精读《X3D: Expanding Architectures for Efficient Video Recognition》论文
文章目录
- 1 背景说明
- 2 之前方法存在的问题
- 3 文章要解决的核心问题
- 4 文章的贡献
- 5 结论
- 6 X3D Networks
-
- 6.1 Basis instantiation
- 6.2 Expansion operations
- 6.3 Progressive Network Expansion
- 7 实验
-
- 7.1 Expanded networks
- 7.2 对比实验

论文名:X3D: Expanding Architectures for Efficient Video Recognition
论文链接:https://arxiv.org/abs/2004.04730
代码链接:https://github.com/facebookresearch/SlowFast
1 背景说明
和上一篇TSM论文的背景其实都是差不多的,略过。
点击:上一篇TSM论文精读超链接
2 之前方法存在的问题
在之前的图像分类网络的发展中,之前的工作会去探索网络深度、输入分辨率、和通道宽度等方面来进行网络结构的设计。然后,在视频分类网络的发展历程上,之前的工作通常是基于图像模型直接进行时间维度的扩展,而不对视频分类网络本身进行探索。
3 文章要解决的核心问题
如何把一个很小的2D图像分类架构扩展成3D的架构,实现精度和复杂度的平衡。
4 文章的贡献
- 文章考虑了多个轴,并在多个轴上定义了扩展操作,这些扩展操作能够提升X2D的性能;
- 文章提出了一套逐步地网络扩展方法,并在这逃扩展方法上使用扩展操作,得到了多个版本的X3D;
- 文章探索出来的X3D在多个数据集上达到了SOTA,并且能够很好地实现精度和复杂度的平衡。
5 结论
这篇文章提出了一种由很小的2DCNN网络逐步扩展而来的能够提出时空信息的网络(X3D)。在计算/精度权衡下,X3D在空间、时间、宽度和深度多个候选轴进行扩展。他们在逐步扩展的过程中发现,具有少的通道维度和高时空分辨率的网络可以有效地用于视频识别。
6 X3D Networks

其中, γ t \gamma_t γt代表持续时间的轴(可以理解为被采样到的帧数)、 γ τ \gamma_{\tau} γτ代表帧率的轴(时间采样频率)、 γ s \gamma_{s} γs代表空间分辨率、 γ w \gamma_{w} γw代表特征宽度(外部)、 γ b \gamma_{b} γb代表内部的(”bottleneck”)宽度和 γ d \gamma_{d} γd代表深度。
这篇论文感兴趣的是不同轴之间的权衡:
- 3DCNN的最佳时间采样策略是什么?较长的输入时间且较稀疏的采样是否优于较短时间的快速采样?
- 什么样的空间分辨率是最好的?是否存在性能饱和的最大空间分辨率?
- 是拥有高帧率但更窄的通道的网络更好(时间维度长、特征通道少),还是使用更宽的通道的模型缓慢处理视频更好?
- 当增加网络宽度时,是全局扩展网络宽度更好,还是扩展内部的(”bottleneck”)宽度更好?
- 为了保持接受野的大小足够大且生长速率大致恒定,是否应该通过扩展输入分辨率来进行深入,还是更好地扩展到不同的轴?这对空间和时间维度都成立吗?
- 是否需要为了保持卷积核的感受野而加深网络,且是否在时间和空间上都使用?
6.1 Basis instantiation

其中,卷积核的维度表示为{ T × S 2 , C T \times S^2 ,C T×S2,C}。X3D通过6个轴 { γ t , γ τ , γ s , γ w , γ b , γ d \gamma_t,\gamma_{\tau},\gamma_{s},\gamma_{w},\gamma_{b},\gamma_{d} γt,γτ,γs,γw,γb,γd}来对X2D进行拓展,X2D在这6个轴上都为1。
Network resolution and channel capacity
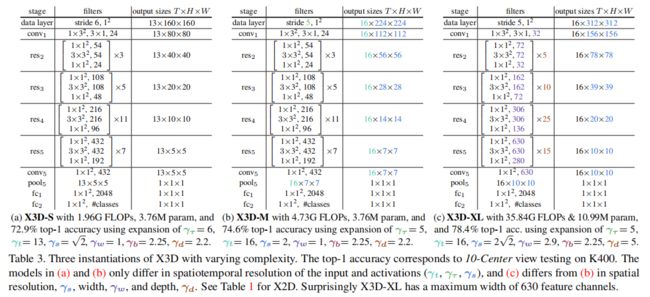
对照着表1,该模型在data layer以帧率 1 γ τ \frac{1}{\gamma_{\tau}} γτ1对原始视频采样。并以 T × S 2 = 1 × 11 2 2 T \times S^2=1 \times 112^2 T×S2=1×1122作为基本输入(X2D的输入)。在 r e s 2 res_2 res2到 r e s 5 res_5 res5的过程,空间分辨率变为之前的 1 2 \frac{1}{2} 21时,特征通道变成了之前的2倍。
该模型保留了所有特征的时间分辨率,没有时间下行采样(既没有时间池化也没有时间跨步卷积),直到分类前的全局池化层。因此,tensor保留了完整的时间帧。
Network stages
X2D是由 stage-level 和 bottleneck 设计组成的,通过将 bottleneck 块中的每个空间3×3卷积扩展到3×3×3(即 3 × 3 2 3 \times 3^2 3×32)的时空卷积。此外,conv1 stage中的3×1时间卷积是通道级的,不涉及空间。
Discussion
X2D可以被解释为Slow pathway,因为它只使用一个帧作为输入。因此相比典型的3DCNN,它也更加地轻量。
6.2 Expansion operations
他们定义了一组基本的扩展操作,通过在时间、空间、宽度和深度维度上执行以下操作,来将X2D从一个微小的空间网络依次扩展到X3D。
-
X-Fast 在保持剪辑持续时间不变时(即视频长度不变),通过增加帧速率, 1 γ τ \frac{1}{\gamma_{\tau}} γτ1,扩大时间激活大小 γ t \gamma_t γt。(简单理解应该是,视频长度不变,增加采样频率,使得网络的输入帧变多,这样子也让视频更连续)
-
X-Temporal 通过同时增加视频长度和帧速率 1 γ τ \frac{1}{\gamma_{\tau}} γτ1,来扩大持续时间和时间分辨率。
-
X-Spatial 通过增加输入视频的空间采样分辨率来扩展空间分辨率 γ s \gamma_s γs。
-
X-Depth 通过以 γ d \gamma_d γd的倍数来增加每个residual stage的层数来增加网络的深度。
-
X-Width 层通过全局宽度扩展因子 γ w \gamma_w γw均匀扩展所有层通道数。
-
X-Bottleneck在每个 residual 块中扩展卷积核的内通道宽度 γ b \gamma_b γb。
6.3 Progressive Network Expansion
他们采用一种简单的递进算法进行网络扩展,类似于特征选择的正向和反向算法。最初我们从X2D开始,用基数为a的一组单位扩展因子X0实例化基模型。我们使用a = 6个因子,X={ γ t , γ τ , γ s , γ w , γ b , γ d \gamma_t,\gamma_{\tau},\gamma_{s},\gamma_{w},\gamma_{b},\gamma_{d} γt,γτ,γs,γw,γb,γd}。
Forward expansion
衡量当前扩展因子X对应网络的扩展标准函数表示为J(X)。该指标得分越高,扩展因子越好,得分越低,扩展因子越差。在他们的实验中,这对应于扩展X的模型的准确性。此外,C(X)是衡量当前扩展因子X对应成本的复杂度标准函数。在我们的实验中,
函数C被设置为由X扩展的网络实例化所对应的浮点操作计算量(FLOPs)。然后,网络扩展尝试寻找最佳的扩展因子X, X = a r g m a x Z , C ( Z ) = c = J ( Z ) X = argmax_{Z,C(Z)=c}= J(Z) X=argmaxZ,C(Z)=c=J(Z),其中Z为可能要探索的扩展因子(类似于搜索空间),C为目标复杂度。然后,每次只改变其中一个因子,其余因子保持不变。而每一次改变,有6种可能(每一次改变的可能性和因子数量一样),然后选择最优X的(正确率最高的)那个作为下一次改变的出发点。详细地说,在初始阶段,模型为X2D,对应着一个计算复杂度,然后给定一个目标复杂度,模型要通过每次改变一个因子,然后一步步变换到目标复杂度。且每一次改变所对应的改变量也是定义好的,即让当前的模型的复杂度变成两倍。定义的操作如下:
- X-Fast γ t = 2 γ t \gamma_{t}=2\gamma_{t} γt=2γt,实现方法: γ τ = 0.5 γ τ \gamma_{\tau}=0.5\gamma_{\tau} γτ=0.5γτ
- X-Temporal γ t = 2 γ t \gamma_{t}=2\gamma_{t} γt=2γt,实现方法: γ τ = 0.75 γ τ \gamma_{\tau}=0.75\gamma_{\tau} γτ=0.75γτ+视频长度变成1.5倍
- X-Spatial γ s = 2 γ s \gamma_{s}=\sqrt{2} \gamma_{s} γs=2γs
- X-Depth γ d = 2.2 γ d \gamma_{d}=2.2 \gamma_{d} γd=2.2γd
- X-Width γ w = 2 γ w \gamma_{w}=2\gamma_{w} γw=2γw
- X-Bottleneck γ b = 2.25 γ b \gamma_{b}=2.25 \gamma_{b} γb=2.25γb
Backward contraction
由于前向扩展只在离散步骤中产生模型,如果目标复杂度被前向扩展步骤超过,他们执行后向收缩步骤以满足所需的目标复杂度。此收缩被实现为上一次展开的简单缩减,以便与目标相匹配。例如,如果最后一步将帧率提高了两倍,那么他们就会向后收缩将帧率降低到一个 <2的倍数,以大致匹配所需的目标复杂度。
7 实验
训练
不使用预训练,从0开始训练。对于时间域,他们从全视频中随机采样一个片段,网络的输入是时间步幅为 γ τ \gamma_{\tau} γτ的 γ t \gamma_{t} γt帧;对于空间域,他们从视频中随机裁剪 112 γ s × 112 γ s 112\gamma_{s} \times 112\gamma_{s} 112γs×112γs大小的像素区域。
推理
采用两种推理策略:
- K-Center:时间上,从视频中采样K个片段(例如K=10),并在空间上将较短侧缩放到 128 γ s 128\gamma_{s} 128γs像素,并进行 γ t × 112 γ s × 112 γ s \gamma_{t} \times 112\gamma_{s} \times 112\gamma_{s} γt×112γs×112γs的中心裁剪。
- K-LeftCenterRight:在时间上与上面相同,但取 γ t × 112 γ s × 112 γ s \gamma_{t} \times 112\gamma_{s} \times 112\gamma_{s} γt×112γs×112γs的3个裁剪来覆盖更长的空间轴,作为全卷积测试的近似值。他们平均了所有个体预测的softmax分数。
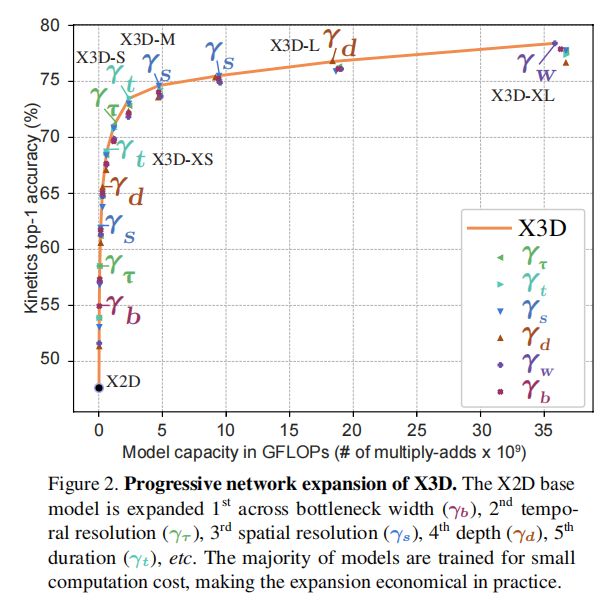
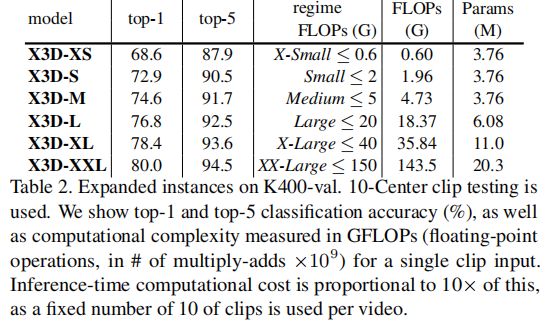
7.1 Expanded networks
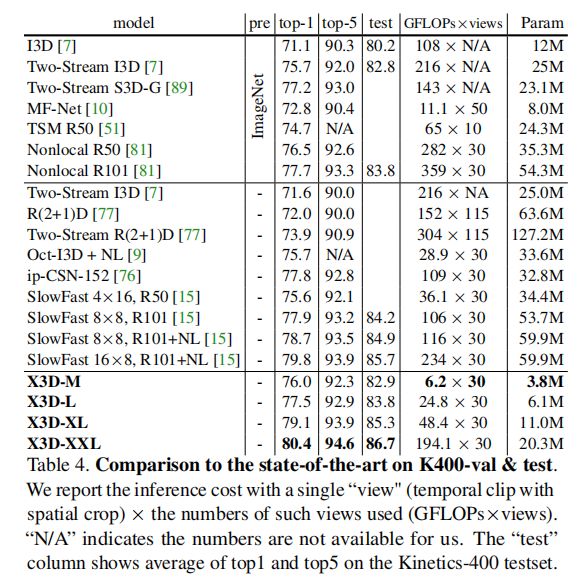
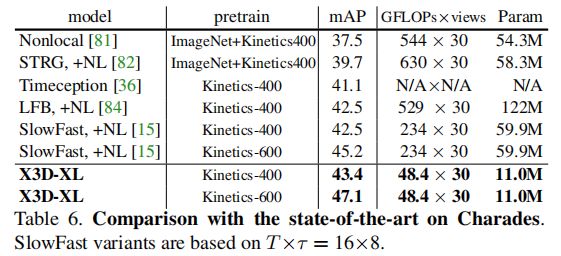
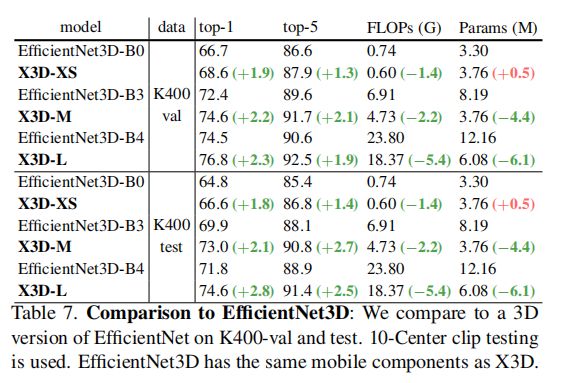
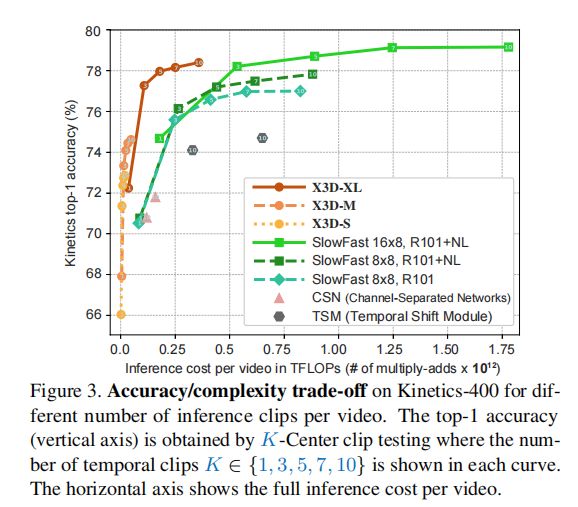
7.2 对比实验