Region Proposal Network
Region Proposal Network
-
-
-
- Region Proposal Network
- 模型配置文件概览
- 网络分析
- RPNHead
-
- 1.配置输入
- 2.代码架构概览(主要是先宏观看看Head的网络架构)
- 3.代码分析(这里是分析Head从self.rpn_head = build_head(rpn_head)语句开始的详细初始化过程)
-
- 1.执行RPNHead的Init函数
- 2.跳转到AnchorHead的init函数
- 3.跳转到BaseDenseHead的init函数
- 4.继续执行AnchorHead初始化函数
- 5.引用到4中的编码器初始化函数
- 6.引用到4中的分类损失初始化函数
- 7.引用到4中的回归损失初始化函数
- 8.引用到4中的分配器初始化函数
- 9.引用到4中的采样器初始化函数
- 10.引用到4中的anchor生成器初始化函数
- 4.Head前向传播
-
- 1.RPN网络的前向传播
- 2.链接到1中的「一」方法:通过骨架与颈部提取特征
- 3.链接到1中的「二」方法:通过网络头部计算损失值
- 4.链接到3中的「三」方法:将FPN的输出传入到头部网络中,进行前向推理
- 5.链接到4中的「四」方法:用partial对象,分别将FPN的输出(5,)中的每一个特征图传入到self.forward_single函数中,再对输出结果取一个元组,所以最后的返回结果是(分类得分,边界框回归)
- 6.链接到5中的「五」方法:首先通过rpn_conv函数将FPN输出的单个特征图进行维度转换,转换到统一的channels数量,方便后续进行分类rpn_cls预测和rpn_reg预测,分类结果形状为(N, num_anchors * num_classes, H, W),边框回归结果形状为(N, num_anchors * 4, H, W)
- 7.链接到3中的「六」方法:根据gt框和outs计算loss
- 8.链接到7中的「七」方法:调用父类的loss前向传播函数
- 9.链接到8中的「八」方法:根据特征图大小获取anchors
- 10.链接到9中的「九」方法:生成anchors
- 11.链接到10中的「十」方法:单个特征图生成anchors方法
- 12.链接到9中的「十一」方法:计算有效项
- 13.链接到8中的「十二」方法:获取到正负样本
- 14.链接到13中的「十三」方法:多项提交同时计算多个目标(当batch_size>1时)
- 15.链接到14中的「十四」方法:
- 16.链接到14中的「十五」方法:
- 17.链接到16中的「十六」方法:
- 18.链接到16中的「十七」方法:
- 19.链接到18中的「十八」方法:
- 20.链接到14中的「十九」方法:
- 21.链接到20中的「二十」方法:
- 22.链接到20中的「二十一」方法:
- 23.链接到20中的「二十二」方法:
- 24.链接到14中的「二十三」方法:
- 25.链接到24中的「二十四」方法:
- RPN网络的全流程图示
-
- 1.RPN网络的初始化
- Reference
-
-
Region Proposal Network
在RPN网络中,我们首先生成区域候选框,以往的算法例如RCNN网络会采用选择性搜索(selective search)来实现区域候选框的生成,缺点是其计算成本高昂切需要人工调试,所以需要我们今天所讨论的主角RPN网络以另一种方式帮助我们快速根据Anchor生成区域候选框,在区域候选框生成后,我们需要对每个候选框进行Assign,在对其做Sample样本均衡化,进而对其做分类任务,这是目标检测方法的主要分支之一,另一个分支是对边界框的宽高及中心偏移量进行回归任务(例如SSD)。
模型配置文件概览
model = dict(
type='RPN',
pretrained='torchvision://resnet50', #使用预训练模型
backbone=dict(
type='ResNet',
depth=50, #深度50层
num_stages=4, #网络分为4个阶段
out_indices=(0, 1, 2, 3), #提取特征图的阶段下标,这里指提取每个阶段的输出特征图
frozen_stages=1, #冻结预训练模型的特征图权重,这里为1,指的是冻结第二层提取特征图的权重
norm_cfg=dict(type='BN', requires_grad=True), #标准化配置,多卡训练用SyncBN
norm_eval=True,
style='pytorch'),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048], # 骨架多尺度特征图输出通道
out_channels=256, # 增强后通道输出
num_outs=5), # 输出num_outs个多尺度特征图
rpn_head=dict(
type='RPNHead',
in_channels=256, #
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0)))
train_cfg = dict(
rpn=dict(
assigner=dict(
type='MaxIoUAssigner',
pos_iou_thr=0.7,
neg_iou_thr=0.3,
min_pos_iou=0.3,
ignore_iof_thr=-1),
sampler=dict(
type='RandomSampler',
num=256,
pos_fraction=0.5,
neg_pos_ub=-1,
add_gt_as_proposals=False),
allowed_border=0,
pos_weight=-1,
debug=False))
网络分析
- 根据配置信息,简述网络。
| 组件 | 名称 |
|---|---|
| Backbone | ResNet |
| Neck | FPN |
| Head | RPNHead |
| BBox Assigner | MaxIoUAssigner |
| BBox Sampler | RandomSampler |
| BBox Encoder | DeltaXYWHBBoxCoder |
| Loss | loss_cls(CrossEntropyLoss),loss_bbox(L1Loss) |
- RPN解决了什么问题?
RPN第一次出现在世人眼中是在Faster RCNN这个结构中,专门用来提取候选框,在RCNN和Fast RCNN等物体检测架构中,用来提取候选框的方法通常是Selective Search,是比较传统的方法,而且比较耗时,在CPU上要2s一张图。所以作者提出RPN,专门用来提取候选框,一方面RPN耗时少,另一方面RPN可以很容易结合到Fast RCNN中,称为一个整体。
- 提出了哪些创新点?
- 仍有哪些不足?
- 应用场景有哪些?
RPNHead
1.配置输入
rpn_head=dict(
type='RPNHead',
in_channels=256,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
target_means=[0.0, 0.0, 0.0, 0.0],
target_stds=[1.0, 1.0, 1.0, 1.0]),
loss_cls=dict(
type='CrossEntropyLoss', use_sigmoid=True, loss_weight=1.0),
loss_bbox=dict(type='L1Loss', loss_weight=1.0))
2.代码架构概览(主要是先宏观看看Head的网络架构)
1.rpn_head.py
class RPNHead(RPNTestMixin, AnchorHead):
"""RPN head.
Args:
in_channels (int): Number of channels in the input feature map.
""" # noqa: W605
# 初始化RPN头部网络,继承自 RPNTestMixin, AnchorHead
def __init__(self, in_channels, **kwargs):
super(RPNHead, self).__init__(1, in_channels, **kwargs)
def _init_layers(self):
"""Initialize layers of the head."""
...
def init_weights(self):
"""Initialize weights of the head."""
...
def forward_single(self, x):
"""Forward feature map of a single scale level."""
...
return rpn_cls_score, rpn_bbox_pred
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
...
return dict(
loss_rpn_cls=losses['loss_cls'], loss_rpn_bbox=losses['loss_bbox'])
def _get_bboxes_single(self,
cls_scores,
bbox_preds,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False):
"""Transform outputs for a single batch item into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (num_anchors * num_classes, H, W).
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (num_anchors * 4, H, W).
mlvl_anchors (list[Tensor]): Box reference for each scale level
with shape (num_total_anchors, 4).
img_shape (tuple[int]): Shape of the input image,
(height, width, 3).
scale_factor (ndarray): Scale factor of the image arange as
(w_scale, h_scale, w_scale, h_scale).
cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used.
rescale (bool): If True, return boxes in original image space.
Returns:
Tensor: Labeled boxes in shape (n, 5), where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1.
"""
...
return dets[:cfg.nms_post]
2.anchor_head
@HEADS.register_module()
class AnchorHead(BaseDenseHead, BBoxTestMixin):
"""Anchor-based head (RPN, RetinaNet, SSD, etc.).
Args:
num_classes (int): Number of categories excluding the background
category.
in_channels (int): Number of channels in the input feature map.
feat_channels (int): Number of hidden channels. Used in child classes.
anchor_generator (dict): Config dict for anchor generator
bbox_coder (dict): Config of bounding box coder.
reg_decoded_bbox (bool): If true, the regression loss would be
applied on decoded bounding boxes. Default: False
loss_cls (dict): Config of classification loss.
loss_bbox (dict): Config of localization loss.
train_cfg (dict): Training config of anchor head.
test_cfg (dict): Testing config of anchor head.
""" # noqa: W605
# 继承自 BaseDenseHead,BBoxTestMixin
def __init__(self,
num_classes,
in_channels,
feat_channels=256,
anchor_generator=dict(
type='AnchorGenerator',
scales=[8, 16, 32],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict(
type='DeltaXYWHBBoxCoder',
clip_border=True,
target_means=(.0, .0, .0, .0),
target_stds=(1.0, 1.0, 1.0, 1.0)),
reg_decoded_bbox=False,
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
loss_bbox=dict(
type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
train_cfg=None,
test_cfg=None):
def _init_layers(self):
"""Initialize layers of the head."""
def init_weights(self):
"""Initialize weights of the head."""
def forward_single(self, x):
"""Forward feature of a single scale level.
Args:
x (Tensor): Features of a single scale level.
Returns:
tuple:
cls_score (Tensor): Cls scores for a single scale level \
the channels number is num_anchors * num_classes.
bbox_pred (Tensor): Box energies / deltas for a single scale \
level, the channels number is num_anchors * 4.
"""
...
return cls_score, bbox_pred
def forward(self, feats):
"""Forward features from the upstream network.
Args:
feats (tuple[Tensor]): Features from the upstream network, each is
a 4D-tensor.
Returns:
tuple: A tuple of classification scores and bbox prediction.
- cls_scores (list[Tensor]): Classification scores for all \
scale levels, each is a 4D-tensor, the channels number \
is num_anchors * num_classes.
- bbox_preds (list[Tensor]): Box energies / deltas for all \
scale levels, each is a 4D-tensor, the channels number \
is num_anchors * 4.
"""
return multi_apply(self.forward_single, feats)
def get_anchors(self, featmap_sizes, img_metas, device='cuda'):
"""Get anchors according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
device (torch.device | str): Device for returned tensors
Returns:
tuple:
anchor_list (list[Tensor]): Anchors of each image.
valid_flag_list (list[Tensor]): Valid flags of each image.
"""
...
return anchor_list, valid_flag_list # valid_flags得到在padding以内的值
def _get_targets_single(self,
flat_anchors,
valid_flags,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
img_meta,
label_channels=1,
unmap_outputs=True):
"""Compute regression and classification targets for anchors in a
single image.
Args:
flat_anchors (Tensor): Multi-level anchors of the image, which are
concatenated into a single tensor of shape (num_anchors ,4)
valid_flags (Tensor): Multi level valid flags of the image,
which are concatenated into a single tensor of
shape (num_anchors,).
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
img_meta (dict): Meta info of the image.
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
img_meta (dict): Meta info of the image.
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple:
labels_list (list[Tensor]): Labels of each level
label_weights_list (list[Tensor]): Label weights of each level
bbox_targets_list (list[Tensor]): BBox targets of each level
bbox_weights_list (list[Tensor]): BBox weights of each level
num_total_pos (int): Number of positive samples in all images
num_total_neg (int): Number of negative samples in all images
"""
...
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds, sampling_result)
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
label_channels=1,
unmap_outputs=True,
return_sampling_results=False):
"""Compute regression and classification targets for anchors in
multiple images.
Args:
anchor_list (list[list[Tensor]]): Multi level anchors of each
image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, 4).
valid_flag_list (list[list[Tensor]]): Multi level valid flags of
each image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, )
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
gt_bboxes_ignore_list (list[Tensor]): Ground truth bboxes to be
ignored.
gt_labels_list (list[Tensor]): Ground truth labels of each box.
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple: Usually returns a tuple containing learning targets.
- labels_list (list[Tensor]): Labels of each level.
- label_weights_list (list[Tensor]): Label weights of each \
level.
- bbox_targets_list (list[Tensor]): BBox targets of each level.
- bbox_weights_list (list[Tensor]): BBox weights of each level.
- num_total_pos (int): Number of positive samples in all \
images.
- num_total_neg (int): Number of negative samples in all \
images.
additional_returns: This function enables user-defined returns from
`self._get_targets_single`. These returns are currently refined
to properties at each feature map (i.e. having HxW dimension).
The results will be concatenated after the end
"""
...
return res + tuple(rest_results)
def loss_single(self, cls_score, bbox_pred, anchors, labels, label_weights,
bbox_targets, bbox_weights, num_total_samples):
"""Compute loss of a single scale level.
Args:
cls_score (Tensor): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W).
bbox_pred (Tensor): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W).
anchors (Tensor): Box reference for each scale level with shape
(N, num_total_anchors, 4).
labels (Tensor): Labels of each anchors with shape
(N, num_total_anchors).
label_weights (Tensor): Label weights of each anchor with shape
(N, num_total_anchors)
bbox_targets (Tensor): BBox regression targets of each anchor wight
shape (N, num_total_anchors, 4).
bbox_weights (Tensor): BBox regression loss weights of each anchor
with shape (N, num_total_anchors, 4).
num_total_samples (int): If sampling, num total samples equal to
the number of total anchors; Otherwise, it is the number of
positive anchors.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
...
return loss_cls, loss_bbox
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss. Default: None
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
...
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def get_bboxes(self,
cls_scores,
bbox_preds,
img_metas,
cfg=None,
rescale=False,
with_nms=True):
"""Transform network output for a batch into bbox predictions.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
cfg (mmcv.Config | None): Test / postprocessing configuration,
if None, test_cfg would be used
rescale (bool): If True, return boxes in original image space.
Default: False.
with_nms (bool): If True, do nms before return boxes.
Default: True.
Returns:
list[tuple[Tensor, Tensor]]: Each item in result_list is 2-tuple.
The first item is an (n, 5) tensor, where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1. The second item is a
(n,) tensor where each item is the predicted class labelof the
corresponding box.
Example:
>>> import mmcv
>>> self = AnchorHead(
>>> num_classes=9,
>>> in_channels=1,
>>> anchor_generator=dict(
>>> type='AnchorGenerator',
>>> scales=[8],
>>> ratios=[0.5, 1.0, 2.0],
>>> strides=[4,]))
>>> img_metas = [{'img_shape': (32, 32, 3), 'scale_factor': 1}]
>>> cfg = mmcv.Config(dict(
>>> score_thr=0.00,
>>> nms=dict(type='nms', iou_thr=1.0),
>>> max_per_img=10))
>>> feat = torch.rand(1, 1, 3, 3)
>>> cls_score, bbox_pred = self.forward_single(feat)
>>> # note the input lists are over different levels, not images
>>> cls_scores, bbox_preds = [cls_score], [bbox_pred]
>>> result_list = self.get_bboxes(cls_scores, bbox_preds,
>>> img_metas, cfg)
>>> det_bboxes, det_labels = result_list[0]
>>> assert len(result_list) == 1
>>> assert det_bboxes.shape[1] == 5
>>> assert len(det_bboxes) == len(det_labels) == cfg.max_per_img
"""
...
return result_list
def _get_bboxes_single(self,
cls_score_list,
bbox_pred_list,
mlvl_anchors,
img_shape,
scale_factor,
cfg,
rescale=False,
with_nms=True):
"""Transform outputs for a single batch item into bbox predictions.
Args:
cls_score_list (list[Tensor]): Box scores for a single scale level
Has shape (num_anchors * num_classes, H, W).
bbox_pred_list (list[Tensor]): Box energies / deltas for a single
scale level with shape (num_anchors * 4, H, W).
mlvl_anchors (list[Tensor]): Box reference for a single scale level
with shape (num_total_anchors, 4).
img_shape (tuple[int]): Shape of the input image,
(height, width, 3).
scale_factor (ndarray): Scale factor of the image arange as
(w_scale, h_scale, w_scale, h_scale).
cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used.
rescale (bool): If True, return boxes in original image space.
Default: False.
with_nms (bool): If True, do nms before return boxes.
Default: True.
Returns:
Tensor: Labeled boxes in shape (n, 5), where the first 4 columns
are bounding box positions (tl_x, tl_y, br_x, br_y) and the
5-th column is a score between 0 and 1.
"""
...
if with_nms:
det_bboxes, det_labels = multiclass_nms(mlvl_bboxes, mlvl_scores,
cfg.score_thr, cfg.nms,
cfg.max_per_img)
return det_bboxes, det_labels
else:
return mlvl_bboxes, mlvl_scores
def aug_test(self, feats, img_metas, rescale=False):
"""Test function with test time augmentation.
Args:
feats (list[Tensor]): the outer list indicates test-time
augmentations and inner Tensor should have a shape NxCxHxW,
which contains features for all images in the batch.
img_metas (list[list[dict]]): the outer list indicates test-time
augs (multiscale, flip, etc.) and the inner list indicates
images in a batch. each dict has image information.
rescale (bool, optional): Whether to rescale the results.
Defaults to False.
Returns:
list[ndarray]: bbox results of each class
"""
return self.aug_test_bboxes(feats, img_metas, rescale=rescale)
3.base_dense_head.py
class BaseDenseHead(nn.Module, metaclass=ABCMeta):
"""Base class for DenseHeads."""
def __init__(self):
super(BaseDenseHead, self).__init__()
@abstractmethod
def loss(self, **kwargs):
"""Compute losses of the head."""
pass
@abstractmethod
def get_bboxes(self, **kwargs):
"""Transform network output for a batch into bbox predictions."""
pass
def forward_train(self,
x,
img_metas,
gt_bboxes,
gt_labels=None,
gt_bboxes_ignore=None,
proposal_cfg=None,
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
proposal_list (list[Tensor]): Proposals of each image.
"""
outs = self(x) # 得到卷积后的输出
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore)
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
3.代码分析(这里是分析Head从self.rpn_head = build_head(rpn_head)语句开始的详细初始化过程)
RPNHead的初始化
1.执行RPNHead的Init函数
class RPNHead(RPNTestMixin, AnchorHead):
# 初始化函数,in_channels(int)是输入特征图的维度数,随后进入到AnchorHead类的初始化方法;
def __init__(self, in_channels, **kwargs):
super(RPNHead, self).__init__(1, in_channels, **kwargs)
2.跳转到AnchorHead的init函数
class AnchorHead(BaseDenseHead, BBoxTestMixin):
def __init__(self,
num_classes, #类别数
in_channels, #输入特征图的维度
feat_channels=256,
anchor_generator=dict( #anchor生成器的配置信息
type='AnchorGenerator',
scales=[8, 16, 32],
ratios=[0.5, 1.0, 2.0],
strides=[4, 8, 16, 32, 64]),
bbox_coder=dict( # bbox编码器的配置信息
type='DeltaXYWHBBoxCoder',
clip_border=True,
target_means=(.0, .0, .0, .0),
target_stds=(1.0, 1.0, 1.0, 1.0)),
reg_decoded_bbox=False,
loss_cls=dict( # 分类的损失函数
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=1.0),
loss_bbox=dict( #回归损失函数
type='SmoothL1Loss', beta=1.0 / 9.0, loss_weight=1.0),
train_cfg=None, # 获取到Assigner和Sampler的配置信息(训练模式)
test_cfg=None): # 获取到BBox Decoder和BBox PostProcess的配置信息(测试模式)
super(AnchorHead, self).__init__()
3.跳转到BaseDenseHead的init函数
class BaseDenseHead(nn.Module, metaclass=ABCMeta):
"""Base class for DenseHeads."""
# BaseDenseHead的初始化方法,主要有loss,get_bboxes,forward_train方法的抽象类
def __init__(self):
super(BaseDenseHead, self).__init__()
4.继续执行AnchorHead初始化函数
class AnchorHead(BaseDenseHead, BBoxTestMixin):
# 常规赋值
self.in_channels = in_channels
self.num_classes = num_classes
self.feat_channels = feat_channels
self.use_sigmoid_cls = loss_cls.get('use_sigmoid', False) # 是否使用sigmoid分类
# TODO better way to determine whether sample or not
# 这里是判断是否是不需要进行正负样本采样的回归损失,例如使用FocalLoss不需要进行头部的采样
self.sampling = loss_cls['type'] not in [
'FocalLoss', 'GHMC', 'QualityFocalLoss'
]
if self.use_sigmoid_cls:
self.cls_out_channels = num_classes
else:
self.cls_out_channels = num_classes + 1
if self.cls_out_channels <= 0:
raise ValueError(f'num_classes={num_classes} is too small')
self.reg_decoded_bbox = reg_decoded_bbox
# 初始化编码器
self.bbox_coder = build_bbox_coder(bbox_coder)「5」 # 编码器,对label进行编码然后进行loss计算
self.loss_cls = build_loss(loss_cls) 「6」 # 分类损失
self.loss_bbox = build_loss(loss_bbox) 「7」 # 边框回归损失
self.train_cfg = train_cfg # 更新训练配置信息获取到Assigner和Sampler
self.test_cfg = test_cfg # 更新测试配置信息获取到获取到BBox Decoder和BBox PostProcess
if self.train_cfg:
# 分类问题样本不均衡问题,为了解决不均衡的问题,需要首先划分进而确定正负样本,再使用一些方法来解决不均衡的问题,比如说采样
self.assigner = build_assigner(self.train_cfg.assigner)「8」# 初始化正负样本属性分配模块
# use PseudoSampler when sampling is False
# 若没有指定采样器默认采取PseudoSampler
if self.sampling and hasattr(self.train_cfg, 'sampler'):
sampler_cfg = self.train_cfg.sampler
else:
sampler_cfg = dict(type='PseudoSampler')
self.sampler = build_sampler(sampler_cfg, context=self) 「9」# 初始化采样器
self.fp16_enabled = False
self.anchor_generator = build_anchor_generator(anchor_generator) 「10」 # 初始化anchor生成器
# usually the numbers of anchors for each level are the same
# except SSD detectors
# 计算
self.num_anchors = self.anchor_generator.num_base_anchors[0] # num_base_anchors函数返回一个列表,列表的长度是base_sizes的长度,且列表中的anchors数量都一样,所以取第一个即可
self._init_layers() # 这个步骤是初始化rpn的卷积层,分类层,回归层,三个卷积层
# 初始化网络层
def _init_layers(self):
"""Initialize layers of the head."""
# rpn_conv层的作用是将不同channels的特征图放缩到一致的channels,为self.feat_channels
self.rpn_conv = nn.Conv2d(
self.in_channels, self.feat_channels, 3, padding=1)
# rpn_cls层的作用是将RPNHead前向推理后的特征图经过rpn_conv后,进行分类预测
# 输出的channels的数量为num_anchors*cls_out_channels(classes)
self.rpn_cls = nn.Conv2d(self.feat_channels,
self.num_anchors * self.cls_out_channels, 1)
# rpn_reg层的作用是将RPNHead前向推理后的特征图经过rpn_conv后,进行边框回归预测
# 输出的channels的数量为num_anchors*4 (cx,cy,w,h)
self.rpn_reg = nn.Conv2d(self.feat_channels, self.num_anchors * 4, 1)
5.引用到4中的编码器初始化函数
class DeltaXYWHBBoxCoder(BaseBBoxCoder):
def __init__(self,
target_means=(0., 0., 0., 0.),
target_stds=(1., 1., 1., 1.),
clip_border=True):
super(BaseBBoxCoder, self).__init__() # 继承自BaseBBoxCoder(实现两个抽象接口encoder和decoder)
self.means = target_means # 反三角坐标目标的归一化方法
self.stds = target_stds # 针对增量坐标归一化目标的标准偏差
self.clip_border = clip_border # 图像边框之外是否裁剪,默认为True
6.引用到4中的分类损失初始化函数
class CrossEntropyLoss(nn.Module):
def __init__(self,
use_sigmoid=False,
use_mask=False,
reduction='mean',
class_weight=None,
loss_weight=1.0):
"""CrossEntropyLoss.
Args:
use_sigmoid (bool, optional): Whether the prediction uses sigmoid
of softmax. Defaults to False.
use_mask (bool, optional): Whether to use mask cross entropy loss.
Defaults to False.
reduction (str, optional): . Defaults to 'mean'.
Options are "none", "mean" and "sum".
class_weight (list[float], optional): Weight of each class.
Defaults to None.
loss_weight (float, optional): Weight of the loss. Defaults to 1.0.
"""
super(CrossEntropyLoss, self).__init__()
assert (use_sigmoid is False) or (use_mask is False)
self.use_sigmoid = use_sigmoid
self.use_mask = use_mask
self.reduction = reduction
self.loss_weight = loss_weight
self.class_weight = class_weight
if self.use_sigmoid:
self.cls_criterion = binary_cross_entropy # 二分类交叉熵
elif self.use_mask:
self.cls_criterion = mask_cross_entropy # mask交叉熵(二分类交叉熵)
else:
self.cls_criterion = cross_entropy # 多分类交叉熵
7.引用到4中的回归损失初始化函数
class L1Loss(nn.Module):
"""L1 loss.
Args:
reduction (str, optional): The method to reduce the loss.
Options are "none", "mean" and "sum".
loss_weight (float, optional): The weight of loss.
"""
def __init__(self, reduction='mean', loss_weight=1.0):
super(L1Loss, self).__init__()
self.reduction = reduction
self.loss_weight = loss_weight
8.引用到4中的分配器初始化函数
# MaxIoUAssigner继承自BaseAssigner(实现了一个assign抽象方法)
class MaxIoUAssigner(BaseAssigner):
"""Assign a corresponding gt bbox or background to each bbox.
Each proposals will be assigned with `-1`, or a semi-positive integer
indicating the ground truth index.
- -1: negative sample, no assigned gt
- semi-positive integer: positive sample, index (0-based) of assigned gt
Args:
pos_iou_thr (float): IoU threshold for positive bboxes.
neg_iou_thr (float or tuple): IoU threshold for negative bboxes.
min_pos_iou (float): Minimum iou for a bbox to be considered as a
positive bbox. Positive samples can have smaller IoU than
pos_iou_thr due to the 4th step (assign max IoU sample to each gt).
gt_max_assign_all (bool): Whether to assign all bboxes with the same
highest overlap with some gt to that gt.
ignore_iof_thr (float): IoF threshold for ignoring bboxes (if
`gt_bboxes_ignore` is specified). Negative values mean not
ignoring any bboxes.
ignore_wrt_candidates (bool): Whether to compute the iof between
`bboxes` and `gt_bboxes_ignore`, or the contrary.
match_low_quality (bool): Whether to allow low quality matches. This is
usually allowed for RPN and single stage detectors, but not allowed
in the second stage. Details are demonstrated in Step 4.
gpu_assign_thr (int): The upper bound of the number of GT for GPU
assign. When the number of gt is above this threshold, will assign
on CPU device. Negative values mean not assign on CPU.
"""
def __init__(self,
pos_iou_thr,
neg_iou_thr,
min_pos_iou=.0,
gt_max_assign_all=True,
ignore_iof_thr=-1,
ignore_wrt_candidates=True,
match_low_quality=True,
gpu_assign_thr=-1,
iou_calculator=dict(type='BboxOverlaps2D')):
self.pos_iou_thr = pos_iou_thr
self.neg_iou_thr = neg_iou_thr
self.min_pos_iou = min_pos_iou
self.gt_max_assign_all = gt_max_assign_all
self.ignore_iof_thr = ignore_iof_thr
self.ignore_wrt_candidates = ignore_wrt_candidates
self.gpu_assign_thr = gpu_assign_thr
self.match_low_quality = match_low_quality
self.iou_calculator = build_iou_calculator(iou_calculator) # 初始化iou计算器,直接获取到函数名,类内实现了__call_直接通过 方法名()调用
9.引用到4中的采样器初始化函数
# 继承自BaseSampler类(实现了两个抽象方法_sample_pos,_sample_neg和sample函数)
class RandomSampler(BaseSampler):
"""Random sampler.
Args:
num (int): Number of samples
pos_fraction (float): Fraction of positive samples
neg_pos_up (int, optional): Upper bound number of negative and
positive samples. Defaults to -1.
add_gt_as_proposals (bool, optional): Whether to add ground truth
boxes as proposals. Defaults to True.
"""
def __init__(self,
num, #样本数量
pos_fraction, # 正样本比例
neg_pos_ub=-1, # 负样本和正样本的上限数量,默认为-1
add_gt_as_proposals=True,
**kwargs):
from mmdet.core.bbox import demodata
super(RandomSampler, self).__init__(num, pos_fraction, neg_pos_ub,
add_gt_as_proposals)
self.rng = demodata.ensure_rng(kwargs.get('rng', None)) # a numpy random number generator
class BaseSampler(metaclass=ABCMeta):
"""Base class of samplers."""
def __init__(self,
num,
pos_fraction,
neg_pos_ub=-1,
add_gt_as_proposals=True,
**kwargs):
# 常规赋值初始化
self.num = num
self.pos_fraction = pos_fraction
self.neg_pos_ub = neg_pos_ub
self.add_gt_as_proposals = add_gt_as_proposals
self.pos_sampler = self
self.neg_sampler = self
10.引用到4中的anchor生成器初始化函数
# anchors(锚框生成器),继承于Object类
class AnchorGenerator(object):
"""Standard anchor generator for 2D anchor-based detectors.
Args:
strides (list[int] | list[tuple[int, int]]): Strides of anchors
in multiple feature levels in order (w, h).
ratios (list[float]): The list of ratios between the height and width
of anchors in a single level.
scales (list[int] | None): Anchor scales for anchors in a single level.
It cannot be set at the same time if `octave_base_scale` and
`scales_per_octave` are set.
base_sizes (list[int] | None): The basic sizes
of anchors in multiple levels.
If None is given, strides will be used as base_sizes.
(If strides are non square, the shortest stride is taken.)
scale_major (bool): Whether to multiply scales first when generating
base anchors. If true, the anchors in the same row will have the
same scales. By default it is True in V2.0
octave_base_scale (int): The base scale of octave.
scales_per_octave (int): Number of scales for each octave.
`octave_base_scale` and `scales_per_octave` are usually used in
retinanet and the `scales` should be None when they are set.
centers (list[tuple[float, float]] | None): The centers of the anchor
relative to the feature grid center in multiple feature levels.
By default it is set to be None and not used. If a list of tuple of
float is given, they will be used to shift the centers of anchors.
center_offset (float): The offset of center in proportion to anchors'
width and height. By default it is 0 in V2.0.
Examples:
>>> from mmdet.core import AnchorGenerator
>>> self = AnchorGenerator([16], [1.], [1.], [9])
>>> all_anchors = self.grid_anchors([(2, 2)], device='cpu')
>>> print(all_anchors)
[tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
[11.5000, -4.5000, 20.5000, 4.5000],
[-4.5000, 11.5000, 4.5000, 20.5000],
[11.5000, 11.5000, 20.5000, 20.5000]])]
>>> self = AnchorGenerator([16, 32], [1.], [1.], [9, 18])
>>> all_anchors = self.grid_anchors([(2, 2), (1, 1)], device='cpu')
>>> print(all_anchors)
[tensor([[-4.5000, -4.5000, 4.5000, 4.5000],
[11.5000, -4.5000, 20.5000, 4.5000],
[-4.5000, 11.5000, 4.5000, 20.5000],
[11.5000, 11.5000, 20.5000, 20.5000]]), \
tensor([[-9., -9., 9., 9.]])]
"""
def __init__(self,
strides, # 步长(指的是在feature map上生成anchor的步长)
ratios, # 宽高比
scales=None, # 缩放比例
base_sizes=None, # 基础大小
scale_major=True,
octave_base_scale=None,
scales_per_octave=None,
centers=None, # 指定中心点(一般默认最左上角点)
center_offset=0.):
# check center and center_offset
if center_offset != 0:
assert centers is None, 'center cannot be set when center_offset' \
f'!=0, {centers} is given.'
if not (0 <= center_offset <= 1):
raise ValueError('center_offset should be in range [0, 1], '
f'{center_offset} is given.')
if centers is not None:
assert len(centers) == len(strides), \
'The number of strides should be the same as centers, got ' \
f'{strides} and {centers}'
# calculate base sizes of anchors
self.strides = [_pair(stride) for stride in strides]
self.base_sizes = [min(stride) for stride in self.strides
] if base_sizes is None else base_sizes
assert len(self.base_sizes) == len(self.strides), \
'The number of strides should be the same as base sizes, got ' \
f'{self.strides} and {self.base_sizes}'
# calculate scales of anchors
assert ((octave_base_scale is not None
and scales_per_octave is not None) ^ (scales is not None)), \
'scales and octave_base_scale with scales_per_octave cannot' \
' be set at the same time'
if scales is not None:
self.scales = torch.Tensor(scales)
elif octave_base_scale is not None and scales_per_octave is not None:
octave_scales = np.array(
[2**(i / scales_per_octave) for i in range(scales_per_octave)])
scales = octave_scales * octave_base_scale
self.scales = torch.Tensor(scales)
else:
raise ValueError('Either scales or octave_base_scale with '
'scales_per_octave should be set')
self.octave_base_scale = octave_base_scale
self.scales_per_octave = scales_per_octave
self.ratios = torch.Tensor(ratios)
self.scale_major = scale_major
self.centers = centers
self.center_offset = center_offset
self.base_anchors = self.gen_base_anchors() # 同级下分析gen_base_anchors函数
# 生成基于center点的基础锚框,比如说有3个基础大小的锚框,同时有2个ratios和2个scales,
# 最终会生成3×2×2=12个基础锚框,要得到所有锚框,
# 只需要根据strides计算每个锚框相对于左上角基础框的偏移量即可。
# 此函数用来生成基本锚框
def gen_base_anchors(self):
"""Generate base anchors.
Returns:
list(torch.Tensor): Base anchors of a feature grid in multiple \
feature levels.
"""
multi_level_base_anchors = [] # 定义接收所有基础锚框的空列表
for i, base_size in enumerate(self.base_sizes): # 迭代出每个base_size
center = None
if self.centers is not None:
center = self.centers[i]
multi_level_base_anchors.append(
# 根据base_size生成当前base_size下的所有ratios和scales组合的基础锚框
self.gen_single_level_base_anchors(
base_size,
scales=self.scales,
ratios=self.ratios,
center=center)) # 传入Base_size
return multi_level_base_anchors # 返回所有基础锚框,共len(base_sizes)×ratios×scales个
# 根据base_size,生成当前base_size下,所有ratios和scales组合的基础锚框,共1×ratios×scales个
def gen_single_level_base_anchors(self,
base_size,
scales,
ratios,
center=None):
"""Generate base anchors of a single level.
Args:
base_size (int | float): Basic size of an anchor.
scales (torch.Tensor): Scales of the anchor.
ratios (torch.Tensor): The ratio between between the height
and width of anchors in a single level.
center (tuple[float], optional): The center of the base anchor
related to a single feature grid. Defaults to None.
Returns:
torch.Tensor: Anchors in a single-level feature maps.
"""
# 常规赋值
w = base_size
h = base_size
if center is None:
x_center = self.center_offset * w
y_center = self.center_offset * h
else:
x_center, y_center = center
# 这里保持h_ratios×w_ratios保持为1,同时可以实现ratios的宽高比
h_ratios = torch.sqrt(ratios)
w_ratios = 1 / h_ratios
if self.scale_major:
# 这里可以分为多个步骤来解读:
# w_ratios[:, None]和scales[None, :]是升维,将例如(3,)升维(3,1)或(1,3)
# w是base_size,与w_ratios,scales相乘得到基于当前base_size的所有锚宽,同理得到hs
# view(-1)是按最后一维铺平
ws = (w * w_ratios[:, None] * scales[None, :]).view(-1)
hs = (h * h_ratios[:, None] * scales[None, :]).view(-1)
else:
ws = (w * scales[:, None] * w_ratios[None, :]).view(-1)
hs = (h * scales[:, None] * h_ratios[None, :]).view(-1)
# use float anchor and the anchor's center is aligned with the
# pixel center
# center一般为(0,0),所以此处得到的应该是左上角点
base_anchors = [
x_center - 0.5 * ws, y_center - 0.5 * hs, x_center + 0.5 * ws,
y_center + 0.5 * hs
]
# 按最后一维叠加
base_anchors = torch.stack(base_anchors, dim=-1)
return base_anchors
4.Head前向传播
1.RPN网络的前向传播
class RPN(BaseDetector):
def forward_train(self,
img,
img_metas,
gt_bboxes=None,
gt_bboxes_ignore=None):
"""
Args:
img (Tensor): Input images of shape (N, C, H, W).
Typically these should be mean centered and std scaled.
img_metas (list[dict]): A List of image info dict where each dict
has: 'img_shape', 'scale_factor', 'flip', and may also contain
'filename', 'ori_shape', 'pad_shape', and 'img_norm_cfg'.
For details on the values of these keys see
:class:`mmdet.datasets.pipelines.Collect`.
gt_bboxes (list[Tensor]): Each item are the truth boxes for each
image in [tl_x, tl_y, br_x, br_y] format.
gt_bboxes_ignore (None | list[Tensor]): Specify which bounding
boxes can be ignored when computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
# 判断是不是debug模式
if self.train_cfg.rpn.get('debug', False):
self.rpn_head.debug_imgs = tensor2imgs(img)
# 先运行backbone+beck进行特征提取
x = self.extract_feat(img) 「一」
# 对head进行forward train,输出loss
losses = self.rpn_head.forward_train(x, img_metas, gt_bboxes, None,
gt_bboxes_ignore) 「二」
return losses
2.链接到1中的「一」方法:通过骨架与颈部提取特征
# 链接到「一」的特征提取层,这里是通过骨架网络和网络颈部提取特征
# 这里更关注头部网络的前向推理,骨架与网络颈部的前向暂不推导
def extract_feat(self, img):
"""Extract features.
Args:
img (torch.Tensor): Image tensor with shape (n, c, h ,w).
Returns:
list[torch.Tensor]: Multi-level features that may have
different resolutions.
"""
# 进行网络骨架推理,resnet一般得到4个特征层
x = self.backbone(img)
# 进行网络颈部推理,FPN一般输入4个特征图,得到5个输出
if self.with_neck:
x = self.neck(x)
return x
3.链接到1中的「二」方法:通过网络头部计算损失值
# 链接到「二」的网络头部loss计算
class BaseDenseHead(nn.Module, metaclass=ABCMeta):
def forward_train(self,
x, # 来自颈部网络FPN的输出
img_metas, # 输入图像的元素,例如图像尺寸,缩放比例等等
gt_bboxes, # ground-truth 形状为(gt框数, 4)
gt_labels=None, # ground-truth的标签信息 形状为(gt框数,)
gt_bboxes_ignore=None, # 要忽略的GT框 形状为(num_ignored_gts, 4)
proposal_cfg=None, #
**kwargs):
"""
Args:
x (list[Tensor]): Features from FPN.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
proposal_cfg (mmcv.Config): Test / postprocessing configuration,
if None, test_cfg would be used
Returns:
tuple:
losses: (dict[str, Tensor]): A dictionary of loss components.
各损失值的字典
proposal_list (list[Tensor]): Proposals of each image.
对每张图像的预测候选框
"""
# 将FPN的输出传入到头部网络中,进行前向推理(RPNHead)
# 得到的输出是一个(2,)的元组,分别是每个尺度的特征图分类得分,和边界框回归结果
outs = self(x) 「三」
# 判断gt_labels是不是为None,然后将outs和gt_bboxes,gt_labels,img_metas融合成一个元组
if gt_labels is None:
loss_inputs = outs + (gt_bboxes, img_metas)
else:
loss_inputs = outs + (gt_bboxes, gt_labels, img_metas)
# 根据gt框和outs计算loss
losses = self.loss(*loss_inputs, gt_bboxes_ignore=gt_bboxes_ignore) 「六」
if proposal_cfg is None:
return losses
else:
proposal_list = self.get_bboxes(*outs, img_metas, cfg=proposal_cfg)
return losses, proposal_list
4.链接到3中的「三」方法:将FPN的输出传入到头部网络中,进行前向推理
# 链接到「三」的网络头部前向传播,开始往上层传播,前向推理AnchorHead
class AnchorHead(BaseDenseHead, BBoxTestMixin):
# AnchorHead的前向传播
def forward(self, feats):
"""Forward features from the upstream network.
Args:
feats (tuple[Tensor]): Features from the upstream network, each is
a 4D-tensor.
传入4维特征图
Returns:
tuple: A tuple of classification scores and bbox prediction.
返回一个包含分类得分和边界框回归的结果元组
- cls_scores (list[Tensor]): Classification scores for all \
scale levels, each is a 4D-tensor, the channels number \
is num_anchors * num_classes.
对于所有尺度的分类得分,结果是一个4维的张量,深度是num_anchors * num_classes
- bbox_preds (list[Tensor]): Box energies / deltas for all \
scale levels, each is a 4D-tensor, the channels number \
is num_anchors * 4.
对于所有尺度的边框回归,结果是一个4维的张量,深度是num_anchors * 4
"""
return multi_apply(self.forward_single, feats) 「四」# 注意这里传入的函数是self.forward_single函数
5.链接到4中的「四」方法:用partial对象,分别将FPN的输出(5,)中的每一个特征图传入到self.forward_single函数中,再对输出结果取一个元组,所以最后的返回结果是(分类得分,边界框回归)
# 多尺度特征图,一个一个迭代进行forward_single
def multi_apply(func, *args, **kwargs):
"""Apply function to a list of arguments.
Note:
This function applies the ``func`` to multiple inputs and
map the multiple outputs of the ``func`` into different
list. Each list contains the same type of outputs corresponding
to different inputs.
Args:
func (Function): A function that will be applied to a list of
arguments
Returns:
tuple(list): A tuple containing multiple list, each list contains \
a kind of returned results by the function
"""
# 将多个方法统一到一个方法列表中,参数以缺省值的形式传入partial对象
pfunc = partial(func, **kwargs) if kwargs else func
# 分别计算各个方法的输出
map_results = map(pfunc, *args)
# 返回的结果是一个元组(会执行传入的func方法,在这里会把一个(5,)的FPN输出特征图,分别传入func方法中,在这里的func方法是forward_single函数)
return tuple(map(list, zip(*map_results))) 「五」
6.链接到5中的「五」方法:首先通过rpn_conv函数将FPN输出的单个特征图进行维度转换,转换到统一的channels数量,方便后续进行分类rpn_cls预测和rpn_reg预测,分类结果形状为(N, num_anchors * num_classes, H, W),边框回归结果形状为(N, num_anchors * 4, H, W)
def forward_single(self, x):
"""Forward feature map of a single scale level."""
x = self.rpn_conv(x)
x = F.relu(x, inplace=True)
rpn_cls_score = self.rpn_cls(x)
rpn_bbox_pred = self.rpn_reg(x)
return rpn_cls_score, rpn_bbox_pred
7.链接到3中的「六」方法:根据gt框和outs计算loss
class RPNHead(RPNTestMixin, AnchorHead):
def loss(self,
cls_scores, # 每个尺度下的候选框得分,(N, num_anchors * num_classes, H, W)
bbox_preds, # 每个尺度下的候选框位置预测,(N, num_anchors * 4, H, W)
gt_bboxes, # 每张图的标注信息,(num_gts, 4) in [tl_x, tl_y, br_x, br_y] format
img_metas, # 图像信息
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss.
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
losses = super(RPNHead, self).loss(
cls_scores,
bbox_preds,
gt_bboxes,
None,
img_metas,
gt_bboxes_ignore=gt_bboxes_ignore) 「七」 # 调用父类的loss前向传播函数
return dict(
loss_rpn_cls=losses['loss_cls'], loss_rpn_bbox=losses['loss_bbox'])
8.链接到7中的「七」方法:调用父类的loss前向传播函数
class AnchorHead(BaseDenseHead, BBoxTestMixin):
@force_fp32(apply_to=('cls_scores', 'bbox_preds'))
def loss(self,
cls_scores,
bbox_preds,
gt_bboxes,
gt_labels,
img_metas,
gt_bboxes_ignore=None):
"""Compute losses of the head.
Args:
cls_scores (list[Tensor]): Box scores for each scale level
Has shape (N, num_anchors * num_classes, H, W)
bbox_preds (list[Tensor]): Box energies / deltas for each scale
level with shape (N, num_anchors * 4, H, W)
gt_bboxes (list[Tensor]): Ground truth bboxes for each image with
shape (num_gts, 4) in [tl_x, tl_y, br_x, br_y] format.
gt_labels (list[Tensor]): class indices corresponding to each box
img_metas (list[dict]): Meta information of each image, e.g.,
image size, scaling factor, etc.
gt_bboxes_ignore (None | list[Tensor]): specify which bounding
boxes can be ignored when computing the loss. Default: None
Returns:
dict[str, Tensor]: A dictionary of loss components.
"""
# 得到每个特征图的尺寸
featmap_sizes = [featmap.size()[-2:] for featmap in cls_scores]
assert len(featmap_sizes) == self.anchor_generator.num_levels
device = cls_scores[0].device
anchor_list, valid_flag_list = self.get_anchors(
featmap_sizes, img_metas, device=device) 「八」# 根据特征图大小获取anchors
label_channels = self.cls_out_channels if self.use_sigmoid_cls else 1
cls_reg_targets = self.get_targets(
anchor_list,
valid_flag_list,
gt_bboxes,
img_metas,
gt_bboxes_ignore_list=gt_bboxes_ignore,
gt_labels_list=gt_labels,
label_channels=label_channels) 「十二」 # 获取正负样本
if cls_reg_targets is None:
return None
# 常规赋值
(labels_list, label_weights_list, bbox_targets_list, bbox_weights_list,
num_total_pos, num_total_neg) = cls_reg_targets
# 统计总的sample数
num_total_samples = (
num_total_pos + num_total_neg if self.sampling else num_total_pos)
# anchor number of multi levels
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# concat all level anchors and flags to a single tensor
concat_anchor_list = []
for i in range(len(anchor_list)):
concat_anchor_list.append(torch.cat(anchor_list[i]))
all_anchor_list = images_to_levels(concat_anchor_list,
num_level_anchors)
# 计算损失
losses_cls, losses_bbox = multi_apply(
self.loss_single,
cls_scores,
bbox_preds,
all_anchor_list,
labels_list,
label_weights_list,
bbox_targets_list,
bbox_weights_list,
num_total_samples=num_total_samples)
return dict(loss_cls=losses_cls, loss_bbox=losses_bbox)
9.链接到8中的「八」方法:根据特征图大小获取anchors
# 传入特征图的大小获取到对应尺寸的锚框
def get_anchors(self, featmap_sizes, img_metas, device='cuda'):
"""Get anchors according to feature map sizes.
Args:
featmap_sizes (list[tuple]): Multi-level feature map sizes.
img_metas (list[dict]): Image meta info.
device (torch.device | str): Device for returned tensors
Returns:
tuple:
anchor_list (list[Tensor]): Anchors of each image.
valid_flag_list (list[Tensor]): Valid flags of each image.
"""
# 统计图像数量
num_imgs = len(img_metas)
# since feature map sizes of all images are the same, we only compute
# anchors for one time
multi_level_anchors = self.anchor_generator.grid_anchors(
featmap_sizes, device) 「九」 # 生成anchors
# 将上面得到的多尺度特征图映射为一个二维的列表,因为传入batch的shape一致,所以根据特征图生成的anchors也可以共用
# 有几张图像就复制几次
anchor_list = [multi_level_anchors for _ in range(num_imgs)]
# for each image, we compute valid flags of multi level anchors
# 对每张图像进行anchor可行性计算
valid_flag_list = []
for img_id, img_meta in enumerate(img_metas):
multi_level_flags = self.anchor_generator.valid_flags(
featmap_sizes, img_meta['pad_shape'], device) 「十一」
valid_flag_list.append(multi_level_flags)
return anchor_list, valid_flag_list # valid_flags得到在padding以内的值
10.链接到9中的「九」方法:生成anchors
def grid_anchors(self, featmap_sizes, device='cuda'):
"""Generate grid anchors in multiple feature levels.
Args:
featmap_sizes (list[tuple]): List of feature map sizes in
multiple feature levels.
device (str): Device where the anchors will be put on.
Return:
list[torch.Tensor]: Anchors in multiple feature levels. \
The sizes of each tensor should be [N, 4], where \
N = width * height * num_base_anchors, width and height \
are the sizes of the corresponding feature level, \
num_base_anchors is the number of anchors for that level.
"""
# 对应的特征图生成anchors的步长列表长度要与特征图数量一致
assert self.num_levels == len(featmap_sizes)
# 建立保存所有anchors的列表
multi_level_anchors = []
# 遍历
for i in range(self.num_levels):
# 单个特征图生成anchors
anchors = self.single_level_grid_anchors(
self.base_anchors[i].to(device),
featmap_sizes[i],
self.strides[i],
device=device) 「十」 # 单个特征图生成anchors方法
multi_level_anchors.append(anchors)
return multi_level_anchors
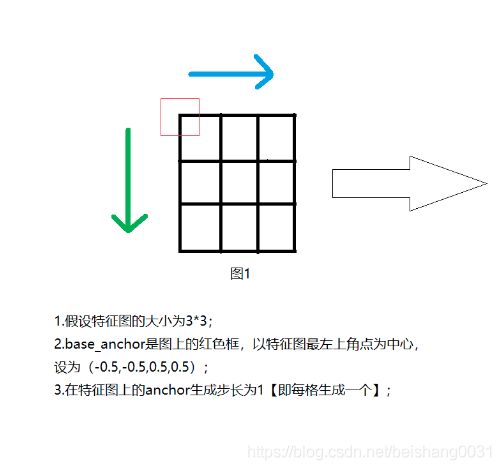
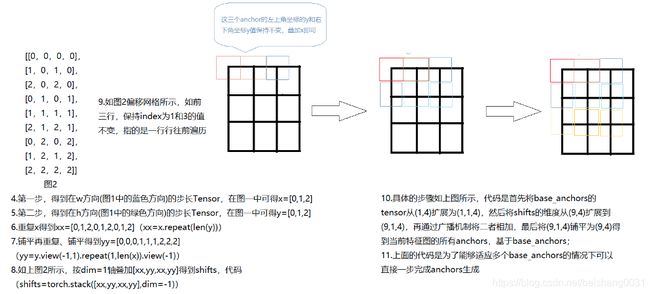
11.链接到10中的「十」方法:单个特征图生成anchors方法
def single_level_grid_anchors(self,
base_anchors,
featmap_size,
stride=(16, 16),
device='cuda'):
"""Generate grid anchors of a single level.
# 单级别特征图的anchors生成方法
Note:
This function is usually called by method ``self.grid_anchors``.
# 该方法经常由self.grid_anchors所调用
Args:
base_anchors (torch.Tensor): The base anchors of a feature grid.
# 基础锚框
featmap_size (tuple[int]): Size of the feature maps.
# 特征图大小
stride (tuple[int], optional): Stride of the feature map in order
(w, h). Defaults to (16, 16).
# 特征图上的步长大小
device (str, optional): Device the tensor will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: Anchors in the overall feature maps.
# 返回单个特征图上的所有锚框
"""
# 常规赋值
feat_h, feat_w = featmap_size
# convert Tensor to int, so that we can covert to ONNX correctlly
feat_h = int(feat_h)
feat_w = int(feat_w)
# torch.arange方法生成从0到x-1步长为1的所有值,例如0,1,2,3...,x-1
# 乘上步长得到对应在w和h上的偏移量
shift_x = torch.arange(0, feat_w, device=device) * stride[0]
shift_y = torch.arange(0, feat_h, device=device) * stride[1]
# 上面只是得到了在w和h方向上各自第一行(列)的偏移
# 应该得到在特征图上的所有偏移,size与特征图一致
shift_xx, shift_yy = self._meshgrid(shift_x, shift_y)
# 按h方向叠加为一个tensor
# 例如 shift_xx = tensor([0., 1., 2., 0., 1., 2.])
# shift_yy = tensor([0., 0., 0., 1., 1., 1.])
# shifts = tensor([
# [0., 0., 0., 0.],
# [1., 0., 1., 0.],
# [2., 0., 2., 0.],
# [0., 1., 0., 1.],
# [1., 1., 1., 1.],
# [2., 1., 2., 1.]])
# 其实在这一步已经基本完成了当前特征图的所有anchor的生成
# 仔细看,shifts中的前三个shifts[0~2][1]和shifts[0~2][2]保持不变
# 其实是首先固定base_anchor在当前特征图中的y不变,就是按行向前计算anchor,详见最后的图示
shifts = torch.stack([shift_xx, shift_yy, shift_xx, shift_yy], dim=-1)
# 转换类型
shifts = shifts.type_as(base_anchors)
# first feat_w elements correspond to the first row of shifts
# add A anchors (1, A, 4) to K shifts (K, 1, 4) to get
# shifted anchors (K, A, 4), reshape to (K*A, 4)
# 首先shifts[:, None, :]将shifts中插入一维
# 例如 之前的shifts[0]为[0., 0., 0., 0.],现在为[[0., 0., 0., 0.]]
# base_anchors从变成3维,例如之前为(2,4)->(1,2,4)
# shifts从(6,4)->(6,1,4)
# 广播机制all_anchors为(6,2,4)
# 这一步的目的是为了把base_anchors分别与步长相加,得到每个base_anchor的所有偏移框
# 当base_anchors从例如(2,4)->(1,2,4),偏移网格也从(6,4)->(6,1,4)
# 那么按照广播机制(6,1,4)->(6,2,4)其中的1->2是复制偏移步长的数量和base_anchor的数量相一致
# base_anchors的(1,2,4)中的2指的是base_anchor的数量
# base_anchors广播到(1,2,4)->(6,2,4),其中6是当前特征图的所有anchor数,也是每个anchor的偏移
all_anchors = base_anchors[None, :, :] + shifts[:, None, :]
# 按最后一维为4铺开(6,2,4)->(12,4)
all_anchors = all_anchors.view(-1, 4)
# first A rows correspond to A anchors of (0, 0) in feature map,
# then (0, 1), (0, 2), ...
return all_anchors
def _meshgrid(self, x, y, row_major=True):
"""Generate mesh grid of x and y.
Args:
x (torch.Tensor): Grids of x dimension.
y (torch.Tensor): Grids of y dimension.
row_major (bool, optional): Whether to return y grids first.
Defaults to True.
Returns:
tuple[torch.Tensor]: The mesh grids of x and y.
"""
# 假设传入的
# x,y = [0,1,2],[0,1]
# 传入的x是第一行的偏移
# 传入的y是第一列的偏移
# 重复len(y)次的x得到xx (3,)-> (3*len(y),)
# xx = [0,1,2,0,1,2]
xx = x.repeat(len(y))
# y.view(-1, 1),将y按最后的维度拆分为(N,1),例如(3,)->(3,1)像是从行到列
# [0,1]->[[0],[1]]
# y.repeat(1,len(x)),指定按x方向重复数组
# [[0,0,0],[1,1,1]]
# y.view(-1)将数组铺平为一行
# yy = [0,0,0,1,1,1]
yy = y.view(-1, 1).repeat(1, len(x)).view(-1)
if row_major:
return xx, yy
else:
return yy, xx
12.链接到9中的「十一」方法:计算有效项
def valid_flags(self, featmap_sizes, pad_shape, device='cuda'):
"""Generate valid flags of anchors in multiple feature levels.
Args:
featmap_sizes (list(tuple)): List of feature map sizes in
multiple feature levels.
pad_shape (tuple): The padded shape of the image.
device (str): Device where the anchors will be put on.
Return:
list(torch.Tensor): Valid flags of anchors in multiple levels.
"""
assert self.num_levels == len(featmap_sizes)
multi_level_flags = []
for i in range(self.num_levels):
# 对应特征图的步长,也可以看作是输入原图padding之后的下采样次数如两次步长为4,三次步长为8
anchor_stride = self.strides[i]
# 特征图的大小
feat_h, feat_w = featmap_sizes[i]
# 从img_meta中取到,输入图像经过预处理后的大小,也是输入网络的大小
h, w = pad_shape[:2]
valid_feat_h = min(int(np.ceil(h / anchor_stride[1])), feat_h)
valid_feat_w = min(int(np.ceil(w / anchor_stride[0])), feat_w)
flags = self.single_level_valid_flags((feat_h, feat_w),
(valid_feat_h, valid_feat_w),
self.num_base_anchors[i],
device=device)
multi_level_flags.append(flags)
return multi_level_flags
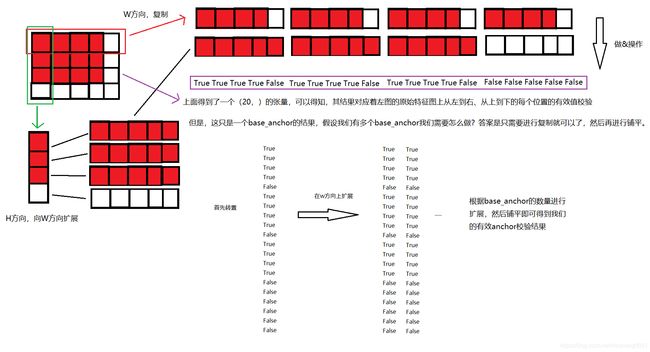
def single_level_valid_flags(self,
featmap_size,
valid_size,
num_base_anchors,
device='cuda'):
"""Generate the valid flags of anchor in a single feature map.
Args:
featmap_size (tuple[int]): The size of feature maps.
valid_size (tuple[int]): The valid size of the feature maps.
num_base_anchors (int): The number of base anchors.
device (str, optional): Device where the flags will be put on.
Defaults to 'cuda'.
Returns:
torch.Tensor: The valid flags of each anchor in a single level \
feature map.
"""
feat_h, feat_w = featmap_size
valid_h, valid_w = valid_size
assert valid_h <= feat_h and valid_w <= feat_w
# 创建两个默认为False的tensor
valid_x = torch.zeros(feat_w, dtype=torch.bool, device=device)
valid_y = torch.zeros(feat_h, dtype=torch.bool, device=device)
# 取到有效值范围的下标赋值为True
valid_x[:valid_w] = 1
valid_y[:valid_h] = 1
# 得到有效值的网格输出
valid_xx, valid_yy = self._meshgrid(valid_x, valid_y)
# 这一步的目的,可以看作将h方向上的值当作一个flag标志,在valid_y[:valid_h] = 1内
# y的值始终为True,先将y扩展到与x一样的长度,再做与运算,也是和之前的anchor计算一样,逐行计算
# 它的目的可以用下图直接概括
valid = valid_xx & valid_yy
# torch.contiguous()方法首先拷贝了一份张量在内存中的地址,然后将地址按照形状改变后的张量的语义进行排列
# expand扩张只是为了复制多个(根据num_base_anchors的个数)“有效值校验”的结果
# 首先将valid[:, None]变为(N,1)的形状,再在最后一维上进行扩展
# 最后铺平
valid = valid[:, None].expand(valid.size(0),
num_base_anchors).contiguous().view(-1)
return valid
13.链接到8中的「十二」方法:获取到正负样本
def get_targets(self,
anchor_list,
valid_flag_list,
gt_bboxes_list,
img_metas,
gt_bboxes_ignore_list=None,
gt_labels_list=None,
label_channels=1,
unmap_outputs=True,
return_sampling_results=False):
"""Compute regression and classification targets for anchors in
multiple images.
Args:
anchor_list (list[list[Tensor]]): Multi level anchors of each
image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, 4).
valid_flag_list (list[list[Tensor]]): Multi level valid flags of
each image. The outer list indicates images, and the inner list
corresponds to feature levels of the image. Each element of
the inner list is a tensor of shape (num_anchors, )
gt_bboxes_list (list[Tensor]): Ground truth bboxes of each image.
img_metas (list[dict]): Meta info of each image.
gt_bboxes_ignore_list (list[Tensor]): Ground truth bboxes to be
ignored.
gt_labels_list (list[Tensor]): Ground truth labels of each box.
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple: Usually returns a tuple containing learning targets.
- labels_list (list[Tensor]): Labels of each level.
- label_weights_list (list[Tensor]): Label weights of each \
level.
- bbox_targets_list (list[Tensor]): BBox targets of each level.
- bbox_weights_list (list[Tensor]): BBox weights of each level.
- num_total_pos (int): Number of positive samples in all \
images.
- num_total_neg (int): Number of negative samples in all \
images.
additional_returns: This function enables user-defined returns from
`self._get_targets_single`. These returns are currently refined
to properties at each feature map (i.e. having HxW dimension).
The results will be concatenated after the end
"""
# 常规校验
num_imgs = len(img_metas)
assert len(anchor_list) == len(valid_flag_list) == num_imgs
# anchor number of multi levels
# 得到每个尺度的anchor数量
num_level_anchors = [anchors.size(0) for anchors in anchor_list[0]]
# concat all level anchors to a single tensor
# 把所有的anchors整合到一个张量里
concat_anchor_list = []
concat_valid_flag_list = []
for i in range(num_imgs):
assert len(anchor_list[i]) == len(valid_flag_list[i])
concat_anchor_list.append(torch.cat(anchor_list[i]))
concat_valid_flag_list.append(torch.cat(valid_flag_list[i]))
# compute targets for each image
# 计算每张图像的目标
if gt_bboxes_ignore_list is None:
gt_bboxes_ignore_list = [None for _ in range(num_imgs)]
if gt_labels_list is None:
gt_labels_list = [None for _ in range(num_imgs)]
results = multi_apply(
self._get_targets_single,
concat_anchor_list,
concat_valid_flag_list,
gt_bboxes_list,
gt_bboxes_ignore_list,
gt_labels_list,
img_metas,
label_channels=label_channels,
unmap_outputs=unmap_outputs) 「十三」 # 多项提交同时计算多个目标(当batch_size>1时)
(all_labels, all_label_weights, all_bbox_targets, all_bbox_weights,
pos_inds_list, neg_inds_list, sampling_results_list) = results[:7]
rest_results = list(results[7:]) # user-added return values
# no valid anchors
if any([labels is None for labels in all_labels]):
return None
# sampled anchors of all images
num_total_pos = sum([max(inds.numel(), 1) for inds in pos_inds_list])
num_total_neg = sum([max(inds.numel(), 1) for inds in neg_inds_list])
# split targets to a list w.r.t. multiple levels
# 拆分成各层
labels_list = images_to_levels(all_labels, num_level_anchors)
label_weights_list = images_to_levels(all_label_weights,
num_level_anchors)
bbox_targets_list = images_to_levels(all_bbox_targets,
num_level_anchors)
bbox_weights_list = images_to_levels(all_bbox_weights,
num_level_anchors)
res = (labels_list, label_weights_list, bbox_targets_list,
bbox_weights_list, num_total_pos, num_total_neg)
if return_sampling_results:
res = res + (sampling_results_list,)
for i, r in enumerate(rest_results): # user-added return values
rest_results[i] = images_to_levels(r, num_level_anchors)
return res + tuple(rest_results)
14.链接到13中的「十三」方法:多项提交同时计算多个目标(当batch_size>1时)
def _get_targets_single(self,
flat_anchors,
valid_flags,
gt_bboxes,
gt_bboxes_ignore,
gt_labels,
img_meta,
label_channels=1,
unmap_outputs=True):
"""Compute regression and classification targets for anchors in a
single image.
Args:
flat_anchors (Tensor): Multi-level anchors of the image, which are
concatenated into a single tensor of shape (num_anchors ,4)
valid_flags (Tensor): Multi level valid flags of the image,
which are concatenated into a single tensor of
shape (num_anchors,).
gt_bboxes (Tensor): Ground truth bboxes of the image,
shape (num_gts, 4).
img_meta (dict): Meta info of the image.
gt_bboxes_ignore (Tensor): Ground truth bboxes to be
ignored, shape (num_ignored_gts, 4).
img_meta (dict): Meta info of the image.
gt_labels (Tensor): Ground truth labels of each box,
shape (num_gts,).
label_channels (int): Channel of label.
unmap_outputs (bool): Whether to map outputs back to the original
set of anchors.
Returns:
tuple:
labels_list (list[Tensor]): Labels of each level
label_weights_list (list[Tensor]): Label weights of each level
bbox_targets_list (list[Tensor]): BBox targets of each level
bbox_weights_list (list[Tensor]): BBox weights of each level
num_total_pos (int): Number of positive samples in all images
num_total_neg (int): Number of negative samples in all images
"""
inside_flags = anchor_inside_flags(flat_anchors, valid_flags,
img_meta['img_shape'][:2],
self.train_cfg.allowed_border) 「十四」
# 假设没有任何有效anchor,返回一个(None,) * 7的元组
if not inside_flags.any():
return (None,) * 7
# assign gt and sample anchors
# 筛选出有效anchors
anchors = flat_anchors[inside_flags, :]
# 划分正负样本
assign_result = self.assigner.assign(
anchors, gt_bboxes, gt_bboxes_ignore,
None if self.sampling else gt_labels) 「十五」# 正负样本划分
sampling_result = self.sampler.sample(assign_result, anchors,
gt_bboxes) 「十九」 # 样本均衡采样
# 统计有效anchors的数量
num_valid_anchors = anchors.shape[0]
# 创建两个维度和num_valid_anchors一样的空tensor
bbox_targets = torch.zeros_like(anchors)
bbox_weights = torch.zeros_like(anchors)
labels = anchors.new_full((num_valid_anchors,),
self.num_classes,
dtype=torch.long)
label_weights = anchors.new_zeros(num_valid_anchors, dtype=torch.float)
# 采样的正负样本下标
pos_inds = sampling_result.pos_inds
neg_inds = sampling_result.neg_inds
if len(pos_inds) > 0:
# reg_decoded_bbox(布尔):如果为true,则回归损失将应用于解码的边界框,默认值:False
if not self.reg_decoded_bbox:
pos_bbox_targets = self.bbox_coder.encode(
sampling_result.pos_bboxes, sampling_result.pos_gt_bboxes) 「二十三」
else:
pos_bbox_targets = sampling_result.pos_gt_bboxes
# 覆盖bbox_targets和bbox_weights中的正样本项
bbox_targets[pos_inds, :] = pos_bbox_targets
bbox_weights[pos_inds, :] = 1.0
if gt_labels is None:
# Only rpn gives gt_labels as None
# Foreground is the first class since v2.5.0
# 在RPN中训练时gt_labels为None
labels[pos_inds] = 0
else:
labels[pos_inds] = gt_labels[
sampling_result.pos_assigned_gt_inds]
# 在配置文件中赋值正样本的权重
if self.train_cfg.pos_weight <= 0:
label_weights[pos_inds] = 1.0
else:
label_weights[pos_inds] = self.train_cfg.pos_weight
# 如果存在负样本也要对相对应的负样本权重赋值
if len(neg_inds) > 0:
label_weights[neg_inds] = 1.0
# map up to original set of anchors
# 将输出反映射到原始的输入
if unmap_outputs:
num_total_anchors = flat_anchors.size(0)
labels = unmap(
labels, num_total_anchors, inside_flags,
fill=self.num_classes) # fill bg label
label_weights = unmap(label_weights, num_total_anchors,
inside_flags)
bbox_targets = unmap(bbox_targets, num_total_anchors, inside_flags)
bbox_weights = unmap(bbox_weights, num_total_anchors, inside_flags)
return (labels, label_weights, bbox_targets, bbox_weights, pos_inds,
neg_inds, sampling_result)
15.链接到14中的「十四」方法:
# 检查锚点是否在边界内
def anchor_inside_flags(flat_anchors,
valid_flags,
img_shape,
allowed_border=0):
"""Check whether the anchors are inside the border.
Args:
flat_anchors (torch.Tensor): Flatten anchors, shape (n, 4).
valid_flags (torch.Tensor): An existing valid flags of anchors.
img_shape (tuple(int)): Shape of current image.
allowed_border (int, optional): The border to allow the valid anchor.
Defaults to 0.
Returns:
torch.Tensor: Flags indicating whether the anchors are inside a \
valid range.
"""
img_h, img_w = img_shape[:2]
# 被允许的边界
if allowed_border >= 0:
inside_flags = valid_flags & \ #首先是之前计算出来的有效值校验结果
(flat_anchors[:, 0] >= -allowed_border) & \ # 确定左上角坐标的x值是否大于0或Z
(flat_anchors[:, 1] >= -allowed_border) & \ # 确定左上角坐标的y值是否大于0或Z
(flat_anchors[:, 2] < img_w + allowed_border) & \ # 确定右下角坐标的x值是否小于图像宽度
(flat_anchors[:, 3] < img_h + allowed_border)# 确定右下角坐标的y值是否小于图像高度
else:
inside_flags = valid_flags
return inside_flags
16.链接到14中的「十五」方法:
def assign(self, bboxes, gt_bboxes, gt_bboxes_ignore=None, gt_labels=None):
"""Assign gt to bboxes.
This method assign a gt bbox to every bbox (proposal/anchor), each bbox
will be assigned with -1, or a semi-positive number. -1 means negative
sample, semi-positive number is the index (0-based) of assigned gt.
The assignment is done in following steps, the order matters.
1. assign every bbox to the background
2. assign proposals whose iou with all gts < neg_iou_thr to 0
3. for each bbox, if the iou with its nearest gt >= pos_iou_thr,
assign it to that bbox
4. for each gt bbox, assign its nearest proposals (may be more than
one) to itself
Args:
bboxes (Tensor): Bounding boxes to be assigned, shape(n, 4).
gt_bboxes (Tensor): Groundtruth boxes, shape (k, 4).
gt_bboxes_ignore (Tensor, optional): Ground truth bboxes that are
labelled as `ignored`, e.g., crowd boxes in COCO.
gt_labels (Tensor, optional): Label of gt_bboxes, shape (k, ).
Returns:
:obj:`AssignResult`: The assign result.
Example:
>>> self = MaxIoUAssigner(0.5, 0.5)
>>> bboxes = torch.Tensor([[0, 0, 10, 10], [10, 10, 20, 20]])
>>> gt_bboxes = torch.Tensor([[0, 0, 10, 9]])
>>> assign_result = self.assign(bboxes, gt_bboxes)
>>> expected_gt_inds = torch.LongTensor([1, 0])
>>> assert torch.all(assign_result.gt_inds == expected_gt_inds)
"""
# 判断gt框的数量是否超出允许在gpu上进行正负样本划分的阈值,超过则选用CPU
assign_on_cpu = True if (self.gpu_assign_thr > 0) and (
gt_bboxes.shape[0] > self.gpu_assign_thr) else False
# compute overlap and assign gt on CPU when number of GT is large
if assign_on_cpu:
device = bboxes.device
bboxes = bboxes.cpu()
gt_bboxes = gt_bboxes.cpu()
if gt_bboxes_ignore is not None:
gt_bboxes_ignore = gt_bboxes_ignore.cpu()
if gt_labels is not None:
gt_labels = gt_labels.cpu()
overlaps = self.iou_calculator(gt_bboxes, bboxes) 「十六」 # 计算IOU的值
# 这部分是计算iof的
if (self.ignore_iof_thr > 0 and gt_bboxes_ignore is not None
and gt_bboxes_ignore.numel() > 0 and bboxes.numel() > 0):
if self.ignore_wrt_candidates:
ignore_overlaps = self.iou_calculator(
bboxes, gt_bboxes_ignore, mode='iof')
ignore_max_overlaps, _ = ignore_overlaps.max(dim=1)
else:
ignore_overlaps = self.iou_calculator(
gt_bboxes_ignore, bboxes, mode='iof')
ignore_max_overlaps, _ = ignore_overlaps.max(dim=0)
overlaps[:, ignore_max_overlaps > self.ignore_iof_thr] = -1
#
assign_result = self.assign_wrt_overlaps(overlaps, gt_labels) 「十七」
if assign_on_cpu:
assign_result.gt_inds = assign_result.gt_inds.to(device)
assign_result.max_overlaps = assign_result.max_overlaps.to(device)
if assign_result.labels is not None:
assign_result.labels = assign_result.labels.to(device)
return assign_result
17.链接到16中的「十六」方法:
class BboxOverlaps2D(object):
"""2D Overlaps (e.g. IoUs, GIoUs) Calculator."""
def __call__(self, bboxes1, bboxes2, mode='iou', is_aligned=False):
"""Calculate IoU between 2D bboxes.
Args:
bboxes1 (Tensor): bboxes have shape (m, 4) in
format, or shape (m, 5) in format.
bboxes2 (Tensor): bboxes have shape (m, 4) in
format, shape (m, 5) in format, or be
empty. If ``is_aligned `` is ``True``, then m and n must be
equal.
mode (str): "iou" (intersection over union), "iof" (intersection
over foreground), or "giou" (generalized intersection over
union).
is_aligned (bool, optional): If True, then m and n must be equal.
Default False.
Returns:
Tensor: shape (m, n) if ``is_aligned `` is False else shape (m,)
"""
assert bboxes1.size(-1) in [0, 4, 5]
assert bboxes2.size(-1) in [0, 4, 5]
if bboxes2.size(-1) == 5:
bboxes2 = bboxes2[..., :4]
if bboxes1.size(-1) == 5:
bboxes1 = bboxes1[..., :4]
return bbox_overlaps(bboxes1, bboxes2, mode, is_aligned)
def bbox_overlaps(bboxes1, bboxes2, mode='iou', is_aligned=False, eps=1e-6):
"""Calculate overlap between two set of bboxes.
# 计算两个bbox集合的重叠度
If ``is_aligned `` is ``False``, then calculate the overlaps between each
bbox of bboxes1 and bboxes2, otherwise the overlaps between each aligned
pair of bboxes1 and bboxes2.
# 如果设置is_aligned为真,则会取bboxex1和bboxes2相对应的元素进行计算,反之,会取每一个bboxes1和每个bboxes2的元素进行计算
Args:
bboxes1 (Tensor): shape (B, m, 4) in format or empty.
bboxes2 (Tensor): shape (B, n, 4) in format or empty.
B indicates the batch dim, in shape (B1, B2, ..., Bn).
If ``is_aligned `` is ``True``, then m and n must be equal.
mode (str): "iou" (intersection over union) or "iof" (intersection over
foreground).
is_aligned (bool, optional): If True, then m and n must be equal.
Default False.
eps (float, optional): A value added to the denominator for numerical
stability. Default 1e-6.
Returns:
Tensor: shape (m, n) if ``is_aligned `` is False else shape (m,)
Example:
>>> bboxes1 = torch.FloatTensor([
>>> [0, 0, 10, 10],
>>> [10, 10, 20, 20],
>>> [32, 32, 38, 42],
>>> ])
>>> bboxes2 = torch.FloatTensor([
>>> [0, 0, 10, 20],
>>> [0, 10, 10, 19],
>>> [10, 10, 20, 20],
>>> ])
>>> overlaps = bbox_overlaps(bboxes1, bboxes2)
>>> assert overlaps.shape == (3, 3)
>>> overlaps = bbox_overlaps(bboxes1, bboxes2, is_aligned=True)
>>> assert overlaps.shape == (3, )
Example:
>>> empty = torch.empty(0, 4)
>>> nonempty = torch.FloatTensor([[0, 0, 10, 9]])
>>> assert tuple(bbox_overlaps(empty, nonempty).shape) == (0, 1)
>>> assert tuple(bbox_overlaps(nonempty, empty).shape) == (1, 0)
>>> assert tuple(bbox_overlaps(empty, empty).shape) == (0, 0)
"""
assert mode in ['iou', 'iof', 'giou'], f'Unsupported mode {mode}'
# Either the boxes are empty or the length of boxes's last dimenstion is 4
assert (bboxes1.size(-1) == 4 or bboxes1.size(0) == 0)
assert (bboxes2.size(-1) == 4 or bboxes2.size(0) == 0)
# Batch dim must be the same
# Batch dim: (B1, B2, ... Bn)
# 确保维度一致
assert bboxes1.shape[:-2] == bboxes2.shape[:-2]
batch_shape = bboxes1.shape[:-2]
# 取到个数
rows = bboxes1.size(-2)
cols = bboxes2.size(-2)
# 针对对齐的情况
if is_aligned:
assert rows == cols
# 针对有为空的情况
if rows * cols == 0:
if is_aligned:
return bboxes1.new(batch_shape + (rows, ))
else:
return bboxes1.new(batch_shape + (rows, cols))
# 计算bboxes1的面积
area1 = (bboxes1[..., 2] - bboxes1[..., 0]) * (
bboxes1[..., 3] - bboxes1[..., 1])
# 计算bboxes2的面积
area2 = (bboxes2[..., 2] - bboxes2[..., 0]) * (
bboxes2[..., 3] - bboxes2[..., 1])
if is_aligned:
lt = torch.max(bboxes1[..., :2], bboxes2[..., :2]) # [B, rows, 2]
rb = torch.min(bboxes1[..., 2:], bboxes2[..., 2:]) # [B, rows, 2]
wh = (rb - lt).clamp(min=0) # [B, rows, 2]
overlap = wh[..., 0] * wh[..., 1]
if mode in ['iou', 'giou']:
union = area1 + area2 - overlap
else:
union = area1
if mode == 'giou':
enclosed_lt = torch.min(bboxes1[..., :2], bboxes2[..., :2])
enclosed_rb = torch.max(bboxes1[..., 2:], bboxes2[..., 2:])
else:
# 计算两个bbox相交的最左上角坐标
# 假设bboxes1有2个,bboxes2有3个
# 则 lt和rb的结果为(2,3,2)表示每个bboxes1和每个bboxes2间的最大值ltx,lty或最小值rbx,rby
# 感觉这里有点错误
lt = torch.max(bboxes1[..., :, None, :2],
bboxes2[..., None, :, :2]) # [B, rows, cols, 2]
rb = torch.min(bboxes1[..., :, None, 2:],
bboxes2[..., None, :, 2:]) # [B, rows, cols, 2]
# 相减直接得到宽高,限制最小值最少为0
wh = (rb - lt).clamp(min=0) # [B, rows, cols, 2]
# 相乘直接得到相交面积
overlap = wh[..., 0] * wh[..., 1]
if mode in ['iou', 'giou']:
# 将area1和area2分别扩维相加再减去重叠部分
union = area1[..., None] + area2[..., None, :] - overlap
else:
union = area1[..., None]
if mode == 'giou':
enclosed_lt = torch.min(bboxes1[..., :, None, :2],
bboxes2[..., None, :, :2])
enclosed_rb = torch.max(bboxes1[..., :, None, 2:],
bboxes2[..., None, :, 2:])
# 分母上增加的数值以保证数值稳定性,防止分母为0
eps = union.new_tensor([eps])
union = torch.max(union, eps)
ious = overlap / union
if mode in ['iou', 'iof']:
# 返回计算的IOU
return ious
# calculate gious
enclose_wh = (enclosed_rb - enclosed_lt).clamp(min=0)
enclose_area = enclose_wh[..., 0] * enclose_wh[..., 1]
enclose_area = torch.max(enclose_area, eps)
gious = ious - (enclose_area - union) / enclose_area
return gious
18.链接到16中的「十七」方法:
def assign_wrt_overlaps(self, overlaps, gt_labels=None):
"""Assign w.r.t. the overlaps of bboxes with gts.
# overlaps是k个gt框和n个anchors的IOU值结果,shape为(k,n)
Args:
overlaps (Tensor): Overlaps between k gt_bboxes and n bboxes,
shape(k, n).
gt_labels (Tensor, optional): Labels of k gt_bboxes, shape (k, ).
Returns:
:obj:`AssignResult`: The assign result.
"""
num_gts, num_bboxes = overlaps.size(0), overlaps.size(1)
# 1. assign -1 by default
# 创建一个值为-1,shape为(n,)的张量
assigned_gt_inds = overlaps.new_full((num_bboxes,),
-1,
dtype=torch.long)
# 考虑没有gt框或没有有效anchor的情况
if num_gts == 0 or num_bboxes == 0:
# No ground truth or boxes, return empty assignment
max_overlaps = overlaps.new_zeros((num_bboxes,))
if num_gts == 0:
# No truth, assign everything to background
assigned_gt_inds[:] = 0
if gt_labels is None:
assigned_labels = None
else:
assigned_labels = overlaps.new_full((num_bboxes,),
-1,
dtype=torch.long)
return AssignResult(
num_gts,
assigned_gt_inds,
max_overlaps,
labels=assigned_labels)
# for each anchor, which gt best overlaps with it
# for each anchor, the max iou of all gts
# overlaps的维度是k×n
# max_overlaps是n个anchors中的每一个跟gt框有最大IOU的值,形状为(n,)
# argmax_overlaps的shape为(n,)是max_overlaps其中对应的k的下标(即指明当前anchor和哪个gt框iou最大)
# 指明当前anchor和哪个gt框iou最大,值是多少
max_overlaps, argmax_overlaps = overlaps.max(dim=0)
# for each gt, which anchor best overlaps with it
# for each gt, the max iou of all proposals
# 指明当前gt框和哪个anchor框iou最大,值是多少
gt_max_overlaps, gt_argmax_overlaps = overlaps.max(dim=1)
# 2. assign negative: below
# the negative inds are set to be 0
# 划分负样本,根据max_overlaps中的iou值,可得每个anchor与哪个gt框最吻合,iou值为多少
# 只要max_overlaps的值大于0且小于设定的neg_iou_thr阈值,便划分为负样本
# 负样本的值为0
if isinstance(self.neg_iou_thr, float):
assigned_gt_inds[(max_overlaps >= 0)
& (max_overlaps < self.neg_iou_thr)] = 0
elif isinstance(self.neg_iou_thr, tuple):
assert len(self.neg_iou_thr) == 2
assigned_gt_inds[(max_overlaps >= self.neg_iou_thr[0])
& (max_overlaps < self.neg_iou_thr[1])] = 0
# 3. assign positive: above positive IoU threshold
# 划分正样本,max_overlaps大于设定的正样本阈值,即划分为正样本
pos_inds = max_overlaps >= self.pos_iou_thr
# 将大于正样本阈值的对应项从argmax_overlaps中取出值并+1
# 赋值给assigned_gt_inds对应的位置的项
# 此时assigned_gt_inds中,负样本为0,正样本的值为[1,k],默认为-1为背景
assigned_gt_inds[pos_inds] = argmax_overlaps[pos_inds] + 1
# 这一步是将更多匹配值较低的anchor赋为正样本(或许会小于pos_iou_thr)
# 赋值可能会将步骤3中的一些正样本划分重写
if self.match_low_quality:
# Low-quality matching will overwirte the assigned_gt_inds assigned
# in Step 3. Thus, the assigned gt might not be the best one for
# prediction.
# For example, if bbox A has 0.9 and 0.8 iou with GT bbox 1 & 2,
# bbox 1 will be assigned as the best target for bbox A in step 3.
# However, if GT bbox 2's gt_argmax_overlaps = A, bbox A's
# assigned_gt_inds will be overwritten to be bbox B.
# 重点:This might be the reason that it is not used in ROI Heads.这或许是不在ROI头部网络中使用match_low_quality的原因,指的是覆盖步骤三的样本划分
# 按照gt框的匹配值来划分正样本
for i in range(num_gts):
# 取到第i个gt框的最大iou,判断是否大于min_pos_iou
if gt_max_overlaps[i] >= self.min_pos_iou:
# gt_max_assign_all标志位是指是否匹配更多同值的anchor框,例如gt框最大iou值为0.5,同时有多个anchor的iou值为0.5,将其全部划分为正样本
if self.gt_max_assign_all:
max_iou_inds = overlaps[i, :] == gt_max_overlaps[i]
assigned_gt_inds[max_iou_inds] = i + 1
else:
assigned_gt_inds[gt_argmax_overlaps[i]] = i + 1
if gt_labels is not None:
assigned_labels = assigned_gt_inds.new_full((num_bboxes,), -1)
pos_inds = torch.nonzero(
assigned_gt_inds > 0, as_tuple=False).squeeze()
if pos_inds.numel() > 0:
assigned_labels[pos_inds] = gt_labels[
assigned_gt_inds[pos_inds] - 1]
else:
assigned_labels = None
return AssignResult(
num_gts, assigned_gt_inds, max_overlaps, labels=assigned_labels) 「十八」#存储
19.链接到18中的「十八」方法:
class AssignResult(util_mixins.NiceRepr):
"""Stores assignments between predicted and truth boxes.
存储预测框Gt框的样本划分结果
Attributes:
num_gts (int): the number of truth boxes considered when computing this
assignment
# 指的是GT框的个数
gt_inds (LongTensor): for each predicted box indicates the 1-based
index of the assigned truth box. 0 means unassigned and -1 means
ignore.
# 指的是对应的每个anchor的assigned情况,默认-1代表背景并忽略,0为负样本,[1,num_gts]为正样本
max_overlaps (FloatTensor): the iou between the predicted box and its
assigned truth box.
# 每个anchor最大IOU值
labels (None | LongTensor): If specified, for each predicted box
indicates the category label of the assigned truth box.
Example:
>>> # An assign result between 4 predicted boxes and 9 true boxes
>>> # where only two boxes were assigned.
>>> num_gts = 9
>>> max_overlaps = torch.LongTensor([0, .5, .9, 0])
>>> gt_inds = torch.LongTensor([-1, 1, 2, 0])
>>> labels = torch.LongTensor([0, 3, 4, 0])
>>> self = AssignResult(num_gts, gt_inds, max_overlaps, labels)
>>> print(str(self)) # xdoctest: +IGNORE_WANT
>>> # Force addition of gt labels (when adding gt as proposals)
>>> new_labels = torch.LongTensor([3, 4, 5])
>>> self.add_gt_(new_labels)
>>> print(str(self)) # xdoctest: +IGNORE_WANT
"""
def __init__(self, num_gts, gt_inds, max_overlaps, labels=None):
self.num_gts = num_gts
self.gt_inds = gt_inds
self.max_overlaps = max_overlaps
self.labels = labels
# Interface for possible user-defined properties
self._extra_properties = {}
20.链接到14中的「十九」方法:
def sample(self,
assign_result,
bboxes,
gt_bboxes,
gt_labels=None,
**kwargs):
"""Sample positive and negative bboxes.
# 采样正负样本
This is a simple implementation of bbox sampling given candidates,
assigning results and ground truth bboxes.
Args:
assign_result (:obj:`AssignResult`): Bbox assigning results.
bboxes (Tensor): Boxes to be sampled from.
gt_bboxes (Tensor): Ground truth bboxes.
gt_labels (Tensor, optional): Class labels of ground truth bboxes.
Returns:
:obj:`SamplingResult`: Sampling result.
Example:
>>> from mmdet.core.bbox import RandomSampler
>>> from mmdet.core.bbox import AssignResult
>>> from mmdet.core.bbox.demodata import ensure_rng, random_boxes
>>> rng = ensure_rng(None)
>>> assign_result = AssignResult.random(rng=rng)
>>> bboxes = random_boxes(assign_result.num_preds, rng=rng)
>>> gt_bboxes = random_boxes(assign_result.num_gts, rng=rng)
>>> gt_labels = None
>>> self = RandomSampler(num=32, pos_fraction=0.5, neg_pos_ub=-1,
>>> add_gt_as_proposals=False)
>>> self = self.sample(assign_result, bboxes, gt_bboxes, gt_labels)
"""
# 维度矫正
if len(bboxes.shape) < 2:
bboxes = bboxes[None, :]
# 或许会有5维的情况
bboxes = bboxes[:, :4]
# 创建和anchors长度一样的tensor,值为0
gt_flags = bboxes.new_zeros((bboxes.shape[0], ), dtype=torch.uint8)
if self.add_gt_as_proposals and len(gt_bboxes) > 0:
if gt_labels is None:
raise ValueError(
'gt_labels must be given when add_gt_as_proposals is True')
bboxes = torch.cat([gt_bboxes, bboxes], dim=0)
assign_result.add_gt_(gt_labels)
gt_ones = bboxes.new_ones(gt_bboxes.shape[0], dtype=torch.uint8)
gt_flags = torch.cat([gt_ones, gt_flags])
# num_expected_pos指的是期望得到的正样本的数目
num_expected_pos = int(self.num * self.pos_fraction)
pos_inds = self.pos_sampler._sample_pos(
assign_result, num_expected_pos, bboxes=bboxes, **kwargs) 「二十」#得到正样本采样
# We found that sampled indices have duplicated items occasionally.
# (may be a bug of PyTorch)
# 去重
pos_inds = pos_inds.unique()
# 统计正样本个数
num_sampled_pos = pos_inds.numel()
# 计算期望得到的负样本个数
num_expected_neg = self.num - num_sampled_pos
# TODO
if self.neg_pos_ub >= 0:
_pos = max(1, num_sampled_pos)
neg_upper_bound = int(self.neg_pos_ub * _pos)
if num_expected_neg > neg_upper_bound:
num_expected_neg = neg_upper_bound
neg_inds = self.neg_sampler._sample_neg(
assign_result, num_expected_neg, bboxes=bboxes, **kwargs) 「二十一」# 得到负样本采样
neg_inds = neg_inds.unique()
sampling_result = SamplingResult(pos_inds, neg_inds, bboxes, gt_bboxes,
assign_result, gt_flags) 「二十二」
return sampling_result
21.链接到20中的「二十」方法:
def _sample_pos(self, assign_result, num_expected, **kwargs):
"""Randomly sample some positive samples."""
# torch.nonzero找到目标中不为0元素的下标
# assign_result.gt_inds > 0指的是被划分为正样本的元素
pos_inds = torch.nonzero(assign_result.gt_inds > 0, as_tuple=False)
# pos_inds.numel()是统计元素数目
if pos_inds.numel() != 0:
# 压缩维度,一般在这里压缩为一维
pos_inds = pos_inds.squeeze(1)
# 判断 正样本个数是否超出预期的数目 num_expected
if pos_inds.numel() <= num_expected:
# 没有超出直接返回
return pos_inds
else:
# 若超出,则随机选择num_expected个
return self.random_choice(pos_inds, num_expected)
22.链接到20中的「二十一」方法:
def _sample_neg(self, assign_result, num_expected, **kwargs):
"""Randomly sample some negative samples."""
# torch.nonzero找到目标中不为0元素的下标(注意assign_result.gt_inds == 0返回的值是bool),所以此处得到的结果是返回结果为真的下标
# assign_result.gt_inds == 0指的是被划分为负样本的项
neg_inds = torch.nonzero(assign_result.gt_inds == 0, as_tuple=False)
if neg_inds.numel() != 0:
neg_inds = neg_inds.squeeze(1)
if len(neg_inds) <= num_expected:
return neg_inds
else:
return self.random_choice(neg_inds, num_expected)
23.链接到20中的「二十二」方法:
class SamplingResult(util_mixins.NiceRepr):
"""Bbox sampling result.
Example:
>>> # xdoctest: +IGNORE_WANT
>>> from mmdet.core.bbox.samplers.sampling_result import * # NOQA
>>> self = SamplingResult.random(rng=10)
>>> print(f'self = {self}')
self =
"""
def __init__(self, pos_inds, neg_inds, bboxes, gt_bboxes, assign_result,
gt_flags):
# 正样本下标
self.pos_inds = pos_inds
# 负样本下标
self.neg_inds = neg_inds
# 正样本框
self.pos_bboxes = bboxes[pos_inds]
# 负样本框
self.neg_bboxes = bboxes[neg_inds]
# TODO
self.pos_is_gt = gt_flags[pos_inds]
# gt框个数
self.num_gts = gt_bboxes.shape[0]
# 正样本划分的anchor对应gt框
self.pos_assigned_gt_inds = assign_result.gt_inds[pos_inds] - 1
if gt_bboxes.numel() == 0:
# hack for index error case
assert self.pos_assigned_gt_inds.numel() == 0
self.pos_gt_bboxes = torch.empty_like(gt_bboxes).view(-1, 4)
else:
if len(gt_bboxes.shape) < 2:
gt_bboxes = gt_bboxes.view(-1, 4)
# 正样本划分的anchor对应gt框的值
self.pos_gt_bboxes = gt_bboxes[self.pos_assigned_gt_inds, :]
if assign_result.labels is not None:
self.pos_gt_labels = assign_result.labels[pos_inds]
else:
self.pos_gt_labels = None
24.链接到14中的「二十三」方法:
def encode(self, bboxes, gt_bboxes):
"""Get box regression transformation deltas that can be used to
transform the ``bboxes`` into the ``gt_bboxes``.
Args:
bboxes (torch.Tensor): Source boxes, e.g., object proposals.
gt_bboxes (torch.Tensor): Target of the transformation, e.g.,
ground-truth boxes.
Returns:
torch.Tensor: Box transformation deltas
"""
assert bboxes.size(0) == gt_bboxes.size(0)
assert bboxes.size(-1) == gt_bboxes.size(-1) == 4
encoded_bboxes = bbox2delta(bboxes, gt_bboxes, self.means, self.stds) 「二十四」# 将anchors和gt框进行编码
return encoded_bboxes
25.链接到24中的「二十四」方法:
def bbox2delta(proposals, gt, means=(0., 0., 0., 0.), stds=(1., 1., 1., 1.)):
"""Compute deltas of proposals w.r.t. gt.
We usually compute the deltas of x, y, w, h of proposals w.r.t ground
truth bboxes to get regression target.
This is the inverse function of :func:`delta2bbox`.
Args:
proposals (Tensor): Boxes to be transformed, shape (N, ..., 4)
gt (Tensor): Gt bboxes to be used as base, shape (N, ..., 4)
means (Sequence[float]): Denormalizing means for delta coordinates
stds (Sequence[float]): Denormalizing standard deviation for delta
coordinates
Returns:
Tensor: deltas with shape (N, 4), where columns represent dx, dy,
dw, dh.
"""
# 判断维度
assert proposals.size() == gt.size()
# 转为浮点
proposals = proposals.float()
gt = gt.float()
# 计算中心点以及宽高
px = (proposals[..., 0] + proposals[..., 2]) * 0.5
py = (proposals[..., 1] + proposals[..., 3]) * 0.5
pw = proposals[..., 2] - proposals[..., 0]
ph = proposals[..., 3] - proposals[..., 1]
gx = (gt[..., 0] + gt[..., 2]) * 0.5
gy = (gt[..., 1] + gt[..., 3]) * 0.5
gw = gt[..., 2] - gt[..., 0]
gh = gt[..., 3] - gt[..., 1]
# 计算偏差
dx = (gx - px) / pw
dy = (gy - py) / ph
dw = torch.log(gw / pw)
dh = torch.log(gh / ph)
deltas = torch.stack([dx, dy, dw, dh], dim=-1)
# 均值与方差
means = deltas.new_tensor(means).unsqueeze(0)
stds = deltas.new_tensor(stds).unsqueeze(0)
# 每个值减均值除方差
deltas = deltas.sub_(means).div_(stds)
return deltas