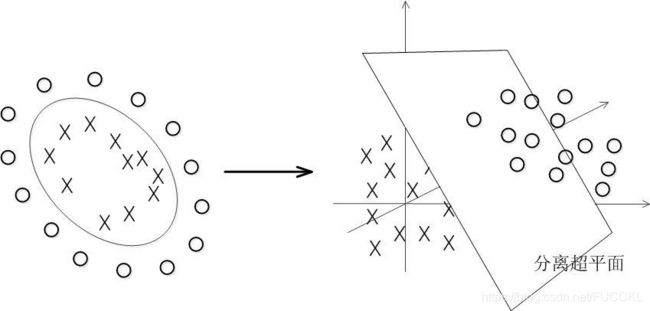
1.1 原始非线性映射(核方法)
在我们遇到核函数之前,如果用原始的方法,那么在用线性学习器学习一个非线性关系,需要选择一个非线性特征集,并且将数据写成新的表达形式,这等价于应用一个固定的非线性映射,将数据映射到特征空间,在特征空间中使用线性学习器。这种思想即为核方法。
核方法是解决非线性模式分析问题的一种有效途径,其核心思想是:首先,通过某种非线性映射将原始数据嵌入到合适的高维特征空间;然后,利用通用的线性学习器在这个新的空间中分析和处理模式。
在前面的推导中,我们得到
![]()
因此分类函数为
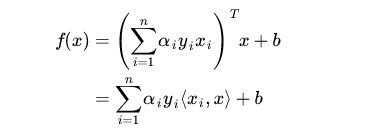
我们定义φ(x)为映射函数,将低维空间样本集映射到高维空间,令
在第一节中我们得到分类函数和极大a的公式:
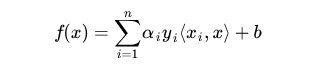
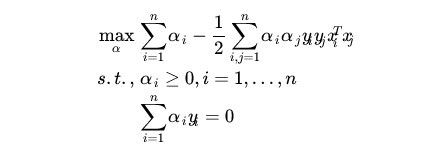
在进行映射后,则公式变为:
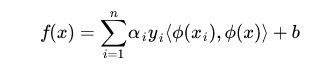
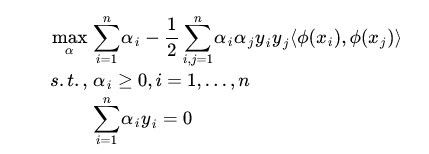
这种方法可以做到非线性分类,但是有一个很大的问题,就是容易出现维度爆炸,即当样本维数很大时,计算量会非常大。下面举例说明。
如下图所示的两类数据,分别分布为两个圆圈的形状,这样的数据本身就是线性不可分的,此时咱们该如何把这两类数据分开呢
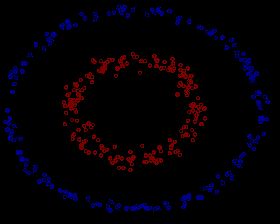
事实上,上图所述的这个数据集,是用两个半径不同的圆圈加上了少量的噪音生成得到的,所以,一个理想的分界应该是一个“圆圈”而不是一条线(超平面)。如果用X1和来X2表示这个二维平面的两个坐标的话,我们知道一条二次曲线(圆圈是二次曲线的一种特殊情况)的方程可以写作这样的形式:
![]()
这里如果我们构造另外一个五维的空间,其中五个坐标的值分别为Z1=X1,Z2=X1^2,Z3=X2,Z4=X2 ^2,Z5=X1X2,那么显然,上面的方程在新的坐标系下可以写作
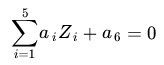
也就是说,如果我们做一个映射R2至R5,将X按照上面的规则映射为Z,那么在新的空间中原来的数据将变成线性可分的,从而使用之前我们推导的线性分类算法就可以进行处理了。这正是 Kernel 方法处理非线性问题的基本思想。
此时的映射函数为φ(x)=[x1,x1^2,x2,x2 ^2,x1x2]T (T表示转置)。
在最初的例子里,我们对一个二维空间做映射,选择的新空间是原始空间的所有一阶和二阶的组合,得到了五个维度;
如果原始空间是三维(一阶、二阶和三阶的组合),那么我们会得到:3(一次)+3(二次交叉)+3(平方)+3(立方)+1(x1 *x2 *x3)+2 *3(交叉,一个一次一个二次,类似x1 *x2^2) = 19维的新空间,这个数目是呈指数级爆炸性增长的,从而势必这给φ(x)的计算带来非常大的困难,而且如果遇到无穷维的情况,就根本无从计算了。
这个时候,核函数的重要性就体现了。
1.2 核函数性质
从最开始的简单例子出发,设两个向量
![]() 和
和
![]()
而φ(x)即是前面说的五维空间的映射,因此映射过后的内积为:
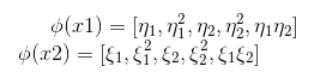
![]()
我们注意到:
![]()
二者有很多相似的地方,实际上,我们只要把某几个维度线性缩放一下,然后再加上一个常数维度,具体来说,上面这个式子的计算结果实际上和映射
![]()
之后的内积<φ(x1),φ(x2)>的结果是相等的,那么区别在于什么地方呢?
一个是映射到高维空间中,然后再根据内积的公式进行计算;
而另一个则直接在原来的低维空间中进行计算,而不需要显式地写出映射后的结果。
刚才提到的映射的维度爆炸,在前一种方法已经无法计算的情况下,后一种方法却依旧能从容处理,甚至是无穷维度的情况也没有问题。
我们把这里的计算两个向量在隐式映射过后的空间中的内积的函数叫做核函数 (Kernel Function) ,例如,在刚才的例子中,我们的核函数为:
![]()
现在我们的分类函数为:
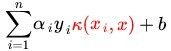
极大求a的公式为:
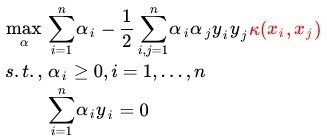
我们称呼这种构造核函数来解决核方法中出现维数爆炸的问题的方法叫做戏核法(Kernel Trick)
Kernel Trick:
定义一个核函数K(x1,x2)=<φ(x1),φ(x2)>,其中x1和x2是低维度空间中点(在这里可以是标量,也可以是向量),φ(xi)是低维度空间的点xi转化为高维度空间中的点的表示,< , > 表示向量的内积。这里核函数K(x1,x2)=<φ(x1),φ(x2)>的表达方式一般都不会显式地写为内积的形式,即我们不关心高维度空间的形式,也即我们不关心具体的映射函数是什么。
1.3 核函数的存在性判断和构造
既然我们不关心高纬度空间的表达形式,那么我们怎么才能判断一个函数是否是核函数呢?
Mercer 定理:任何半正定的函数都可以作为核函数。
所谓半正定的函数f(xi,xj),是指拥有训练数据集合(x1,x2,…xn),我们定义一个矩阵的元素aij = f(xi,xj),这个矩阵是n*n的,如果这个矩阵是半正定的,那么f(xi,xj)就称为半正定的函数。这个mercer定理不是核函数必要条件,只是一个充分条件,即还有不满足mercer定理的函数也可以是核函数。

Mercer定理表明为了证明K是有效的核函数,那么我们不用去寻找φ(x),而只需要在训练集上求出各个Kij,然后判断矩阵K是否是半正定(使用左上角主子式大于等于零等方法)即可。
核函数的构造要基于映射函数φ(x),使K(⋅,⋅)=<φ(x1), φ(x2),…>
最理想的情况下,我们希望知道数据的具体形状和分布,从而得到一个刚好可以将数据映射成线性可分的 φ(x) ,然后通过这个 φ(x)得出对应的 K(⋅,⋅) 进行内积计算。然而,第二步通常是非常困难甚至完全没法做的。不过,由于第一步也是几乎无法做到,因为对于任意的数据分析其形状找到合适的映射本身就不是什么容易的事情,所以,人们通常都是“胡乱”选择映射的,所以,根本没有必要精确地找出对应于映射的那个核函数,而只需要“胡乱”选择一个核函数即可——我们知道它对应了某个映射,虽然我们不知道这个映射具体是什么。由于我们的计算只需要核函数即可,所以我们也并不关心也没有必要求出所对应的映射的具体形式。
当然,说是“胡乱”选择,其实是夸张的说法,通常人们会从一些常用的核函数中选择(根据问题和数据的不同,选择不同的参数,实际上就是得到了不同的核函数),例如:

多项式核那里空间维度,也即映射后的空间维度为C(m+d,d),m为原始维度。
例如上面举的例子,m=2,d=2,x=[X1,X2]T(T表示转置),则我们使用核函数(x’z+1) ^ 2来生成映射函数Fi(x)和Fi(z)。因为核函数是由Fi(x)和Fi(z)内积的结果,所以实际上Fi(x)可以看做成由(X1+X2+1)^2生成的,Fi(x)在这个例子中最高次为2。
将(x1+x2+1)^2展开得(X1X1 + X1X2 + X2X2 +X1 + X2 + 1)(前面的系数均略去了),共6项。
映射后的维度为C(4,2),即(4*3)/(2 *1)=6。如下图所示
![]()
1.4 核函数小结
实际中,我们会经常遇到线性不可分的样例,此时,我们的常用做法是用核方法把样例特征映射到高维空间中去。
但进一步,如果凡是遇到线性不可分的样例,一律映射到高维空间,那么这个维度大小是会高到可怕的(如上文中19维乃至无穷维的例子)。那咋办呢?
此时,戏核法,也就是核函数就隆重登场了,核函数的价值在于它虽然也是将特征进行从低维到高维的转换,但核函数绝就绝在它事先在低维上进行计算,而将实质上的分类效果表现在了高维上,也就如上文所说的避免了直接在高维空间中的复杂计算。