使用python预测基金
This tutorial was created to democratize data science for business users (i.e., minimize usage of advanced mathematics topics) and alleviate personal frustration we have experienced on following tutorials and struggling to apply that same tutorial for our needs. Considering this, our mission is as follows:
创建本教程的目的是使业务用户的数据科学民主化(即,最大限度地减少高级数学主题的使用),并减轻我们在后续教程中遇到的个人挫败感,并努力将同一教程应用于我们的需求。 考虑到这一点,我们的任务如下:
Provide practical application of data science tasks with minimal usage of advanced mathematical topics
以最少的高级数学主题提供数据科学任务的实际应用
Only use a full set of data, which are similar to data we see in business environment and that are publicly available in a tutorial, instead of using simple data or snippets of data used by many tutorials
仅使用与我们在业务环境中看到的数据相似并且在教程中公开可用的全套数据,而不是使用简单数据或许多教程使用的数据片段
Clearly state the prerequisites at beginning of the tutorial. We will try to provide additional information on those prerequisites
在教程开始时清楚地说明先决条件。 我们将尝试提供有关这些先决条件的其他信息
Provide written tutorial on each topic to ensure all steps are easy to follow and clearly illustrated
提供有关每个主题的书面教程,以确保所有步骤都易于遵循并清楚地说明
1.说明(1. Description)
This is multi-part series on how-to create a forecast, using one of the most widely used data science tool — Python.
这是有关如何使用最广泛使用的数据科学工具之一Python创建预测的系列文章。
Forecasting is the process of making predictions of the future based on past and present data and its trends. The accuracy of forecast decreases as you stretch out your forecast. For example, if you are forecasting monthly sales then accuracy of forecast for month 1 sales of forecast will be higher than month 2 sales of forecast and so on. One of my co-workers likes to state that best way to predict tomorrow’s weather is to assume it is similar to today’s weather. Everything else is just a guess.
预测是根据过去和现在的数据及其趋势对未来进行预测的过程。 延伸预测时,预测的准确性会降低。 例如,如果您正在预测月度销售,则预测的第一个月的销售的预测准确性将高于预测的第二个月的销售,依此类推。 我的一位同事喜欢说,预测明天天气的最好方法是假设它与今天的天气相似。 其他所有只是猜测。
Forecasting Series consists of:
预测系列包括:
Part 1.1 — Create Forecast using Excel 2016/2019 (https://medium.com/@sungkim11/data-science-for-business-users-f4c050cbec96)
第1.1部分-使用Excel 2016/2019创建预测( https://medium.com/@sungkim11/data-science-for-business-users-f4c050cbec96 )
- Part 1.2 — Advanced Topics on Forecast using Excel 2016/2019 第1.2部分-使用Excel 2016/2019进行预测的高级主题
Part 2.1 — Create Forecast using Python — ARIMA (https://medium.com/@sungkim11/create-forecast-using-python-arima-part-2-1-efca5c5c14f3)
第2.1部分-使用Python创建预测-ARIMA( https://medium.com/@sungkim11/create-forecast-using-python-arima-part-2-1-efca5c5c14f3 )
- Part 2.2 — Advanced Topics on Forecast using Python — ARIMA 第2.2部分-使用Python进行预测的高级主题-ARIMA
- Part 2.3 — Extend Forecast (Python) to include What-If Analysis Capabilities — ARIMA 第2.3部分-扩展预测(Python)以包括假设分析功能-ARIMA
Part 3.1 — Create Forecast using Python — Prophet
第3.1部分-使用Python创建预测-先知
- Part 3.2 — Advanced Topics on Forecast using Python — Prophet第3.2部分-使用Python进行预测的高级主题-Prophet
- Part 3.3 — Extend Forecast (Python) to include What-If Analysis Capabilities — Prophet 第3.3部分-扩展预测(Python)以包括假设分析功能-先知
Part 4.1 — Create Forecast using Python — LSTM (https://medium.com/@sungkim11/create-forecast-using-python-lstm-4-1-1ab8b138a08f)
第4.1部分-使用Python创建预测-LSTM( https://medium.com/@sungkim11/create-forecast-using-python-lstm-4-1-1ab8b138a08f )
- Part 4.2 — Advanced Topics on Forecast using Python — LSTM 第4.2部分—使用Python进行预测的高级主题— LSTM
- Part 4.3 — Extend Forecast (Python) to include What-If Analysis Capabilities — LSTM 第4.3部分—扩展预测(Python)以包括假设分析功能— LSTM
Prophet is a procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and several seasons of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
先知是一种基于附加模型预测时间序列数据的过程,其中非线性趋势与每年,每周和每天的季节性以及假期影响相吻合。 它最适合具有强烈季节性影响和多个季节历史数据的时间序列。 先知对于丢失数据和趋势变化具有较强的鲁棒性,并且通常能够很好地处理异常值。
Prophet is open source software released by Facebook™’s Core Data Science team. It is available for download on CRAN and PyPI.
Prophet是Facebook™核心数据科学团队发布的开源软件。 它可以在CRAN和PyPI上下载。
Prophet is:
先知是:
- Accurate and fast: Prophet is used in many applications across Facebook for producing reliable forecasts for planning and goal setting. Facebook has found it to perform better than any other approach in the majority of cases. We fit models in Stan so that you get forecasts in just a few seconds. 准确,快速:Prophet在Facebook的许多应用程序中用于生成可靠的计划和目标设定预测。 Facebook发现,在大多数情况下,它比任何其他方法都有更好的表现。 我们在Stan中拟合模型,以便您在几秒钟内获得预测。
- Fully automatic: Get a reasonable forecast on messy data with no manual effort. Prophet is robust to outliers, missing data, and dramatic changes in your time series. 全自动:无需人工即可获得有关杂乱数据的合理预测。 先知对异常值,丢失的数据以及时间序列中的急剧变化具有鲁棒性。
- Tunable forecasts: The Prophet procedure includes many possibilities for users to tweak and adjust forecasts. You can use human-interpretable parameters to improve your forecast by adding your domain knowledge. 可调整的预测:“先知”过程为用户提供了许多调整和调整预测的可能性。 您可以使用人类可以解释的参数来添加自己的领域知识,从而改善预测效果。
- Available in R or Python: Facebook has implemented the Prophet procedure in R and Python, but they share the same underlying Stan code for fitting. Use whatever language you’re comfortable with to get forecasts. 可在R或Python中使用:Facebook已在R和Python中实现了Prophet过程,但它们共享相同的基础Stan代码以进行拟合。 使用您喜欢的任何语言来获取预测。
2.先决条件 (2. Prerequisites)
Following are prerequisite software for this tutorial:
以下是本教程的必备软件:
- [x] Python (Download Anaconda Python from here => https://www.anaconda.com/download/ and install on your computer.)
- [x] Python Package: fbprophet (Install using "conda install -c conda-forge fbprophet" in your Anaconda Prompt). All other python packages used in this tutorial comes with Anaconda Python.You can also use Google Colab (https://colab.research.google.com/) as we have done for this tutorial.Following are prerequisite knowledge for this tutorial:
以下是本教程的先决知识:
- [x] Create Forecast Using Excel 2016/2019 tutorial
- [x] Basic knowledge Python (You really do not need to be expert in python to use python for data science tasks. Many data scientists supplement their basic knowledge of python with google :-) to complete their tasks. We will provide a tutorial soon...
- [x] Basic knowledge installing Python packages (Good news is that Anaconda simplifies this for you somewhat, but they only have limited selection of packages you may need - e.g., pmdarima, which is used in this tutorial cannot be installed using this method). We will provide a tutorial soon...
- [x] Basic knowledge Jupyter Notebook/Lab (Good news is that Jupyter Notebook/Lab is easy to use and learn). We will provide a tutorial soon...
- [x] Basic knowledge Pandas (Pandas is data analysis tools for the Python programming language. This is one of the tool where more you know will make your job easier and there is always google :-). We will provide a tutorial soon...
- [x] Basic knowledge statistical data visualization tool, such as matplotlib, seaborn, bokeh, or plotly (These are data visualization tool for the Python programming language. These are a set of the tool where more you know will make your job easier and there is always google :-). We will provide a tutorial soon...
- [x] Historical data with same frequency (e.g., hourly, daily, weekly, monthly, quarterly, yearly, etc.), to create a forecast. This is important since you cannot create a forecast without historical data that does not have same frequency. If your data does not follow same frequency, then aggregate your data so it will be same frequency. For example, if your data consists of any random two days per week then aggregate (i.e., sum up those two days) your data into a weekly data then create a forecast using aggregated data.3.步骤 (3. Steps)
Please follow the step by step instructions, which is divided into 8 major steps as shown below:
请按照分步说明进行操作,该说明分为8个主要步骤,如下所示:
- Get Data 获取数据
- Format Data格式化数据
- Import Data汇入资料
- Cleanse Data清理数据
- Analyze Data分析数据
- Prep Data准备数据
- Develop and Validate Forecast Model开发和验证预测模型
- Maintain Forecast维持预测
3.1。 获取数据 (3.1. Get Data)
United Stated Census Bureau maintains Monthly Retail Trade Report, from January 1992 to Present. This data was picked to illustrate forecasting because it has extensive historical data with same monthly frequency. Data is available as Excel spreadsheet format at https://www.census.gov/retail/mrts/www/mrtssales92-present.xls
美国人口普查局维护从1992年1月至今的每月零售贸易报告。 选择该数据是为了说明预测,因为它具有每月频率相同的大量历史数据。 数据以Excel电子表格格式提供,网址为https://www.census.gov/retail/mrts/www/mrtssales92-present.xls
1. Click on the link to save Excel spreadsheet to your local directory/folder.
1.单击链接以将Excel电子表格保存到本地目录/文件夹。
2. Open the Excel spreadsheet (i.e., Monthly Trade Report).
2.打开Excel电子表格(即每月贸易报告)。
3. Monthly Retail Trade Report is organized by year where each year from 1992 to 2018 are separated by worksheet. Within each worksheet, there are two different types of figures — not adjusted and adjusted. For each type, there is summary set of figures followed by more detailed figure, organized by NAICS Code (i.e., North American Industry Classification System — the standard used by Federal statistical agencies in classifying business establishments for the purpose of collecting, analyzing, and publishing statistical data related to the U.S. business economy).
3.月度零售贸易报告按年份组织,其中1992年至2018年之间每年均按工作表分开。 在每个工作表中,有两种不同类型的数字-未调整和已调整。 对于每种类型,都有一组摘要图,然后是更详细的图,这些图由NAICS代码组织(即北美行业分类系统,这是联邦统计机构用于对企业进行分类以收集,分析和发布的标准)与美国商业经济有关的统计数据)。
3.2。 格式化数据 (3.2. Format Data)
We will need to format the data in Monthly Trade Report, so we can create a forecast from consolidated multiple years of data. At the same time, this data is bit more extensive then we would like, so we will be filtering data as follow:
我们将需要在“每月贸易报告”中格式化数据,以便我们可以根据合并的多年数据创建预测。 同时,此数据比我们想要的要广泛得多,因此我们将按以下方式过滤数据:
- Use January 2005 to Present time to ensure cyclic behavior (full economic cycle with boom and recession) is represented in our data 使用2005年1月来表示时间,以确保周期性行为(充满景气和衰退的整个经济周期)体现在我们的数据中
- Use “NOT ADJUSTED” data as illustrated on cell line 7 to line 12 on the spreadsheet. Other data is nice, but it is bit much for our needs 使用电子表格上第7行到第12行中所示的“ NOT ADJUSTED”数据。 其他数据很好,但是可以满足我们的需求
1. Insert a new worksheet, entitled “Forecast”.
1.插入一个新的工作表,标题为“ Forecast”。
2. Copy and paste data from 2005 worksheet into “Forecast” worksheet. When pasting data, use “Transpose” option on Paste. It is easier to scroll up and down then scroll sideways to see the data.
2.将2005年工作表中的数据复制并粘贴到“预测”工作表中。 粘贴数据时,请在“粘贴”上使用“移调”选项。 上下滚动然后横向滚动查看数据会更容易。
3. Repeat the step 2 for 2006 thru 2018.
3.重复2006年到2018年的步骤2。
4. Copy and paste column label at top of pasted data. Again when pasting data, use “Transpose” option on paste.
4.复制列标签并将其粘贴在粘贴数据的顶部。 再次粘贴数据时,在粘贴上使用“转置”选项。
5. Insert date column at left of pasted data, start with 01/01/2005 on first row then 02/01/2005 on second row then fill the rows with date. The end date should be 10/01/2018.
5.在粘贴数据的左侧插入日期列,从第一行的01/01/2005开始,然后在第二行的02/01/2005开始,然后用日期填充行。 结束日期应该是10/01/2018。
6. Save the spreadsheet as mrtssales92-present_step2.xlsx.
6.将电子表格另存为mrtssales92-present_step2.xlsx。
3.3。 汇入资料 (3.3. Import Data)
Unlike Excel, which is all in one application, you will need to import data into python — specifically pandas (Python Data Analysis Library), which is python’s in-memory database where you can perform data analysis and modeling.
与Excel完全集成在一个应用程序中不同,您需要将数据导入python-特别是pandas(Python数据分析库),它是python的内存数据库,您可以在其中执行数据分析和建模。
3.3.1. Export Excel data to CSV file
3.3.1。 将Excel数据导出到CSV文件
1. Open Excel worksheet, entitled “mrtssales92-present_step2.xlsx”.
1.打开Excel工作表,标题为“ mrtssales92-present_step2.xlsx”。
2. Navigate to “Forecast” worksheet and convert all numbers to just number — e.g., 330000 instead of 330,000. Since 330000 is imported as number and 330,000 is imported as text. It is easier this way. Otherwise, you will need to programatically change data type.
2.导航到“预测”工作表,然后将所有数字转换为仅数字,例如330000而不是330,000。 由于330000作为数字导入,330,000作为文本导入。 这样比较容易。 否则,您将需要以编程方式更改数据类型。
3. Extend the date that currently ends on 10/1/2018 to 12/1/2020 since we will be creating forecast to December 2020.
3.因为我们将创建预测到2020年12月,所以将当前结束日期从10/1/2018延长到12/1/2020。
4. Save the worksheet as CSV file format, entitled “mrtssales92-present_step3.csv”.
4.将工作表另存为CSV文件格式,标题为“ mrtssales92-present_step3.csv”。
3.3.2. Import Python Packages
3.3.2。 导入Python包
Best analogy of Python as programming language is that of smart phone. Python is great programming language where you can accomplish a lot of tasks, just like brand new smart phone. Just like brand new smart phone, it is bit limited since it can only accomplish basic tasks without apps that excels at special tasks, such as Google Map. Python packages are similar to smart phone apps where these packages can accomplish specific tasks very well, such as pandas.
Python作为编程语言的最佳比喻是智能手机。 Python是一种很棒的编程语言,您可以在其中完成许多任务,就像全新的智能手机一样。 就像全新的智能手机一样,它也有一定的局限性,因为它只能完成基本任务,而没有能够执行特殊任务的应用程序,例如Google Map。 Python程序包类似于智能手机应用程序,其中这些程序包可以很好地完成特定任务,例如熊猫。
1. Install pmdarima python package
1.安装pmdarima python软件包
!pip install fbprophetRequirement already satisfied: fbprophet in /usr/local/lib/python3.6/dist-packages (0.6)
Requirement already satisfied: Cython>=0.22 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (0.29.21)
Requirement already satisfied: cmdstanpy==0.4 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (0.4.0)
Requirement already satisfied: pystan>=2.14 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (2.19.1.1)
Requirement already satisfied: numpy>=1.10.0 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (1.18.5)
Requirement already satisfied: pandas>=0.23.4 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (1.0.5)
Requirement already satisfied: matplotlib>=2.0.0 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (3.2.2)
Requirement already satisfied: LunarCalendar>=0.0.9 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (0.0.9)
Requirement already satisfied: convertdate>=2.1.2 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (2.2.1)
Requirement already satisfied: holidays>=0.9.5 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (0.9.12)
Requirement already satisfied: setuptools-git>=1.2 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (1.2)
Requirement already satisfied: python-dateutil>=2.8.0 in /usr/local/lib/python3.6/dist-packages (from fbprophet) (2.8.1)
Requirement already satisfied: pytz>=2017.2 in /usr/local/lib/python3.6/dist-packages (from pandas>=0.23.4->fbprophet) (2018.9)
Requirement already satisfied: pyparsing!=2.0.4,!=2.1.2,!=2.1.6,>=2.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.0.0->fbprophet) (2.4.7)
Requirement already satisfied: cycler>=0.10 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.0.0->fbprophet) (0.10.0)
Requirement already satisfied: kiwisolver>=1.0.1 in /usr/local/lib/python3.6/dist-packages (from matplotlib>=2.0.0->fbprophet) (1.2.0)
Requirement already satisfied: ephem>=3.7.5.3 in /usr/local/lib/python3.6/dist-packages (from LunarCalendar>=0.0.9->fbprophet) (3.7.7.1)
Requirement already satisfied: pymeeus<=1,>=0.3.6 in /usr/local/lib/python3.6/dist-packages (from convertdate>=2.1.2->fbprophet) (0.3.7)
Requirement already satisfied: six in /usr/local/lib/python3.6/dist-packages (from holidays>=0.9.5->fbprophet) (1.15.0)2. Import python packages so python can use them and show its version. Showing version is important since it will enable other users to replicate your work using same python version and python packages version.
2.导入python软件包,以便python可以使用它们并显示其版本。 显示版本很重要,因为它可以使其他用户使用相同的python版本和python软件包版本复制您的工作。
import pandas as pd
import matplotlib as plt
import fbprophet
from fbprophet import Prophet
import statsmodels
from statsmodels.tsa.seasonal import seasonal_decompose
import platform
import numpy as np
import sklearn
from sklearn.metrics import mean_squared_error
from pandas.tseries.offsets import MonthBegin
from pandas.tseries.offsets import MonthEnd/usr/local/lib/python3.6/dist-packages/statsmodels/tools/_testing.py:19: FutureWarning:
pandas.util.testing is deprecated. Use the functions in the public API at pandas.testing instead.print('Python: ', platform.python_version())
print('pandas: ', pd.__version__)
print('matplotlib: ', plt.__version__)
print('Prophet: ', fbprophet.__version__)
print('statsmodels: ', statsmodels.__version__)
print('NumPy: ', np.__version__)
print('sklearn: ', sklearn.__version__)Python: 3.6.9
pandas: 1.0.5
matplotlib: 3.2.2
Prophet: 0.6
statsmodels: 0.10.2
NumPy: 1.18.5
sklearn: 0.22.2.post1Very short explanation of python packages:
python软件包的简短说明:
- pandas: data analysis tool 熊猫:数据分析工具
- matplotlib: data visualization toolmatplotlib:数据可视化工具
- Prophet: procedure for forecasting time series data based on an additive model where non-linear trends are fit with yearly, weekly, and daily seasonality, plus holiday effects先知:基于加法模型预测时间序列数据的过程,其中非线性趋势与年,周和日的季节性相适应,加上假日影响
- statsmodels: statistical models toolstatsmodels:统计模型工具
- numpy: scientific computing toolnumpy:科学计算工具
- sklearn — machine learningsklearn-机器学习
3.3.3. Import data from newly created CSV file and specify that date column is index column.
3.3.3。 从新创建的CSV文件导入数据,并指定日期列为索引列。
#Upload file
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
#Assign uploaded file to pandas
monthly_retail_data = pd.read_csv(fn, index_col = 0)Upload widget is only available when the cell has been executed in the current browser session. Please rerun this cell to enable.
仅当在当前浏览器会话中执行了单元格时,上载小部件才可用。 请重新运行此单元格以启用。
Saving mrtssales92-present_part3_3.csv to mrtssales92-present_part3_3.csv
User uploaded file "mrtssales92-present_part3_3.csv" with length 9426 bytes3.3.4. Validate data is imported correctly
3.3.4。 验证数据是否正确导入
As shown below, date column is imported as index and all other columns are imported as number.
如下所示,日期列作为索引导入,所有其他列作为数字导入。
monthly_retail_data.info()
Index: 192 entries, 1/1/2005 to 12/1/2020
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Retail and food services sales, total 166 non-null float64
1 Retail sales and food services excl motor vehicle and parts 166 non-null float64
2 Retail sales and food services excl gasoline stations 166 non-null float64
3 Retail sales and food services excl motor vehicle and parts and gasoline stations 166 non-null float64
4 Retail sales, total 166 non-null float64
5 Retail sales, total (excl. motor vehicle and parts dealers) 166 non-null float64
dtypes: float64(6)
memory usage: 10.5+ KBYou can also display imported data.
您还可以显示导入的数据。
monthly_retail_dataNotes: There are no numbers after November 2018, which is displayed as NaN, which is just missing values. This makes sense since those dates were created as placeholder for forecast.
注意:2018年11月之后没有数字,显示为NaN,仅缺少值。 这是有道理的,因为这些日期被创建为预测的占位符。
3.3.5. Convert the index to date. Index needs to be datetime, which is required for time series data
3.3.5。 将索引转换为日期。 索引必须是日期时间,这是时间序列数据所必需的
monthly_retail_data.index = pd.to_datetime(monthly_retail_data.index)3.3.6. Validate that index has been converted to date where Index has been converted to DatetimeIndex
3.3.6。 验证索引已转换为日期,其中索引已转换为DatetimeIndex
monthly_retail_data.info()
DatetimeIndex: 192 entries, 2005-01-01 to 2020-12-01
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Retail and food services sales, total 166 non-null float64
1 Retail sales and food services excl motor vehicle and parts 166 non-null float64
2 Retail sales and food services excl gasoline stations 166 non-null float64
3 Retail sales and food services excl motor vehicle and parts and gasoline stations 166 non-null float64
4 Retail sales, total 166 non-null float64
5 Retail sales, total (excl. motor vehicle and parts dealers) 166 non-null float64
dtypes: float64(6)
memory usage: 10.5 KB3.4。 清理数据 (3.4. Cleanse Data)
After data has been formatted, we will need to cleanse data. There is a truism in saying that Garbage in Garbage out. Simple thing like if all numbers are stored as number needs to be checked.
数据格式化后,我们将需要清理数据。 说垃圾在垃圾里是不言而喻的。 简单的事情,例如是否所有数字都存储为数字需要检查。
Ensure all numbers are stored as number, not text. Same applies to both date and text. In addition, ensure all numbers, dates and text are consistent. If the number is not stored as number, but as text — e.g., 121K instead of 121,000, you will need to cleanse the data to ensure all numbers are stored as number. Imported Monthly Trade Report does not seem to have any dirty data, so this step is not need.
确保所有数字都存储为数字,而不是文本。 日期和文本均相同。 此外,请确保所有数字,日期和文本均一致。 如果数字不是存储为数字,而是存储为文本,例如121K而不是121,000,则需要清理数据以确保所有数字都存储为数字。 导入的每月贸易报告似乎没有任何脏数据,因此不需要此步骤。
3.5。 分析数据 (3.5. Analyze Data)
After data has been imported, we will be analyzing data to look for some specific items. Those items are:
导入数据后,我们将分析数据以查找某些特定项目。 这些项目是:
- Missing Data. It would be nice to have all data filled-in, but in real-life that is not always the case. We will need to identify all missing data and denote as such. 缺失数据。 填写所有数据会很好,但是在现实生活中并非总是如此。 我们将需要识别所有丢失的数据并以此表示。
- Outliers. Outliers happens. It would be nice to include them, but it will skew our forecast without additional benefits. We will need to identify all outliers and denote as such. 离群值。 发生异常值。 将它们包括在内会很不错,但会在没有其他好处的情况下歪曲我们的预测。 我们将需要识别所有异常值并以此表示。
- Seasonality. It is a characteristic of data in which data experiences regular and predictable changes which occur every year. This is important since if the historical data has seasonality then our forecast also needs to reflect this seasonality. 季节性。 它是数据的特征,其中数据会经历每年定期发生且可预测的更改。 这很重要,因为如果历史数据具有季节性,那么我们的预测也需要反映这种季节性。
- Cyclic Behavior. It takes place when there are regular fluctuations in the data which usually last for an interval of at least two years, such as economic recession or economic boom. 循环行为。 当数据定期波动至少持续两年(例如经济衰退或经济繁荣)时,就会发生这种情况。
3.5.1. Missing Data
3.5.1。 缺失数据
Formatted Monthly Trade Report seems to be fully populated, so this step is not need.
格式化的每月贸易报告似乎已完全填充,因此不需要此步骤。
3.5.2. Outliers
3.5.2。 离群值
Simplest way to detect outliers is to create a line chart of the data since the data points are limited in scope. Formatted Monthly Trade Report seems to be consistent from year to year, so this step is not need.
检测异常值的最简单方法是创建数据折线图,因为数据点的范围有限。 格式化的每月贸易报告似乎每年都保持一致,因此不需要此步骤。
3.5.3. Seasonality
3.5.3。 季节性
Simplest way to detect seasonality is to create a line chart for each of labeled data. Seasonality analysis will be shown below for each sales data.
检测季节性的最简单方法是为每个标记数据创建折线图。 季节性分析将在下面显示每个销售数据。
3.5.4. Cyclic Behavior
3.5.4。 循环行为
To detect if the data reflects cyclic behavior is to create a line chart for each of sales data. As you can see, the data reflects cyclic behavior where there was economic boom between 2005 thru 2006, followed by economic recession between 2007 thru 2009, followed by gradual increase in sales figure between 2010 thru 2015 then economic boom from 2016 to present. Cyclic Behavior analysis will be shown below for each sales data.
要检测数据是否反映出周期性行为,就是为每个销售数据创建一个折线图。 如您所见,数据反映了周期性行为,即2005年至2006年间经济繁荣,随后是2007年至2009年经济衰退,随后是2010年至2015年销售数字逐渐增长,然后是2016年至今的经济繁荣。 循环行为分析将在下面显示每个销售数据。
3.5.5. Filter the data to only historical or actuals since it does not make sense to analyze empty data
3.5.5。 将数据过滤为仅历史数据或实际数据,因为分析空数据没有意义
monthly_retail_actuals = monthly_retail_data.loc['2005-01-01':'2018-10-01']3.5.6. Configure chart
3.5.6。 配置图表
We will be setting chart size here since default chart is bit too small.
由于默认图表太小,我们将在此处设置图表大小。
# Get current size
fig_size = plt.rcParams["figure.figsize"]
# Set figure width to 12 and height to 9
fig_size[0] = 30
fig_size[1] = 5
plt.rcParams["figure.figsize"] = fig_size3.5.7. Analyze Retail and food services, total
3.5.7。 分析零售和食品服务,总计
3.5.7.1. Chart Retail and food services sales, total
3.5.7.1。 零售和食品服务销售额图表,总计
Now, let’s chart the data. We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty charts with python, but this will do for now.
现在,让我们绘制数据图表。 我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail and food services sales, total', kind='line', grid=1)
plt.pyplot.show()
Convert the index back to date again.
再次将索引转换回日期。
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.7.2. Decompose Retail and food services sales, total time series data
3.5.7.2。 分解零售和食品服务销售,总时间序列数据
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_and_food_services_sales_total_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail and food services sales, total'], model='multiplicative')
Retail_and_food_services_sales_total_decompose_result.plot()
plt.pyplot.show()
3.5.8. Analyze Retail sales and food services excl motor vehicle and parts
3.5.8。 分析零售和食品服务(不包括汽车和零部件)
3.5.8.1. Chart Retail sales and food services excl motor vehicle and parts
3.5.8.1。 图表零售和食品服务,不包括机动车和零件
We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty chart with python, but this will do for now.
我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail sales and food services excl motor vehicle and parts', kind='line', grid=1)
plt.pyplot.show()
Convert the index to date again
再次将索引转换为日期
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.8.2. Decompose Retail sales and food services excl motor vehicle and parts time series data
3.5.8.2。 分解零售和食品服务(不包括机动车和零件时间序列数据)
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail sales and food services excl motor vehicle and parts'], model='multiplicative')
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_decompose_result.plot()
plt.pyplot.show()
3.5.9. Analyze Retail sales and food services excl gasoline stations
3.5.9。 分析零售和食品服务除外加油站
3.5.9.1. Chart Retail sales and food services excl gasoline stations
3.5.9.1。 零售和食品服务图表,不包括加油站
We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty chart with python, but this will do for now.
我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail sales and food services excl gasoline stations', kind='line', grid=1)
plt.pyplot.show()
Convert the index to date again
再次将索引转换为日期
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.9.2. Decompose Retail sales and food services excl gasoline stations time series data
3.5.9.2。 分解零售和食品服务(不包括加油站)时间序列数据
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_sales_and_food_services_excl_gasoline_stations_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail sales and food services excl gasoline stations'], model='multiplicative')
Retail_sales_and_food_services_excl_gasoline_stations_decompose_result.plot()
plt.pyplot.show()
3.5.10. Retail sales and food services excl motor vehicle and parts and gasoline stations
3.5.10。 零售和食品服务,不包括机动车,零件和加油站
3.5.10.1. Chart Retail sales and food services excl motor vehicle and parts and gasoline stations
3.5.10.1。 图表零售和食品服务,不包括汽车,零件和加油站
We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty chart with python, but this will do for now.
我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail sales and food services excl motor vehicle and parts and gasoline stations', kind='line', grid=1)
plt.pyplot.show()
Convert the index to date again
再次将索引转换为日期
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.10.2. Decompose Retail sales and food services excl motor vehicle and parts and gasoline stations time series data
3.5.10.2。 分解零售和食品服务(不包括汽车,零件和加油站)的时间序列数据
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail sales and food services excl motor vehicle and parts and gasoline stations'], model='multiplicative')
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_decompose_result.plot()
plt.pyplot.show()
3.5.11. Analyze Retail sales, total
3.5.11。 分析零售总额
3.5.11.1. Chart Retail sales, total
3.5.11.1。 图表零售总额
We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty chart with python, but this will do for now.
我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail sales, total', kind='line', grid=1)
plt.pyplot.show()
Convert the index to date again
再次将索引转换为日期
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.11.2. Decompose Retail sales, total time series data
3.5.11.2。 分解零售,总时间序列数据
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_sales_total_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail sales, total'], model='multiplicative')
Retail_sales_total_decompose_result.plot()
plt.pyplot.show()
3.5.12. Analyze Retail sales, total (excl. motor vehicle and parts dealers)
3.5.12。 分析零售总额(不包括汽车和零件经销商)
3.5.12.1. Chart Retail sales, total (excl. motor vehicle and parts dealers)
3.5.12.1。 图表零售总额(不包括汽车和零件经销商)
We cannot create a chart using index column so we will be temporarily removing date index before creating line chart with grid. You can create pretty chart with python, but this will do for now.
我们无法使用索引列创建图表,因此在使用网格创建折线图之前,我们将暂时删除日期索引。 您可以使用python创建漂亮的图表,但是现在就可以了。
monthly_retail_actuals.reset_index().plot(x='Month', y='Retail sales, total (excl. motor vehicle and parts dealers)', kind='line', grid=1)
plt.pyplot.show()
Convert the index to date again
再次将索引转换为日期
monthly_retail_actuals.index = pd.to_datetime(monthly_retail_actuals.index)3.5.12.2. Decompose Retail sales, total (excl. motor vehicle and parts dealers) time series data
3.5.12.2。 分解零售,总时间(不包括汽车和零件经销商)的时间序列数据
Decomposition is primarily used for time series analysis, and as an analysis tool it can be used to inform forecasting models on your problem. It provides a structured way of thinking about a time series forecasting problem, both generally in terms of modeling complexity and specifically in terms of how-to best capture each of these components in a given model. Multiplicative model was chosen since changes increase or decrease over time whereas Additive model changes over time are consistently made by the same amount.
分解主要用于时间序列分析,并且作为分析工具,可以用于告知问题的预测模型。 它提供了一种有关时间序列预测问题的结构化思考方式,通常是从建模复杂性方面,还是从如何最好地捕获给定模型中的每个组件方面。 之所以选择乘法模型,是因为随着时间的变化会增加或减少,而随着时间的推移,可加性模型的变化将始终保持相同的数量。
We can see that the trend and seasonality information extracted from the Retail and food services sales, total data does seem consistent with observed data. The residuals seems interesting where variability shows high variability in 2008/2009 (i.e., Great Recession) and in 2012 (Not sure what happened in 2012 — maybe start of booming economy).
我们可以看到,从零售和食品服务销售中提取的趋势和季节性信息的总数据似乎与观察到的数据一致。 在2008/2009年(即大萧条)和2012年(不确定2012年发生了什么—可能是经济蓬勃发展)的高变异性中,残差似乎很有趣。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_decompose_result = seasonal_decompose(monthly_retail_actuals['Retail sales, total (excl. motor vehicle and parts dealers)'], model='multiplicative')
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_decompose_result.plot()
plt.pyplot.show()3.6。 准备数据 (3.6. Prep Data)
We will need to prep data to ensure we only use clean data to create our forecast. Some of the basic data prep tasks are:
我们将需要准备数据以确保仅使用干净数据来创建预测。 一些基本的数据准备任务是:
- Remove data outliers. Let say for one month, your sales doubled or tripled due to once in lifetime promotion. This is nice data point to consider, but it will skew our forecast without providing any value. We will need to cap and floor our data to ensure outliers are removed. 删除数据异常值。 假设一个月内,由于终身促销一次,您的销售额翻了一番或三倍。 这是可以考虑的很好的数据点,但是它会扭曲我们的预测而没有提供任何价值。 我们将需要对数据进行上限和下限以确保消除异常值。
- Impute missing data. Sometimes, some of the data are just missing for whatever the reason. If the percentage of missing value is low, then you can impute that missing data. 估算缺少的数据。 有时,无论出于何种原因,一些数据都会丢失。 如果缺失值的百分比较低,则可以估算该缺失数据。
Monthly Trade Report does not seem to have any outliers nor missing data, so this step is not need.
每月贸易报告似乎没有异常值或数据缺失,因此不需要此步骤。
3.7。 开发和验证预测模型 (3.7. Develop and Validate Forecast Model)
To create a forecast model, we shall use Prophet to forecast growth.
要创建预测模型,我们将使用先知来预测增长。
3.7.1. Retail and food services sales, total
3.7.1。 零售和食品服务销售额,总计
3.7.1.1. Filter Monthly Retail Data to just Retail and food services sales, total data
3.7.1.1。 将每月零售数据过滤为仅零售和食品服务销售,总数据
Retail_and_food_services_sales_total_data = monthly_retail_actuals.filter(items=['Retail and food services sales, total'])print('All: ', Retail_and_food_services_sales_total_data.shape)All: (166, 1)3.7.1.2. Split the data into Train and Test data
3.7.1.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_and_food_services_sales_total_train = Retail_and_food_services_sales_total_data.loc['2005-01-01':'2016-12-01']
Retail_and_food_services_sales_total_test = Retail_and_food_services_sales_total_data.loc['2017-01-01':]3.7.1.3. Validate data split was done correctly
3.7.1.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_and_food_services_sales_total_train.shape)
print( 'Test: ', Retail_and_food_services_sales_total_test.shape)Train: (144, 1)
Test: (22, 1)3.7.1.4. Prep train data for modeling
3.7.1.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_and_food_services_sales_total_train = Retail_and_food_services_sales_total_train.reset_index()
Retail_and_food_services_sales_total_train.columns = ['ds', 'y']
Retail_and_food_services_sales_total_train.head()
3.7.1.5. Fit the Model
3.7.1.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_and_food_services_sales_total_model = Prophet()
Retail_and_food_services_sales_total_model.fit(Retail_and_food_services_sales_total_train)INFO:numexpr.utils:NumExpr defaulting to 2 threads.
INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.1.6. Forecast Sales using the Model
3.7.1.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales.由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度。
Retail_and_food_services_sales_total_future = Retail_and_food_services_sales_total_model.make_future_dataframe(freq='M', periods=22)
Retail_and_food_services_sales_total_forecast = Retail_and_food_services_sales_total_model.predict(Retail_and_food_services_sales_total_future)
Retail_and_food_services_sales_total_forecast
There are a lot of information above. The columns we are interested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们感兴趣的列都是“ ds”(表示月份)和“ yhat”(表示预测的销售额)。
3.7.1.7. Chart the Model Forecast
3.7.1.7。 绘制模型预测
Retail_and_food_services_sales_total_model.plot(Retail_and_food_services_sales_total_forecast)
3.7.1.8. Chart the Individual Forecast Model Components
3.7.1.8。 绘制单个预测模型组件的图表
Retail_and_food_services_sales_total_model.plot_components(Retail_and_food_services_sales_total_forecast)
3.7.1.9. Validate Forecast
3.7.1.9。 验证预测
3.7.1.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.1.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_and_food_services_sales_total_forecast_filtered = Retail_and_food_services_sales_total_forecast.filter(["ds","yhat"])
Retail_and_food_services_sales_total_forecast_filtered
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_and_food_services_sales_total_forecast_filtered['ds'] = pd.to_datetime(Retail_and_food_services_sales_total_forecast_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_and_food_services_sales_total_forecast_filtered.columns = ['Month', 'Prediction']
Retail_and_food_services_sales_total_forecast_filtered = Retail_and_food_services_sales_total_forecast_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_and_food_services_sales_total_validate = pd.DataFrame(Retail_and_food_services_sales_total_forecast_filtered, index = Retail_and_food_services_sales_total_test.index, columns=['Prediction'])
Retail_and_food_services_sales_total_validate = pd.concat([Retail_and_food_services_sales_total_test, Retail_and_food_services_sales_total_validate], axis=1)
Retail_and_food_services_sales_total_validate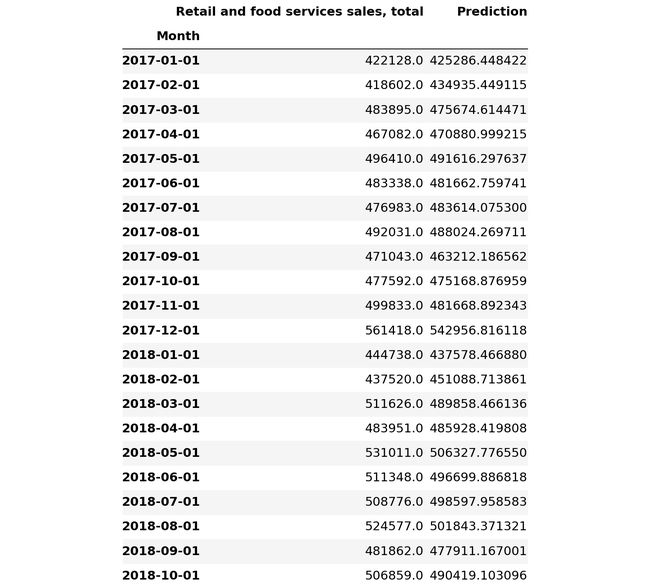
3.7.1.9.2. Plot the difference in actual sales with forecast sales
3.7.1.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_and_food_services_sales_total_validate.plot()
plt.pyplot.show()
3.7.1.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.1.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_and_food_services_sales_total_validate['Abs Diff'] = (Retail_and_food_services_sales_total_validate['Retail and food services sales, total'] - Retail_and_food_services_sales_total_validate['Prediction']).abs()
Retail_and_food_services_sales_total_validate['Abs Diff %'] = (Retail_and_food_services_sales_total_validate['Retail and food services sales, total'] - Retail_and_food_services_sales_total_validate['Prediction']).abs()/Retail_and_food_services_sales_total_validate['Retail and food services sales, total']
Retail_and_food_services_sales_total_validate.loc['Average Abs Diff %'] = pd.Series(Retail_and_food_services_sales_total_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_and_food_services_sales_total_validate.loc['Min Abs Diff %'] = pd.Series(Retail_and_food_services_sales_total_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_and_food_services_sales_total_validate.loc['Max Abs Diff %'] = pd.Series(Retail_and_food_services_sales_total_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_and_food_services_sales_total_validate
3.7.1.9.4. Compare all historical/actual sales with forecasted sales
3.7.1.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_and_food_services_sales_total_future_all = Retail_and_food_services_sales_total_model.make_future_dataframe(freq='M', periods=48)
Retail_and_food_services_sales_total_forecast_all = Retail_and_food_services_sales_total_model.predict(Retail_and_food_services_sales_total_future_all)
Retail_and_food_services_sales_total_forecast_all
Prep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_and_food_services_sales_total_forecast_all = Retail_and_food_services_sales_total_forecast_all.filter(["ds","yhat"])
Retail_and_food_services_sales_total_forecast_all['ds'] = pd.to_datetime(Retail_and_food_services_sales_total_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_and_food_services_sales_total_forecast_all.columns = ['Month', 'Prediction']
Retail_and_food_services_sales_total_forecast_all = Retail_and_food_services_sales_total_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_and_food_services_sales_total = monthly_retail_data.filter(items=['Retail and food services sales, total'])
Retail_and_food_services_sales_total_1 = Retail_and_food_services_sales_total.loc['2005-01-01':'2016-12-01']
Retail_and_food_services_sales_total_2 = Retail_and_food_services_sales_total.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_and_food_services_sales_total_validate_all = pd.DataFrame(Retail_and_food_services_sales_total_forecast_all, index = Retail_and_food_services_sales_total_2.index, columns=['Prediction'])
Retail_and_food_services_sales_total_validate_all = pd.concat([Retail_and_food_services_sales_total_2, Retail_and_food_services_sales_total_validate_all], axis=1)
Retail_and_food_services_sales_total_validate_all = Retail_and_food_services_sales_total_1.append(Retail_and_food_services_sales_total_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_and_food_services_sales_total_validate_all.plot()
plt.pyplot.show()
3.7.2. Retail sales and food services excl motor vehicle and parts
3.7.2。 零售和食品服务,不包括机动车和零件
3.7.2.1. Filter Monthly Retail Data to just Retail sales and food services excl motor vehicle and parts
3.7.2.1。 将每月零售数据过滤为仅零售和食品服务(不包括汽车和零件)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_data = monthly_retail_actuals.filter(items=['Retail sales and food services excl motor vehicle and parts'])print('All: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_data.shape)All: (166, 1)3.7.2.2. Split the data into Train and Test data
3.7.2.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_data.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_test = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_data.loc['2017-01-01':]3.7.2.3. Validate data split was done correctly
3.7.2.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train.shape)
print( 'Test: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_test.shape)Train: (144, 1)
Test: (22, 1)3.7.2.4. Prep train data for modeling
3.7.2.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train.reset_index()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train.columns = ['ds', 'y']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train.head()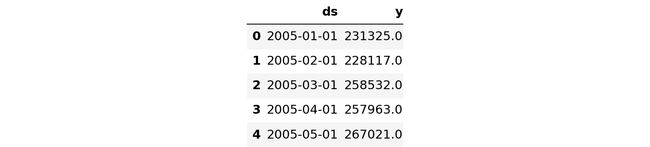
3.7.2.5. Fit the Model
3.7.2.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model = Prophet()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.fit(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_train)INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.2.6. Forecast Sales using the Model
3.7.2.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_future = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.make_future_dataframe(freq='M', periods=22)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.predict(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_future)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast
There are a lot of information above. The columns we are interested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们感兴趣的列都是“ ds”(表示月份)和“ yhat”(表示预测的销售额)。
3.7.2.7. Chart the Model Forecast
3.7.2.7。 绘制模型预测
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.plot(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast)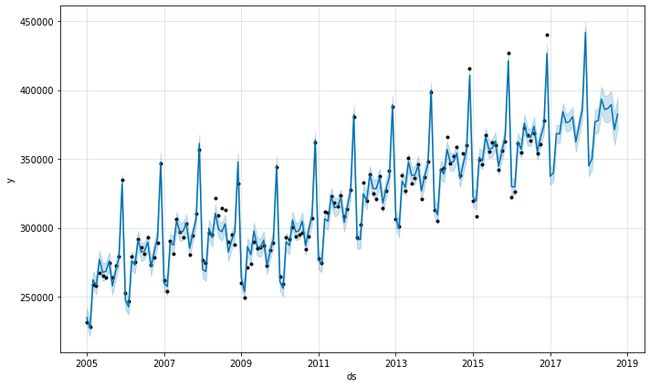
3.7.2.8. Chart the Individual Forecast Model Components
3.7.2.8。 绘制单个预测模型组件的图表
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.plot_components(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast)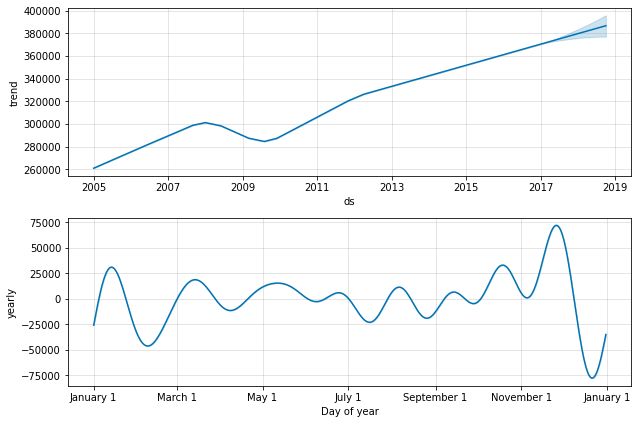
3.7.2.9. Validate Forecast
3.7.2.9。 验证预测
3.7.2.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.2.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered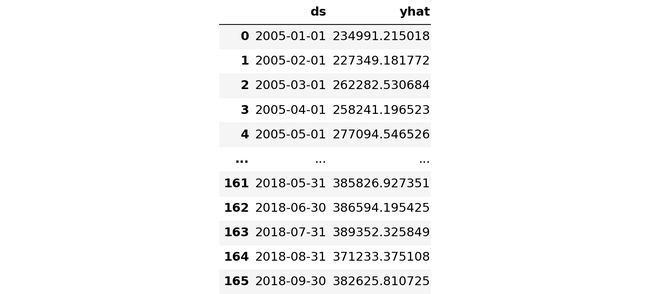
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate = pd.DataFrame(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_filtered, index = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_test.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate = pd.concat([Retail_sales_and_food_services_excl_motor_vehicle_and_parts_test, Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate], axis=1)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate
3.7.2.9.2. Plot the difference in actual sales with forecast sales
3.7.2.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate.plot()
plt.pyplot.show()
3.7.2.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.2.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Abs Diff'] = (Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Retail sales and food services excl motor vehicle and parts'] - Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Prediction']).abs()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Abs Diff %'] = (Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Retail sales and food services excl motor vehicle and parts'] - Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Prediction']).abs()/Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Retail sales and food services excl motor vehicle and parts']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate.loc['Average Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate.loc['Min Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate.loc['Max Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate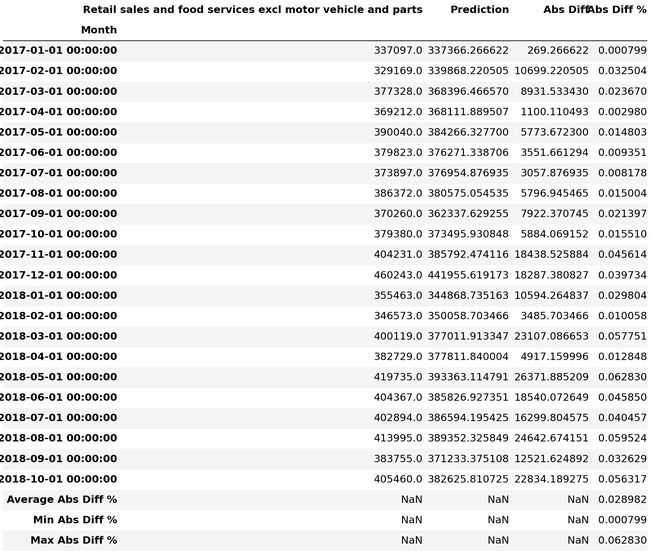
3.7.2.9.4. Compare all historical/actual sales with forecasted sales
3.7.2.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_future_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.make_future_dataframe(freq='M', periods=48)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_model.predict(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_future_all)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all
Prep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts = monthly_retail_data.filter(items=['Retail sales and food services excl motor vehicle and parts'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_1 = Retail_sales_and_food_services_excl_motor_vehicle_and_parts.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_2 = Retail_sales_and_food_services_excl_motor_vehicle_and_parts.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all = pd.DataFrame(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_forecast_all, index = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_2.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all = pd.concat([Retail_sales_and_food_services_excl_motor_vehicle_and_parts_2, Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all], axis=1)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_1.append(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_validate_all.plot()
plt.pyplot.show()3.7.3. Retail sales and food services excl gasoline stations
3.7.3。 零售和食品服务,不包括加油站
3.7.3.1. Filter Monthly Retail Data to just Retail sales and food services excl gasoline stations data
3.7.3.1。 将每月零售数据过滤为零售和食品服务除外加油站数据
Retail_sales_and_food_services_excl_gasoline_stations_data = monthly_retail_actuals.filter(items=['Retail sales and food services excl gasoline stations'])print('All: ', Retail_sales_and_food_services_excl_gasoline_stations_data.shape)All: (166, 1)3.7.3.2. Split the data into Train and Test data
3.7.3.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_sales_and_food_services_excl_gasoline_stations_train = Retail_sales_and_food_services_excl_gasoline_stations_data.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_gasoline_stations_test = Retail_sales_and_food_services_excl_gasoline_stations_data.loc['2017-01-01':]3.7.3.3. Validate data split was done correctly
3.7.3.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_sales_and_food_services_excl_gasoline_stations_train.shape)
print( 'Test: ', Retail_sales_and_food_services_excl_gasoline_stations_test.shape)Train: (144, 1)
Test: (22, 1)3.7.3.4. Prep train data for modeling
3.7.3.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_sales_and_food_services_excl_gasoline_stations_train = Retail_sales_and_food_services_excl_gasoline_stations_train.reset_index()
Retail_sales_and_food_services_excl_gasoline_stations_train.columns = ['ds', 'y']
Retail_sales_and_food_services_excl_gasoline_stations_train.head()
3.7.3.5. Fit the Model
3.7.3.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_sales_and_food_services_excl_gasoline_stations_model = Prophet()
Retail_sales_and_food_services_excl_gasoline_stations_model.fit(Retail_sales_and_food_services_excl_gasoline_stations_train)INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.3.6. Forecast Sales using the Model
3.7.3.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales.由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度。
Retail_sales_and_food_services_excl_gasoline_stations_future = Retail_sales_and_food_services_excl_gasoline_stations_model.make_future_dataframe(freq='M', periods=22)
Retail_sales_and_food_services_excl_gasoline_stations_forecast = Retail_sales_and_food_services_excl_gasoline_stations_model.predict(Retail_sales_and_food_services_excl_gasoline_stations_future)
Retail_sales_and_food_services_excl_gasoline_stations_forecast
There are a lot of information above. The columns we are interested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们感兴趣的列都是“ ds”(表示月份)和“ yhat”(表示预测的销售额)。
3.7.3.7. Chart the Model Forecast
3.7.3.7。 绘制模型预测
Retail_sales_and_food_services_excl_gasoline_stations_model.plot(Retail_sales_and_food_services_excl_gasoline_stations_forecast)
3.7.3.8. Chart the Individual Forecast Model Components
3.7.3.8。 绘制单个预测模型组件的图表
Retail_sales_and_food_services_excl_gasoline_stations_model.plot_components(Retail_sales_and_food_services_excl_gasoline_stations_forecast)
3.7.3.9. Validate Forecast
3.7.3.9。 验证预测
3.7.3.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.3.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered = Retail_sales_and_food_services_excl_gasoline_stations_forecast.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered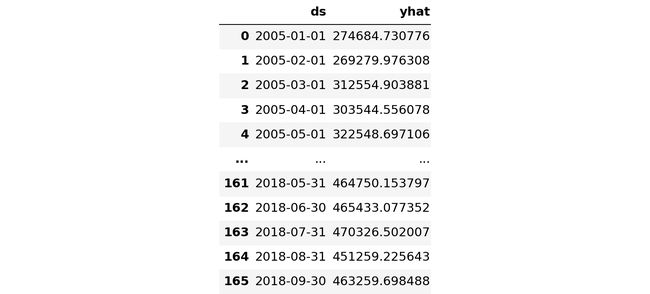
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered = Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_sales_and_food_services_excl_gasoline_stations_validate = pd.DataFrame(Retail_sales_and_food_services_excl_gasoline_stations_forecast_filtered, index = Retail_sales_and_food_services_excl_gasoline_stations_test.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_gasoline_stations_validate = pd.concat([Retail_sales_and_food_services_excl_gasoline_stations_test, Retail_sales_and_food_services_excl_gasoline_stations_validate], axis=1)
Retail_sales_and_food_services_excl_gasoline_stations_validate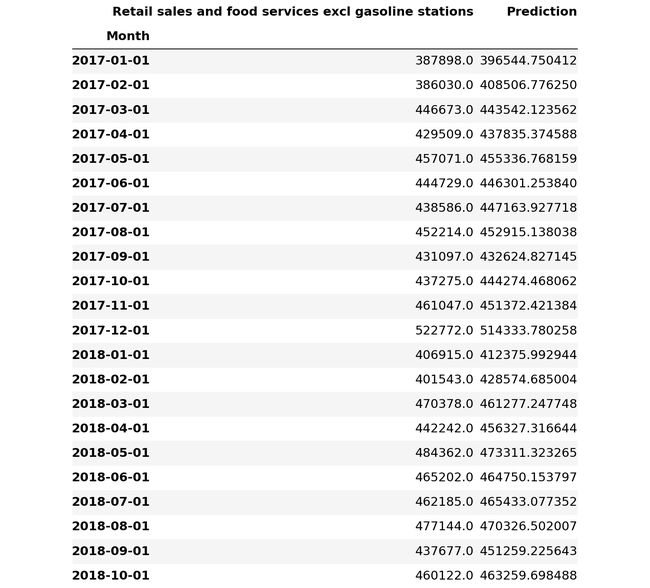
3.7.3.9.2. Plot the difference in actual sales with forecast sales
3.7.3.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_sales_and_food_services_excl_gasoline_stations_validate.plot()
plt.pyplot.show()
3.7.3.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.3.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_sales_and_food_services_excl_gasoline_stations_validate['Abs Diff'] = (Retail_sales_and_food_services_excl_gasoline_stations_validate['Retail sales and food services excl gasoline stations'] - Retail_sales_and_food_services_excl_gasoline_stations_validate['Prediction']).abs()
Retail_sales_and_food_services_excl_gasoline_stations_validate['Abs Diff %'] = (Retail_sales_and_food_services_excl_gasoline_stations_validate['Retail sales and food services excl gasoline stations'] - Retail_sales_and_food_services_excl_gasoline_stations_validate['Prediction']).abs()/Retail_sales_and_food_services_excl_gasoline_stations_validate['Retail sales and food services excl gasoline stations']
Retail_sales_and_food_services_excl_gasoline_stations_validate.loc['Average Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_gasoline_stations_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_gasoline_stations_validate.loc['Min Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_gasoline_stations_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_gasoline_stations_validate.loc['Max Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_gasoline_stations_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_gasoline_stations_validate
3.7.3.9.4. Compare all historical/actual sales with forecasted sales
3.7.3.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_sales_and_food_services_excl_gasoline_stations_future_all = Retail_sales_and_food_services_excl_gasoline_stations_model.make_future_dataframe(freq='M', periods=48)
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_gasoline_stations_model.predict(Retail_sales_and_food_services_excl_gasoline_stations_future_all)
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all
Prep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_gasoline_stations_forecast_all.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_gasoline_stations_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_gasoline_stations_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_sales_and_food_services_excl_gasoline_stations = monthly_retail_data.filter(items=['Retail sales and food services excl gasoline stations'])
Retail_sales_and_food_services_excl_gasoline_stations_1 = Retail_sales_and_food_services_excl_gasoline_stations.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_gasoline_stations_2 = Retail_sales_and_food_services_excl_gasoline_stations.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_sales_and_food_services_excl_gasoline_stations_validate_all = pd.DataFrame(Retail_sales_and_food_services_excl_gasoline_stations_forecast_all, index = Retail_sales_and_food_services_excl_gasoline_stations_2.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_gasoline_stations_validate_all = pd.concat([Retail_sales_and_food_services_excl_gasoline_stations_2, Retail_sales_and_food_services_excl_gasoline_stations_validate_all], axis=1)
Retail_sales_and_food_services_excl_gasoline_stations_validate_all = Retail_sales_and_food_services_excl_gasoline_stations_1.append(Retail_sales_and_food_services_excl_gasoline_stations_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_sales_and_food_services_excl_gasoline_stations_validate_all.plot()
plt.pyplot.show()
3.7.4. Retail sales and food services excl motor vehicle and parts and gasoline stations
3.7.4。 零售和食品服务,不包括机动车,零件和加油站
3.7.4.1. Filter Monthly Retail Data to just Retail and food services sales, total data to just Retail sales and food services excl motor vehicle and parts and gasoline stations
3.7.4.1。 将每月零售数据过滤为仅零售和食品服务销售,将总数据仅为零售和食品服务的销售,不包括汽车,零件和加油站
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_data = monthly_retail_actuals.filter(items=['Retail sales and food services excl motor vehicle and parts and gasoline stations'])print('All: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_data.shape)All: (166, 1)3.7.4.2. Split the data into Train and Test data
3.7.4.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_data.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_test = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_data.loc['2017-01-01':]3.7.4.3. Validate data split was done correctly
3.7.4.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train.shape)
print( 'Test: ', Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_test.shape)Train: (144, 1)
Test: (22, 1)3.7.4.4. Prep train data for modeling
3.7.4.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train.reset_index()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train.columns = ['ds', 'y']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train.head()
3.7.4.5. Fit the Model
3.7.4.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model = Prophet()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.fit(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_train)INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.4.6. Forecast Sales using the Model
3.7.4.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_future = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.make_future_dataframe(freq='M', periods=22)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.predict(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_future)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast
There are a lot of information above. The columns we are interested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们感兴趣的列都是“ ds”(表示月份)和“ yhat”(表示预测的销售额)。
3.7.4.7. Chart the Model Forecast
3.7.4.7。 绘制模型预测
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.plot(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast)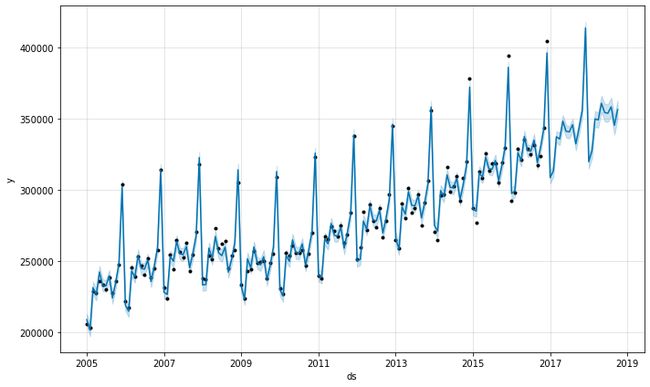
3.7.4.8. Chart the Individual Forecast Model Components
3.7.4.8。 绘制单个预测模型组件的图表
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.plot_components(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast)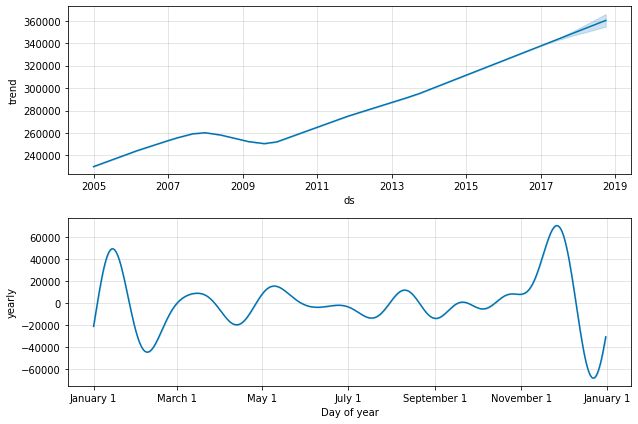
3.7.4.9. Validate Forecast
3.7.4.9。 验证预测
3.7.4.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.4.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate = pd.DataFrame(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_filtered, index = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_test.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate = pd.concat([Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_test, Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate], axis=1)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate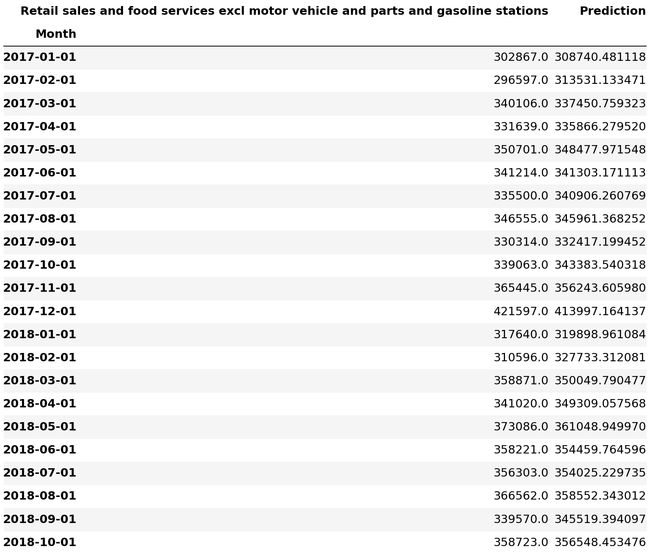
3.7.4.9.2. Plot the difference in actual sales with forecast sales
3.7.4.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate.plot()
plt.pyplot.show()
3.7.4.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.4.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Abs Diff'] = (Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Retail sales and food services excl motor vehicle and parts and gasoline stations'] - Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Prediction']).abs()
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Abs Diff %'] = (Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Retail sales and food services excl motor vehicle and parts and gasoline stations'] - Retail_and_food_services_sales_total_validate['Prediction']).abs()/Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Retail sales and food services excl motor vehicle and parts and gasoline stations']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate.loc['Average Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate.loc['Min Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate.loc['Max Abs Diff %'] = pd.Series(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate
3.7.4.9.4. Compare all historical/actual sales with forecasted sales
3.7.4.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_future_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.make_future_dataframe(freq='M', periods=48)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_model.predict(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_future_all)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all
Prep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all.filter(["ds","yhat"])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all['ds'] = pd.to_datetime(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all.columns = ['Month', 'Prediction']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations = monthly_retail_data.filter(items=['Retail sales and food services excl motor vehicle and parts and gasoline stations'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_1 = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations.loc['2005-01-01':'2016-12-01']
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_2 = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all = pd.DataFrame(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_forecast_all, index = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_2.index, columns=['Prediction'])
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all = pd.concat([Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_2, Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all], axis=1)
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all = Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_1.append(Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_sales_and_food_services_excl_motor_vehicle_and_parts_and_gasoline_stations_validate_all.plot()
plt.pyplot.show()
3.7.5. Retail sales, total
3.7.5。 零售总额
3.7.5.1. Filter Monthly Retail sales, total data
3.7.5.1。 筛选每月零售销售总额数据
Retail_sales_total_data = monthly_retail_actuals.filter(items=['Retail sales, total'])print('All: ', Retail_sales_total_data.shape)All: (166, 1)3.7.5.2. Split the data into Train and Test data
3.7.5.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_sales_total_train = Retail_sales_total_data.loc['2005-01-01':'2016-12-01']
Retail_sales_total_test = Retail_sales_total_data.loc['2017-01-01':]3.7.5.3. Validate data split was done correctly
3.7.5.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_sales_total_train.shape)
print( 'Test: ', Retail_sales_total_test.shape)Train: (144, 1)
Test: (22, 1)3.7.5.4. Prep train data for modeling
3.7.5.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_sales_total_train = Retail_sales_total_train.reset_index()
Retail_sales_total_train.columns = ['ds', 'y']
Retail_sales_total_train.head()3.7.5.5. Fit the Model
3.7.5.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_sales_total_model = Prophet()
Retail_sales_total_model.fit(Retail_sales_total_train)INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.5.6. Forecast Sales using the Model
3.7.5.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales.由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度。
Retail_sales_total_future = Retail_sales_total_model.make_future_dataframe(freq='M', periods=22)
Retail_sales_total_forecast = Retail_sales_total_model.predict(Retail_sales_total_future)
Retail_sales_total_forecast
There are a lot of information above. The columns we are interested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们感兴趣的列都是“ ds”(表示月份)和“ yhat”(表示预测的销售额)。
3.7.5.7. Chart the Model Forecast
3.7.5.7。 绘制模型预测
Retail_sales_total_model.plot(Retail_sales_total_forecast)
3.7.5.8. Chart the Individual Forecast Model Components
3.7.5.8。 绘制单个预测模型组件的图表
Retail_sales_total_model.plot_components(Retail_sales_total_forecast)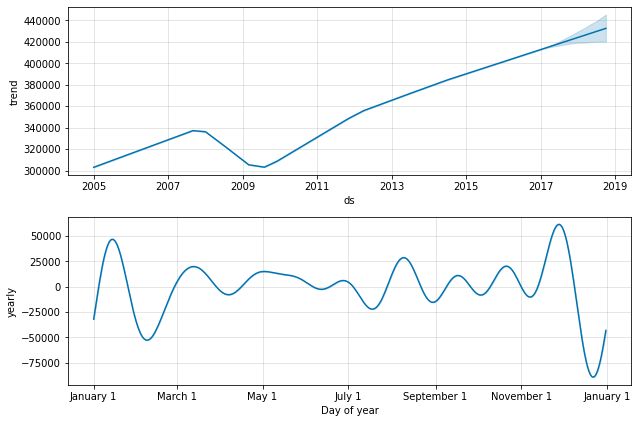
3.7.5.9. Validate Forecast
3.7.5.9。 验证预测
3.7.5.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.5.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_sales_total_forecast_filtered = Retail_sales_total_forecast.filter(["ds","yhat"])
Retail_sales_total_forecast_filtered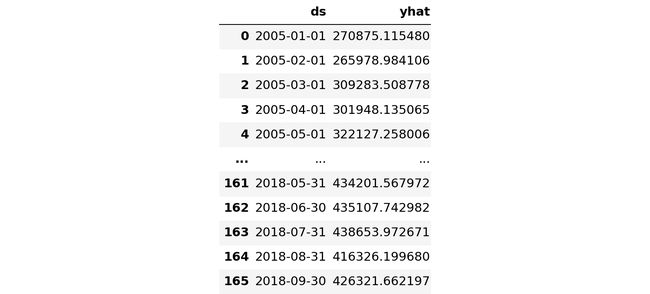
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_sales_total_forecast_filtered['ds'] = pd.to_datetime(Retail_sales_total_forecast_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_sales_total_forecast_filtered.columns = ['Month', 'Prediction']
Retail_sales_total_forecast_filtered = Retail_sales_total_forecast_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_sales_total_validate = pd.DataFrame(Retail_sales_total_forecast_filtered, index = Retail_sales_total_test.index, columns=['Prediction'])
Retail_sales_total_validate = pd.concat([Retail_sales_total_test, Retail_sales_total_validate], axis=1)
Retail_sales_total_validate
3.7.5.9.2. Plot the difference in actual sales with forecast sales
3.7.5.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_sales_total_validate.plot()
plt.pyplot.show()
3.7.5.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.5.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_sales_total_validate['Abs Diff'] = (Retail_sales_total_validate['Retail sales, total'] - Retail_sales_total_validate['Prediction']).abs()
Retail_sales_total_validate['Abs Diff %'] = (Retail_sales_total_validate['Retail sales, total'] - Retail_sales_total_validate['Prediction']).abs()/Retail_sales_total_validate['Retail sales, total']
Retail_sales_total_validate.loc['Average Abs Diff %'] = pd.Series(Retail_sales_total_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_sales_total_validate.loc['Min Abs Diff %'] = pd.Series(Retail_sales_total_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_sales_total_validate.loc['Max Abs Diff %'] = pd.Series(Retail_sales_total_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_sales_total_validate
3.7.5.9.4. Compare all historical/actual sales with forecasted sales
3.7.5.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_sales_total_future_all = Retail_sales_total_model.make_future_dataframe(freq='M', periods=48)
Retail_sales_total_forecast_all = Retail_sales_total_model.predict(Retail_sales_total_future_all)
Retail_sales_total_forecast_allPrep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_sales_total_forecast_all = Retail_sales_total_forecast_all.filter(["ds","yhat"])
Retail_sales_total_forecast_all['ds'] = pd.to_datetime(Retail_sales_total_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_sales_total_forecast_all.columns = ['Month', 'Prediction']
Retail_sales_total_forecast_all = Retail_sales_total_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_sales_total = monthly_retail_data.filter(items=['Retail sales, total'])
Retail_sales_total_1 = Retail_sales_total.loc['2005-01-01':'2016-12-01']
Retail_sales_total_2 = Retail_sales_total.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_sales_total_validate_all = pd.DataFrame(Retail_sales_total_forecast_all, index = Retail_sales_total_2.index, columns=['Prediction'])
Retail_sales_total_validate_all = pd.concat([Retail_sales_total_2, Retail_sales_total_validate_all], axis=1)
Retail_sales_total_validate_all = Retail_sales_total_1.append(Retail_sales_total_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_sales_total_validate_all.plot()
plt.pyplot.show()
3.7.6. Retail sales, total (excl. motor vehicle and parts dealers)
3.7.6。 零售总额(不包括汽车和零件经销商)
3.7.6.1. Filter Monthly Retail Data to just Retail sales, total (excl. motor vehicle and parts dealers)
3.7.6.1。 将每月零售数据过滤为零售总额(不包括汽车和零件经销商)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers
Retail_sales_total_excl_motor_vehicle_and_parts_dealers
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_data = monthly_retail_actuals.filter(items=['Retail sales, total (excl. motor vehicle and parts dealers)'])print('All: ', Retail_sales_total_excl_motor_vehicle_and_parts_dealers_data.shape)All: (166, 1)3.7.6.2. Split the data into Train and Test data
3.7.6.2。 将数据分为训练和测试数据
We will be diving data into two sets of data:
我们将把数据分为两组数据:
- Train Data 火车数据
- Test Data测试数据
Usually we use 70 Train/30 Test (70/30) split, 80 Train/20 Test (80/20) split, 90 Train/10 Test (90/10) split or even 95 Train/5 Test (95/5) where train data is used to create a forecast and test data is used to validate the forecast. For simplification purposes, we will split the data as follows:
通常我们使用70 Train / 30 Test(70/30)split,80 Train / 20 Test(80/20)split,90 Train / 10 Test(90/10)split甚至是95 Train / 5 Test(95/5)火车数据用于创建预测,测试数据用于验证预测。 为简化起见,我们将数据拆分如下:
- Train Data: January 2005 thru December 2016 火车数据:2005年1月至2016年12月
- Test Data: January 2017 thru October 2018测试数据:2017年1月至2018年10月
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_data.loc['2005-01-01':'2016-12-01']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_test = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_data.loc['2017-01-01':]3.7.6.3. Validate data split was done correctly
3.7.6.3。 验证数据分割是否正确完成
print( 'Train: ', Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train.shape)
print( 'Test: ', Retail_sales_total_excl_motor_vehicle_and_parts_dealers_test.shape)Train: (144, 1)
Test: (22, 1)3.7.6.4. Prep train data for modeling
3.7.6.4。 准备火车数据以进行建模
Prophet requires the date column to be named ‘ds’ and the value column to be named ‘y’.
先知要求日期列命名为“ ds”,值列命名为“ y”。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train.reset_index()
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train.columns = ['ds', 'y']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train.head()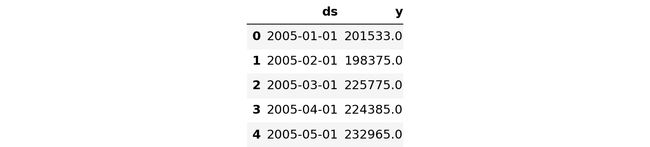
3.7.6.5. Fit the Model
3.7.6.5。 拟合模型
We fit the model by instantiating a new Prophet object. Then you call its fit method and pass in the historical dataframe.
我们通过实例化一个新的Prophet对象来拟合模型。 然后,调用其fit方法并传入历史数据框。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model = Prophet()
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.fit(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_train)INFO:fbprophet:Disabling weekly seasonality. Run prophet with weekly_seasonality=True to override this.
INFO:fbprophet:Disabling daily seasonality. Run prophet with daily_seasonality=True to override this.
3.7.6.6. Forecast Sales using the Model
3.7.6.6。 使用模型预测销售
Predictions are then made on a dataframe with a column ‘ds’ containing the dates for which a prediction is to be made. We are using:
然后在带有“ ds”列的数据帧上进行预测,该列包含要进行预测的日期。 我们正在使用:
- Freq = ‘M” to indicate this is monthly data Freq ='M”表示这是每月数据
- Periods = 22 is used since test data set covers 22 months, so we can compare how well the model forecast the sales against the actual sales由于测试数据集涵盖22个月,因此使用了Periods = 22,因此我们可以比较模型预测销售与实际销售的程度
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_future = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.make_future_dataframe(freq='M', periods=22)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.predict(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_future)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast
There are a lot of information above. The columns we are intested in going forward basis is both ‘ds’, which indicates month and ‘yhat’, which indicates forecasted sales amount.
上面有很多信息。 我们今后要检验的列都是“ ds”(表示月份)和“ yhat”(表示预测销售额)。
3.7.6.7. Chart the Model Forecast
3.7.6.7。 绘制模型预测
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.plot(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast)
3.7.6.8. Chart the Individual Forecast Model Components
3.7.6.8。 绘制单个预测模型组件的图表
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.plot_components(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast)
3.7.6.9. Validate Forecast
3.7.6.9。 验证预测
3.7.6.9.1. Prep Forecast Data so we can compare the forecast with actuals in Test dataset
3.7.6.9.1。 准备预测数据,以便我们可以将预测与测试数据集中的实际值进行比较
We only need two columns of data — ‘ds’ so we can match months and ‘yhat’ so we can compare forecasted sales with actual sales.
我们只需要两列数据-“ ds”,以便我们可以匹配月份和“ yhat”,从而可以将预测的销售额与实际销售额进行比较。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast.filter(["ds","yhat"])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered
Prophet returns all forecasted month datatime with end of the month date. The conversion to beginning of the month is needed so we can compare forecast with actuals.
先知返回月底日期的所有预测的月份数据时间。 需要转换为月初,因此我们可以将预测值与实际值进行比较。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered['ds'] = pd.to_datetime(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered['ds']) - pd.offsets.MonthBegin(n=0)Rename column names from ‘ds’ and ‘yhat’ to column names used in test dataset — ‘Month’ and ‘Prediction’.
将列名从“ ds”和“ yhat”重命名为测试数据集中使用的列名-“ Month”和“ Prediction”。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered.columns = ['Month', 'Prediction']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered.set_index('Month')Join forecast dataset with test dataset so we can compare how forecast model performed.
将预测数据集与测试数据集连接起来,以便我们可以比较预测模型的执行情况。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate = pd.DataFrame(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_filtered, index = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_test.index, columns=['Prediction'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate = pd.concat([Retail_sales_total_excl_motor_vehicle_and_parts_dealers_test, Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate], axis=1)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate
3.7.6.9.2. Plot the difference in actual sales with forecast sales
3.7.6.9.2。 绘制实际销售额与预测销售额之间的差异
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate.plot()
plt.pyplot.show()
3.7.6.9.3. Compute the absolute difference between actual sales with forecasted sales
3.7.6.9.3。 计算实际销售额与预期销售额之间的绝对差额
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Abs Diff'] = (Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Retail sales, total (excl. motor vehicle and parts dealers)'] - Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Prediction']).abs()
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Abs Diff %'] = (Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Retail sales, total (excl. motor vehicle and parts dealers)'] - Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Prediction']).abs()/Retail_and_food_services_sales_total_validate['Retail and food services sales, total']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate.loc['Average Abs Diff %'] = pd.Series(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Abs Diff %'].mean(), index = ['Abs Diff %'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate.loc['Min Abs Diff %'] = pd.Series(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Abs Diff %'].min(), index = ['Abs Diff %'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate.loc['Max Abs Diff %'] = pd.Series(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate['Abs Diff %'].max(), index = ['Abs Diff %'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate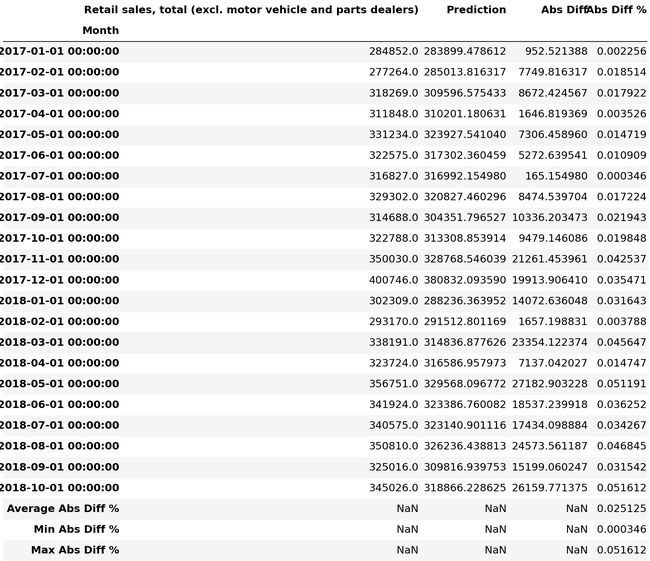
3.7.6.9.4. Compare all historical/actual sales with forecasted sales
3.7.6.9.4。 比较所有历史/实际销售与预测销售
Generate 48 months of sales forecast using the forecast model.
使用预测模型生成48个月的销售预测。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_future_all = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.make_future_dataframe(freq='M', periods=48)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_model.predict(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_future_all)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all
Prep the forecasted sales so it can be compared against the actual/historical sales.
准备预测的销售量,以便可以将其与实际/历史销售量进行比较。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all.filter(["ds","yhat"])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all['ds'] = pd.to_datetime(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all['ds']) - pd.offsets.MonthBegin(n=0)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all.columns = ['Month', 'Prediction']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all.set_index('Month')Filter the actual/historical sales to periods when there is no forecasted sales data and when there is forecasted sales data.
在没有预测的销售数据且没有预测的销售数据的期间,过滤实际/历史销售。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers = monthly_retail_data.filter(items=['Retail sales, total (excl. motor vehicle and parts dealers)'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_1 = Retail_sales_total_excl_motor_vehicle_and_parts_dealers.loc['2005-01-01':'2016-12-01']
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_2 = Retail_sales_total_excl_motor_vehicle_and_parts_dealers.loc['2017-01-01':]Join actual/historical sales data with forecast sales data.
将实际/历史销售数据与预测销售数据结合在一起。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all = pd.DataFrame(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_forecast_all, index = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_2.index, columns=['Prediction'])
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all = pd.concat([Retail_sales_total_excl_motor_vehicle_and_parts_dealers_2, Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all], axis=1)
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all = Retail_sales_total_excl_motor_vehicle_and_parts_dealers_1.append(Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all, sort=True)Plot all data, including both actual/historical sales data with forecast sales data.
绘制所有数据,包括实际/历史销售数据和预测销售数据。
Retail_sales_total_excl_motor_vehicle_and_parts_dealers_validate_all.plot()
plt.pyplot.show()
3.8。 维持预测 (3.8. Maintain Forecast)
Like everything, newly created forecast needs to be maintained. More likely on a monthly basis since this is monthly forecast, forecast needs to be updated to reflect revised trend.
像其他所有内容一样,需要维护新创建的预测。 由于这是每月预测,因此更可能按月进行,因此需要更新预测以反映修订后的趋势。
To revise the forecast to reflect more up to date data, follow the steps above where you will revise step 3.7.
要修改预测以反映更多最新数据,请按照上述步骤修改步骤3.7。
When diving data into two sets of data:
将数据分为两组数据时:
- Train Data: January 2005 thru January 2017 (+ 1 month) 火车数据:2005年1月至2017年1月(+1个月)
- Test Data: February 2017 (+ 1 month) thru November 2018 (+ 1 month) 测试数据:2017年2月(+1个月)至2018年11月(+1个月)
Repeat the process for all subsequent months.
在随后的所有月份重复该过程。
希望您喜欢本教程。 (I hope you have enjoyed this tutorial.)
翻译自: https://medium.com/swlh/create-forecast-using-python-prophet-3-1-5ea64c3b103b
使用python预测基金