【论文阅读】DANet(CVPR2019)
论文题目:Dual Attention Network for Scene Segmentation
论文地址:https://arxiv.org/pdf/1809.02983.pdf
代码地址:https://github.com/junfu1115/DANet
自注意力讲解:https://blog.csdn.net/qq_37935516/article/details/104123018
文章贡献:
1. 提出了具有自注意力机制的双注意网络DANet,以增强场景分割中特征表示的判别能力。
2. 提出了位置注意模块PAM和通道注意模块CAM,在局部特征上建模丰富的上下文相关性,显著地改善了分割结果;
3. 在Cityscapes、PASCAL Context和COCO Stuff数据上取得了先进的效果。
1 背景与动机
场景分割是具有挑战性的,可用于多种任务,如自动驾驶、图像编辑等。为了提高其像素级的准确率,需提高特征表示的判别能力。
常用的方法有:1.利用多尺度上下文融合;2.利用RNN来获取长期依赖。
上述方法存在问题,前者不能在全局视图中充分利用事物之间的关系,后者的效果依赖于长期记忆学习结果。
为了解决以上问题,作者提出DANet,它在扩张的FCN中附加了位置注意模块PAM和通道注意模块CAM,可以在全局上获取任意2个位置的关系,无论它们相隔多远。有以下3个优点:
- 避免光影等的影响;
- 解决相同物体的多尺度问题;
- 考虑了空间和通道的依赖关系。

如上图中,马路上的阴影可能对分割结果造成影响,不同距离的车大小不同。
2 相关工作
语义分割
1. 上下文关系聚合:Deeplabv2&v3利用空间池化金字塔和并行空洞卷积;PSPNet采用空间金字塔池化获得多尺度上下文;编码-解码结构等。
2. 学习局部特征的上下文依赖:DAG-RNN、PSANet、OCNet、EncNet等。
自注意模块
注意模块可以模拟长期依赖关系。之前主要应用在机器翻译、图像生成器等方面。
与以往的工作不同,作者在场景分割任务中扩展了自我注意机制,并精心设计了两种类型的注意模块来捕捉丰富的上下文关系,以更好地实现类内紧凑的特征表示。
3 网络模型
下图是DANet的整体网络结构图:

首先将输入图片经过一个骨干网络resent,其中去掉了resnet最后2层的下采样,得到大小为原图1/8的特征图。
将该特征图分别经过位置注意模块(绿色)和通道注意模块(蓝色),获得集合了自注意力后的特征图,并进行融合操作,得到最终结果。
PAM&CAM

图A是位置注意模块的细节图。
A为经过骨干网络后提取的特征图,大小为CxHxW。首先将A经过一个卷积操作获得新特征图B、C(B=C,大小为CxHxW),然后将BC都reshape为CxN的大小,其中N=HxW。将B进行转置后与C相乘,获得的结果再经过softmax操作,得到大小为NxN的特征图S。S中每行的和为1,Sij可理解为j位置像素对i位置像素的权重,即所有像素j对某固定像素i的权重和为1。
同时,将A经过另一个卷积操作得到特征图D(大小为CxHxW),同样的reshape为CxN的大小。将其与S的转置相乘,得到CxN大小的结果图,再reshape回CxHxW大小,乘以一个系数α。最后将其与A相加,获得最终的融合了位置信息的特征图结果E。其中α是一个需学习的权重参数,初始值为0。
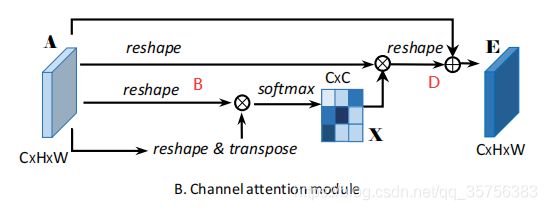
图B是通道注意模块的细节图。
与PAM模块类似,只是对特征图A没有进行卷积操作,而是直接对A进行操作。同样的,将A reshape为CxN的大小,记为B,然后将B与自己的转置相乘,再经过softmax操作,得到大小为CxC的特征图X。将X的转置与B相乘,再reshape回CxHxW的大小,乘以一个系数β,记为D。将A与D相加,则得到最后融合了通道信息的特征图E。β初始值也为0。
Sum fusion操作
具体来说,论文将两个注意模块的输出E1和E2通过卷积层进行转换,然后执行元素和来实现特征融合。最后通过卷积层得到最终的预测图。
4 实验结果
在多个数据集上均取得了先进的效果。
1. Cityscapes数据集
PAM和CAM的消融实验
使用了随机裁剪和随机左右翻转,对使用PAM和CAM模块与否的对比结果:



边界和细节更清晰,同时语义一致性得到了有效的提高。
改善性能的消融实验
- DA:数据增强(随机缩放);
- Multi-Grid:在最后一个ResNet块中应用了不同大小(4,8,16)的网格层次结构;
- MS:将分割概率图从8个图像尺度{0.5 0.75 1 1.25 1.5 1.75 2 2.2}中取平均值进行推理。

注意模块的可视化

第2和第3列是对应点12位置注意力的结果图,第4和第5列是通道11(车)和通道4(植物)的通道注意力结果图。
与其他方法的比较

其中,PSANet与DANet使用了相同的骨干网络resnet101,DenseASPP使用了更强大的预训练模型。
2. PASCAL VOC 2012数据集
对比骨干网络选用resnet50/101的结果:

对模型进行微调后的结果:

微调后由80.4上升到了82.6,但是比EncNet要低。
3. PASCAL Context数据集

4. COCO Stuff数据集
