面试总结1
文章目录
-
-
- 人事
-
- 你的汇报对象是谁:
- 对运维的理解:
- 运维每天的工作:
- 项目
-
- linux学到了啥:
- 数据库的理解:
- zabbix 【5.0】
-
- 话术:
- 监控思路(监控指标):
- zabbix模式:
- zabbix组成部分:
- zabbix监控项、触发器和模板三者间的关系
- zabbix模板:
- zabbix不常见的模板:
- zabbix服务器迁移,如何做?
- 简述zabbix升级过程
- 5.0版本的新特性:
- zabbix中的api应用
- Zabbix如何发现新机器?
- zabbix 自定义发现:
- zabbix 自定义监控:
- zabbix客户端是怎么进行批量安装的
- 微信报警怎么做的:
- 报警风暴如何避免:
- 其他监控:
- MySQL【5.7】
-
- 数据库类型:
- MySQL 5.7新特性:
- mysql和nosql的区别:
- MySQL高可用:
- mysql主从复制过程(原理):
- MySQL主从故障切换后,如何恢复主从复制:
- 主从同步异常如何解决(不是重做主从):
- 主从分别宕机的问题
- 主从延迟的常见原因:
- MySQL 主从延迟很大怎么办(措施):
- mysql日志文件:
- 慢查询日志如何设置:
- mysql安全方面措施:
- 数据库连接不上,原因:
- 数据库忘记密码怎么解决?
- mysql数据库你们是使用什么工具完成读写分离的:
- mysql优化:
- 备份哪些数据:
- MySQL备份(日常数据):
- 几种备份:
- MySQL查询缓存开启
- 怎么查看数据库的引擎?
- MySQL 存储引擎 MyISAM和InnoDB区别:
- 数据库事务
- MySQL数据库中delete 和truncate的区别:
- MHA 【0.58】
-
- 话术:
- MHA简介:
- MHA节点(4台,一主两从):
- MHA工作流程:
- Redis 【6.0】
-
- redis支持的数据类型:
- redis用来做什么:
- redis架构:
- redis哨兵
- redis主从原理
- redis的吞吐量
- Redis 事务:
- Redis回收进程:
- 击穿、雪崩、穿透:
- Redis 集群最大节点个数:
- Redis字符串的存储量:
- Redis槽位:
- Redis持久化两种方式,有什么区别,如何做:
- Redis 如何设置密码及验证密码?
- memcache 和redis有什么区别:
- redis为什么比MySQL快:
- 负载均衡
- LVS
-
- LVS和Nginx的区别:
- lvs模式:
- lvs算法:
- Nginx 【1.20】
-
- 为什么nginx性能这么高:
- Nginx与Apache的区别:
- Squid、Varinsh、Nginx 做缓存区别:
- nginx正向代理和反向代理区别以及列举 nginx作为反向代理的负载均衡算法和常用模块:
- nginx调优:
- nginx配置文件详解:
- Nginx虚拟主机:
- nginx图片缓存30天如何写:
- nginx gzip模块如如何使用?
- nginx如何设置防ddos攻击:
- Nginx中,解释如何在URL中保留双斜线:
- Nginx命令:
- NGINX配置文件分为那几部分:
- nginx模块:
- Nginx日志文件:
- Nginx工作模式:
- nginx服务器上master和worker的区别:
- NGINX如何将worker 进程绑定特定内核:
- 写一个每天0点执行的删除nginx日志的脚本,保留最近七天的日志
- fastcgi:
- fastcgi 与 cgi 的区别:
- HTTP返回码的意义:
- 静态网页,动态网页:
- keepalived
-
- 工作原理:
- 脑裂:
- keepalived的模块:
- Tomcat 【9】
-
- Tomcat 调优做过哪些:
- tomcat目录结构:
- tomcat的三种模式
- tomcat内存泄漏和内存溢出
- Tomcat session共享:
- cookie和session区别:
- Gitlab 【6.5】
-
- 话术:
- 工具清单:
- CI/CD持续集成持续部署
- 描述一线自动化上线流程:
- svn和Git区别
- harbor工具:
- 发布策略 :
- git常用命令
- 遇到的问题:
- jenkins 【2.3】
-
- jenkins简介
- Jenkins用过哪些插件:
- ansible
-
- ansible的playbooke是干什么的:
- ansible插件:
- ansible模块:
- ansible和saltstack的区别:
- ELK
-
- 话术:
- ELK组成:
- 为什么用ELK:
- ELK作用:
- ES的特点
- ES的缺点
- ELK架构:
- ELK插件:
- ES分片:
- ES调优实战:
- ES调优:
- ES中的倒排索引:
- ES中的集群、节点、索引、文档、类型分别是什么?
- 文档【index】:类似关系数据库中的一行
- elk一般用来收集哪些日志:
- 日志分析你们关注哪些参数:
- 参数用来分析什么:
- Nginx日志分析怎么做的:
- 官方文档:
- Logstash 三个组件
- Logstash事件处理:
- logstash 特点
- kibana特点
- 遇到的问题:
- docker
-
- docker简介:
- Docker镜像
- Docker容器
- 你用docker做过什么:
- docker持久化怎么做的:
- dockerfile 与 docker-compose的区别:
- docker三剑客:
- docker私有库:
- docker最小镜像:
- pid是1的进程:
- docker四种网络模式:
- docker命令:
- docker容器状态:
- docker运行状态:
- 登录docker容器的方式有哪些:
- dockerfile中最常见的指令:
- docekr、kvm、vmware的区别
- 遇到的问题:
- K8S
- Hadoop
-
- Hadoop运行模式:
- kafka
- shell
-
- 写过哪些shell脚本:
- shell脚本监控MySQL主从:
- shell脚本监控公司网段的IP是否存活:
- Shell实现99乘法表:
- 计算1到100相加:
- 假如系统有100个系统账号,名字一次为name1-name100,编写脚本删除这些用户:
- liunx三剑客:
- shell参数:
- vi和vim区别:
- 云
-
- 云服务器:
- 云服务区别:
- 系统
-
- 操作系统(应用场景和特点):
- (新服务器)新安装的Linux系统在安全和性能方面做哪些配置:
- linux最大文件数用ulimit:
- nofile和nproc
- Linux启动流程:
- Linux1号进程(init进程):
- Linux系统中病毒怎么解决:
- 网络文件系统(NFS(2049) MFS):
- 进程和线程的区别:
- 什么原因引起系统负载变高 / 服务器变慢?
- 僵尸进程(Z进程):
- 系统还有空间,但是却创建不了文件,什么原因?
- linux inode节点:
- 为什么iNode节点会用完?
- Linux 软连接和硬链接区别:
- Linux打包工具:
- 配置文件:
- 定时任务:
- 命令:
- 网络
-
- 解释 ip地址,子网掩码,网关的意义:
- 网络流量抓取:
- iptable(防火墙):
- ebtables与iptables的区别:
- centos6和centos7中防火墙区别:
- 磁盘
-
- raid:
- 磁盘空间满如何排查:
- 磁盘扩容:
- 删除文件,但是硬盘空间没释放:
- Linux交换分区swap和物理内存的区别:
- 磁盘分区:
- 架构
-
- 架构图:
- 假设目前的服务器规模是200台,说说你的管理思路,例如存储,监控,日志收集等:
- 排查
-
- 平台访问卡顿,可能的故障原因:
- 系统出现问题怎么排查的:
- 一些原理
-
- CDN意义:
- DNS原理:
- 虚拟化:
- jumpserver:
- 介绍:
- 微服务:
- spring cloud:
- 惊群现象:
- 跨域:
- DDoS攻击:
- 中间件:
- JDK:
- 协议:
- TCP/IP的七层模型:
- TCP(三次握手,四次挥手):
- FTP:
-
人事
你的汇报对象是谁:
运维经理
对运维的理解:
以服务为中心,以稳定、安全、高效为三个基本点,确保公司的互联网业务能够 7×24 小时为用户提供高质量的服务。
运维每天的工作:
邮件:看看信息,看是否有任务,工作,企业的服务器报警内容
日常巡检:昨天的备份是否成功,服务器的运行状态是否正常
研究任务:完成老大分派的任务,例. 搭建一个LNMP环境、优化环境
开发方面:帮助开发,需要用到的平台、工具等
开会:汇报、总结,出现的紧急状况,处理情况完成度
上线代码:帮助开发人员的代码进行推送,SVN 或 Git
学习:平常没有任务或者故障处理的时间久会学习一些公司未来要上线的技术,以便自己能更好的完成工作
项目
linux学到了啥:
常用的linux安装部署 调优 安装中间件 监控都可以
数据库的理解:
对数据库做集群部署(主主,MHA等),对数据库做监控,
zabbix 【5.0】
话术:
对于运维人员来说,监控是非常重要的,因为如果想要保证公司的线上业务整体能够稳定运行,那么我们则需要实时关注与其相关的各项指标是否正常,而Zabbix 监控系统是企业级开源的、分布式监控系统,对设备配置要求低,告警机制多样灵活, 而且具有优秀的图形化界面,我们监控的初衷就是当某些指标不符合我们的需求时,我们能够在第一时间发现异常,并且服务器出现故障的时候方便我们更直观的去依靠监控平台去发现问题。
我们主要是对zabbix监控进行了一个升级,升级到了5.0版本。用的是微信报警,
在升级之后,我日常工作主要负责的是:根据需求来制定详细的监控表单以及基础模板套用;合理分配告警阈值以及构建自定义动作和告警方式;
一般情况下主要监控一些应用级的
内存CPU的使用情况以及硬盘的主要是监控硬盘的IO。
应用层的进程的端口,进程的状态。
还有网络层的通过获取URL地址的返回状态码。
来做这个做了这些监控。
除此之外就是通过告警信息进行实时故障排查,并且根据数据趋势分析; 5. 通过分析实现项目告警的预排除,达到风险可控。
故障的处理。
一旦发现告警了啊,我收到之后我要及时的处理。
处理的过程就是
如果说呢这个问题是跟运维相关的,比如说磁盘满了呀。
我都会听一听。
清理一下日志。
或者是那个。
排查原因。
如果是跟应用相关的。
我们要查看应用日志,是不是我们会和研发人员
那个沟通啊,一起来处理问题。
监控思路(监控指标):
- 硬件监控(SNMP 协议)——网络设备、网卡状态、网口状态、网线状态、硬盘状态、温度(主板 cpu 南桥 北桥) 、风扇转速、电源(电压 电源状态)
- 交换机:进出流量、CPU、内存使用情况、内存空闲情况、当前内存使用情况
- 使用Telnet登录到交换机,开启snmp服务
- 使用getif工具查看交换机端口信息,根据在interface选项卡中的int值,查看当前交换机改端口的OID值,然后在zabbix中使用OID值对交换机端口进行监控
- 在zabbix中添加对交换机的监控、添加主机、创建监控模板、创建监控项、触发器、创建图形
- 交换机:进出流量、CPU、内存使用情况、内存空闲情况、当前内存使用情况
- 系统级——内存空间,cpu负载,磁盘空间,磁盘IO,进程数,tcp状态,开机时间
- 内存:使用率、缓冲区、缓存区、交换分区的大小
- 网络:网卡的先行速率、占用网络带宽最多的进程、数据包的丢包、网络数据包阻塞情况
- 进程:系统中的总进程数、特定程序的进程数
- 应用级——监控服务,端口,status模块
- 监控Nginx参数
- Active connections: 当前活跃连的接数
- accepts:已接收的客户端请求数量
- handled:已处理的客户端请求数量
- requests:客户端发送的总请求数(吞吐量)
- Reading:正在读取客户端请求报文首部的连接数
- Writing:正在向客户端发送响应报文的连接数
- Waiting:正在等待客户端发送请求报文的空闲连接数
- 等等…
- 监控MySQL参数(磁盘使用情况、内存使用情况、并发链接数量、数据库增删改查的频率、主从状态)
- 数据库版本
- 数据库的连接状态
- 数据库启动时间
- 数据库当前连接数
- 数据库使用的连接最大个数
- 数据库放弃的连接个数
- 数据库尝试连接失败次数
- IO进程运行状态
- SQL进程运行状态
- 主库二进制日志文件
- 从库和主库的延迟时间
- 等等…
- 监控Nginx参数
- web监控——响应时间、加载时间、渲染时间、web服务是否正常:状态码(页面不是200–>触发报警)、服务的并发量、
- 日志监控——ELK、(收集、存储、分析、展示)日志
- 安全监控——firewalld、WAF(nginx+lua)、安全宝、牛盾云、安全狗
zabbix模式:
Zabbix的主动模式和被动模式都是相对agent来说的
- 被动模式是 server主动去收集 agent上的数据,优点是模板多,更具灵活性,缺点server端压力大
- (默认)主动模式就是agent将消息推送给server,主动将监控项内需要检测的数据提交给server或proxy。优点是减轻了server的压力,缺点是所有的模板要修改为主动模式
zabbix组成部分:
五部分
- zabbix web GUI web界面
- zabbix database 数据存储
- zabbix server 服务端
- zabbix agent 客户端
- zabbix proxy 代理,减轻server的压力
zabbix监控项、触发器和模板三者间的关系
item监控项,系统级的资源监控,从agent取得,提交到server
triger 触发器,满足条件,触发报警
template模板,item+triger的集合
关系:监控项是基础,有监控项才有触发器,两者的组合构成了模板,也可编辑和自定义
zabbix模板:
- Template App Zabbix Server
- Template OS Linux
- mysql监控报警
- nginx连接监控报警
- Tcp连接监控相关设置
- RabbitMQ的连接监控设置
- MySQL监控报警
zabbix不常见的模板:
不常见的是我是使用别人的,然后结合情况进行修改
zabbix服务器迁移,如何做?
- 部署新环境和proxy代理
- 同步新老节点配置文件、程序以及proxy
- 不管主被动模式,最重要 的都是server端,关闭action,停掉旧节点
- 配置proxy代理指向新节点
- 恢复action,配置web界面,重启查看是否有数据
简述zabbix升级过程
停止Zabbix-server
备份配置文件、PHP文件和Zabbix二进制文件【创建目录,cp过去】
备份数据库【mysqldump】
升级zabbix 4.2的yum源【rpm -Uvh】
安装,修改相应的配置文件
启动,观察日志,查验是否有新字段
5.0版本的新特性:
竖直的的菜单界面,原本是横版的,界面可以完全隐藏。
触发器支持字符串比较
监控项可以从UI马上测试数据
原来的check now功能控件改成execut now
数据触发器对zabbix-proxy可用性敏感
web端可以添加第三方模块或自己开发模块增强zabbix前端功能
web端小组件复制粘贴
管理大量主机
重新编写LLD发现规则
加大监控项值的字符数
增加浮点数的精度(15位),手动安装需要增加补丁
添加了2种方法监控db.odbc的监控项
增加了对监控项值进行预处理,可以用一个新的值代替
纳秒级别的数据发送并输入到文件,需要相应设置
安全连接数据,支持配置TLS连接到MySQL和PostgreSQL数据库
限制客户端检查
使用一种更强的bcrypt加密技术来哈希用户密码,而不是MD5。升级后对更强密码的更改是自动的,即不需要用户方面的努力。注意,超过72个字符的密码将被截断。
支持配置webhook时可以指定一个HTTP代理。默认情况下,新的HTTPProxy参数在webhook参数列表中以空值列出。在指定代理值时,支持与项目配置中的HTTP代理字段相同的功能。
低级发现规则列表总是链接到单个主机,因此不可能在一个地方查看所有发现规则,也不可能筛选特定主机组的规则或有错误的规则。在新版本中,低级发现规则列表包含一个筛选器,允许按主机组、主机、发现项类型、发现规则状态和其他参数进行筛选。此外,列表中添加的第一列现在总是显示发现规则的主机。
支持大规模更新主机上或者是模板上的宏
为每种通知消息媒体设置默认模板
用于问题确认和其他问题更新操作的问题更新屏幕有几个改进:
显示问题名称(如果有多个问题,则选择N个问题);
问题更新消息的大小从256个字符增加到2048个字符;
支持不确认问题;
不确认问题的选项设置
主机级别的SNMP认证
手动SNMP缓存清除
邮件通知归属到同一个进程当中
支持Elasticsearch 7.X,不支持7.x以前版本
支持SAML2.0身份验证来登录到zabbix界面
webhook 集成,使用webhook消息媒体来推送zabbix告警通知
zabbix-agent 2版本,也支持windows上面安装
后面还有宏相关,数据库相关,监控项,web前端,守护进程
zabbix中的api应用
API应用程序编程接口
API包含四种方法: get, create, update 和 delete
检索 创建 更新和删除数据
调用Zabbix的api接口来获取监控项的历史数据
应用——集成第三方软件和自动化日常任务
功能:
远程管理Zabbix配置
远程检索配置和历史数据
Zabbix如何发现新机器?
通过发现网络中的主机,并自动把主机添加到监控中,并关联特定的模板,实现自动监控
zabbix 自定义发现:
-
首先需要在模板当中创建一个自动发现的规则,这个地方只需要一个名称和一个键值。
-
过滤器中间要添加你需要的用到的值宏。
-
然后要创建一个监项原型,也是一个名称和一个键值。
-
然后需要去写一个这样的键值的收集。
自动发现实际上就是需要首先去获得需要监控的值,然后将这个值作为一个新的参数传递到另外一个收集数据的item里面去。
zabbix 自定义监控:
-
写一个脚本用于获取待监控服务的一些状态信息。
-
在zabbix客户端的配置文件zabbix_agentd.conf中添加上自定义的“UserParameter”,目的是方便zabbix调用我们上面写的那个脚本去获取待监控服务的信息。
-
在zabbix服务端使用zabbix_get测试是否能够通过第二步定义的参数去获取zabbix客户端收集的数据。
-
在zabbix服务端的web界面中新建模板,同时第一步的脚本能够获取什么信息就添加上什么监控项,“键值”设置成前面配置的“UserParameter”的值。
-
数据显示图表,直接新建图形并选择上一步的监控项来生成动态图表即可。
zabbix客户端是怎么进行批量安装的
-
使用命令生成密钥。
-
将公钥发送到所有安装zabbix客户端的主机。
-
安装 ansible 软件,(修改配置文件,将zabbix 客户机添加进组)。
-
创建一个安装zabbix客户端的剧本。
-
执行该剧本。
-
验证。
微信报警怎么做的:
zabbix企业微信告警这一方面只需要配置一次就可以使用很久了,所以有些不常用的配置可能会遗忘,但是一般都有写文档的习惯,然后配置微信报警的流程大致是这样的:
- 微信申请一个企业公众号
- 添加部门及成员
- 添加应用
- 在企业号上新建应用
- 设置管理员 【记录cropID secret值】
- 接口调用测试是否可用【填入cropID、secret值,查看返回结果是 ok即为成功】
- zabbix服务端配置
- 配置告警脚本【应用ID、cropID、secret值】
- Web界面新增报警媒介信息【类型:脚本】
- 配置用户报警媒介信息
- 配置触发器动作
- 测试是否成功
报警风暴如何避免:
智能告警平台(Cloud Alert) CA,能快速接入各类告警信息,通过自动去重、规则压缩、算法降噪;同时通过分派、排班、通知等功能,快速实现告警流程化管理,帮助运维团队更快响应告警,有序处理问题。
机房故障(网络中断、机房断电等)会导致部署在该机房的模块异常,引发大规模的报警风暴。报警风暴不但会对报警的处理造成打扰,而且可能会增大报警系统压力,严重时可能导致后续报警延迟送达。因此,如果能快速准确地感知机房故障,并将相关报警进行合并,将会有利于运维人员快速捕捉故障根因,还能减少报警系统压力
其他监控:
- Nagios:Nagios简单直观,报警与数据都在同一页面,红色即为问题项。Nagios web端不要做任何配置。
- mrtg:配置简单、源码开发、可定制
MySQL【5.7】
数据库类型:
| 关系型数据库 | 非关系型数据库 |
|---|---|
| mysql / mariadb(3306),oracle(1521),sql server(1433) | redis,memcache,mongoDB |
MySQL 5.7新特性:
新增了新的优化器、原生JSON支持、多源复制,还优化了整体的性能、GIS空间扩展、InnoDB。
mysql和nosql的区别:
- mysql关系型数据库,数据能持久化,存储在硬盘中,读取慢
- nosql非关系型数据库,不能持久化,速度快效率高
MySQL高可用:
| 方案 | |
|---|---|
| 主从或主主半同步复制 | 使用双节点数据库,搭建单向或者双向的半同步复制。在5.7以后的版本中,由于lossless replication、logical多线程复制等一些列新特性的引入,使得MySQL原生半同步复制更加可靠。 |
| 半同步复制优化 | 半同步复制机制是可靠的。如果半同步复制一直是生效的,那么便可以认为数据是一致的。但是由于网络波动等一些客观原因,导致半同步复制发生超时而切换为异步复制,那么这时便不能保证数据的一致性。所以尽可能的保证半同步复制,便可提高数据的一致性。 |
| 高可用架构优化 | 将双节点数据库扩展到多节点数据库,或者多节点数据库集群。可以根据自己的需要选择一主两从、一主多从或者多主多从的集群。 由于半同步复制,存在接收到一个从机的成功应答即认为半同步复制成功的特性,所以多从半同步复制的可靠性要优于单从半同步复制的可靠性。并且多节点同时宕机的几率也要小于单节点宕机的几率,所以多节点架构在一定程度上可以认为高可用性是好于双节点架构。 |
| 共享存储 | 共享存储实现了数据库服务器和存储设备的解耦,不同数据库之间的数据同步不再依赖于MySQL的原生复制功能,而是通过磁盘数据同步的手段,来保证数据的一致性 |
| 分布式协议 | 分布式协议可以很好解决数据一致性问题。 |
mysql主从复制过程(原理):
- 主库接受到更新命令,执行更新操作,生成binlog
- 从库开启一个I/O线程与主库dump_thread建立连接
- 主库dump_thread从本地读取binlog传送给从库
- 从库从主库获取到binlog后存储到本地,成为relay log,并将读取到的binlog文件名和位置保存到master-info文件
- sql_thread线程读取relay log解析、执行命令更新数据
Slave开启I/O线程来请求master服务器,请求指定bin-log
Master端收到请求,Master端I/O线程响应请求通过bin-log将内容返给salve
Slave将收到的内容存入relay-log中继日志中
Slave端SQL实时监测relay-log日志有更新
执行完毕之后,Slave端跟master端数据保持一致!
MySQL主从故障切换后,如何恢复主从复制:
记录master位置,切换架构为BA,保证业务,恢复前记录position结束位置,最后通过二进制日志文件进行恢复
主从同步异常如何解决(不是重做主从):
-
配置文件 添加slave-skip-errors = 错误代码 重启查看
-
stop slave;
跳过slave上的1个错误:mysql>set global sql_slave_skip_counter=1;
start slave;
主从分别宕机的问题
1、登录从库
mysql -uroot -p123456 -S /application/mysql-5.6.20/mysql.sock
2、停止slave 服务
mysql>stop slave;
3、在其他从库或者主库上完全备份同步的数据,并确定同步文件和同步位置
mysqldump -uroot -p123456 -S /application/mysql-5.6.20/mysql.sock -A -B --events|gzip >/opt/rep.sql.gz
4、将数据灌入从库
#gunzip rep.sql.gz>rep.sql
#mysql -uroot -p'pwd123' -S /application/mysql-5.6.20//mysql.sock < rep.sql
5、执行同步命令
mysql>change master to master_host='10.0.0.7',master_user='repl',
master_password='slavepass',master_log_file='mysql-bin.001440',
master_log_pos=68824;
6、开启同步服务
mysql>start slave
主从延迟的常见原因:
常见原因:Master、Slave负载过高、网络延迟、机器性能低、MySQL配置不合理。
MySQL 主从延迟很大怎么办(措施):
- 最简单的减少slave同步延时的方案就是在架构上做优化,尽量让主库的DDL快速执行
- 修改配置减少延迟(设置sync_binlog=0|关闭binlog,提高sql执行效率)
- 使用更好的硬件设备作为slave
- 加入缓存,降低mysql压力
mysql日志文件:
-
错误日志: -log-err
-
查询日志: -log
-
慢查询日志: -log-slow-queries
-
更新日志: -log-update
-
二进制日志: -log-bin
-
中继日志:-relay-log
慢查询日志如何设置:
-
全局变量设置
将 slow_query_log 全局变量设置为“ON”状态
mysql> set global slow_query_log=‘ON’;
-
设置慢查询日志存放的位置
mysql>set global slow_query_log_file=’/usr/local/mysql/data/slow.log’;
-
查询超过1秒就记录
mysql> set global long_query_time=1;
-
重启数据库
验证 show variables like ‘%slow_query%’;
mysql安全方面措施:
- 删除数据库不使用的默认用户
- 配置相应的权限(包括远程连接)
- 不可在命令行界面下输入数据库的密码
- 定期修改密码与加强密码的复杂度
- mysql_secure_installation
- –为root用户设置密码
–删除匿名账号
–取消root用户远程登录
–删除test库和对test库的访问权限
–刷新授权表使修改生效
数据库连接不上,原因:
- 用户名错误
- 密码错误
- 服务器名错误
- 服务器端口错误
- 服务器设置错误
- 服务器没有运行
数据库忘记密码怎么解决?
关闭数据库,命令行输入mysqld_safe --skip-grent-tables回车进入交互状态
打开另一个终端,直接mysql回车进入数据库
更新密码update mysql.user set password=password(‘密码’) where user=’root’; 退出数据库,再次登录验证
mysql数据库你们是使用什么工具完成读写分离的:
amoeba支持读写分离
mycat支持读写分离
mysql优化:
首先是确定MySQL的最大连接数,然后为临时表分配足够的内存,增加线程缓存大小
-
系统内核优化
-
数据库性能优化
- 硬件配置 内存 cpu 尽可能大一些,硬盘采用raid10提高IO速度,或者采用SSD硬盘
- 网卡尽可能选千M网卡以上
- 数据库版本,选择合适的数据库版本
- 利用慢查询日志,分析MySQL数据库的索引和慢查询语句
-
数据库配置优化
-
net.ipv4.tcp_fin_timeout = 30
#TIME_WAIT超时时间,默认是60s
-
net.ipv4.tcp_max_syn_backlog = 4096
#进入SYN队列最大长度,加大队列长度可玩2 容纳更多的等待连接
-
max_connections = 151
#同时处理最大连接数
-
open_files_limit = 1024
#打开文件数限制
备份哪些数据:
系统数据库、用户数据库和事务日志
MySQL备份(日常数据):
我在我们公司使用的是我写的一个脚本,利用MySQL本身自带的mysqldump工具进行备份
使用crontab定时计划任务 每天在晚上访问量少的时间段进行增量备份,还有一个月一次的全备
如果说备份量比较大的话,我们会使用Xtrbackup工具
mysqldump热备份,速度一般,数据小的场景
xtrabackup物理热备份,支持完全备份和增备,速度非常快
LVM快照物理备份,只能进行泠备份,innodb不开启独立表空间的话只能备份整个数据库
几种备份:
- 全备:备份数据库所有数据。
- 增备:在上次备份的基础上备份新增数据。
- 冷备:停止服务的基础上进行备份操作
- 温备:服务在线,但仅支持读请求,不允许写请求。
- 热备:不停机备份(实行在线进行备份操作,不影响数据库的正常运行)
MySQL查询缓存开启
have_query_cache表示是否支持查询缓存,YES表示支持
query_cache_type表示缓存类型,ON开启查询缓存
怎么查看数据库的引擎?
查看数据库支持的引擎show engines;查看当前数据库所使用的引擎的话,用show variables like ‘%storage%’;
MySQL 存储引擎 MyISAM和InnoDB区别:
- InnoDB支持事务,MyISAM 不支持事务。
- InnoDB支持外键,MyISAM 不支持外键。
- InnoDB是聚集索引,MyISAM是非聚集索引。
- InnoDB不保存表的具体行数,需要全表扫描。
- MyISAM保存表的行数,执行语句速度很快。
- InnoDB最小的锁粒度是行锁,MyISAM最小的锁粒度是表锁。
innoDB 支持事务、支持行锁和外键约束
myiSAM 原子性、一致性、隔离性、持久性)
mysiSAM没有InnoDB存储速度快
mysiSAM适合做密集型的数据
数据库事务
- A=Atomicity(原子性):要么全部成功,要么全部失败
- C=Consistency(一致性):不存在中间状态.
- I=Isolation:(隔离性): 通常来说:一个事务在完全提交之前,对其他事务是不可见的
- D=Durability:(持久性):一经提交不再改变
MySQL数据库中delete 和truncate的区别:
- delete可带where条件删除,truncate只能删除整个表的数据
- delete支持事务回滚【rollback】,truncate不支持
- 如果清空整个表的话,truncate会重建表结构,效率高,delete效率低
delete语句执行删除的过程是每次从表中删除一行,并且同时将该行的删除操作作为事务记录在日志中保存以便进行进行回滚操作。
truncate则一次性地从表中删除所有的数据并不把单独的删除操作记录记入日志保存,删除行是不能恢复的。并且在删除的过程中不会激活与表有关的删除触发器。执行速度快
表被truncate后,这个表和索引所占用的空间会恢复到初始大小,
delete操作不会减少表或索引所占用的空间。
drop语句将表所占用的空间全释放掉
在速度上,一般来说,drop> truncate> delete。
MHA 【0.58】
话术:
MySQL数据库安全一直都是运维的重中之重,随着业务的发展,数 据库的并发量也在不断的增加,为了保障服务的高可靠性, 以及高可用性,我们进行了数据库硬件升级以及部署了MHA,实现了MySQL的高可用,实 现了数据安全性的提高,使数据信息更加的安全可靠。
1. 负责MySQL集群的日常维护、保证数据库正常运行使用;
2. 负责数据库的日常备份,全备与增量备份;
3. 负责虚拟环境测试数据库架构升级运行情况;
4. 负责参与MHA架构的部署分析,根据实际情况进行升级和调试; 5. 配置IP切换脚本, 当数据库故障的时候从库主动接替主库VIP实现高可用;
6. 负责数据库升级后,加入监控系统,对数据库进行监控;
MHA简介:
一套MySQL高可用软件。在MySQL故障切换过程中,MHA能做到在0~30秒之内自动完成数据库的故障切换操作,并且 在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。MHA里有 两个角色一个是MHA Node(数据节点)另一个是MHA Manager(管理节点)。MHA Manager可以单独部署 在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台 MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新 数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。
MHA节点(4台,一主两从):
node数据节点 manager管理节点
MHA工作流程:
Manager节点通过masterha_manager脚本启动MHA后会先进行检查工作:
Manager节点通过masterha_check_ssh脚本检查各节点的互信配置
Manager节点通过masterha_check_repl脚本检查主从之间的复制情况
检查工作均完成且确认无误后,Manager节点会进行监控工作:
Manager节点通过masterha_master_monitor对主库不断的进行心跳检测,主库3次无响应后会认为其以宕机
当主库宕机后,会开始故障转移工作,首先会对SLAVE进行选主,有以下3种算法:
读取Manager配置文件,判断是否有强制选主的Slave
自动判断目前已有从库的日志量,将最接近主库日志量的从库选为新的主库
根据配置文件中先后顺序进行选主
当选主完成后,Manager节点会再次通过SSH链接已宕机主库,有以下2种情况发生:
已宕机主库的SSH能够链接,表明MySQL服务是由逻辑因素所导致的宕机,此时Manager会通过save_binary_logs脚本,计算各个从库(包括新主库)与已宕机主库之间binlog差异,将已宕机主库的binlog位置找出来并进行截取、分发到各个从库上进行数据对齐,确保数据一致性
已宕机主库的SSH不能链接,表明MySQL服务是由物理因素所导致的宕机,此时Manager会通过apply_diff_relay_logs脚本,计算各个从库relay-log的差异,将差异较大的从库与新主库进行relay-log对齐,确保数据一致性
当所有库的数据一致性被确保之后,所有从库都将会与新主库建立主从关系,同时旧的已宕机主库信息将会从Manager项目配置文件中移除,至此整个MHA软件服务结束,Manager不会再对Node进行管理,接下来需要管理员手动对已宕机主库进行排查恢复,并且手动搭建旧主库与新主库之间的主从关系然后重新启动整个MHA服务。
Redis 【6.0】
redis支持的数据类型:
| 类型 | 作用 | |
|---|---|---|
| 字符串 | string | 这是最简单的类型,就是普通的 set 和 get,做简单的 KV 缓存。 |
| 哈希 | hash | 这个是类似 map 的一种结构,这个一般就是可以将结构化的数据,比如一个对象(前提是这个对象没嵌套其他的对象)给缓存在 redis 里,然后每次读写缓存的时候,可以就操作 hash 里的某个字段。 |
| 列表 | list | list 是有序列表,这个可以玩儿出很多花样。 比如可以通过 list 存储一些列表型的数据结构,类似粉丝列表、文章的评论列表之类的东西。 |
| 集合 | set | set 是无序集合,自动去重。 |
| 有序集合 | sorted set | sorted set 是排序的 set,去重但可以排序,写进去的时候给一个分数,自动根据分数排序。 |
redis用来做什么:
我们公司最常用缓存数据,redis是个缓存数据库,用于存储使用频繁的数据,这样减少访问数据库的次数,提高运行效率,对经常需要查询且变动不是很频繁的数据
redis架构:
- 主从复制
- 哨兵
- proxy集群
redis哨兵
哨兵的话主要是三个功能,监控,提醒,自动故障迁移【高可用】
监控的话就是sentinel会不断的检查master和salve运作是否正常
提醒的话,当某个redis出现问题时,sentinel会向管理者发送通知
自动故障迁移是当master故障宕机时,sentinel发送通告消息,将其中一个slave升级为新的master,发布订阅模式通知其他slave,修改配置文件,保持服务连续性
redis主从原理
主(master)和 从(slave)部署在不同的服务器上,当主节点服务器写入数据时,会同步到从节点的服务器上,一般主节点负责写,从节点负责读
作用:读写分离,提高效率 数据热备份,提供多个副本
主从同步分类:
全量同步
从开启后,会向主发送sync命令
主收到命令后,开始生成rdb文件并使用缓冲区记录所有写的命令
完成后将快照文件和缓冲区发送给从
从收到后,会载入快照文件和执行命令
增量同步
主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令
redis的吞吐量
Redis是单进程单线程的,利用队列技术将并发访问变为串行访问,消除了传统数据库串行控制的开销【多线程的话会涉及到锁和cpu消耗问题】
单点的qps【每秒请求数】10万/秒,tps【每秒处理事务数】8万/秒
Redis 事务:
单独的隔离操作:事务中命令会按顺序去执行,在过程中,不会被其他客户端打断
原子操作:事务中的命令要么全部被执行,要么全部都不执行
Redis回收进程:
客户端运行了新命令,添加了新的数据
redis检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收
击穿、雪崩、穿透:
- 击穿:一条数据过期,大并发过来 —互斥锁
- 雪崩:n条数据过期 —过期时间+随机时间
- 穿透:数据不存在,反复访问数据库 —缓存空值,布隆过滤器
雪崩:当访问量大于服务器的承载能力的时候,redis缓存直接挂掉,请求穿过缓存直达数据库,数据库扛不住,导致数据直接挂掉,最终导致整个系统挂掉,造成雪崩
穿透:一个服务器有上百万的流量请求时,如果这些请求的数据在redis缓存这一层不存在,那么就会穿过redis的缓存直达到后台,也就是mysql服务器,导致整个微服务应用挂掉【这种攻击多指黑客攻击】
击穿:在key非常热点的时期,访问量过多,高并发的持续性的大访问量,将会直接击穿缓存,访问量就都跑到数据库上了,就像屏障上凿出一个洞一样
熔断:当下游服务器不可用或相应过慢的时候,上游服务器为保证自己整体服务的可用性,不再继续调用目标服务器,直接返回,快速释放资源,如果目标服务器好转则恢复调用
解决方案
雪崩:使用集群缓存,保证缓存服务的高可用【主从+哨兵】
穿透:解决的话,主要是针对空值缓存,设置过期时间为1~2分钟
击穿: 1)设置热点数据永不过期【不太建议】
2)根据实际情况设置互斥锁,只让一个线程构建缓存,其他线程等待构建缓存的线程执行完,重新从缓存获取数据
Redis 集群最大节点个数:
【16384】个
Redis字符串的存储量:
512M
Redis槽位:
存储数据,类似于表一样的东西;其实就是虚拟的很小粒度的分区,通过hash算法将数据存放对应的槽里面
Redis持久化两种方式,有什么区别,如何做:
| 方式 | 区别 | 如何做 |
|---|---|---|
| RDB(默认) | 体积小,恢复速度快,安全性低(全备易故障丢失,持久性不如AOF),快照方式保存 | 会单独创建一个子进程【fork】来做持久化,先将数据写进一个临时文件,等持久化过程结束,用临时文件替换之前的持久化文件 |
| AOF | 体积大,恢复速度慢,安全性根据策略决定,文件方式保存 | 将数据变更都写入指定目录下,保存数据完整性,持久化效果好 |
Redis 如何设置密码及验证密码?
设置密码:config set requirepass 123456
授权密码:auth 123456
memcache 和redis有什么区别:
- 持久化:Redis支持持久化,Memcache不支持持久化
- 多线程:Memcache支持多线程,Redis支持单线程,CPU利用Memcache利用率更高
- 分布式:Redis做主从结构,而Memcache服务器需要通过hash一致化来支撑主从结构
- 数据结构:Memcache仅能支持简单的K-V形式,Redis支持的数据更多
- 虚拟内存:Redis当物理内存使用完时,会将一些很久没有用的内存交换到磁盘,而Memcache采取的LUR策略,将一部分数据刷新
redis为什么比MySQL快:
redis是非关系型数据库,处理速度快,
负载均衡
硬件:F5,A10,Array
软件:LVS,Nginx,Haproxy
LVS
LVS和Nginx的区别:
Lvs是位于4层,抗负载能力强,应用广泛
Nginx4、7层都可以做,对网络依赖性小,稳定,支持正则、动静分离等。还是一个web服务器,缓存服务器
LVS抗负载能力强,因为lvs工作方式的逻辑是非常简单的,IO线程占用低,而且工作再网络层第4层,仅作请求分发用,没有流量,所以在效率上基本不需要太过考虑。lvs一般很少出现故障,即使出现故障一般也是其他地方(如内存、CPU等)出现问题导致lvs出现问题
Nginx工作在网络的第7层,所以它可以针对http应用本身来做分流策略,比如针对域名、目录结构等,相比之下lvs并不具备这样的功能,所以nginx单凭这点可以利用的场合就远多于lvs了;但nginx有用的这些功能使其可调整度要高于lvs,所以经常要去触碰触碰,由lvs的第2条优点来看,触碰多了,人为出现问题的几率也就会大
负载这一块,我们公司使用的是LVS,nginx之前也使用一些,在这几年的使用中,我发现几个优点,
lvs工作在第四层,仅仅做请求分发的作用,负载能力强,而且IO线程占用比较少,没有流量,逻辑简单,很少出现故障
在使用nginx,它是工作在七层,安装简单,如果出现问题排错也方便,本身可以做正反向代理,web服务器,负载均衡,而且模块也特别多,
我们在使用lvs过程中我使用的是DR模式,我给你讲一讲DR模式原理吧,DR模式通过改写请求报文的目标MAC地址,将请求发送给真实服务器,而真实服务器响应的处理结果直接返回给客户端
lvs模式:
| 模式 | 原理 |
|---|---|
| DR | (半开式网络,性能和成本相对比较理想,节点和调度器都在局域网,而节点响应却通过路由返回给用户【VIP和RIP要在同一网络】)**DR模式是通过改写请求报文的目标MAC地址,将请求发给真实服务器的,而真实服务器响应后的处理结果直接返回给客户端用户,对整个系统的吞吐量大大提高。**同TUN模式一样,DR模式可以极大的提高集群系统的伸缩性。而且DR模式没有IP隧道的开销,对集群中的真实服务器也没有必要必须支持IP隧道协议的要求。但是要求调度器LB与真实服务器RS都有一块网卡连接到同一物理网段上,必须在同一个局域网环境。DR模式是互联网使用比较多的一种模式。 |
| TUN | 开放式网络,通过调度器接收用户请求,各个节点通过各自的因特网连接直接回应客户机,代价昂贵 |
| NAT | 网络地址转换,安全性高,负载低,只通过网关接收和响应请求 |
| FULLNAT |
lvs算法:
- rr 轮询算法 按照顺序轮流分配
- wrr 加权轮询 根据服务器性能不同,动态调整
- lc最小连接数 根据请求数量依次分配到由少到多的服务器
Nginx 【1.20】
为什么nginx性能这么高:
得益于它的事件处理机制:
异步非阻塞事件处理机制:运用了epoll模型,提供了一个队列,排队解决
事件收集器,事件发送器,事件处理器
Nginx与Apache的区别:
nginx 处理静态文件好,静态处理性能比 apache 高三倍以上
nginx 作为负载均衡服务器,支持 7 层负载均衡
处理请求是异步非阻塞的,负载能力比 apache 高很多,而 apache 则是阻塞型的。
在高并发下 nginx 能保持低资源低消耗高性能 ,而 apache 在 PHP 处理慢或者前端压力很大的情况下,很容易出现进程数飙升,从而拒绝服务的现象。
apache 发展到现在,模块超多,基本想到的都可以找到
apache 更为成熟,少 bug ,nginx 的 bug 相对较多
apache 超稳定
apache 在处理动态请求有优势
两者最核心的区别在于 apache 是同步多进程模型,一个连接对应一个进程,而 nginx 是异步的,多个连接(万级别)可以对应一个进程
需要性能的 web 服务,用 nginx 。如果不需要性能只求稳定,更考虑 apache
更为通用的方案是,前端 nginx 抗并发,后端 apache 集群,配合起来会更好。
Squid、Varinsh、Nginx 做缓存区别:
-
SQUID:是功能最全面的,但是架构古老,性能普通
-
Varnish:是速度一流的内存缓存,无存储引擎,容量受到限制,适合缓存页面和图片
-
Nginx:用了插件可以做缓存,只能缓存静态页面
nginx正向代理和反向代理区别以及列举 nginx作为反向代理的负载均衡算法和常用模块:
正向代理即是客户端代理, 服务端不知道实际发起请求的客户端
反向代理即是服务端代理, 客户端不知道实际提供服务的服务端
算法:轮询;权重;ip_hash;fair;url_hash
常用模块:
- rewrite重写模块
- access来源控制模块
- ssl安全模块
- status监控模块
- proxy前端代理模块
- upstream后端代理模块
nginx调优:
- 隐藏 Nginx 版本号和软件名字【server_tokens off;】
- 更改 Nginx 服务的默认用户和权限【user 用户】
- 优化 Nginx worker 进程最大打开文件数
- 优化连接超时时间 【keepalived_timeout】
- 开启高效文件传输模式【gzip on】
- 缓存
- nginx 事件处理模型【use epoll】
- nginx的cpu亲和力【worker_cpu_affinity】
- 文件上传限制大小【gzip_buffers 4 32k;】
- expire 缓存时间调优
- 系统连接数
- 优化工作进程数 worker_processes
- 优化 Nginx 单个进程允许的最大连接数worker_connections
- Nginx 防爬虫优化
nginx配置文件详解:
-
优化
-
-
worker_processes 1; --指定nginx要开启的进程数。最好与CPU个数相同。
-
worker_connections 1024; --每个进程的最大连接数
-
sendfile on; --高效文件传输模式。
-
gzip on; --支持压缩传输,提高传输速度
-
tcp_nopush on;优化网络传输
-
-
-
安全
location /admin {
allow 192.168.1.10;
deny all;
}
Nginx虚拟主机:
-
基于域名的虚拟主机:通过域名来区分虚拟主机——应用:外部网站
-
基于端口的虚拟主机:通过端口来区分虚拟主机——应用:公司内部网站,外部网站的管理后台
-
基于ip的虚拟主机:几乎不用。
nginx图片缓存30天如何写:
location ~ .*\.(gif|jpg|jpeg|png|bmp|swf)$
{expires 30d;}
location ~ .*\.(js|css)?$
{expires 12h; }
nginx gzip模块如如何使用?
http{
gzip on; //开启压缩
gzip_min_length 1k; //设置阀值
gzip_buffers 4 32k; //设置压缩缓冲区数量和大小
gzip_http_version 1.1; //版本
gzip_comp_level 6; //压缩 比例
gzip_types text/plain text/css text/javascript application/json application/javascript application/x-javascript application/xml; //规定文件压缩类型
gzip_vary on; //启用
}
nginx如何设置防ddos攻击:
- 限制每秒请求数
- 限制IP连接数
- 或者使用DDoS deflate工具通过日志分析拦截
Nginx中,解释如何在URL中保留双斜线:
syntax: merge_slashes off
default: merge_slashes on
context: http,server
Nginx命令:
-
重启Nginx:
/usr/nginx/sbin/nginx -s reload -
检查配置文件的准确性:
/usr/nginx/sbin/nginx -tyum安装 启停 nginx 源码安装 启停 /usr/local/nginx/sbin/nginx // -s stop 不停机启动 nginx -s reload 指定配置文件启动 /usr/local/nginx/sbin/nginx -c /usr/local/nginx/conf/nginx.conf 检查配置文件 nginx -t 查看版本 nginx -v
NGINX配置文件分为那几部分:
nginx配置文件分为5个区块
Main事件区块(全局块):影响全局的配置。
-
Events模块:影响服务器与用户网络连接的配置
-
HTTP模块:http的全局设置。
-
server模块:指定虚拟主机域名、IP和端口
-
location模块:location部分用于匹配网页位置
-
upstream模块:后端服务器的负载均衡
nginx模块:
邮件模块,负载均衡的模块,防DDOS的模块,缓存模块
Nginx日志文件:
/var/log/nginx/access.log
记录远程ip,时间,状态码,发送数据大小,从哪个页面访问的,客户端浏览器相关信息
Nginx工作模式:
- 单进程:只有一个进程,所有工作都由它负责,一般在开发阶段和调试使用
- master-worker:一个master管理至少一个worker,master管理worker有信号处理,加载配置等,worker挂掉master会再启一个,稳定和性能高
nginx服务器上master和worker的区别:
master进程管理worker进程,也负责判断配置文件的语法
worker进程处理事务请求
NGINX如何将worker 进程绑定特定内核:
worker_cpu_affinity
写一个每天0点执行的删除nginx日志的脚本,保留最近七天的日志
crontab -e 00 00 * * * sh /root/find.sh
find /var/log/nginx -type f -mtime +7 -name ‘.log’ -exec rm -rf {} ;
find /var/log/nginx -type f -mtime +7 -name '.log’ |xargs rm -rf
fastcgi:
FastCGI:Nginx本身不支持PHP等语言,但是它可以通过FastCGI来将请求扔给某些语言或框架进行处理
fastcgi 与 cgi 的区别:
fastcgi 新增功能
- 分布式计算 【充分利用系统性能,提升系统安全性】
- 多角色与可扩展角色【认证和身份检查、转换数据格式】
HTTP返回码的意义:
| 200:请求成功 | 301:被请求资源永久重定向 | 302:请求资源临时重定向 | 304:未修改 |
|---|---|---|---|
| 403:禁止访问 | 404:页面找不到 | 500:内部服务器错误 | 502:网关无效 |
| 503:服务器不可用 | 504:网关超时 |
静态网页,动态网页:
静态页面在服务器里面是真实存在的,访问静态页面不需要经过数据库,静态页面是静态链接。不含有?号的html类型(html,html,shtml,xhxml,jhtml,xml)
动态页面在服务器里面不是真实存在的,访问动态页面需要经过数据库,动态页面是动态连接。含有?的,或是以.asp、.php、.jsp、.aspx结尾的都是动态。
keepalived
工作原理:
工作原理:Keepalived高可用是通过 [VRRP](vrrp:虚拟路由冗余协议 ,三层协议)进行通信, VRRP是通过竞选机制来确定主备,主优先级高于备,因此,工作时主会优先获得所有资源,备节点处于等待状态,当主宕机时,备节点接替主节点资源对外提供服务,这个时间非常迅速,小于1s,保证服务连续性
脑裂:
脑裂:在高可用HA中,心跳新发生断裂,由原本一个整体变为两独立的节点,出现两个master来争抢资源,导致系统崩溃,数据丢失,解决方法的话,提前部署两根心跳线防止故障发生,还有就是做好监控报警,第一时间发现问题并及时处理,降低损失
原因:
- 心跳线坏了(包括断了,老化)
- 网卡及相关驱动坏了,ip配置及冲突问题(网卡直连)
- 防火墙阻挡心跳消息
- 仲裁的机器出问题(采用仲裁的方案)
- 其他服务配置不当
- 心跳线间连接的设备故障(网卡及交换机)
解决方案:提前用以太网电缆串行连接两根心跳线防止故障发生
通常采用隔离(Fencing)机制
当检测到裂脑时强行关闭一个心跳节点(这个功能需特殊设备支持,如Stonith、feyce)。相当于备节点接收不到心跳消患,通过单独的线路发送关机命令关闭主节点的电源。
预防:做好监控报警,第一时间发现问题并及时处理,降低损失
keepalived的模块:
-
core模块:为keepalived的核心,负责主进程的启动、维护以及全局配置文件的加载和解析。
-
check模块:负责健康检查,包括常见的各种检查方式。
-
vrrp模块:实现VRRP协议的
Tomcat 【9】
Tomcat 调优做过哪些:
内存,并发,缓存,安全,网络,系统
- 内存:Xmx 可用堆最大内存 Xms:初始化时堆的最小内存
- 并发:maxThreads 客户请求最大线程数
- 缓存:compression 打开压缩功能
- 超时响应时间【connrctionTimeout】
- 减少空闲线程数【maxSpareThreads】
- Tomcat的容器编码格式【URIEncoding=utf-8;】
连接数优化
优化线程数
关闭客户端dns查询
修改错误代码的跳转页面,(出现错误码的时候会显示tomcat版本)
tomcat目录结构:
- bin:命令目录
- conf:配置文件目录
- logs:日志目录
- webapps:应用程序目录
- webapps/ROOT :根目录
tomcat的三种模式
BIO:一个线程处理一个请求【阻塞IO】
缺点:并发量高时,线程数较多,浪费资源 //Tomcat7默认使用
NIO:通过少量的线程处理大量的请求【非阻塞IO】 //Tomcat8默认使用
APR:(Apache Portable Runtime)从操作系统层面解决io阻塞问题
Linux如果安装了apr和native,Tomcat7/8默认使用
tomcat内存泄漏和内存溢出
叙述型:
内存泄漏:内存空间使用完毕之后未被收回,也就是一个内存对象的生命周期超出了程序需要它的时间长度
内存溢出:程序申请内存时,没有足够的内存供使用,好比程序申请了50M的内存,可内存只剩下了30M
简答型:
内存溢出:申请不到足够的内存;
内存泄露:无法释放已申请的内存;
两者关系:内存泄露→剩余内存不足→后续申请不到足够内存→内存溢出
解决方案:修改JVM启动参数【Xms,Xmx】,增加内存
检查错误日志,查看OutOfMemory 是否有异常
检查代码【死循环/递归调用/一次全部查询数据】,进行分析,找出位置进行处理
Tomcat session共享:
Tomcat内置的session复制方案
Spring Session也就是基于redis实现session共享
cookie和session区别:
- 数据存放位置不同:
- cookie数据存放在客户的浏览器上,即网页缓存
- session数据放在服务器上,即key-value形式,如redis 和mongoDB
- 安全程度不同:
- cookie不安全
- session安全
- 数据存储大小不同:
- 单个cookie保存的数据不能超过4K,一个站点普遍上限保存20个cookie
- session存储于服务端,浏览器对其没有限制
Gitlab 【6.5】
话术:
为了实现测试环境的持续集成与持续发布,监控软件开发流程,快速定 位及处理问题,展示开发效率,我们使用了 CI/CD 的方案。
1. Gitlab 私有库和 Jenkins 及插件的部署和调试;
2. Gitlab 监测代码库,并在有提交时自动触发;
3. Jenkins 调用 Maven 对代码进行构建,构建状态检测,故障排查;
4. 与开发人员沟通,将代码上线到服务器,日常维护和巡检;
工具清单:
- Linux:这是一切操作的基础,本文中主要用到的Linux版本为Centos8
- Gitlab:负责管理源代码
- Jenkins:负责持续集成部署,
- Docker:负责搭建Gitlab、Jenkins、Web应用。
- Nginx:Web应用服务器、反向代理
- PHP:解析PHP代码
- GIT:管理源代码
CI/CD持续集成持续部署
持续集成:研发频繁的将代码提交到主干上
优势:快速发现错误 || 防止分支偏离主干
持续交付:将集成后的代码部署到更贴近真实运行环境中
通过一个按键就可以随时随地实现应用的部署上线,减少软件开发的成本与时间,减少风险
持续部署:当交付的代码通过评审之后,自动部署到生产环境中
描述一线自动化上线流程:
研发人员上线代码到gitlab项目仓库、jenkins通过git插件将代码拉取到本地,通过ssh传输到ansible批量管理服务器
说明一下,Jenkins与Gitlab的交互包括两部分:
- 一部分是Gitlab通过Webhook提交Git Push事件,触发Jenkins开始执行集成任务,
- 另一部分是Jenkins通过Git从Gitlab拉取源代码。
代码上线:gitlab+jenkins+ansible+sonarqube
CI/CD过程:持续集成 持续交付 持续部署
研发环境(开发环境) -> 提交到代码仓库 -> 测试环境(测试工程师) -> 生产环境(运维工程师)
git gitlab(带web管理界面的git) github
svn和Git区别
svn是集中式版本控制系统,git是分布式版本控制系统。
svn主要是项目管理,git主要是代码管理。
svn由项目经理协调多个项目统筹开发,git通过网络多人开发同一项目。
harbor工具:
harbor是私有镜像仓库
发布策略 :
应用程序升级面临最大挑战是新旧业务切换,将软件从测试的最后阶段带到生产环境,同时要保证系统不间断提供服务。长期以来,业务升级渐渐形成了几个发布策略:蓝绿发布、灰度发布和滚动发布,目的是尽可能避免因发布导致的流量丢失或服务不可用问题。
- 蓝绿部署:旧版本不停,新版本进行测试,新版ok,将用户切换到新版本,同时更新旧版本
- 滚动发布:取出部分服务器更新,更新完后继续使用,循环往复,直至全部更新完
- 灰度发布:ABtest为例,一部分A继续用,一部分测试B,B无问题,A的迁移至B上
git常用命令
git init 初始化git仓库
git add * 把代码添加到暂存区
git rm xxx :删除暂存区代码
git status 查看工作区里代码状态
git commit -m “xxx” 把暂存区的代码提交到版本库
git checkout – xxx 撤销修改
git reset HEAD 回退版本
git log 查看提交历史版本信息
git reflog 查看所有的操作历史
git reset --hard xxx 还原版本
git branch 查看有多少个分支默认只要一个master分支
git branch xxx 创建自定义的分支
git checkout xxx 切换自定义的分支
git merge xxx 合并分支里的新内容
git-rake gitlab:backup:create 备份命令
遇到的问题:
-
多个开发人员进行不同需求的代码同时测试时的相互干扰问题。
-
1、合并代码时经常发生冲突;
-
2、一人代码写错,影响所有人等。
解决方案:
- 多分支同时部署、测试的方案。具体就是每一个开发者的分支代码都可以独立部署到测试服务器(比如,不同的根目录,不同的容器),然后,各开发者可以在各自的测试分支独立调试。
- 配置项目依赖的关系,Jenkins的并发数
首先我们有自己的特性分支,所以冲突发生的并不多,但也遇到过 两人同时修改一个文件,提交时就会报错 解决的话,修改本地冲突文件使其与远程仓库的文件保持一致后,需要提交后才能消除冲突 还有就是积极与同事交流头痛,避免冲突 -
jenkins 【2.3】
jenkins简介
持续、自动化的构建和测试软件的web工具
也就是自动化编译、打包、分发部署
优势:监控软件开发流程,快速问题定位及处理,提示开发效率
Jenkins用过哪些插件:
- Git插件将gitlab仓库内容拉取到本地
- GitLab配置Gitlab的相关认证实现触发
- Ansible执行Ansible任务
- Publish Over SSH负责传输
- Maven
ansible
ansible是批量管理工具
ansible的playbooke是干什么的:
playbook是ansible用于配置,部署,和管理被控节点的剧本
playbook都写过哪些
免秘钥安装部署一些源码包,
比如nginx,tomcat。
ansible插件:
- Connection通信插件
- Lookup循环插件
- Vars变量插件
ansible模块:
ping yum copy command shell script file service
ansible和saltstack的区别:
SaltStack是C/S架构,易扩展
Ansible 依靠SSH传输,无客户端,不易扩展
1.响应速度
SaltStack的master和minion主机是通过ZeroMQ传输数据,而Ansible是通过标准SSH进行数据传输,SaltStack的 响应速度要比Ansible快很多。
2.安全
SaltStack使用ZeroMQ进行数据传输,ZeroMQ本身不加密,AES加密,需注意MITM攻击
Ansible使用标准SSH连接传输数据,不需要在远程主机上启动守护进程,并且标准SSH数据传输本身就是加密传输,这样远程主机不容易被攻击。
3.自身运维
SaltStack需要在Master和Minion主机启动守护进程,自身需要检测守护进程的运行状态,增加运维成本。Ansible和远端主机之间的 通信是通过标准SSH进行,远程主机上只需要运行SSH进程就可以进行运维操作,SSH是机房主机中一般都安装和启动的进程,所以在Ansible进行运 维的时候只需要关注Ansible主机的运行状态。Ansible对机房运维不会增加过多的运维成本。从工具本身的运维角度来说,Ansible要比 SaltStack简单很多。
4.使用语法
Ansible的Playbook语法要比SaltStack的State语法具有更好的可读性。
ELK
话术:
为了更直观简洁的查看日志,通过搭建 ELK 日志分析系统来完成日 志的收集和分析,其中 Elasticsearch 是个开源分布式搜索引擎,Logstash 主要是用来日志的搜集、分析、过滤日志的工具,Kibana 也是一个开源和免费的 工具,Kibana 可以为 Logstash 和 ElasticSearch 提供的日志分析友好的 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
1. 配置服务器 JDK 环境
2. 测试、部署、配置 Elasticsearch
3. 采集日志端搭建 Logstash,修改相应配置
4. 安装 Kibana,配置可视化图形
5. 负责 Nginx 日志的信息,查看数据信息,分析用户行为的日志 6. 负责在多种ELK部署方案中根据平台现有情况进行方案选定
7. 负责ELK平台的规划和搭建部署
8. 负责协调开发测试人员进行ELK平台的配置适配
9. 针对平台现状对ELK进行索引分片优化
10.负责日常数据检索,为运营人员提供技术支持
ELK组成:
- Elasticsearch:存储和搜索日志
- Logstash:收集、过滤日志
- kibana:web界面展示
- filebeat:收集日志(由于Logstash是个重量级的日志收集工具,会消耗大量的资源,所以我们在日常的生产环境通常会使用到filebeat这个轻量级的日志收集工具。)
Elasticsearch 是一个基于 Lucene 的、支持全文索引的分布式存储和索引引擎,主要负责将日志索引并存储起来,方便业务方检索查询。
Logstash是一个日志收集、过滤、转发的中间件,主要负责将各条业务线的各类日志统一收集、过滤后,转发给 Elasticsearch 进行下一步处理。
Kibana是一个可视化工具,主要负责查询 Elasticsearch 的数据并以可视化的方式展现给业务方,比如各类饼图、直方图、区域图等。
为什么用ELK:
一般我们需要进行日志分析场景:直接在日志文件中 grep、awk 就可以获得自己想要的信息。但在规模较大的场景中,此方法效率低下,面临问题包括日志量太大如何归档、文本搜索太慢怎么办、如何多维度查询。需要集中化的日志管理,所有服务器上的日志收集汇总。常见解决思路是建立集中式日志收集系统,将所有节点上的日志统一收集,管理,访问。
ELK作用:
对日志的实时分析,可以随时掌握服务的运行状况、统计 PV/UV、发现异常流量、分析用户行为、查看热门站内搜索关键词等。
帮助运维人员进行线上业务的准实时监控、业务异常时及时定位原因、排除故障、程序研发时跟踪分析Bug、业务趋势分析、安全与合规审计,深度挖掘日志的大数据价值。
1、日志查询,问题排查,上线检查。
2、服务器监控,应用监控,错误报警,bug管理。
3、性能分析,用户行为分析,安全漏洞分析,时间管理。
4、web界面展示
- 清晰明了,方便快速定位和排查问题
- 监控和预警。 日志,监控,预警是相辅相成的。
- 关联事件。多个数据源产生的日志进行联动分析,通过某种分析算法,就能够解决生活中各个问题。
- 数据分析。 这个对于数据分析师,还有算法工程师都是有所裨益的。
ES的特点
实时分析
分布式实时文件存储
文档导向,所有对象全部是文档
高可用性,易扩展,支持集群(Cluster)、分片和复制(Shards 和 Replicas)
接口友好,支持 JSON
ES的缺点
ES没有事务,不支持授权和认证,是一种面向文档的数据库
ELK架构:
架构图一:
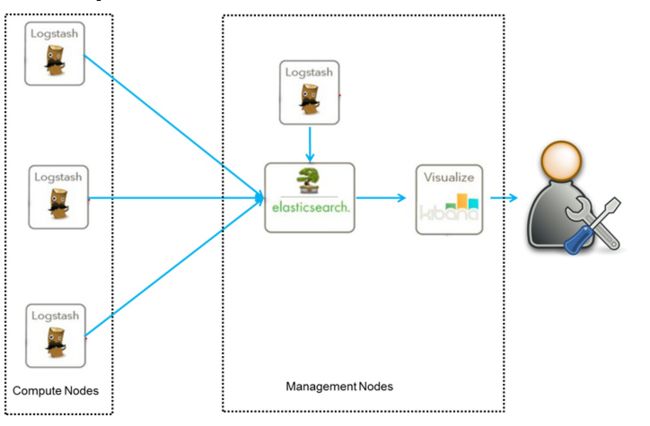
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
- 优点:搭建简单,易于上手。
- 缺点:logstash消耗资源大,*运行占用*cpu和内存高,另外没有消息队列缓存**,存在数据丢失隐患。
- 应用场景:适合小规模集群使用。
架构图二:
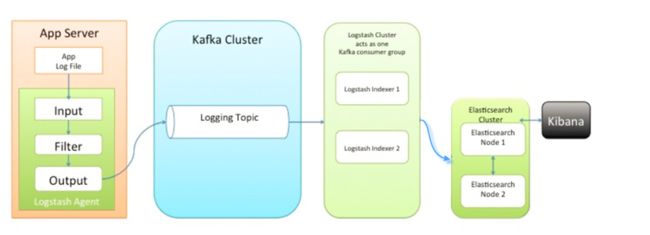
此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
- 优点:引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性。
- 缺点:***依然存在*Logstash占用系统资源过多的问题。
- 应用场景:适合较大集群方案。
架构图三:
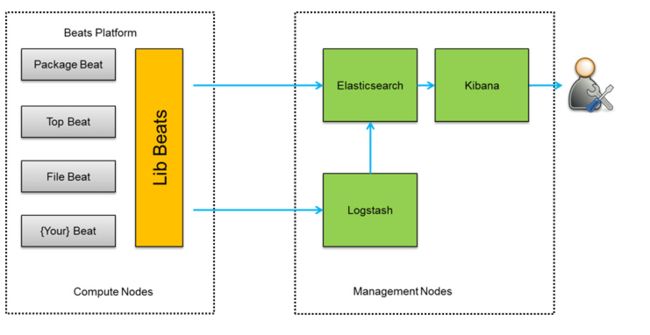
此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
ELK插件:
head 插件:交互的Web前台
kopf 插件:是Es的管理工具,提供了对ES集群操作的API
bigdesk插件:是Es的集群监控工具,提供动态的图表与统计数据
input output head 健康检查,获取节点列表,获取索引列表,创建名为customer的索引
ES分片:
ES调优实战:
存在的问题
随着进入量的上涨,ES集群内部写入峰值达到80w/s,日均文档总量达到280亿,索引占用总量达到 67T,每天新增索引量达到1000+,而每日文档新增存储总量达到10T。
机器配置采用为:64个4C 16g的数据节点,平均CPU使用率在45-50%之间;最大CPU使用率在80%左右;内存使用率60%左右,而磁盘平均使用率达到了53%,整体流程为。
天机阁是基于业务Appid维度按天索引的策略,而伴随业务量的极速上涨主要暴露出来的问题为:
(1)集群内部分片过多
ES分片过多
分片过多的缺点主要有以下三个方面:
ES每个索引的分片都是一个Lucene索引,它会占用消耗CPU、内存、文件句柄;
分片过多,可能导致一个节点聚集大量分片,产生资源竞争;
ES在计算相关度词频统计信息的时候也是基于分片维度的,如果分片过多,也会导致数据过少相关度计算过低。
(2)分片大小不均匀
部分索引的分片容量超过50G,侧面反应了这些索引分片策略的不合理,最终会导致索引的查询性能变慢。
(3)写入耗时过大,部分索引查询性能慢
ES写入耗时达到(1500ms-2000ms),此外分片过大也直接影响到索引的查询性能。
(4)索引创建过慢(1分钟),大量写入被拒绝
集群没有设置主节点,导致创建索引时,数据节点要充当临时主节点的角色,写入量较小的时候,影响不大,当写入压力过大时,会加剧数据节点的负载,影响索引的创建速度。
当出现密集型索引创建时,这个问题被无限放大,索引创建同时也会伴随大量的元数据移动,更加剧了节点负载,从而导致大量数据写入被拒绝现象。
而写入被拒绝最终会导致上游Flink集群剧烈抖动(写入失败抛出大量异常),以致于索引创建高峰期经常出现2-3小时的集群不可用状态。
(5)系统出现大量异常日志
ES服务器异常,主要分为两类,一类是:数据解析异常,另一类是:Fields_limit异常。
(6)索引的容量管理与维护困难
主要是解决大规模以及日益增长数据场景下,集群的自动化容量管理与生命周期管理的问题。
- 优化一期
- 优化点1:优化集群内部分片过多、分片不合理、节点负载不均等问题。
其中主要涉及了二个问题:
如何确定索引单个分片大小?-> 小于40G
如何确定集群中分片数量?-> 节点堆内存节点数200 = 2万左右
上述问题可以阅读ES官方文档和腾讯云ES文档得到全面的答案,这里不再赘述,总而言之,查询和写入的性能与索引的大小是正相关的,要保证高性能,一定要限制索引的大小。
而索引的大小取决于分片与段的大小,分片过小,可能导致段过小,进而导致开销增加,分片过大可能导致分片频繁Merge,产生大量IO操作,影响写入性能。通过阅读相关文档,我提炼了以下三条原则:
分片大小控制50G以内,最好是20-40G,以均衡查询和写入性能。
每个节点可以存储的分片数量与可用堆内存成正比,一条很好的经验法则:“确保每个节点配置的每G堆内存,分片数在20个以下”。
分片数为节点数整数倍,确保分片能在节点之间均衡分布。
当然最好的方法是根据自身业务场景来确定分片大小,看业务是注重读还是注重写以及对数据实时性、可靠性的要求。
天机阁的索引设计模式是非常灵活的,属于典型的时序类型用例索引,以时间为轴,按天索引,数据只增加,不更新。
在这种场景下,搜索都不是第一要素,查询的QPS很低。原先的分片策略针对容量过低的索引统一采用5个分片都默认配置,少数超过500G的大索引才会重新调整分片策略。
而随着近期接入业务的不断增多以及索引进入量的暴涨,集群内部出现了许多容量大小不一,且分布范围较广的索引。老的配置方式显然已经不太合理,既会导致分片数急剧增长,也影响索引的读写性能。
所以结合业务重新评估了集群中各个索引的容量大小,采用分级索引模版的分片控制策略,根据接入业务每天的容量变化,实现业务定制化的自适应分片。
一般而言:当用户遇到性能问题时,原因通常都可回溯至数据的索引方式以及集群中的分片数量。对于涉及多租户和用到时序型索引的用例,这一点尤为突出。
优化点2:优化写入性能。
减少集群副本分片数,过多副本会导致ES内部写扩大。ES集群主用于构建热门Trace索引用于定位问题,业务特性是写入量大而数据敏感度不高。所以我们可以采用经济实惠的配置,去掉过多副本,维护单副本保证数据冗余已经足够,另外对于部分超大索引,我们也会采用0副本的策略。
索引设计方面,id自动生成(舍弃幂等),去掉打分机制,去掉DocValues策略,嵌套对象类型调整为Object对象类型。此处优化的目的是通过减少索引字段,降低Indexing Thread线程的IO压力,经过多次调整选择了最佳参数。
根据ES官方提供的优化手段进行调整,包括Refresh,Flush时间,Index_buffer_size等。
上述优化,其实是对ES集群一种性能的取舍,牺牲数据可靠性以及搜索实时性来换取极致的写入性能。但其实ES只是存储热门数据,天机阁有专门的Hbase集群对全量数据进行备份,详细记录上报日志流水,保证数据的可靠性。
客户端API升级,将之前ES原生的批量API升级为Transport API,策略为当数据缓存到5M(灵活调整)大小时,进行批量写入(经过性能测试)。
- 优化点3:优化索引创建方式。
触发试创建索引改为预创建索引模式。
申请专用主节点用于索引创建工作。
- 优化点4:优化ES服务器异常。
调整字段映射模式,Dynamic-Mapping动态映射可能导致字段映射出现问题,这里修改为手动映射。
调整Limit Feild限制,修改ES索引字段上限。
业务层加入数据清洗算子,过滤脏数据以及埋点错误导致Tag过多的Span,保护存储。
ES调优:
- 1.概述
- 1.Elasticsearch部署建议
-
- 1.1. 选择合理的硬件配置:尽可能使用 SSD
- 1.2. 给JVM配置机器一半的内存,但是不建议超过32G
- 1.3. 规模较大的集群配置专有主节点,避免脑裂问题
- 1.4. Linux操作系统调优
- 2.索引性能调优建议
-
- 2.1. 设置合理的索引分片数和副本数
-
- 2.1.1 索引设置
- 2.1.2 mapping 设置
- 2.1.3 写入数据示例
- 2.1.4 修改副本数示例
- 3. 使用批量请求
-
- 3.1 批量请求接口API
- 4. 通过多进程/线程发送数据
- 5. 调大refresh interval
- 设置 refresh interval API
- 5. 配置事务日志参数
- 6. 设计mapping配置合适的字段类型
- 普通查询
- 过滤器(filter)查询
- 写入时指定路由
- 查询时不指定路由,需要查询所有分片
- 返回结果
- 查询时指定路由,只需要查询1个分片
- 返回结果
- 索引forcemerge API
- 索引关闭API
- 分词效果测试API
- 查询聚合节点配置(conf/elasticsearch.yml):
- 查询请求示例
- teminate_after 查询语法示例
- search_after查询语法示例
- 5. Elasticsearch调优参数说明
ES中的倒排索引:
倒排索引是搜索引擎的核心,是一种想数据结构一样的散列图,可将用户从单词导向文档或网页,主要目的是从文件中款速搜索找出想要的数据
ES中的集群、节点、索引、文档、类型分别是什么?
集群【cluster】:一个或多个节点(服务器)的集合,共同保存了整个数据,并提供跨所有节点的联合索引和搜索功能
节点【node】:属于集群一部分的单个服务器,存储数据并参与群集索引和搜索功能
索引:定义多种类型的映射,好比关系数据库中的“数据库”
【Shards: 索引的分片集合】【eplicas: 索引的拷贝】【Filed:ES的最小单位】
文档【index】:类似关系数据库中的一行
索引中的每个文档可具有不同的结构(字段),但通用字段应该具有相同的数据类型
类型【type】:索引的逻辑类别/分区,其语义完全取决于用户
elk一般用来收集哪些日志:
nginx tomcat mysql 错误日志 访问日志 数据库慢查询日志
日志分析你们关注哪些参数:
- 客户端的ip地址
- 访问时间
- HTTP协议
- 请求状态
参数用来分析什么:
分析:是否出现故障,故障的原因,有哪些事情发生
Nginx日志分析怎么做的:
思路:
-
分析截止目前为止访问量最高的IP排行。
-
分析从早上9点至中午12点总的访问量。
-
分析上一秒的访问请求数。
-
找到当前日志中502或者404错误的页面并统计。
| 关注的参数: | 定义 |
|---|---|
| 网站并发连接数 | 定义为网站服务器在单位时间内能够处理的最大连接数。示例:某网站的并发是5000.意味着单位时间内(理解为1秒或数秒内),正在处理的连接数,正在建立的连接数,加起来一共是5000个。 |
| IP | 即Internet Protocol,一般指独立IP数,独立IP数是指不同IP地址的计算机访问网站时被计的总次数。一般一天00:00-24:00内相同IP地址只被计算一次。 |
| PV | 即Page View,中文翻译为页面浏览,即***页面浏览量或点击量***,不管客户端是否相同,也不管IP和网站页面是否相同,用户只要访问网站页面就会计算PV,一次计为一个PV |
| UV | 即Unique Visitor,***用户访问数,***同一个客户端(PC或移动端)访问网站被计为一个访客。一天(00:00-24:00)内相同的客户端访问同一个网站只统计一次UV。UV一般是以客户端Cookie等技术作为统计依据的,实际统计会有误差。 |
| qps | 每秒请求数 |
| tps | 每秒处理事务数 |
| DAU | 日活跃用户数量 |
| MAU | 月活跃用户人数 |
| 并发数 | 同时访问服务器的连接数 |
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.htmlLogstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.htmlKibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.htmlelasticsearch中文社区:
https://elasticsearch.cn/
Logstash 三个组件
input收集数据,filter处理数据,output输出数据
Logstash事件处理:
Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
logstash 特点
所有数据集中处理
不同格式数据的正常化
自定义日志格式迅速扩展
自定义数据源轻松添加插件
kibana特点
灵活的分析、可视化平台
数据图谱分析【旭日图、饼状图、柱状图、条形图、趋势图】
为不同用户显示直观的界面
即时分享和嵌入的仪表板
遇到的问题:
-
在es上查询,一直查不到,导致超时的情况:
原因分析: 长时间停止ES访问后,与es服务器建立的HTTP连接死掉,需要重新建立连接
解决方案:
增加 httpClientBuilder.setKeepAliveStrategy((response, context) -> Duration.ofMinutes(5).toMillis()); 配置,保持client 每 5分钟 发送数据保持http存活 -
插入数据量过大,导致超时:
原因分析:经分析问题,可能由于大量插入数据,每次插入一条,然后线程池线程全部被用光,所以一直在等待直接timeout超时30s所以抛错
解决方案:
1. 先确定插入数据量是否过大,插入大量数据需要批量插入,切勿单条插入。 由于Http协议底层是基于TCP协议来和对端网络建立连接,TCP协议建立网络连接需要经过三次握手,相对比较耗时,HttpClient为了提升性能,用连接池的方式对提交的连接请求进行管理,每次请求都从连接池里取连接,如果存在直接返回,如果不存在,放入队列等待,直到超过设置的timeout时间报错timeout超时。 2. 如果批量插入,仍然报错timeout就要适当的配置线程数和线程类型。 在yml配置文件中配置线程数 -
问题对应优化:
- 集群内部分片过多
- 分片大小不均匀
- 写入耗时过大,部分索引查询性能慢
- 索引创建过慢(1分钟),大量写入被拒绝
- 系统出现大量异常日志
- 索引的容量管理与维护困难
docker
docker简介:
Docker是一个容器化平台,以容器的形式将应用程序和依赖项打包在一起,以确保应用程序在任何环境中无缝运行
Docker镜像
是Docker容器的源代码,Docker镜像用于创建容器,使用build命令创建镜像
Docker容器
Docker容器包括应用程序及其所有依赖项,作为操作系统的独立进程运行
你用docker做过什么:
docekr部署 zabbix mysql lamp lnmp Tomcat
docker持久化怎么做的:
- 保存到本地磁盘
- volumes(数据卷):存于主机文件系统中的某个区域,由Docker管理(具名挂载;匿名挂载)
- bind mount:存于主机文件系统中的任意位置(指定挂载)
- tmpfs mount(Linux中):存于内存中
dockerfile 与 docker-compose的区别:
docker run:启动容器(针对单个容器,容器最终运行起来是通过拉取构建好的镜像,通过一系列运行指令,如端口映射、外部数据挂载、环境变量来启动服务的)
dockerfile:构建镜像(创建一个镜像,包含安装运行所需的环境、程序代码)
docker-compose:启动服务(多个容器的运行,服务编排,它可以轻松的将多个容器作为service来运行)
docker三剑客:
- Compose:简化容器的生成和运行
- Machine:负责在多种平台上快速安装 Docker 环境
- Swarm:将多个 Docker 主机封装为单个大型的虚拟 Docker 主机
docker私有库:
harbor registry(5000)
docker最小镜像:
alpine (an o pai n)
pid是1的进程:
不能kill,
docker四种网络模式:
bridge【默认,以docker0位网关】
container【容器共享网络】
host【容器与宿主机共享】
none【自定义】
docker命令:
-
拉取镜像:docker pull 镜像名称
-
查看已经下载的镜像:docker images
-
删除镜像:docker rmi 镜像标识
-
运行容器:docker run 镜像名称
-
镜像导出:docker save -o 镜像id
-
镜像导入:docker load -i 镜像文件系统
停止所有容器: docker stop $(docker ps -q) 删除所有停止容器: docker rm $(docker ps -aq)
docker version/info 查看docker版本和信息
ps -ef|grep docker 查看docker引擎进程
docker images 查看本地镜像
docker run -d --name nginx nginx:latest 启动一个容器
docker exec -it nginx /bin/bash 进入一个容器
docker stop/start nginx 关闭一个容器
docker run -d -p 80:80 --name nginx nginx:latest 访问一个容器
docker ps 查看运行的容器
docker ps -a 查看运行和没有运行的容器
docker rmi/rm 删除镜像/容器
```
docker rmi 批量删除:(使用grep和awk过滤得到镜像ID,匹配需要的镜像,获取ID,ID在哪一列就哪一列)
docker rmi $(docker images | grep 要过滤的内容 | awk '{print $3}')
docker容器状态:
四种:运行、已暂停、重启、已退出
docker运行状态:
- created(已创建)
- restarting(重启中)
- running(运行中)
- removing(迁移中)
- paused(暂停)
- exited(停止)
- dead(死亡)
登录docker容器的方式有哪些:
-
使用docker attach 【exit停止容器】
-
使用exec 【exit退出容器】
-
使用nsenter【inspect查看元数据,用PID进入】
-
使用SSH(一般不建议使用)
dockerfile中最常见的指令:
- FROM:指定基础镜像
- LABLE:为镜像指定标签
- COPY:将本地文件复制到容器中
- ADD:解压并复制
- EXPOSE:指定暴露端口
- VOLUME:挂载的目录位置
- RUN:运行指定的命令
- CMD:容器启动时要运行的命令
docekr、kvm、vmware的区别
vmware和kvm属于vm 的管理程序【hypervisor】,在操作系统内核下层运行
docker属于容器管理者【container manager】,在linux内核上层运行
两者对比:
docker比kvm更省资源,可提供非常接近宿主机的性能
而kvm资源隔离比docker更高,kvm支持的操作系统类型更多
遇到的问题:
-
https是私有证书,docker客户端从habor上pull代码的时候会出现认证失败的问题:
-
方法一:
修改配置:
vim /etc/docker/daemon.json
{
"insecure-registries": ["registry.svc.xxx.cn"]}
重启docker
systemctl restart docker
登陆harbor
docker login -uadmin –p*** domain 成功
-
方法二:
首先按照官方文档生成证书(证书名称无所谓)。
使用 IP 访问的情况下,所有域名都可以使用该 IP。
将证书放到指定的位置。
按照文档配置完成后, Docker 客户端还需要配置私有证书认证。
参考这里:https://stackoverflow.com/questions/50768317/docker-pull-certificate-signed-by-unknown-authority
将 Harbor 服务器端的 ca.crt 文件,放到 Docker 客户端指定的目录下面,例如:
/etc/docker/certs.d/IP或域名:5000/ca.crt
1
配置后就能往远程的 Harbor pull 和 push 了。 -
方法三:
修改docker 配置
vi /usr/lib/systemd/system/docker.service增加一行–insecure-registry harbor.sunyasec.com \
harbor.sunyasec.com为域名
2.重新加载配置
systemctl daemon-reload
-
K8S
k8s日志搜集
Hadoop
Hadoop运行模式:
| 模式 | |
|---|---|
| 本地运行模式 | 无需任何守护进程,所有的程序都运行在同一个JVM上执行。在独立模式下调试MR程序非常高效方便。所以一般该模式主要是在学习或者开发阶段调试使用 。 |
| 伪分布运行模式 | Hadoop守护进程运行在本地机器上,模拟一个小规模的集群,换句话说,可以配置一台机器的Hadoop集群,伪分布式是完全分布式的一个特例。 |
| 完全分布式运行模式 | Hadoop守护进程运行在一个集群上。 |
kafka
(56条消息) 32 道常见的 Kafka 面试题_to.to的博客-CSDN博客_kafka面试题
(56条消息) kafka常见面试题(持续更新)_听海的石头的博客-CSDN博客_kafka面试题
(56条消息) 【2021最新版】Kafka面试题总结(25道题含答案解析)_Java小叮当的博客-CSDN博客_kafka面试题
shell
写过哪些shell脚本:
mysql主从状态监控,防止DDOS攻击,MySQL数据备份,防误删文件,巡检系统,服务状态监控,系统优化
shell脚本监控MySQL主从:
思路:
首先我们先获取从库的账户密码进行登录,在查看slave的状态,利用awk进行切割出SQL和IO线程的状态,切割出来进行判断是否为yes
shell脚本监控公司网段的IP是否存活:
思路:
我们用for循环,限制范围在255之内,在用ping 然后$?调用网段范围,进行判断是否成功
Shell实现99乘法表:
#!/bin/bash
for i in `seq 9`
do
for j in `seq $i`
do
echo -n "$j*$i=$[$j*$i] "
done
echo
done
计算1到100相加:
方法一:
seq 100|awk '{i=i+$1}END {print i}'
方法二:
#!/bin/bash
sum=0
for i in `seq 100`
do
sum=$[$sum+$i]
done
echo $sum
假如系统有100个系统账号,名字一次为name1-name100,编写脚本删除这些用户:
#!/bin/bash
for i in `seq 100`
do
userdel name$i
done
liunx三剑客:
-
sed ——基于行(修改) i 直接修改原文件 s 替换 y 变换 c d:删除 s:替换(字符串被替换) g:全局模式,所有匹配的字符串都被替换(不加g默认只替换每行匹配的第一个) p与-n选项结合,实现只打印被替换行 y:变换字符(一一对应) i:插入(匹配行前) a:追加(匹配行后) c:修改(匹配行被修改) r:从文件读入 w:写入文件 q:找到第一个匹配就退出- 修改1.txt的23行study为xxx:
sed -i '23s/study/xxx/' 1.txt - 删除文件中最后一行:
sed -i '$d' 1.txt - 删除空行:
sed -i '/^$/d' 1.txt - 删除以#开头的行:
sed -i '/^#/d' 1.txt
- 修改1.txt的23行study为xxx:
-
awk ——基于列(提取文本) -F 指定域分隔符 空格 tab键 -f 指定从脚本文件中读取awk命令 $0 所有域,即整条记录 $1 第1个域 FS 设置输入域分隔符(-F) NF 浏览记录的个数(所有域) NR 已读的记录数 OFS 输出域分隔符 - 查看nginx日志50行第三列的内容:
awk 'NR==50 {print $3}' access.log - 文件中,输出内容相同次数超过3次的行:
cat 1.txt |sort|uniq -c|awk '{if($1>3){print $2}}' - 统计nginx日志每个iP出现的次数:
cat /var/log/nginx/access.log |awk '{print $1}'|sort -r|uniq -c - 文件第二列为数字,查找第二列大于100的行:
awk '$2>100' 1.txt
- 查看nginx日志50行第三列的内容:
-
grep ——过滤(匹配行) -n 显示包含匹配文本的所有行 -v 显示不包含匹配文本的所有行 -ni 查找包含"内容"大小写的行 -i 不区分大小写 -c 输出匹配行的计数 -r 递归,读取目录下所有文件进行匹配 - 获取不包含an的行:
grep -v an 1.txt - 查询文件里包含hhh的行以及行号:
grep -n 'hhh' 1.txt
- 获取不包含an的行:
-
find
- 查找名字为error.log的日志文件:
find / -type f -name "error.log" - 查找系统内文件大于60K小于100K的文件,并删除他们:
find / -type f -size +60k -size -100k -exec rm -f {} \; - 统计log目录下以test开头的100个文件,然后把这100个文件的第一行保存到aaa这个文件中:
find log -type f -name "test*" |head -100|xargs head -1 -q > aaa - 删除7天前的日志:
find /var/log/nginx/ -type f -name '*.log' -mtime +7 -exec rm -f {} \;
- 查找名字为error.log的日志文件:
-
cat:打印
-
sort:排序
-
uniq:去重 -c(统计次数)
-
正则表达式 ——元字符集(通配符) ? 任意单个字符 * 任意长度的字符 ^ 显示以“内容”开头的行(用于锚定行的开始) [ ] 匹配一个指定范围内的字符 [^ ] 匹配一个不在指定范围内的字符 $ 用于锚定行的结尾
shell参数:
传参:-eq 等于 -gt 大于 -lt 小于
- $# 命令行参数个数(传递参数的个数)
- $* “参数 1 参数 2 …”形式保存的所有参数【以一个单字符串显示所有向脚本传递的参数】
- $@ “参数 1 ”“参数 2 ”…形式保存的所有参数
- $n 第 n 个参数【表示 Shell 的第几个参数 】
- $? 前一个命令或函数的返回码【显示最后命令的执行情况 (0是成功)】
- $0 当前程序名【Shell 的命令本身】
- $$ 本程序的 PID【脚本运行的当前进程 ID 号 】
- $! 上一个命令的 PID【后台运行的最后一个进程的 ID 号 】
- $- :显示 Shell 使用的当前选项
vi和vim区别:
Vi不支持正则表达式的搜索,没有自己的脚本语言
Vim支持正则表达式的搜索,有自己的脚本语言
- 删除:dd
- 复制:yy
- 粘贴:pp
- 查找:/
- 替换文中所有的user为users:
:%s /user/users/g
云
云服务器:
| ECS 云服务器 | 以虚拟机的方式将一台物理机分成多台云服务器,提供可伸缩的计算服务。 |
| SLB 负载均衡 | 基于LVS和Tengine实现的4层和7层负载均衡,有动态扩容,session保持等特点。 |
| RDS 关系型数据库 | 通过云服务的方式让关系型数据库管理、操作和扩展变得更加简单。 |
| OSS 开放存储服务 | 对任意大小数据对象提供高可用,高可靠的海量存储服务。 |
| ESS 自动伸缩 | 自动伸缩是一种根据业务需求和策略,自动调整其弹性计算资源的管理服务 |
| 数据库MySQL | |
| 域名解析DNS | |
| SSL证书 |
云服务区别:
| 服务 | |
|---|---|
| laas | 基础设施服务:IaaS 是云服务的最底层,主要提供一些基础资源。用户需要自己控制底层,实现基础设施的使用逻辑。 |
| paas | 平台服务:PaaS 提供软件部署平台,抽象掉了硬件和操作系统细节,可以无缝地扩展。开发者只需要关注自己的业务逻辑,不需要关注底层 |
| saas | 软件服务SaaS 是软件的开发、管理、部署都交给第三方,不需要关心技术问题,可以拿来即用 |
系统
操作系统(应用场景和特点):
Linux Windows iOS 安卓 鸿蒙系统
Linux发行版:Linux是系统簇,centos 乌班图 SUSE 中标麒麟 Debian
centos和Redhat是什么关系:内核一样,Redhat是企业版,centos是开源版
centos软件安装:yum rpm 二进制
(新服务器)新安装的Linux系统在安全和性能方面做哪些配置:
- 修改用户文件打开数,也就是句柄,ulimit
- 配置网络,保证网络连接通畅
- 配置国内yum源
- 配置时间同步
- 内核优化(最大打开文件数修改 修改系统默认的TIMEOUT时间)
- 精简开机自启
- 关闭不必要服务和端口
- 设置合适防火墙和selinux策略
- 拒绝ping
- ssh加速
- 禁止root远程登录,su
linux最大文件数用ulimit:
ulimit 限制 shell 启动进程所占用的资源(临时)
- ulimit -f 数字 //设置文件的大小,默认是无限大【unlimited】
- 用ulimit -n命令,默认是1024 //最大文件数大小
vim /etc/security/limits.conf(永久)
末行追加
- soft nofile 65565
- hard nofile 65565
ulimit用来限制每个用户可使用的资源,如CPU、内存、句柄等。
一、用法:ulimit [-SHacdefilmnpqrstuvx] [限制]
参数详解:
S:表示软限制,超出设定的值会告警。
H :表示硬限制,超出设定的值会报错。
a :列出系统所有资源限制的值
c:当某些程序发生错误时,系统可能会将该程序在内存中的信息写成文件(除错用),这种文 件就被称为核心文件(core file)。此为限制每个核心文件的最大容量
d:每个进程数据段的最大值
f:当前shell可创建的最大文件容量
l:可以锁定的物理内存的最大值
m:可以使用的常驻内存的最大值
n:每个进程可以同时打开的最大文件句柄数
p:管道的最大值
s:堆栈的最大值
t:每个进程可以使用CPU的最大时间
u:每个用户运行的最大进程并发数
v:当前shell可使用的最大虚拟内存
二、临时修改ulimit
ulimit [-SHacdefilmnpqrstuvx] [限制]
在命令[限制]处,设置值,即可调整限制值,只对当前shell有效
S表示软限制;H表示硬限制;如果不指明,则表示软硬皆设置;
[root@localhost solr-7.7.3]# ulimit -u
4096
[root@localhost solr-7.7.3]# ulimit -u 65535
[root@localhost solr-7.7.3]# ulimit -u
65535
三、永久生效ulimit
修改limits.conf文件,内容如下
[root@localhost solr-7.7.3]# vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
* soft nproc 65536
* hard nproc 65536
四、/etc/security/limits.conf配置详解
格式:
-
domain 是指生效实体
用户名
也可以通过@group指定用户组
使用*表示默认值
type指限制类型
soft软限制
hard硬限制
item限制资源
core同ulimit -c
data同ulimit -d
fsize同ulimit -f
memloc同ulimit -l
nofile同ulimit -n
stack同ulimit -s
cpu 同ulimit -t
nproc同ulimit -u
maxlogins指定用户可以同时登陆的数量
maxsyslogins系统可以同时登陆的用户数
priority用户进程运行的优先级
locks用户可以锁定的文件最大值
sigpengding同ulimit -i
msgqueue同ulimit -q
nofile和nproc
- nofile表示单个进程可以打开的最大文件句柄数(默认值,软限制:1024,硬限制:4096)
- nproc表示单个用户创建的进程数(默认值,软限制:threads-max/2,硬限制:threads-max/2),线程的实现其实是一个轻量级的进程,所以线程也算进程
Linux启动流程:
-
通电
-
bios初始化
-
grub2磁盘引导阶段(MBR)
-
指定boot分区所在分区
-
grub2文件引导阶段
计算机开机后BIOS加电自检,一切正常后,找到第一个启动设备(一般就是硬盘),然后从这个启动设备的主引导扇区读取MBR。MBR这段引导程序识别活动分区,引导操作系统。 -
启动内核,只读挂载 / 设备
-
启动init程序进入初始化阶段(rhel6)
-
启动systemd初始化进程
-
取 /etc/systemd/ 中的文件(之后都是并行的)
-
执行/etc/rc.d/rc.local
-
启动程序
-
启动登陆环境
Linux1号进程(init进程):
1号进程,pid为1的进程,又称init进程。( Systemd 是目前最流行的 Linux init 进程 )
linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命:
1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙);
2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作;
init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态, “收尸”过程中则处于TASK_RUNNING状态。
pid为0、1的进程是杀不掉的,
系统进行初始化的时候将这两个进程的所有信号屏蔽掉了,通过kill发送给0、1的信号被忽略,不会有任何作用。而普通进程有两个信号是不能忽略的:SIGKILL SIGSTOP
系统允许一个进程创建新进程,新进程即为子进程,子进程还可以创建新的子进程,形成进程树结构模型。整个linux系统的所有进程也是一个树形结构。树根是系统自动构造的,即在内核态下执行的0号进程,它是所有进程的祖先。由0号进程创建1号进程(内核态),1号负责执行内核的部分初始化工作及进行系统配置,并创建若干个用于高速缓存和虚拟主存管理的内核线程。随后,1号进程调用execve()运行可执行程序init,并演变成用户态1号进程,即init进程。它按照配置文件/etc/initab的要求,完成系统启动工作,创建编号为1号、2号...的若干终端注册进程getty。
每个getty进程设置其进程组标识号,并监视配置到系统终端的接口线路。当检测到来自终端的连接信号时,getty进程将通过函数execve()执行注册程序login,此时用户就可输入注册名和密码进入登录过程,如果成功,由login程序再通过函数execv()执行shell,该shell进程接收getty进程的pid,取代原来的getty进程。再由shell直接或间接地产生其他进程。
上述过程可描述为:0号进程->1号内核进程->1号用户进程(init进程)->getty进程->shell进程
Linux系统中病毒怎么解决:
-
最简单有效的方法就是重装系统
-
要查的话就是找到病毒文件然后删除
top 命令找到cpu使用率最高的进程,rm -f 命令删除病毒文件,检查计划任务、开机启动项和病毒文件目录有无其他疑似文件等
-
删除病毒文件后不排除有潜伏病毒,所以最好是把备份重装一下
网络文件系统(NFS(2049) MFS):
-
TFS 淘宝
-
GFS 谷歌
-
KFS 两个印度人
-
FASTDFS 中国人
进程和线程的区别:
-
进程是资源分配的最小单位
-
线程是程序执行的最小单位
什么原因引起系统负载变高 / 服务器变慢?
命令:top uptime
原因:内存 CPU 磁盘io 僵尸进程
僵尸进程(Z进程):
defunct进程的出现时间是在子进程终止后,但是父进程尚未读取
我们用top命令查看zombie或者ps aux | grep Z会列出进程表中所有僵尸进程的详细内容
系统还有空间,但是却创建不了文件,什么原因?
iNode节点使用完了
linux inode节点:
-
简介:Inode就是索引节点,是储存文件元信息的区域
-
清理:删除无用的临时文件
为什么iNode节点会用完?
一般是因为我们配置文件,例如生成日志文件的时候配置失误,导致产生大量的小文件
Linux 软连接和硬链接区别:
- 硬链接相当于复制原文件且互通
- 软链接相当于快捷方式
Linux打包工具:
-
gzip -c FILE > FILE.gz保留源文件压缩
-
tar xf FILE
-
bzip2 -c FILE > FILE.bz2
-
xz -c FILE > FILE.xz
配置文件:
| 服务 | |
|---|---|
| 主机名 | /etc/hostname |
| 系统用户 | /etc/passwd |
| 系统启动级别 | /etc/inittab |
| 系统内核参数 | /etc/sysctl.conf(sysctl -p生效) |
| 系统openfile | /etc/security/limits.conf |
| centos6以前的系统服务 | /etc/init.d/ |
| centos7以后的系统服务 | /usr/lib/systemd/system/ |
| 文件系统挂载 | /etc/fstab |
| seliunx | /etc/selinux/config |
| yum仓库 | /etc/yum.repos.d/ |
| ssh服务器 | /etc/ssh/sshd_config |
| dns服务器 | /etc/resolv.conf |
| 网卡 | /etc/sysconfig/network-scripts/ |
| Redis数据库 | redis.conf |
| Apache | /etc/httpd/conf/httpd.conf |
| nginx | /etc/nginx/nginx.conf |
定时任务:
crontab -e 分时日月周
每周六,14 ,16 ,18 定时执行:* 14,16,18 * * 6 sh /root/a.sh
命令:
-
Iftop:实时流量监控工具
-
iostat:分析linux 磁盘i/o的工具,汇报磁盘活动统计情况
yum -y install sysstat -
chattr:改变文件属性
-
端口
-
ss -ntpl
-
netstat -ntpl:监控TCP/IP网络的工具
yum -y install net-tools
-
-
进程
- ps -aux /ps -ef :显示当前进程的状态
-
lsof:列出被各种进程打开的文件信息(打开文件的进程,进程打开的端口)
yum -y install lsof -
pstree:所有进程以树状图显示
-
df -i:查看iNode节点
-
rpm -q:查看软件包是否安装
uname -a # 查看内核/操作系统/CPU信息 head -n 1 /etc/issue # 查看操作系统版本 cat /proc/cpuinfo # 查看CPU信息 hostname # 查看计算机名 lspci -tv # 列出所有PCI设备 lsusb -tv # 列出所有USB设备 lsmod # 列出加载的内核模块 env # 查看环境变量 free -m # 查看内存使用量和交换区使用量 df -h # 查看各分区使用情况 du -sh < 目录名> # 查看指定目录的大小 grep MemTotal /proc/meminfo # 查看内存总量 grep MemFree /proc/meminfo # 查看空闲内存量 top # 实时显示进程状态 uptime # 查看系统运行时间、用户数、负载 cat /proc/loadavg # 查看系统负载 mount | column -t # 查看挂接的分区状态 fdisk -l # 查看所有分区 swapon -s # 查看所有交换分区 hdparm -i /dev/hda # 查看磁盘参数(仅适用于IDE设备) dmesg | grep IDE # 查看启动时IDE设备检测状况 ifconfig # 查看所有网络接口的属性 iptables -L # 查看防火墙设置 route -n # 查看路由表 netstat -lntp # 查看所有监听端口 netstat -antp # 查看所有已经建立的连接 netstat -s # 查看网络统计信息 ps -ef # 查看所有进程 w # 查看活动用户 id < 用户名> # 查看指定用户信息 last # 查看用户登录日志 cut -d: -f1 /etc/passwd # 查看系统所有用户 cut -d: -f1 /etc/group # 查看系统所有组 crontab -l # 查看所有用户的定时任务
| 查看cpu个数(lscpu) | cat /proc/cpuinfo | grep “physical id” | sort | uniq | wc -l |
| 查看CPU核心逻辑个数 | cat /proc/cpuinfo | grep “processor” | wc -l |
| 查看CPU核心物理个数 | cat /proc/cpuinfo | grep “cpu cores” | uniq |
| 查看Linux内核版本 | cat /proc/versio uname -a |
网络
解释 ip地址,子网掩码,网关的意义:
Ip地址:身份明确(通信时使用)
子网掩码:组织明确(通信时所属网段的明确)
网关:边塞明确(不同网段之间通信进出口)
网络流量抓取:
我们通过监控系统zabbix,而且可以画图更直观
iftop 实时流量
ifconfig 总流量
iptable(防火墙):
用iptable限制只有ip为192.168.0.55的IP访问本机22端口:
iptables -I INPUT -p tcp --dport 22 -j DROP
iptables -I INPUT -s 192.168.0.55 -p tcp --dport 22 -j ACCEPT
iptables开放DNS服务:
iptables -A INPUT -p udp --dport 53 -j ACCEPT
ebtables与iptables的区别:
ebtables 主要是控制数据链路层的,在内核中,ebtables 的 数据截获点比 iptables 更“靠前”,它获得的数据更“原始”, ebtables 多用于桥模式,比如控制 VLAN ID 等。 ebtables 就像以太网桥的 iptables。iptables 不能过滤桥接流 量,而 ebtables 可以。ebtables 不适合作为 Internet 防火 墙。
centos6和centos7中防火墙区别:
-
Centos6是iptables ,Centos7是firewall
-
iptables 用于过滤数据包,属于网络层防火墙
-
firewall 能够允许哪些服务可用,哪些端口可用,属于更高一层的防火墙
磁盘
raid:
| raid 0 | raid 1 | raid 5 | raid 10 |
|---|---|---|---|
| Raid 0 最少需要一块磁盘 | 最少需要2块磁盘,偶数盘 | 3块盘起步 | 最少4块盘 |
| 性能极佳,无冗余 | 100%冗余 | 兼顾冗余,损失1块盘,读还行,写一般 | 性能特佳,100%冗余 |
| 适用于个人及日志存储 | 读写一般 | 适用于金融、数据库存储 | 适用于对性能和冗余高要求的业务实现 |
| 适用于重要数据存放,如数据库服务器 |
磁盘空间满如何排查:
df命令查看磁盘使用情况
du查看文件大小
磁盘扩容:
-
在扩容分区之前,先查询确认一下当前操作系统类型 ,可以使用cat /etc/redhat-release进行查看
登录服务器之后,输入df 查看当前系统的分区挂载情况,如根分区/满了。只有lvm格式的能扩容,如果是普通的分区是无法扩容的 。接下来开始操作扩容,首先添加一个硬盘。通过fdisk -l查看硬盘是否添加成功。使用fdisk /dev/新盘的位置 进行分区, 依次 P 打印,n 新建,p主分区 默认分一个区, 新建好分区之后p打印,然后t修改为 8e类型。再次打印p 确认保存。
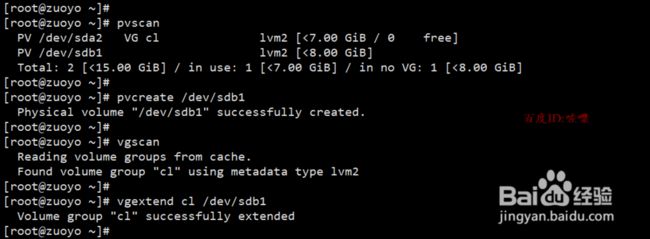
-
查询pv,然后把新硬盘加到PV 。接着查询vg,把新硬盘分区扩容到vg里面
-
扩容到vg之后,查看一下vg的容量,看看是否扩容进去了,

-
扩容到VG之后,接着扩容lv 可以使用lvextend命令。

-
扩容完成之后使用xfs_growfs,扩容才会生效。 (注意扩容期间不要关机,或重启)
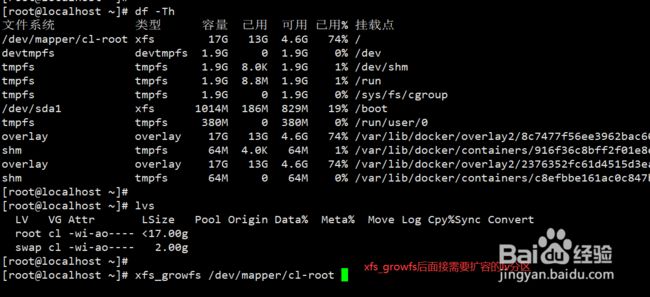
如果是centos6扩容之后,需要使用resize2fs命令
删除文件,但是硬盘空间没释放:
原因:就是某些进程还在使用该文件
分析:
- du -sh /*:查看根目录文件大小,看有无大文件
- df -h:查看磁盘使用情况
- 推测可能为文件被进程锁定或者有进程在一直写文件中的数据
解决:使用lsof | grep delete查看文件删除列表,查找哪个服务被锁定,执行kill -9 删除进程
清空日志echo " " > xx.log,df -h再次查看磁盘空间
Linux交换分区swap和物理内存的区别:
-
物理内存:从物理内存条获取的内存空间
-
交换分区:内存不足时将磁盘中的一部分空间释放出来,供当前运行的程序使用
磁盘分区:
磁盘容量超过2T:parted分区
架构
架构图:
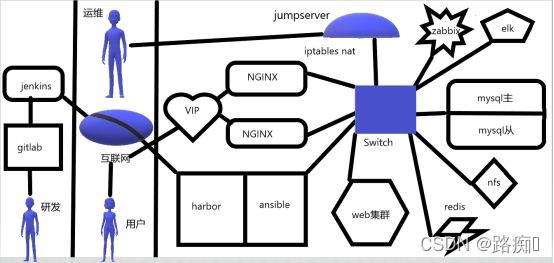
假设目前的服务器规模是200台,说说你的管理思路,例如存储,监控,日志收集等:
-
跳板机统一登录审计
-
Ansible批量部署统一调度
-
cmdb信息管理界面,便于查阅
-
存储日志方面:
Es 4台
Logstash 小200台
Kibana 2 台
zabbix部署了将近一百多台服务器(其中70多台tomcat,4台mysql数据库,6台redis缓存服务器,8台nginx,lvs2台,),监控项首先是通过ansible来批量部署修改配置文件,以及配置一些自定义监控项,在zabbix-server端配置自动发现功能,添加一些自动发现之后的操作,之后在通过模板进行监控。
排查
平台访问卡顿,可能的故障原因:
-
用户自己的个人问题,自身网络卡顿导致 / 自己访问一下
-
我们平台的外网故障,互联网到我们的某段网络故障 / 内网访问一下试试看看卡不卡
带宽不足或者网络故障 / 1是用监控查询试试的网速
网络故障导致网络卡顿的 / 1 广播风暴 ---- 广播地址 回环(环路) IP冲突 -
防火墙故障? 防火墙可能卡顿 / 防攻击的 / 1 被攻击了 DDos攻击 2 真实用户暴涨,导致卡顿
-
交换机故障 / 1 接口故障松动(网线) 2 网速不够(网线的限制) 3 环路 4 IP 地址 或者mac地址冲突 5 广播地址配置冲突, 导致广播风暴
-
负载均衡设备 LVS/NGINX / 1 LVS+KEEPALIVED VRRP ID冲突 51 会导致卡顿 2 看用户量 3 脑裂 4 端口数不够 负载高了 load average
web服务器 TOM/PHP / 1 内存 tomcat内存泄漏 2 并发数不够 3 Cpu 暴涨(开发同学,写了错误的代码导致死循环之类的可能写出BUG了) 4 向下请求数据缓慢 5 图片存在存储服务器里 访问存储服务器慢,图片加载缓慢 -
图片存储服务器 可能会慢? / 请求用户过多 磁盘IO性能跟不上
-
后台服务器缓慢(例如说京东里的调用银行接口导致卡顿)
-
数据库缓慢 缓存缓慢 / 缓存服务器请求的人数过多 缓存平台可以多个平台调用一套缓存 缓存满了 指的是缓存的槽满了 redis卡顿 现象: CPU飙高
-
数据库缓慢(mysql oracle缓慢) / 1 访问用户过多 2 redis故障导致请求全部落在数据库上 3 多表联查关联查询指令过多, 消耗数据库性能,如慢查询过多 4 表过大数据库过大(一般不是突发状况) 5 使用半同步/全同步方案, 影响数据写入速度
-
服务器内存不足 内存抢占导致运行内存不足
局域网 网络问题
遭受攻击 黑客的攻击
系统出现问题怎么排查的:
cpu,硬件,top,分析日志,僵尸进程
一些原理
CDN意义:
CDN是将源站内容分发至最接近用户的节点,使用户可就近取得所需内容,提高用户访问的响应速度和成功率。适用于站点加速、点播、直播等场景
DNS 配置别名
CDN厂家:网宿 阿里云
CDN流程:
CDN 服务器在北京 新疆用户访问抖音
拉:
1.第一个访问用户,会从北京(源服务器)直接访问,先缓存一份到本地CDN节点。
2.后边用户都会从本地CDN节点访问这个视频
推:
发完视频,直接推视频到全国各地CDN各个节点
image.163.com/1.jpg
image.163.com cname lupic.cdn.bcebos.com
lupic.cdn.bcebos.com/1.jpg
国内:蓝汛 网宿 七牛
机房(服务器)->互联网
dns(1.别名解析 2.客户来源判断)
DNS原理:
访问www.baidu.com,先访问本地缓存,有则返回,无则继续
向根域名解析服务器,接下来依次向一级/二级/三级域名解析服务器
找到资源存储到本地缓存并返回给客户
当应用想要查询www的信息时,它就需要与本地的域名服务器进行联系,此时本地的域名服务器向根域的命名服务器发送一个请求,查询www.baidu.com的地址;根命名服务器发现不属于自己的管辖区,而是属于com下的一个域,它就会通告去联系一个com区的命名服务器以获得更多的信息,并发送一个所有com名字服务器的地址列表;本地的命名服务器会继续向这些服务器发送解析请求,而其中负责com域的服务器判别是属于自己的区域,则将重复上述过程,直到找到解析www这台机器的域名服务并获得以www.baidu.com命名计算机的IP地址
虚拟化:
docker容器化部署 k8s可移植容器 openstack云计算管理
kvm 物理机虚拟化资源池 ESXI企业级虚拟机 vmware
在应用方面docker (经得起折腾,部署速度快)
在系统方面kvm( 宿主隔离,也支持快照)
KVM简介
是系统虚拟化模块,使用liunx自身的调度器管理,用kvm把多台物理机虚拟化后,组成一个大的虚拟化资源池,方便用户从资源池中按分配计算能力,提升资源的使用效率,保证多用户资源之间的隔离性,安全性
jumpserver:
产生:
防止身份的滥用和冒用
4A:
身份验证:提供集中的运维入口,基于多样的认证方式确保用户身份的可信
授权控制:为不同权限的角色创建各自的账号,禁止越权操作
账号管理:统—账户管理策略,能够实现对所有服务器﹑网络设备﹑安全设备等账号进行 集中管理,完成对账号整个生命周期的监控
安全审计:全面记录运维过程中的操作,通过审计记录、录像回放完整还原运维过程
概括:
用途就是出事了,找到责任人,是谁干的
堡垒机 = 跳板机 + 监控
叙述:
堡垒机给每个运维人员分配了一个账户,确保身份的唯一,利用它的单点登录能力,使运维人员无需知道主机的账号密码,从而可以有效防止账号泄漏和共享,并且运维人员需要访问什么主机,需要管理者事先授权
介绍:
:虚拟专用网络 外网访问内网的 的一种技术
场景应用:在家办公或者出差时使用
OpenVPN 是一个基于 OpenSSL 库的应用层 VPN 实现,官方的端口是1194
和传统 VPN 相比,它的优点是简单易用
微服务:
微服务架构就是将一个庞大的业务系统按照业务模块拆分成若干个独立的子系统,每个子系统都是一个独立的应用
spring cloud:
Spring cloud 是对于微服务架构的实现,底层基于http协议
惊群现象:
多个进程和线程同时阻塞等待一个事件,事件发生唤醒所有线程,但最终只能有一个线程对该事件进行处理,其他线程在失败后重新休眠,这种性能浪费就是惊群
Linux2.6版本以后,内核已经解决了accept()函数的“惊群”问题
处理方式就是,当内核接收到一个客户连接后,只会唤醒等待队列上的第一个进程或线程
跨域:
解决浏览器的同源策略来实现跨域访问资源
DDoS攻击:
在短时间内发起大量请求,耗尽服务器的资源,无法响应正常的访问,造成网站实质下线
措施(防范):
- 流量清洗(针对DDoS攻击的监控、告警和防护的一种网络安全服务)
- 备份网站
- HTTP 请求的拦截
- 带宽扩容
- CDN加速
- ddos deflate
中间件:
将具体业务和底层逻辑解耦的组件
JDK:
Java的开发工具包
协议:
| 协议 | 中文 | 几层 | 作用 |
|---|---|---|---|
| ICMP | 网际控制报文协议 | 网络层 | ICMP协议是一种面向无连接的协议,用于传输出错报告控制信息。主要用于在主机与路由器之间传递控制信息,包括报告错误、交换受限控制和状态信息等。Ping命令、Tracert命令 |
| VRRP | 虚拟路由冗余协议 | 网络层 | |
| TCP/UDP | 传输控制协议 | 传输层 | 区别: tcp是面向连接和可靠 udp是无连接 |
| FTP | 文件传输协议 | 应用层 |
TCP/IP的七层模型:
-
应用层:为用户提供服务
-
表示层:数据的表示、安全、压缩。
-
会话层:会话的建立、管理、终止
-
传输层:定义传输数据的协议端口号,以及流量控制和差错校验。
-
网络层:进行逻辑地址寻址,实现不同网络之间的路径选择。
-
数据链路层:控制网络层与物理层之间通信
-
物理层:为数据传输提供可靠的环境
TCP(三次握手,四次挥手):

- 首先客户端发送一个SYN的包用于发起连接,此时的seq序列号由自己指定
- 服务端收到后从原来的监听(LISTEN)状态转换为SYN_RCVD状态
- 服务端向客户端发送一个SYN , ACK标注的包,此时ACK为客户端发来的seq序号加1,seq则自己指定
- 客户端收到包后转为ESTABLISHED状态,并且向服务端发送一个包来确认,此时ACK确认序号为服务器发来的seq的值加1
- 最后服务器收到确认包之后将自己的状态转变为ESTABLISHED

- 建立好连接之后,客户端先发送FIN数据包,并将TCP状态变为FIN_WAIT_1。
- 服务端收到FIN包,将自己的状态转换为CLOSE_WAIT,并发送ACK确认包
- 客户端接收到ACK包之后,将自己的状态变为FIN_WAIT_2,等待服务端发送FIN和ACK
- 服务端发送之后将自己的状态置为LAST_ACK
- 客户端收到包后将自己的状态转换为TIME_WAIT,等待2MSL(报文段的最大生存时间)
- 服务端收到ACK后将状态置为CLOSED,四次挥手结束
FTP:
参照物:ftp server端
主动模式(20):有利于ftp服务器的管理
- ftp服务器的数据端口20主动连接客户端的数据端口,来建立数据连接,用来传输数据,这个数据连接的建立有可能被客户端防火墙拦截掉。
被动模式(21):有利于客户端服务器的管理
- 客户端的数据端口去连接ftp服务器的数据端口,建立数据连接。
7. *Rsync+inotify和Rsync+crontab区别*
Rsync+inotify是实时备份
Rsync+crontab是定时备份