05基于卷积神经网络-支持向量机(自动寻优)CNN-SVM数据分类算法
- CNN原理
卷积神经网络(Convolutional Neural Network,CNN)是一种深度学习模型,广泛用于计算机视觉领域。CNN 的核心思想是通过卷积层和池化层来自动提取图像中的特征,从而实现对图像的高效处理和识别。
在传统的机器学习方法中,图像特征的提取通常需要手工设计的特征提取器,如SIFT、HOG等。而 CNN 则可以自动从数据中学习到特征表示。这是因为 CNN 模型的卷积层使用了一系列的卷积核(filters),通过在输入图像上滑动并进行卷积运算,可以有效地捕捉到图像中的局部特征。
CNN 模型的卷积层可以同时学习多个不同的卷积核,每个卷积核都可以提取出不同的特征。通过堆叠多个卷积层,CNN 可以在不同的层次上提取出越来越抽象的特征。例如,低层次的卷积层可以捕捉到边缘和纹理等基本特征,而高层次的卷积层可以捕捉到更加复杂的语义特征,比如目标的形状和结构。
在卷积层之后,CNN 还会使用池化层来进一步压缩特征图的维度,减少计算量并增强模型的平移不变性。常见的池化操作包括最大池化(Max Pooling)和平均池化(Average Pooling),它们可以对特征图进行降采样,并保留最显著的特征。
通过多次堆叠卷积层和池化层,CNN 可以将输入图像逐渐转换为一系列高级特征表示。这些特征表示可以用于各种计算机视觉任务,如图像分类、目标检测、语义分割等。此外,CNN 还可以通过在最后添加全连接层和激活函数来进行预测和分类。
CNN 特征提取的主要优势在于其自动学习特征表示的能力和对图像局部结构的敏感性。相较于传统的手工设计特征提取器,CNN 可以更好地适应不同的数据集和任务,并且能够从大规模的数据集中学习到具有判别性的特征表示。这使得 CNN 成为计算机视觉领域的重要工具,并在许多实际应用中取得了令人瞩目的成果。

- 支持向量机原理
支持向量机(Support Vector Machine,SVM)是一种强大的监督学习算法,主要用于分类和回归问题。SVM 的核心思想是通过在特征空间上构建一个最优超平面来进行分类,这个超平面可以将不同类别的样本尽可能地分开,并且具有最大的间隔。
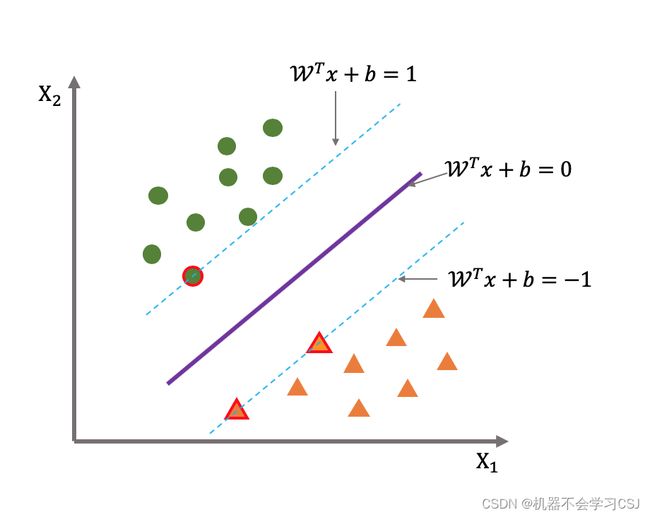
SVM 的工作原理可以简单描述为以下几个步骤:
特征映射:首先,将输入数据映射到高维特征空间。这是为了使数据在某种程度上线性可分,即在高维空间中存在一个超平面能够完全分割不同类别的样本。
寻找最佳超平面:在高维特征空间中,SVM 通过寻找一个最佳的超平面来进行分类。这个超平面被定义为能够最大化最靠近它的各类别样本的距离的超平面。这些最接近超平面的样本被称为“支持向量”,因为它们对于定义超平面起到了关键作用。
解决最优化问题:在寻找最佳超平面的过程中,SVM 将问题转化为一个凸优化问题。目标是最小化正则化项和误分类样本带来的损失。通过求解这个优化问题,可以找到最佳的超平面参数。
核函数:SVM 还引入了核函数的概念,它可以将低维输入数据映射到高维特征空间,避免了直接计算高维空间中的内积。常用的核函数有线性核、多项式核和高斯核等,根据不同的问题选择合适的核函数可以提高分类器的性能。
SVM 的优点在于:
在处理小样本的情况下表现良好,可以有效地处理高维数据。
通过最大化间隔,SVM 对噪声数据具有较强的鲁棒性。
SVM 的决策函数仅依赖于支持向量,因此模型相对简洁,预测速度快。
然而,SVM 也存在一些限制:
- SVM 对大规模数据集和高维数据的训练时间较长。
- SVM 对参数的选择敏感,需要进行调优。
- SVM在处理多类别问题时需要额外的策略,如一对多或一对一方法。
总结起来,支持向量机是一种强大的分类算法,通过构建最优超平面来实现分类任务。它在小样本、高维数据和非线性问题上表现出色,并且具有良好的鲁棒性和泛化能力。
3. CNN-SVM
利用CNN卷积神经网络对原始特征数据进行升维特征提取,然后选取最佳的卷积层展开提取的特征作为支持向量机SVM分类器的输入数据。最后进行
4. 程序内容
%% 读取数据
res = xlsread('XXX.xlsx');
%% 分析数据
num_class = length(unique(res(:,end))); % 计算类别数
num_dim = size(res,2)-1; % 特征维度
num_res = size(res,1); % 样本总数 行的数量
num_size = 0.7; % 设置训练集占比
res = res(randperm(num_res),:); %打乱数据 注释则按顺序
flag_conusion = 1; %设置是否显示混淆矩阵
%% 设置变量存储数据
P_train = []; P_test = [];
T_train = []; T_test = [];
%% 划分数据集
for i = 1: num_class
mid_res = res((res(:, end) == i), :); % 循环取出不同类别的样本
mid_size = size(mid_res, 1); % 得到不同类别样本个数
mid_tiran = round(num_size* mid_size); % 得到该类别的训练样本个数
P_train= [P_train; mid_res(1: mid_tiran, 1: end -1)]; % 训练集输入
T_train=[T_train; mid_res(1: mid_tiran, end)]; %训练集输出
P_test = [P_test; mid_res(mid_tiran + 1:end, 1:end -1)]; % 测试集输入
T_test = [T_test; mid_res(mid_tiran + 1: end, end)]; % 测试集输出
end
-
结果展示
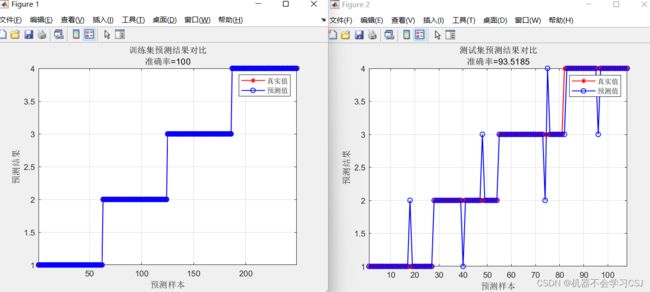
准确率
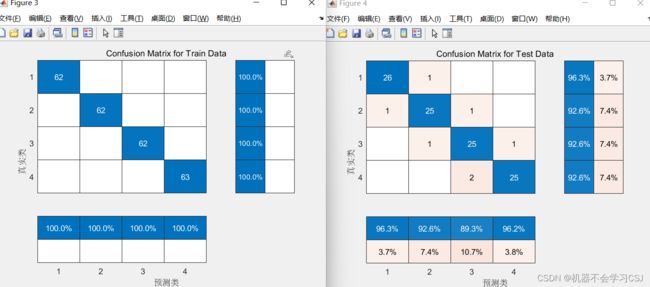
混淆矩阵
训练过程

训练网络结构图

-
获取方式
私信我或者点击下列链接
基于卷积神经网络-支持向量机数据分类 https://mbd.pub/o/bread/mbd-ZZuTlJ5t
关注免费送分类和时间序列程序!!!!!!!
搜索公主号:同名,去掉英文。可以获取下列资源
Matlab机器学习数据分类和时间序列预测基础模型大合集,免费赠送!!!!