论文笔记之Stein变分梯度下降
论文地址:点这里。作者还提供了Stein变分梯度下降法的源码。
Note:
源码不涉及深度学习,所以PyTorch用户或者TF用户都可以使用。
Stein变分梯度下降(SVGD)可以理解是一种和随机梯度下降(SGD)一样的优化算法。在强化学习算法中,Soft-Q-Learning使用了SVGD去优化,而Soft-AC选择了SGD去做优化。
Stein Variational Gradient Descent:A General Purpose Bayesian Inference Algorithm
- Abstract
- 1 Introduction
- 2 Background
- 3 Variational Inference Using Smooth Transforms
-
- 3.1 Stein Operator as the Derivative of KL Divergence
- 3.2 Stein Variational Gradient Descent
- 4 Related Works
- 5 Experiments
- 6 Conclusion
- 源码解析
Abstract
本文旨在提供一种新的变分推断(VI)算法用来做梯度下降(优化)。通过优化两个分布的KL散度,粒子不断迭代,使之从初始的分布一步步达到目标分布。算法涉及到Stein特征的平滑转换以及核差异(KSD)。
Note:
- 关于KSD的介绍,可以参考我的另一篇论文笔记。
1 Introduction
贝叶斯推断是一种模型估计的方法,核心就是那个贝叶斯公式。该公式中有一个归一化因子 p ( x ) = ∫ p ( x ) d x p(x)=\int p(x)\mathrm{d}x p(x)=∫p(x)dx,当高维问题时候,计算将变得困难。因此MCMC和VI这两种方法就应运而生,用于解决这个计算复杂度问题。
马尔科夫链蒙特卡洛(MCMC)的缺陷在于收敛慢且难收敛,优点是偏差较小,毕竟是个需要采样的方法(强化学习最初的MC方法也有这2个特点)。
变分推断(VI)是一种优化算法,用随机梯度下降最小化目标分布与估计分布之间的KL散度,其优点是优化速度快适合于大数据,缺陷是存在较大的偏差,优化结果的好坏与否取决于最先定义的数簇(如经典的平均场变分数簇)偏差大小。
最大后验概率(MAP)是一种依靠先验知识的计算后验概率的方法,这是一种MAP贝叶斯,并不是全贝叶斯。
作者提出一种新型通用的变分推断算法——Stein变分梯度下降。可以看成是一种用于贝叶斯推断的梯度下降方法。它有以下特点:
- 使用粒子去做分布的估计。
- 是一种梯度下降算法,可以用在任何使用SGD做优化的地方。
- 是一种最小化目标分布和估计分布间KL散度的算法,不断地驱动粒子去拟合(fit)目标分布。
- 算法引入了平滑转换、KSD(Stein方法+RKHS)。
- 是一种全贝叶斯算法。
- 当使用单个粒子的时候,该算法就相当于对MAP做梯度下降;当使用所有的粒子的时候,就是全贝叶斯算法。
- 是一种超越经典VI的新VI算法。
- Stein梯度下降最大的贡献在于:它在再生核希尔伯特空间下给出了使得KL散度下降最快的确定性方向。
2 Background
这里是对贝叶斯中的后验分布 p ( x ) = p ˉ ( x ) / Z p(x)=\bar{p}(x)/Z p(x)=pˉ(x)/Z以及KSD的介绍。KSD有个优点在于通过使用Stein得分函数 ∇ x log p ( x ) \nabla_x\log p(x) ∇xlogp(x)来避免计算归一化因子 Z Z Z。
3 Variational Inference Using Smooth Transforms
VI做模型估计:
目标分布 p ( x ) p(x) p(x),估计分布 q ( x ) q(x) q(x),数簇 Q = { q ( x ) } \mathcal{Q}=\{q(x)\} Q={q(x)},通过优化KL散度来得到估计模型 q ∗ q^* q∗:
q ∗ = arg min q ∈ Q { K L ( q ∣ ∣ p ) = E q [ log q ( x ) ] − E q [ log p ˉ ( x ) ] + log Z } (4) q^*=\argmin_{q\in\mathcal{Q}}\{KL(q||p)=\mathbb{E}_q[\log q(x)]-\mathbb{E}_q[\log\bar{p}(x)]+\log Z\}\tag{4} q∗=q∈Qargmin{KL(q∣∣p)=Eq[logq(x)]−Eq[logpˉ(x)]+logZ}(4)
VI就是通过这种方式来免除归一化因子的计算。问题就是这个数簇 Q \mathcal{Q} Q很难去选择一个合适通用的。
作者指出,合适的 Q \mathcal{Q} Q应该具备以下原则:
- 准确性:广度足够以至于可以近似一系列目标分布。
- 计算可行性:容易去计算,不要整个难以实现的。
- 可解决性:可以和KL散度优化结合起来。
在此基础上,作者引入平滑变换 T : X → X , X ⊂ R d T:\mathcal{X}\to\mathcal{X},\mathcal{X}\subset\mathbb{R}^d T:X→X,X⊂Rd,也就是说将 Q \mathcal{Q} Q看成一个一对一平滑变换 z = T ( x ) , x ∈ X z=T(x),x\in\mathcal{X} z=T(x),x∈X得到的数簇,且 x ∼ q 0 ( x ) x\sim q_0(x) x∼q0(x)。
Note:
- 一对一的原因在于:①必须保证是函数。②如果是多对一的话,就不能保证是增量转换(单调)了,比如如果T是个 y = x 2 y=x^2 y=x2,那么当你粒子 x x x经过好几轮平滑转化之后, q q q已经发生改变了,这时候你从 q q q采样的 x x x经过平滑转换可能就会回到之前发生过的某个 q q q分布了,这是不允许的,因为这样就有点回环曲折的意思,不能保证最快的优化了。
那么经过 T T T之后的数簇是怎么样的呢?利用坐标变换公式可得:
q [ T ] ( z ) = q ( x ) ⋅ ∣ det ( ∂ x ∂ z ) ∣ = q ( T − 1 ( z ) ) ⋅ ∣ det ( ∇ z T − 1 ( z ) ) ∣ q_{[T]}(z)=q(x)\cdot|\det(\frac{\partial x}{\partial z})|=q(T^{-1}(z))\cdot|\det(\nabla_zT^{-1}(z))| q[T](z)=q(x)⋅∣det(∂z∂x)∣=q(T−1(z))⋅∣det(∇zT−1(z))∣其中 det ( ∇ z T − 1 ( z ) ) \det(\nabla_zT^{-1}(z)) det(∇zT−1(z))是矩阵 T − 1 ( z ) T^{-1}(z) T−1(z)的雅克比行列式。
或者反过来:
q [ T − 1 ] ( x ) = q ( T ( x ) ) ⋅ ∣ det ( ∇ x T ( x ) ) ∣ q_{[T^{-1}]}(x) = q(T(x))\cdot|\det(\nabla_xT(x))| q[T−1](x)=q(T(x))⋅∣det(∇xT(x))∣作者指出平滑变化的引入使得准确性和计算可行性满足了,可是可解决性还不能满足,因此一种方法是将 T T T参数化,但参数化将面临3个问题:
- 需要选择合适的参数表示来平衡三个原则。
- 参数化表示不一定能满足T的一对一性。
- 参数化不一定使得Jacobian可以得到有效计算。
参数化既然这么麻烦,作者索性放弃选用了一种不需要参数化表示 T T T的方法——一种迭代式构建增量变化的方法,在RKHS下,可表现出最快的梯度下降方向:
- 该方法不需要计算雅克比矩阵。
- 形式上简单,类似于经典的梯度下降算法,可计算性强。
3.1 Stein Operator as the Derivative of KL Divergence
作者提出了转换的表达式: T ( x ) = x + ϵ ⋅ ϕ ( x ) T(x)=x+\epsilon\cdot\phi(x) T(x)=x+ϵ⋅ϕ(x)。
Note:
- 这个表达式长得很像梯度下降吧,意味着 ϕ ( x ) \phi(x) ϕ(x)代表着方向。
- ϵ \epsilon ϵ是一个很小很小的数。
- ϕ ( x ) \phi(x) ϕ(x)可微,是一个向量。
- 当 ∣ ϵ ∣ |\epsilon| ∣ϵ∣很小的时候。 T ( x ) ≈ x T(x)\approx x T(x)≈x,所以其雅可比矩阵 ∇ x T − 1 \nabla_xT^{-1} ∇xT−1就是个单位阵,显然雅克比行列式不等于0,根据反函数理论,保证了 T T T的单调性,也就保证了一对一。
接下来就是本文最重要的地方之一了。
Lemma1
如果 X ∈ X , X ⊂ R X\in\mathcal{X},\mathcal{X}\subset\mathbb{R} X∈X,X⊂R, F F F是平滑变换,则:
∂ det ( F ( X ) ) ∂ F ( X ) T = det ( F ( X ) ) ⋅ F − 1 ( X ) \frac{\partial{\det(F(X))}}{\partial{F(X)}^T}=\det(F(X))\cdot F^{-1}(X) ∂F(X)T∂det(F(X))=det(F(X))⋅F−1(X)证明如下:

Note:
- 求导对象 x x x必须是
方阵。
Lemma2
如果 p ( x ) 、 q ( x ) p(x)、q(x) p(x)、q(x)都是光滑的函数, x ∈ X x\in\mathcal{X} x∈X, T = T ϵ ( x ) T=T_\epsilon(x) T=Tϵ(x)是个一对一的转换函数,且对 x , ϵ x,\epsilon x,ϵ都可微, s p ( x ) s_p(x) sp(x)为Stein得分函数, q [ T ] q_{[T]} q[T]是 x ∼ q x\sim q x∼q时 z = T ϵ ( x ) z=T_\epsilon(x) z=Tϵ(x)的概率密度函数,则:
∇ ϵ K L ( q [ T ] ∣ ∣ p ) = E q [ s p T ( T ( x ) ) ∇ ϵ T ( x ) + t r ( ( ∇ x T ( x ) ) − 1 ⋅ ( ∇ ϵ ∇ x T ( x ) ) ) ] \nabla_\epsilon KL(q[T]||p)=\mathbb{E}_q[s_p^T(T(x))\nabla_\epsilon T(x)+ tr((\nabla_xT(x))^{-1}\cdot(\nabla_\epsilon\nabla_xT(x)))] ∇ϵKL(q[T]∣∣p)=Eq[spT(T(x))∇ϵT(x)+tr((∇xT(x))−1⋅(∇ϵ∇xT(x)))]证明如下:

Note:
- 画红色的转置 T T T和迹 t r tr tr是为了输出格式的需要。
- 原论文补充材料中的推导对最后的结果漏了一个转置符 T T T。
Theorem 3.1.
T ( x ) = x + ϵ ⋅ ϕ ( x ) T(x)=x+\epsilon\cdot\phi(x) T(x)=x+ϵ⋅ϕ(x),平滑变换 z = T ( x ) z=T(x) z=T(x)以及未知分布 q [ T ] ( z ) q_{[T]}(z) q[T](z),当 x ∼ p ( x ) x\sim p(x) x∼p(x)时,有
∇ ϵ K L ( q [ T ] ∣ ∣ p ) ∣ ϵ = 0 = − E x ∼ q [ t r ( A p ϕ ( x ) ) ] (5) \nabla_\epsilon KL(q_{[T]}||p)|_{\epsilon=0}=-\mathbb{E}_{x\sim q}[tr(\mathcal{A}_p\phi(x))]\tag{5} ∇ϵKL(q[T]∣∣p)∣ϵ=0=−Ex∼q[tr(Apϕ(x))](5)证明如下:
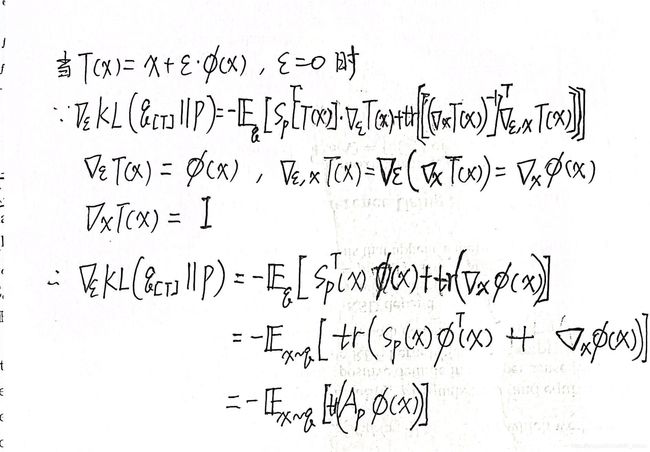
Note:
- A p ϕ ( x ) = s p ϕ ( x ) T + ∇ x ϕ ( x ) \mathcal{A}_p\phi(x)=s_p\phi(x)^T+\nabla_x\phi(x) Apϕ(x)=spϕ(x)T+∇xϕ(x)
- 这里和KSD的原论文相反,这里是 q q q未知,为估计分布, p p p已知,为目标分布。
- 等式左边涉及到泛函导数、变分法的知识,变分法是专门用于处理泛函问题的工具,相当于微积分法是专门用于处理函数问题的工具,我们要找到使得KL散度下降最快的函数 T T T,这就是典型的泛函问题,我们求的是泛函极值问题,所以该问题就是变分问题。
- 等式右边是个和KSD相关的东西,等式左边代表着KL散度的方向导数。这个怎么理解呢?根据泛函分析,左边的表达式如果等于0的话,意味着此时KL散度取得极值,但由于 ϵ = 0 \epsilon=0 ϵ=0之后仍然会有变量 x x x的存在,所以这一次你右边不会等于一个0,那 ϵ = 0 \epsilon=0 ϵ=0出来的是什么呢?
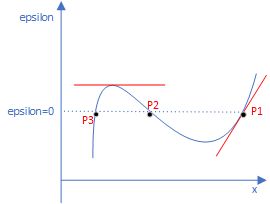
如上图所示,可以把KL散度理解为一个二元的函数 F ( x , ϵ ) F(x,\epsilon) F(x,ϵ),实际上的图应该是个立体的,有许多个小山坡,这只是简易表示。分析:式(5)左边这是一个对 ϵ \epsilon ϵ的偏导数,即只关于 ϵ \epsilon ϵ的斜率。式(5)表达的就是点P的情况,也就是说KL散度关于 ϵ \epsilon ϵ的斜率是个和变量 x x x有关的值,但可以是这条曲线上的P1、P2、P3点的斜率值,具体哪个取决于 x x x的值,但如上面所说,实际上是立体图,也就是说确定了 x x x,即确定了哪个P点之后,比如确定了P1,那么立体图上这个斜率是有无数多种的,沿着不同方向有不同的变化率,这其实就是方向导数!所以式(5)就是方向导数,一看到方向导数,就想到了梯度,它是方向导数的最大值,也是变化率最大的方向,巧的是式(5)右边就是个能进行优化求出最大值的表达式,当 ϕ ( x ) \phi(x) ϕ(x)取特定的值,右边就能达到最大。至于这个“负号”,并不碍事,我们在利用式(5)的时候,只是表示从上升最快转成下降最快而已,这样便于KL梯度下降,梯度的反方向就是下降最快的方向。
Lemma 3.2.
如果所有的方向 ϕ ( x ) \phi(x) ϕ(x)都在球内: B = { ϕ ∈ H d : ∣ ∣ ϕ ∣ ∣ H d 2 ≤ S ( q , p ) } \mathcal{B}=\{\phi\in\mathcal{H}^d:||\phi||^2_{\mathcal{H}^d}\leq\mathbb{S}(q,p)\} B={ϕ∈Hd:∣∣ϕ∣∣Hd2≤S(q,p)},则在这些方向中能最大化式(5)中那个负梯度的方向为:
ϕ ∗ ( ⋅ ) = E x ∼ q [ s p ( x ) k ( x , ⋅ ) + ∇ x k ( x , ⋅ ) ] = E x ∼ q [ A p k ( x , ⋅ ) ] (6) \phi^*(\cdot)=\mathbb{E}_{x\sim q}[s_p(x)k(x,\cdot)+\nabla_xk(x,\cdot)]=\mathbb{E}_{x\sim q}[\mathcal{A}_pk(x,\cdot)]\tag{6} ϕ∗(⋅)=Ex∼q[sp(x)k(x,⋅)+∇xk(x,⋅)]=Ex∼q[Apk(x,⋅)](6)Note:
- ϕ = ϕ ( ⋅ ) , k ( x , ⋅ ) \phi=\phi(\cdot),k(x,\cdot) ϕ=ϕ(⋅),k(x,⋅)都表示向量。
- s p s_p sp为Stein得分函数。
- 这个引理来自于KSD那篇论文的Theorem3.8。
- 式(6)和论文中的不太一样,从我的理解角度看,论文中表达的意思应该就是我这里式(6)写的那样。
- 当 ϕ = ϕ ∗ \phi=\phi^* ϕ=ϕ∗的时候,式(5)就相当于: ∇ ϵ K L ( q [ T ] ∣ ∣ p ) ∣ ϵ = 0 = − S ( p , q ) \nabla_\epsilon KL(q_{[T]}||p)|_{\epsilon=0}=-\mathbb{S}(p,q) ∇ϵKL(q[T]∣∣p)∣ϵ=0=−S(p,q)。换句话说当 ϕ = ϕ ∗ \phi=\phi^* ϕ=ϕ∗的时候,是KL散度下降最快的方向。
当 ϕ \phi ϕ取最优值 ϕ ∗ \phi^* ϕ∗的时候,只要变量沿着方向 ϕ ∗ \phi^* ϕ∗移动 ϵ ⋅ S ( q , p ) \epsilon\cdot\mathbb{S(q,p)} ϵ⋅S(q,p),就可以使得KL散度以最快的速度下降(从这里也看出了 ϕ ( x ) \phi(x) ϕ(x)代表着方向)。同时,平滑转换 T = x + ϵ ⋅ ϕ ∗ ( x ) T=x+\epsilon\cdot\phi^*(x) T=x+ϵ⋅ϕ∗(x)。总的流程用一个动态过程表示为:
起始分布 q 0 q_0 q0;
第一次梯度下降: T 0 ∗ ( x ) = x + ϵ 0 ⋅ ϕ q 0 , p ∗ ( x ) ; q 1 ( x ) = q 0 [ T 0 ∗ ] ( x ) T^*_0(x)=x+\epsilon_0\cdot\phi^*_{q_0,p}(x);q_1(x)=q_{0[T_0^*]}(x) T0∗(x)=x+ϵ0⋅ϕq0,p∗(x);q1(x)=q0[T0∗](x);
第二次梯度下降: T 1 ∗ ( x ) = x + ϵ 1 ⋅ ϕ q 1 , p ∗ ( x ) ; q 2 ( x ) = q 1 [ T 1 ∗ ] ( x ) T^*_1(x)=x+\epsilon_1\cdot\phi^*_{q_1,p}(x);q_2(x)=q_{1[T_1^*]}(x) T1∗(x)=x+ϵ1⋅ϕq1,p∗(x);q2(x)=q1[T1∗](x);
… … …直至收敛
总结起来就是:
q l + 1 = q l [ T l ∗ ] , T l ∗ ( x ) = x + ϵ l ⋅ ϕ q l , p ∗ ( x ) (7) q_{l+1}=q_{l[T^*_l]},T^*_l(x)=x+\epsilon_l\cdot\phi^*_{q_l,p}(x)\tag{7} ql+1=ql[Tl∗],Tl∗(x)=x+ϵl⋅ϕql,p∗(x)(7)Note:
- T , q T,q T,q的不断迭代也显示了平滑转换一对一性的重要,因此 ϵ \epsilon ϵ要足够小。
- 最终KL散度会因为不断减小而为0, q q q会收敛到目标分布 p p p,当且仅当 ϕ p , q ∞ ∗ ( x ) = 0 \phi^*_{p,q^\infty}(x)=0 ϕp,q∞∗(x)=0
Functional Gradient(泛函梯度)
设 f 、 g ∈ H d \mathbf{f}、\mathbf{g}\in\mathcal{H}^d f、g∈Hd,则 F [ f ] F[f] F[f]就是泛函, ∇ f F [ f ] \nabla_\mathbf{f}F[\mathbf{f}] ∇fF[f]就是泛函梯度,其有如下结论: F [ f + ϵ g ( x ) ] = F [ f ] + ϵ < ∇ f F [ f ] , g > H d + O ( ϵ 2 ) F[\mathbf{f}+\epsilon\mathbf{g}(x)]=F[f]+\epsilon<\nabla_\mathbf{f}F[\mathbf{f}],\mathbf{g}>_{\mathcal{H}^d}+O(\epsilon^2) F[f+ϵg(x)]=F[f]+ϵ<∇fF[f],g>Hd+O(ϵ2)。
Theorem 3.3.
设 T ( x ) = x + f ( x ) , x ∈ R d , f ∈ H d T(x)=x+\mathbf{f}(x),x\in\mathbb{R}^d,\mathbf{f}\in\mathcal{H}^d T(x)=x+f(x),x∈Rd,f∈Hd,则:
∇ f K L ( q [ T ] ∣ ∣ p ) ∣ f = 0 = − ϕ q , p ∗ ( x ) \nabla_{\mathbf{f}}KL(q_{[T]}||p)|_{\mathbf{f}=0}=-\phi^*_{q,p}(x) ∇fKL(q[T]∣∣p)∣f=0=−ϕq,p∗(x)Note:
- 这个式子我最终没有证明出来,看过作者在补充材料的证明是有问题的,要么就是矩阵向量前后大小对不上,要么就是最后部分漏东西,最后 f = 0 \mathbf{f}=0 f=0带进去也是得不出 ϕ ∗ = E x ∼ q ( x ) [ A p k ( x , ⋅ ) ] \phi^*=\mathbb{E}_{x\sim q(x)}[\mathcal{A}_pk(x,\cdot)] ϕ∗=Ex∼q(x)[Apk(x,⋅)]这个结果的,只能证明到 E x ∼ q ( x ) [ t r ( A p k ( x , ⋅ ) ) ] \mathbb{E}_{x\sim q(x)}[tr(\mathcal{A}_pk(x,\cdot))] Ex∼q(x)[tr(Apk(x,⋅))]。
- 以下是我的证明:
 接下来需要用到向量矩阵的Taylor展开(和高数中的略有不同):
接下来需要用到向量矩阵的Taylor展开(和高数中的略有不同):
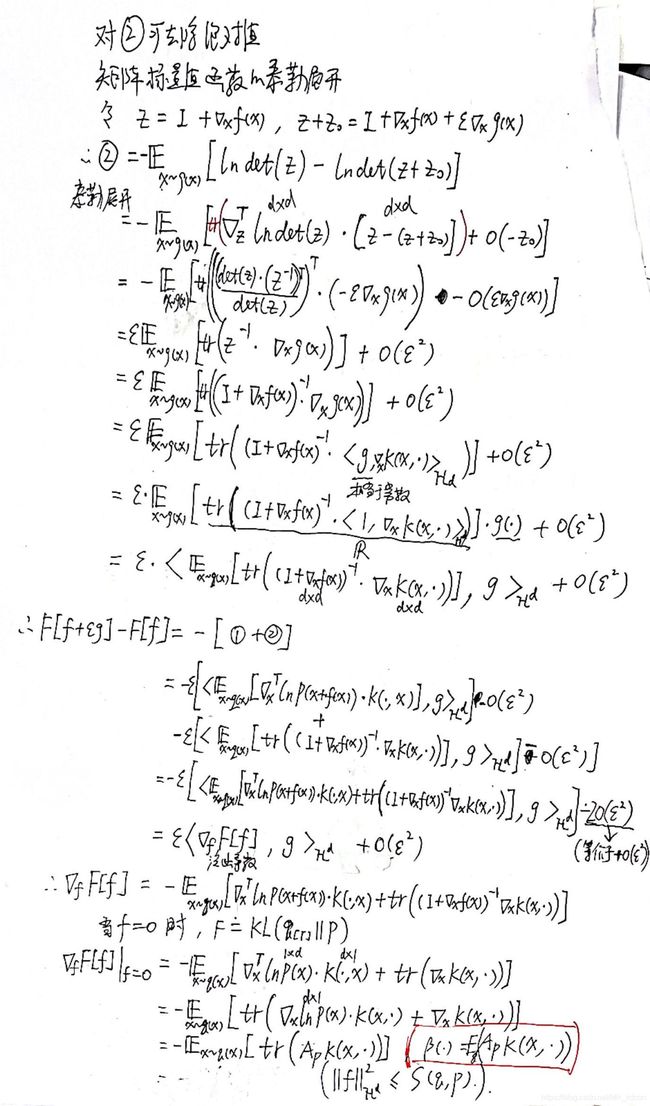 总之感觉作者在凑这个 ϕ ∗ \phi^* ϕ∗,这个Theorem 3.3应该算错的,因此下面关于这个定理的就不分析了。不过好在这个定理的好坏并不影响Algorithm1,即Stein变分梯度下降。
总之感觉作者在凑这个 ϕ ∗ \phi^* ϕ∗,这个Theorem 3.3应该算错的,因此下面关于这个定理的就不分析了。不过好在这个定理的好坏并不影响Algorithm1,即Stein变分梯度下降。 - 另外需要注意的是,我们一般向量内积或者矩阵内积的结果都是实值,默认都是大小一样的且向量必须同为行或者列向量,矩阵内积必须均为方阵。如果 < A , B >
3.2 Stein Variational Gradient Descent
算法的伪代码如下:

- 伪码简洁明了,左边是公式(7),不断更新粒子(可以理解成样本)来改变初始分布 q 0 q_0 q0。
- 粒子 { x i l } i = 1 n \{x_i^l\}^n_{i=1} {xil}i=1n表示第 l l l次迭代的第 i i i个粒子,一个 n n n个。粒子最开始是从分布 q 0 q_0 q0中采样的,最初的分布 q q q是不准确的并且可以是任意的。也就是说,该算法不依赖于初始的分布。
- 准确的说,粒子的统计分布就是 q ( x ) q(x) q(x)。比如第 l l l次迭代,统计粒子的均值、方差构成高斯分布 p ( x ) p(x) p(x)。伪代码所做的就是用这些粒子去拟合目标分布 p ( x ) p(x) p(x)。
- 右边是公式(6)的近似表示,用样本均值作为期望的估计值,这是常用的做法了。
- 算法模仿了我们所熟知的梯度上升,之前说过, ϕ \phi ϕ代表了梯度方向,为KL散度下降最快的方向。该算法的梯度上升模式是粒子级别的,我们之前接触比较多的神经网络,梯度上升都是参数级别的。
- 公式(8)的Part1和Part2类似于与探索与利用这种相互排斥的操作。首先Part1的 ∇ \nabla ∇部分,粒子会朝着 p p p分布概率高的地方移动,但这样容易陷入局部最优,不要以为SVGD就不会陷入局部最优了,SVGD确实保证了每一步都向着KL减小最快的方向移动,这当然包括局部最小和全局最小,所以是否陷入局部最优和算法优化速度快慢是两回事。至于Part2的 ∇ \nabla ∇部分,作者举了个RBF核的例子: k ( x , x ′ ) = exp ( − 1 h ∣ ∣ x − x ′ ∣ ∣ 2 ) k(x,x')=\exp(-\frac{1}{h}||x-x'||^2) k(x,x′)=exp(−h1∣∣x−x′∣∣2),经过Part2的处理后: ∑ j 2 h ( x − x j ) k ( x j , x ) \sum_j\frac{2}{h}(x-x_j)k(x_j, x) ∑jh2(x−xj)k(xj,x),这一项代表着粒子将会朝着远离当前迭代轮数 l l l的粒子,从而减轻局部最优的风险。同样是这个高斯核,当 h → 0 h\to0 h→0,那么这个排斥作用就没了,只剩下了Part1,那么粒子都会朝着最大化 log p ( x ) \log p(x) logp(x)移动,这也就是
MAP,从而陷入局部最优。 - 当n=1的时候,算法就演变成了对MAP做梯度上升。
- 算法中给出了确定性的下降方法,远远的优于传统的MCMC算法MCMC算法中使用随机性的方法来增加粒子的多样性,在Stein 变分中根本就不需要。
提高计算效率的方法
核心思想:下采样。
下采样在信号中是对于一个样值序列隔几个样值采样一次。对图像来说,下采样就是对于一副图像I尺寸为 M × N M\times N M×N,对起进行s倍下采样,即得到 ( M / s ) × ( N / s ) (M/s)\times(N/s) (M/s)×(N/s)尺寸的分辨率图像。通俗来说就是采样少部分的样本来近似达到大样本的效果,并且减小计算量。
公式(8)计算的瓶颈在于 ∇ x log p ( x ) , x ∈ { x i } i = 1 n \nabla_x\log p(x),x\in\{x_i\}^n_{i=1} ∇xlogp(x),x∈{xi}i=1n。其中 p ( x ) ∝ p 0 ( x ) ∏ k = 1 N p ( D k ∣ x ) p(x)\propto p_0(x)\prod^N_{k=1}p(D_k|x) p(x)∝p0(x)∏k=1Np(Dk∣x),当数据量 N N N很大的时候,计算复杂度就会很高。作者提出用下采样 Ω ⊂ { 1 , ⋯ , N } \Omega\subset\{1,\cdots,N\} Ω⊂{1,⋯,N}来近似估计 ∇ x log p ( x ) \nabla_x\log p(x) ∇xlogp(x)。本文中的下采样是这样的:
log p ( x ) ≈ log p 0 ( x ) + N ∣ Ω ∣ ∑ k ∈ Ω log p ( D k ∣ x ) . (9) \log p(x)\approx\log p_0(x)+\frac{N}{|\Omega|}\sum_{k\in\Omega}\log p(D_k|x).\tag{9} logp(x)≈logp0(x)+∣Ω∣Nk∈Ω∑logp(Dk∣x).(9)设 ∇ x log p ( x ) \nabla_x\log p(x) ∇xlogp(x)在全粒子上的统计结果为 R R R,在下采样的表现为 G G G,它的原理就是:
N Ω = R G \frac{N}{\Omega}=\frac{R}{G} ΩN=GR用局部代替整体。
Note:
- 遇到大数据 N N N且需要计算 ∑ i = 1 N \sum_{i=1}^N ∑i=1N的时候,可采用下采样减小计算复杂度。
4 Related Works
略
5 Experiments
略
6 Conclusion
总结:
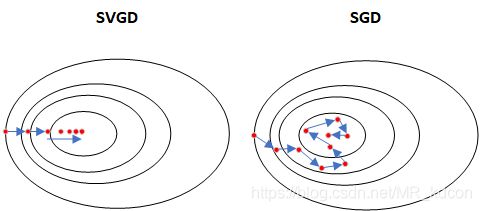
- Stein变分梯度下降是这样的:首先我们需要用粒子拟合的估计分布 q ( x ) q(x) q(x)通过不断迭代靠近目标分布 p ( x ) p(x) p(x),每一次迭代都是一次平滑变化 T T T,平滑变化有很多种,我们要找到使得KL散度下降最快的变化方向(梯度)。因此我们的计算过程其实就优化函数中的出一个最优函数,这就是泛函问题中求泛函极值问题,我们通常使用变分法求解。
- 本文提出的Stein变分梯度下降是结合了Stein方法,并在RKHS空间下进行梯度下降的(优化),即使用了KSD核差异技术。
- Stein变分梯度下降算法使用了粒子层次化的方式不断使2个分布接近一致。从上图2种优化算法的参数轨迹曲线可以看出。
- SVGD显然比我们最先接触到的机器学习经典优化算法——SGD具有更快的收敛速度。SVGD是确定性的优化算法,而SGD是随机性的优化算法,其优化方向取决于样本,有随机性,因此稳定性会打折扣,同时收敛速度收到削弱。
- SVGD的S指的是Stein;SGD的S指的是Stochastic。
- SVGD是一种变分推断VI的新方法,可广泛用于快速贝叶斯推断。
Stein变分梯度下降的优缺点:
优点:
- Stein方法通过Stein得分函数有效化解掉归一化因子。
- Stein特征可以消除未知分布无法计算的问题。
- 引入KSD,推导出使得KL散度下降最快的方向就是核差异方向 ϕ ∗ \phi^* ϕ∗,这是一种
确定性方向,有效增加优化的速度和效率(分析见上)。不像传统的随机性方法,需要通过随机性来增加粒子多样性。 - 梯度方向 ϕ ∗ \phi^* ϕ∗的近似包含正则化,避免陷入局部最优。
- 算法不依赖于初始化粒子是怎么样的,无论如何都会走向复杂的分布,一般都是接近全局最优的局部最优。
缺点:
- 计算复杂度高。
源码解析
关于裸的SVGD代码地址在本文顶部
main.py如下:
A = np.array([[0.2260,0.1652],[0.1652,0.6779]])
mu = np.array([-0.6871,0.8010])
model = MVN(mu, A)
x0 = np.random.normal(0,1, [10,2]);
theta = SVGD().update(x0, model.dlnprob, n_iter=1000, stepsize=0.01)
print("ground truth: ", mu)
print("svgd: ", np.mean(theta,axis=0))
- A是目标分布的协方差,mu是目标分布的均值,model是一个二维高斯分布。
- x0是初始分布 q 0 q_0 q0为一维正态分布采样的10个粒子。将10个粒子送进SVGD的核心代码(Algorithm1)中,输出经过1000次迭代后的的10个粒子分布情况, ϵ = 0.01 \epsilon=0.01 ϵ=0.01,他们的样本均值就是估计分布的均值。
- 三次试验结果如下:
①
ground truth: [-0.6871 0.801 ]
svgd: [-0.68622667 0.80359776]
②
ground truth: [-0.6871 0.801 ]
svgd: [-0.68865996 0.7990209 ]
③
ground truth: [-0.6871 0.801 ]
svgd: [-0.6861909 0.80438672]
可见SVGD的有效性。