RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces论文阅读笔记
论文原文地址:RSGAN: Face Swapping and Editing using Face and Hair Representation in Latent Spaces
本文和上一篇FSNet极为相似,:FSNet: An Identity-Aware Generative Model for Image-based Face Swapping,有需要的小伙伴可以对照着看.

摘要:RSGAN:使用潜在空间中的面部和头发表示进行面部交换和编辑
- 本文提出了一种
基于属性的编辑和随机人脸部件合成的人脸图像自动生成和编辑的集成系统。该系统基于一个深度神经网络,该网络利用大规模人脸图像数据集对人脸和头发区域进行变分学习。 与传统的变分方法不同,所提出的网络分别表示人脸和头发的潜在空间。 我们将所提出的网络称为区域分离生成对抗性网络(RSGAN)。 所提出的网络独立地处理潜在空间中的人脸和头发外观,然后通过替换人脸的潜在空间表示来实现人脸交换,并用它们重建整个人脸图像。这种方法在潜在空间稳健地执行人脸交换,即使是以前的方法导致失败的图像,比如由于不适当的拟合或三维变形模型。 此外,该系统还可以通过操作视觉属性或用随机生成的面部或头发部件组合来进一步编辑具有相同网络的面部交换图像。
引言
- 人的脸是从古至今识别个体的重要标志。 传统上人脸图片是用来记录人的身份。 如今,许多人喜欢在社交网站上分享他们的日常照片,其中通常包括人脸。 在这种情况下,人们想要让照片更有吸引力。 由于这一需求,在计算机图形学和视觉研究社区中引入了大量的人脸图像分析[1-4]和操作[5-11]研究。
- 人脸交换是人脸图像编辑的最重要技术之一,具有广泛的实际应用,如
集体照片[5]、虚拟发型拟合[9]、隐私保护[6,12,13]和机器学习数据增强[14-16]。 传统的人脸交换方法首先检测源图像和目标图像中的人脸区域。 通过数字图像拼接将源图像的人脸区域嵌入到目标图像中。为了说明我们的研究动机,我们在下面的段落简要回顾了以前的面部交换方法。 - 最流行的人脸交换方法之一是使用
三维变形模型(3DMM)[5,17]。在这类方法中,首先通过拟合3DMM[1,2]得到人脸几何形状及其相应的纹理映射。 源和目标图像的纹理映射然后与估计的UV坐标交换。 最后,利用用目标图像估计的照明条件对替换后的人脸纹理进行重新渲染。 这些方法与3DMM可以取代面孔,即使是那些有不同的方向或在不同的照明条件。 然而,在实际应用中,这些方法容易导致人脸几何形状或照明条件的估计失败。 不正确的估计通常是有问题的,因为人们可以敏感地注意到这些几何形状和照明条件的轻微不匹配。[3DMM缺点就在估计照明条件] - 在人脸交换的具体应用中,如隐私保护和虚拟发型拟合,可以任意选择源图像或目标图像。 例如,即使从随机图像中提取新的人脸区域,目标图像的隐私也可以得到保护。 这表明了
从大型图像数据库[6,9]中选择一个源图像和目标图像的想法。该类中的方法可以选择两个输入图像中的一个,这样所选图像与其对应图像相似。 因此,这些方法可以避免在困难的情况下用不同的人脸方向或不同的照明条件替换人脸。 然而,这些方法不能用于任意输入人脸图像之间的人脸交换的更一般目的。 - 最近大量的深度学习研究促进了与大规模图像数据库的人脸交换。 Bao等人。 在他们的条件图像生成论文中引入了一个人脸交换演示,并提出了一个名为CVAE-GAN[18]的神经网络。 他们的方法在训练数据集中为每个人使用数百幅图像,并将人脸身份作为图像条件学习。 在桌面软件工具“FakeApp”中使用了类似的技术[19]由于其易于使用的管道与深度神经网络(DNN)进行人脸交换,最近引起了人们的广泛关注)。 这个工具需要数百个图像的两个目标人交换的脸。 然而,为非名人准备如此大量的肖像图像是相当不可取的。 与这些技术相比,Korshunova等人。 [13]将神经风格转移[20]应用于人脸交换, 通过对预先训练的网络进行微调,在源图像中对一个人的几十幅图像进行微调,将神经风格的传递[20]应用于人脸交换。 不幸的是,对于大多数人来说,收集许多图像并对网络进行微调以生成单个人脸交换图像仍然是不切实际的。[许多方法需要同一个人的大量图片进行训练,但是这样不太方便]
- 在本文中,我们使用生成神经网络来解决上述问题,我们将其称为“
区域分离生成对抗性网络(RSGAN)”。虽然已经介绍了大量关于这种深层生成模型的研究,但将其应用于人脸交换仍然具有挑战性。在普通生成模型中,网络合成的图像或数据作为训练数据获得。 然而,很难准备一个包括人脸交换前后人脸图像的数据集。我们通过设计网络来解决这个问题,为每个面部和头发区域学习不同的潜在空间。该方法中使用的生成器网络被训练成从两个随机向量合成自然人脸图像,这些向量对应于人脸和头发区域的潜在空间表示。因此,生成器网络可以从实际图像样本计算的两个潜在空间表示中合成一个人脸交换图像。图2.中示出了RSGAN的体系结构。

图2. 所提出的RSGAN的网络体系结构,包括三个部分网络,即两个分隔网络和一个合成网络。
分隔网络分别提取输入图像x的人脸和头发区域的潜在空间表示zf和zh。 合成网络从两个潜在空间表示重构输入人脸图像。
通过两个鉴别器网络对重建图像x0和输入图像x进行评估。
全局判别器Dg区分图像是真实的还是假的,补丁判别器Dp区分图像的局部补丁是真实的还是假的。
-
该体系结构由两个变分自动编码器(VAE)和一个生成对抗性网络(GAN)组成)。 两个VAE部分将面部和头发外观编码为潜在空间表示,GAN部分从面部和头发的潜在空间表示中生成自然的面部图像。在SEC3中介绍了网络的详细描述及其训练方法。 除了人脸交换外,这种变分学习还支持其他编辑应用,如
视觉属性编辑和随机人脸部件合成。 为了评估该方法的人脸交换结果,我们利用了身份保存和交换一致性两个度量。 身份保存是使用开源人脸特征提取器OpenFace[21]进行评估的。 通过测量输入图像与通过两个输入图像之间交换两次得到的图像之间的绝对差异和多尺度结构相似性(MS-SIM)[22]来评估人脸交换的一致性。 RSGAN的应用结果及其评价见SEC 4.
贡献: -
作为一种人脸交换和编辑系统,该方法与以往的方法相比具有以下优点:
- 1.它提供了一个用于
人脸交换和附加人脸外观编辑的集成系统; - 2.它的应用是通过训练单个DNN来实现的,并且
不需要任何额外的运行时计算,如微调; - 3.它即使对于
不同人脸方向人脸或在不同的照明条件下,也能稳健地执行高质量的人脸交换;
- 1.它提供了一个用于
2.相关工作
2.1Face swapping
- 为了不同的目的,在许多研究中对人脸交换进行了研究,如集体照片[5]、虚拟发型拟合[9]、隐私保护[6,12,13]和大型机器学习[16]的数据增强。 几项研究[7,12]只交换了脸的部分,如眼睛、鼻子和嘴,而不是在图像之间交换整张脸。 如上一节所述,传统的人脸交换方法之一是基于3DMM[5,17]。 将3DMM拟合到目标面,得到人脸几何形状、纹理映射和照明条件的近似[1,2]。 使用3DMM,
通过替换纹理映射和使用估计的照明条件重新呈现人脸外观来实现人脸交换。 这些基于3DMM的方法的主要缺点是它们需要手动对齐3DMM以获得精确的拟合。[3DMM方法的缺点] - 为了缓解这个问题,Bitouk等人。 [6]提出了
一种用大规模人脸图像数据库进行人脸自动交换的方法。 他们的方法首先搜索具有与输入图像相似布局的人脸图像,然后用边界感知的图像组合替换人脸区域。 Kemelmacher-Shlizerman[9]最近提出了一种更复杂的方法。她精心设计了一个手工制作的特征向量来处理面部图像,并实现了高质量的面部交换。然而,这些通过搜索相似图像的方法不能自由选择输入图像,不适用于任意的人脸图像对。[传统方法缺点] - 最近,
鲍等人。 在他们的CVAE-GAN[18]论文中引入了一个人脸交换演示,它是一个用于条件图像生成的DNN。 在他们的方法中,CVAE-GAN经过训练,通过处理人脸身份作为生成图像的条件,在训练数据集中生成特定人员的人脸图像。该CVAE-GAN通过改变目标图像的人脸身份条件来实现人脸交换。 [CAVE-GAN的方法] - Korshunova等人。 应用
神经风格转移,这是另一种人脸交换[13]深度学习技术。 他们的方法类似于原始的神经风格转移[20]在意义上,面部身份处理类似于艺术风格。 目标面的人脸身份被源面的人脸身份所取代。 这些基于DNN的模型的共同缺点是用户必须收集至少几十幅图像才能获得人脸交换图像。虽然收集如此多的图像是可能的,但对大多数人来说,仅仅为了他们的个人照片编辑而收集这些图像是不切实际的。[Korshunova利用神经风格迁移的方法:缺点就是收集大量个人招照片是不切实际的]
2.2面部图像编辑
- 为了增强面部图像的视觉吸引力,人们提出了多种技术,如
面部表情转移[7,23]、吸引力增强[24]、face image relighting[25,26]。 在传统的人脸图像编辑中,使用人脸分析工具,如主动外观模型[27]和三维变形模型[1,2],对底层的三维人脸几何形状和人脸部件排列进行估计。 这些底层信息在编辑算法中被操纵,以提高输出图像的吸引力。 另一方面,最近基于DNN的方法没有明确地分析这些信息。 通常,输入图像和用户的编辑意图被馈送到端到端的DNN,然后,编辑结果直接从网络输出。例如,几个基于自动编码器的DNN模型[18,28-30]被用来操纵人脸的视觉属性,其中视觉属性,如面部表情和头发颜色,被修改以改变人脸图像外观。[最近的一些基于DNN的方法是一个黑匣子] - 相反,Brock等人。 [31]提出了一种基于油漆界面的图像编辑系统,其中DNN根据用户指定的输入图像和油漆笔画合成自然图像输出。 基于DNN的图像完成[32,33]的几项研究提出了通过用DNN填充输入图像的部分来操纵人脸外观的演示。 然而,估计这些方法的结果是相当困难的,因为它们只填充用户绘制的区域,而且结果在训练数据中是合理的。**[Brock的方法无法客观评价]
3.区域分隔GAN
-
用DNNs交换面部的主要挑战是在面部交换前后准备面部图像,因为没有特殊的手段去换脸,一个真实的人的脸就不能被另一个人的脸所取代。 收集这种人脸图像的另一种可能的方法是数字合成它们。 然而,这是一个鸡和蛋的问题,因为合成这样的面部交换图像是我们的主要目的。 为了克服这一挑战,我们利用变分方法来表示面部和毛发的外观。
在人脸交换中,在图像空间中分别处理一个人脸区域和一个头发区域。 -
人脸交换问题被概括为
合成任意一对人脸和头发图像的问题。 提出的RSGAN的目的是利用人脸和头发外观的潜在空间表示来实现这种图像合成。 在所提出的方法中,这一目的是通过图中所示的DNN来实现的。如图 2.所示,RSGAN的体系结构由两个VAE组成,我们称之为分离器网络,一个GAN,我们称之为合成网络。 在这个网络中,脸和头发区域的外观首先被分隔网络编码成不同的潜在空间表示。 然后,生成网络生成具有所获得的潜在空间表示的人脸图像,从而重建输入图像中的原始外观。然而,只有来自真实图像样本的潜在空间表示的训练会导致过度拟合。[只有真实的人脸图像参数与训练会导致过拟合] -
我们发现,以这种方式训练的RSGAN忽略了人脸表示的潜伏空间,并在人脸交换的同时合成了与目标图像相似的图像。因此,
我们向合成网络提供随机潜在空间表示,使它们被训练成合成自然人脸图像,而不是过度拟合训练数据。[RSGAN解决了上述问题] -
设x为训练图像,c为其对应的视觉属性向量。 通过人脸编码器FE-xf和头发编码器FE-xh,得到了x的人脸和头发外观的潜在空间表示zxf和zxh。 同样,可视化属性c被嵌入到属性的潜在空间中。 通过编码器FE-cf和FE-ch得到人脸和头发属性向量的潜在空间表示zcf和zch。作为标准VAE,这些潜在空间表示是从多元正态分布中采样的,其平均值和方差由编码器网络推断。

其中µl和σ2l是用编码器得到的zl的平均值和方差。 用于人脸和头发区域的解码器网络FD-f和FD-h分别从相应的潜在空间表示中重建外观x’f和x’h。 合成网络G用编码器的潜在空间表示生成重构的外观x’。 这些重建过程制定为:
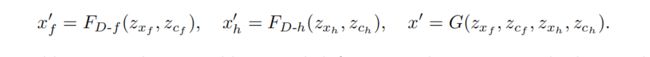
-
此外,从多元标准正态分布N(0,1)中抽样的随机变量在训练中一起使用。 设ˆzxf、ˆzxh、ˆzcf和ˆzch分别对应于zxf、zxh、zcf和zch的随机变量。 我们还计算了随机人脸图像ˆx’与这些样本:

-
通过
两个鉴别器网络Dg和DP对输入图像x和两个生成的图像x'和ˆx'进行评估。全局鉴别器Dg区分这些图像是真实的还是假的,就像标准GANs[34]中的那样。 另一方面,补丁鉴别器DP最初用于图像到图像网络[35],它区分本地补丁是来自真实图像还是假图。此外,我们还训练了一个分类器网络C来估计从输入图像x的视觉属性c*。 分类器网络通常需要编辑一个图像,而这个图像没有准备好视觉属性。 此外,分类器网络还获得了一个entries在0到1之间的视觉属性向量,而在许多公共数据集中准备的视觉属性向量的离散值为0或1。 这样的中间值是有利的,例如,当我们用两个视觉属性项“黑发”和“棕色头发”表示深棕色头发时”。 因此,即使在为x准备视觉属性时,我们也使用估计的属性c∗而不是c。[利用(0,1)之间的中间值来表示视觉属性,而不是用单纯的0或1表示.]
3.1训练
-
在所提出的RSGAN体系结构中,执行三个自动编码过程,每个过程从输入图像x中得到x’f、x’h和x’。 遵循标准VAE,我们定义了三个重建损失函数:
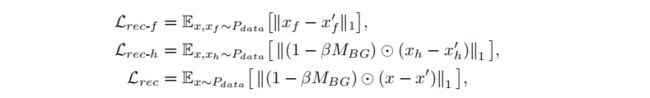
-
其中MBG是一个背景掩码,前景像素为0,背景像素为1**[0表示黑色,1表示白色]**,运算符圆圈加一点表示每像素乘法。 背景掩码MBG用于训练网络在前景区域合成更详细的外观。 在我们的实现中,我们使用参数β=0.5的将背景中的最小平方误差减半。
Kullback Leibler损失函数也被定义为四个编码器中每一个的标准VAE:

-
分离器和合成网络的集合,以及两个鉴别器网络作为标准GAN网络进行对抗性训练。 对抗性损失定义为:

-
此外,训练分类器网络C来估计接近c的正确的视觉属性c∗。我们定义了一个交叉熵损失函数LBCE,并利用它定义了分类器网络LC的一个损失函数:

-
其中ci表示视觉属性向量c的第i个条目。为了保留生成图像x’和ˆx’中的视觉属性,我们添加了以下损失函数来训练生成网络:
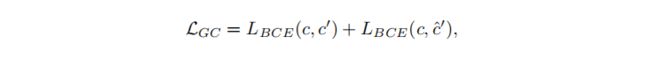
-
其中c’和ˆc’分别估计x’和ˆx’的视觉属性。 训练RSGAN的总损失函数由上述损失函数的加权和定义:

-
我们经验性地确定了加权因子λrec=4000,λKL=1,λadv-g=20,λadv-p=30,λC=1,和λGC=50。 在我们的实验中,使用ADAM优化器将损失函数最小化[36]。初始学习速率为0.0002,β1=0.5,β2为0.999。 mini-batch是50。 补充材料中提供了详细的训练算法。
3.2数据集
-
训练RSGAN需要从真实样本中对人脸图像x,人脸区域图像xf,头发区域图像xh,背景掩码MBG进行采样。 为此,我们从数据集CelebA[3]生成具有大规模人脸图像的人脸和头发区域图像,即图3说明了数据集生成的过程。 在CelebA中原始图像的大小是178×218(图 3(a))。 我们首先使用PSPNet[37]估计前景掩码,这是一种最先进语义分割方法,带有“人”标签。 背景掩码是通过在前景掩码中反转蒙面和非掩蔽像素来获得的(图 3(b))。

图3. 从CelebA[3]的肖像中产生面部和头发区域图像的过程。 用PSPNet[37]计算(B)中的背景掩码,这是一种最先进的基于DNN的语义分割。 用©中的蓝色面部地标计算(D)中的面部和头发区域的裁剪矩形)。 为了提高人脸身份的重建质量,人脸区域比头发区域放大。 -
第二,
我们提取68个面部地标(图3(c)有一个共同的机器学习库,即Dlib[38]。面部区域由41个地标定义,它们对应于眼睛、鼻子和嘴巴,它们在图中用蓝色圆圈表示图 3©。 我们计算了这些地标的凸壳,并沿水平和垂直方向分别将凸壳拉伸1.3倍和1.4倍。 得到的凸壳被用作面罩,如图所示 3(d)。 面部和头发区域用面具提取,并将这些区域裁剪成正方形(图 3(e)和(f))。面部区域的左上角为(30,70),其大小为118×118。 头发区域的左上角为(0,20),其大小为178×178。最后,我们将这些裁剪后的图像调整到相同的大小。 在我们的实验中,我们将它们调整为128×128。 由于人脸区域更重要的是识别图像中的一个人,所以我们对人脸区域使用了更高的分辨率。 在处理数据集中的图像时,我们从CelebA中提取选择包含的202,599幅图像中195,361幅图像的面部地标。 在这些195,361幅图像中,我们使用了180,000幅图像进行训练,其他15,361幅图像用于测试。
3.3 Face swapping with RSGAN
- 用RSGAN从两幅图像x1和x2计算人脸交换图像。 对于每一幅图像,视觉属性c∗1和c∗2首先由分类器估计。 然后,用编码器计算这些变量z1、xf、z1、cf、z2、xh和z2、ch的潜在空间表示。 最后,由生成网络生成面交换图像为x0=G(z1、xf、z1、cf、z2、xh、z2、ch)。 这种只向RSGAN输入两个图像的操作通常执行适当的面部交换。 然而,输入图像中的头发和背景区域有时不能用RSGAN正确地恢复。
为了缓解这一问题,我们可以选择对人脸交换图像执行梯度域图像拼接。在此操作中,使用面罩提取人脸交换图像的人脸区域,该区域的获取方式与数据集生成相同。 然后,通过梯度域图像组成[39],将人脸交换图像的人脸区域由目标图像组成。 为了区分这两种方法,我们分别将它们表示为“RSGAN”和“RSGAN-GD。 除非另有规定,本文所示的结果仅使用RSGAN计算,而不需要RSGAN-GD**.[提出RSGAN_GD方法解决偶尔出现的无法正确换脸的问题]**
4 Results and Discussion
-本节介绍使用预先训练的RSGAN的应用结果。 对于这些结果,我们在Python中使用TensorFlow[40]实现了一个程序,并在一台具有IntelXeon3.6GHz E5-1650v4CPU、NVIDIA GTXTITANX GPU和64GB RAM的计算机上执行了该程序。 我们使用了18万张训练图像,并对拟议的RSGAN网络进行了超过120000个global步骤。 使用一个单独的GPU训练大约花费了50个小时。这篇论文中的所有结果都是使用不包括训练图像中的测试图像生成的。
- 人脸交换:该系统的人脸交换结果如图4.所示,在此图中,第一行说明源图像,第二行说明源图像的再现外观,底部三行说明最左边列中不同目标图像的人脸交换结果。 在每个结果中,我们观察到面部身份、表情、面部部位的形状和阴影在面部交换结果中自然呈现。 在这些输入图像对中,Face#7和Hair#1的面部表情有很大的差异,Face#4和Hair#2的面部定向有差异,Face#3和Hair#1的照明条件有差异。

图 4. 不同面部和头发外观的面部交换结果。 该图中的两个顶部行表示原始输入及其重建外观。 在这些结果中,每个行中图像的人脸区域被每个列中的图像中的人脸替换。 - 即使对于上文提到的那种比较困难的输入对,我们的方法也实现了自然的人脸交换。 此外,我们还将我们的面部交换结果与图 5中[9,17]的最先进的方法进行了比较。将结果与从大型数据库搜索的[9]中使用的输入图像进行比较,使它们的布局与源图像相似。 虽然这些输入图像更有利于[9],但我们的RSGAN-GD的结果与[9]的结果是兼容的。 与其他最先进的方法[17]相比,我们的结果中的面部部分的大小看起来更自然,因为面部部分与整个面部大小的比例与源图像中的比例更相似。 正如本文[17]所报道的,这些性能损失是由于它们对地标检测和3DMM拟合质量的敏感性,尽管它们提出的语义分割是强大的。[和9,17种的方法作比较,优于其他方法]

视觉属性编辑 - 为了与视觉属性向量一起执行人脸交换,所提出的RSGAN将视觉属性向量嵌入到人脸和头发视觉属性的潜在空间中。 因此,所提出的编辑系统能够仅在面部或头发区域中操作属性。 视觉属性编辑的结果如图6所示. 此图包括两个图像组,每个图像组有三行。 在第一行中,顶部指示的视觉属性被添加到面部和头发区域。
图6. 使用RSGAN进行可视化属性编辑的结果。 在这个图中,在标有“Total”的行中得到的结果是为面部和头发区域添加一个新的视觉属性。 用于这些结果的视觉属性在顶部表示。 另一方面,用“Face”标记的行中的结果是通过只为面部区域添加一个新的视觉属性来获得的,而原始的视觉属性用于头发区域。 以“头发”标记的行中的结果以同样的方式生成。【就是说最左边一列是输入原始图像,右边每一列代表添加一个属性之后对于最左侧原始输入的影响。第一行代表对于整体的影响,第二行是对人脸的影响,第三行是对于头发的影响】 - 在第二行和第三行中,视觉属性被添加到面部或头发区域中。 如图所示,仅为一个面部和头发区域添加视觉属性不会影响另一个区域。 例如,当属性“金发”添加到面部区域时,头发颜色没有改变。 此外,“男性”和“老年”等属性可能影响这两个区域,当它们被添加到两个区域中的任何一个区域时,只会改变一个区域的外观。 例如,“男性”属性被添加到面部区域,只有面部外观变得男性化,而头发外观没有改变。 此外,可视化属性编辑还可以应用于带有RSGAN的人脸交换图像。 此应用程序的结果如图 1所示。. 请注意,RSGAN可以通过向网络同时输入两个输入图像和修改的视觉属性向量来实现人脸交换和视觉属性编辑。

图 1.人脸交换和附加视觉属性编辑的结果。 第一列中图像的人脸区域嵌入到第二列中的图像中。 面部交换的结果在第三栏中得到了说明,通过添加“金发”和“眼镜”等视觉属性,它们的外观被进一步操纵”。【比如说加入金发特征、加眼镜、加胡须、加黑发、加男性特征、加笑容。】 RSGAN只通过一次网络传递两个输入图像和视觉属性就可以得到这些结果。
随机人脸零件综合:
-利用所提出的RSGAN,我们可以生成一个新的人脸图像,它具有真实的图像样本中的人脸或头发的外观,以及由随机潜在空间定义的对应区域的外观。这种随机图像合成用于通过随机改变人脸区域的隐私保护,以及通过随机改变头发区域的人脸识别数据增强。 随机图像合成的结果如图 7所示。这个图形由顶部和底部的两组图像组成。 在每组中,左边显示一个输入图像。 在正确的图像中,它的面部或头发区域与随机的头发或面部区域相结合。 上面一组用随机的头发来说明图像,下面一组用随机的脸来说明图像。 尽管随机的面部和头发区域覆盖了大量的外观,但在实际输入中,面部和头发的外观在结果中得到了适当的保留。

图7. 随机面部和头发部分的生成和组成结果。 我们可以对面部和头发外观的独立潜在空间表示进行采样,并将它们与所提出的RSGAN相结合。 在顶部组中,随机头发外观与左侧输入图像的面部区域相结合。 在底部组中,随机人脸外观与输入图像的头发区域相结合。
4.1实验
-
我们使用两个度量来评估所提出的和其他先前方法的人脸交换结果,即
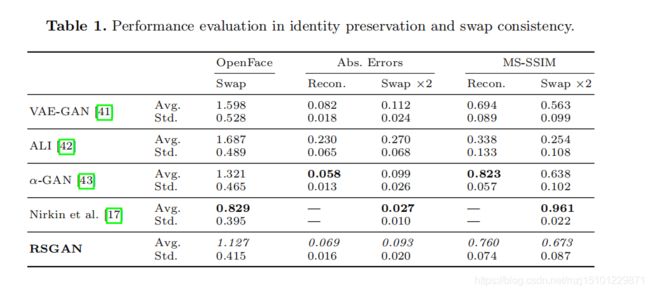
身份保存和交换一致性。 在本实验中,我们将这两个值与Nirkin等人先前自复制的生成网络VAE-GAN[41]、ALI[42]、α-GAN[43]和最先进的人脸交换方法进行了比较。 [17]。 利用生成网络,我们分三步计算了人脸交换的结果。 首先,我们以与数据集合成相同的方式计算面罩。 第二,掩模中源图像的人脸区域被复制和粘贴到目标图像上,从而使两个眼睛位置对齐。最后,将复制和粘贴后的整个图像外观通过馈送到自复制网络进行修复。这些算法制作的人脸交换图像的例子如图8所示。 我们计算了从15,361个测试图像中选择的1000个随机图像对的不同算法的结果。 两个指标的平均值和标准差见表1。 在本表中,每一栏中的最佳分数用黑体字表示,次优分数用斜体字表示。

-
表1比较了所提出的RSGAN和其他方法的人脸交换结果。 在顶部和底部的两个图像组中,最左边列中的两个输入图像的人脸区域被替换。
-
通过输入图像特征向量与人脸交换图像特征向量之间的平方欧几里德距离来评价人脸交换中的身份保持。利用开源人脸特征提取器OpenFace[21]计算特征向量。 第三列的测量距离表明,RSGAN优于其他生成神经网络,但其性能比Nirkin等人的方法差。【Nirkin等人的是3D方法】然而,Nirkin等人的方法。 在本实验中使用的1000个测试图像对中,只能执行81.7%的人脸交换,因为它通常无法将3DMM拟合到两个输入图像中的至少一个。 相反,所提出的RSGAN和其他基于生成神经网络的方法对所有测试图像进行人脸交换。 因此,我们认为RSGAN的人脸交换实际上是有用的,即使身份保存比Nirkin等人最先进的方法略差。 -
用
输入图像与两个输入图像之间交换两次人脸区域后得到的图像之间的绝对差和MSSSIM[22]来评估交换一致性。对于以前的生成神经网络和RSGAN,我们也计算了这些值,对于由网络重建的图像。 如表1所示,具有绝对误差的评价结果和MS-SSIM表明Nirkin等人的方法。 优于生成神经网络,包括RSGAN。 我们认为这是因为Nirkin等人的方法在面部交换时只产生一个面部区域,而生成神经网络同时合成面部和头发区域。 因此,对于Nirkin等人的方法,绝对差异和MS-SSIM的得分相对较低。 其中像素值的差异只发生在人脸区域。此外,Nirkin等人的方法对于在实践中使用相当不稳定,如前一段所述。 因此,所提出的RSGAN方法值得在实践中使用,因为与其他生成神经网络相比,它达到了最好的交换一致性,如“交换×2”列所示。
4.2讨论
变分与非变分方法
-
为了视觉特征提取的目的,许多变体的自动编码器已经被使用[28,44-46]。 在这些方法中,当实际图像外观需要在其应用程序中再现时,通常最好使用非变量方法。 例如,最近的研究[45,46],它引入了一个类似的想法,我们的研究,使用非变量方法的图像部分提取[45]和操纵人们的年龄在肖像[46]。 我们还在一个原型实现中实验了所提出的RSGAN中的一个非变量,我们发现它的自我再现性比本文引入的变分性略好。 然而,考虑到RSGAN的变分方法(如随机人脸零件抽样)的广泛适用性,我们确
定变分方法实际上比非变量方法更有用。
** 区域记忆与RNN:** -
在图像部件合成中,以前的一些研究已经应用递归神经网络来记忆哪些部件已经合成或不[44,45,47]。 在这些研究之后,我们实验地插入了长短期存储器(LSTM)[48]使两个图像编码器网络的输出被馈送到它。 然而,在我们的实验中,我们发现LSTM的这种应用使训练变得困难,并且收敛速度变慢。 在人脸映射和其他应用中,结果的视觉质量不明显优于没有LSTM的RSGAN。 我们用LSTM说明了RSGAN体系结构,并在补充材料中给出了该网络的结果。
局限 -
该系统的主要缺点是
图像分辨率有限。 在我们的实现中,训练数据集中的图像大小为128×128。 因此,图像编辑只能在此分辨率下执行。 为了提高图像分辨率,我们需要训练具有更高分辨率图像的网络,就像CelebA-HQ[49]一样。 在最近的研究中[33,49],使用这样一个高分辨率图像数据集进行训练是通过逐步增加输入图像的分辨率来进行的。 这种方法也可以直接应用于所提出的RSGAN。 因此,该系统的有限图像分辨率将得到明显的解决。[此方法的缺点:分辨率很低]
5.结论
- 本文提出了一种基于生成神经网络的人脸图像综合编辑系统。 该系统实现了
高质量的人脸交换,这是本研究的主要范围,即使对于不同方向和不同照明条件的人脸。 由于所提出的系统可以将人脸和毛发的外观编码为潜在空间表示,因此可以通过操纵潜在空间中的表示来修改图像外观。作为一种深度学习技术,RSGAN体系结构和我们的训练方法的成功意味着深度生成模型甚至可以获得在训练数据集中没有准备的一类图像。 我们相信,我们的实验结果为生成训练数据集中难以准备的数据集提供了一个关键。