2021年安全类比赛writeup总结
360数字安全竞赛
恶意软件家族分类
本赛题的主要目标为恶意软件家族分类,赛题数据集包含了来自10个恶意软件家族,10000多个恶意软件的PE文件(No header)和使用IDAPro生成的asm文件。赛题采用多分类对数损失函数logloss对结果进行评价
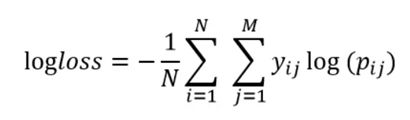
样本存在种类分布不均,大小不一的特点,如其中7,8,9类占的比例较大
**第二名解法: https://mp.weixin.qq.com/s/q0ScSZyXFK8XLgMTBU9k5g**
特征选择:提取了字节直方图、字节熵直方图、字符串信息等静态特征
节区特征:在汇编文件中,除了实现各种逻辑功能的汇编代码,另一部分便是进行文件信息和代码功能说明的注释内容,从中可以获取对应于PE文件某些头部字段的信息。首先,关注文件中节区的统计信息,包括节区(section)个数、段(segment)个数、不同异常类型的节区个数(节区名为空/大小为0)、可读/可执行/可写的节区个数以及是否存在调试段/重定位段/资源段/TLS段等;其次,关注节区的基本属性,包括节区名、节区大小和表示节区特征的字符串列表,其中对对节区的大小信息进行了细化,分别提取了节区进行对齐处理前的大小和实际在磁盘中所占的空间大小;此外,单独提取了文件入口节区(即第一个可执行节区)的节区名以及表示该节区特征的字符串列表。除了简单统计信息外,将其他特征的值与节区名进行配对,并进行散列处理,最终拼接得到节区特征向量。
导入表导出表特征:针对汇编文件注释内容中的导出地址表进行解析,提取其中记录的导出函数。然后进行散列处理,从而得到一个最终的导出表特征向量
TF-IDF特征:提取可读字符串和操作码序列,进行TF-IDF处理得到特征
函数语义特征:以一个函数为基本单位,将每个函数的语义信息抽象成一句话,为每个汇编文件样本生成一个包含操作码语义信息的语料文件,将这些文件集合起来即可建立一个语料库。之后通过word2vec生成语义特征。
模型选择:只使用了xgboost模型
第三名解法:
https://mp.weixin.qq.com/s/jMtPbz1pQ4YJ7eqMhcKtWQ
特征选择
- 通过pythonzipfile对文件进行压缩,并计算了文件的压缩率,并计算了一些比值:包括PE文件大小/ASM文件大小,PE文件压缩率/ASM文件压缩率,以及前述两项的比值。
- 筛选出PE文件中长度小于20的单词,然后使用tfidf方法分别统计了n-gram=1时的前1000个词与n-gram=4时的前1000个词组作为PE文件的内容特征
- ASM每一行的开头都包括.text,.rdata,.data等标识,表示是代码段还是数据段,以及数据段的具体功能,统计了整个文件中不同区段的行数以及总占比作为特征。
- 统计了’?’、’=’、’:’、’*’、’.’、’!'等字符的个数和总占比作为特殊字符特征
- 在ASM文件中,因同一函数可能在同一类恶意软件中重复出现,因此依照’__stdcall’关键字进行分割,提取ASM文件下所有函数名,并进行CountVectorizer,作为stdcall特征
- dll文件表示计算机上的库文件,提供给使用者一些开箱即用的变量、函数或类,在同一类恶意软件中,很有可能复用相同的dll文件,通过识别文件中出现的’.dll’的前缀,提取文件中使用的dll文件的名字,并进行CountVectorizer,作为dll特征
- 在ASM文件中一些关键词体现了代码的关键属性,对文件中的’dll’、‘std’、‘dword’、‘edx’、‘esi’、‘eax’、‘ebx’、‘ecx’、‘edi’、‘ebp’、‘esp’、'eip’进行计数统计,作为keywords特征
- opcode是代码操作寄存器、存储器等元器件的基本指令,如mov移动,add加等,对于同一类恶意软件而言,他们的部分操作逻辑是近似的,对opcode进行统计可以了解代码逻辑。对’aad’、‘aam’、‘adc’、‘add’、‘addpd’、‘addps’、'addsd’等76个操作指令进行提取,生成opcode序列。之后利用tfidf来统计opcode的上下文信息,分别提取ngram=1、2、3、4时的高频特征,作为opcode特征。
数据处理方法
- 使用了Semi-Supervised Learning这种半监督学习方法,补充原有训练集,实现数据增强,使用未标记的数据提高泛化性能
Semi-Supervised Learning介绍:https://zhuanlan.zhihu.com/p/37398862 - 针对类别不平衡问题,对样本数较少的0、3、4类数据通过smote方法进行过采样。相较于随机过采样通过简单复制样本的方式来增加少数样本,容易造成模型过拟合,smote对少数类样本进行分析并人工合成新样本,增加对应类别的样本数,扩充了数据集,实现数据增强。
Smote采样介绍:https://www.cnblogs.com/wqbin/p/11117616.html
模型选择:
使用的是RF+LGB的方法
第四名解法:https://mp.weixin.qq.com/s/1ZZKLz1dP4x6tYbZbJChog
特征选择: - 字节统计值是一种无需解析PE文件格式就可直接提取特征的方式,它统计二进制文件中的全部数据,每8b划分为一个单位其值在0-255之间,统计每个值的出现次数。在生成特征时,由于文件大小也作为常规文件信息中的特征,故字节统计值需要归一化处理,即计算0-255范围内统计值的总和,将每一个统计值除以总和得到归一化后的统计值。
- 字节熵直方图特征:字节熵直方图则近似于熵H和字节值X的联合p(H,X)。为二进制文件计算以字节分布建模的字节熵直方图的bin值。为了提取字节熵直方图,如文献[2]中所述,在二进制文件上滑动一个固定字节长度的窗口,步长也为固定字节长度,通过计算在该窗口中每个字节的出现次数,并计算每个窗口上的以2为底的熵,使用计算出的熵值作为下标,将窗口中每个字节的出现次数自增到特征矩阵相应下标所对应的向量上。随后滑动窗口继续计算对应字节窗口的熵值。在生成特征时,展开该特征矩阵为一维特征向量。
- 字符串特征:通过正则匹配方式来匹配ASM文件里的可打印字符串字段,因在可打印字符串中存在较多的噪声与干扰,因此在进行正则匹配时仅匹配阿拉伯数字0-9,大写字母A-Z和小写字母a-z,且字符串长度在3以上的字段。之后使用TF-IDF算法对字符串序列进行处理。
- Opcode特征:一般来讲,ASM文件的汇编指令也包含着许多重要的数据信息,可以与可执行文件中提取出的特征进行互补。可执行文件经过反汇编后一般分为3部分,包括text,data,bss段。data段和bss段一般存储程序的数据变量和数据常量,因此只对未加壳的text段或已加壳的可执行段进行分析。在这里仅对opcode进行处理,即提取操作码表示,并且过滤如dd、db等停用词。Opcode提取完成之后仍采用TF-IDF对其建模输出
模型选择:
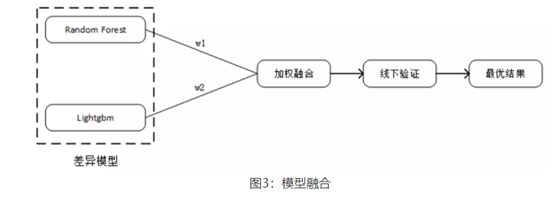
Stacking集成:两层学习器,第一层有不定数目的基学习器,输入的特征矩阵经由第一层的基学习器来抽取有效的特征。第二层的输入来自于第一层的特征输出,故第二层的输入中不应包含原始特征。Stacking集成框架的存在是为了降低单模型对训练数据过拟合的风险,故第二层分类器通常为较为简单的线性分类器,比如逻辑回归、SVM算法等。由于Stacking框架平滑的特性,故其能突显出性能最佳的基模型并降低性能较差的基模型,使之泛化能力更加稳定。在本次比赛过程中,选择用于stacking集成的基层模型为以下五个模型:cat, xgbc, gbm, rf, ext。在第二层使用的模型为逻辑回归算法
Kfold5折法进行训练:由于在数据分析部分观测到存在家族样本不均衡的情况,因此在这里使用样本加权方式,给小样本数量的家族进行加权处理,以此来缓解样本数量不均衡的问题。
此外,为了进一步提升模型的效果采用一些算法竞赛中常用的提分手段,如对数据进行k折分层抽样,训练k个具有不同来源数据的Stacking模型,最后对模型输出结果进行平均处理。通过上述特征抽取,模型集成等步骤,共采用了4组不同结构的特征,即不同参数生成的字符串特征和字节统计值&字节直方图特征进行联合,生成2组联合特征。不同参数生成的2组opcode特征,共计4组特征。而后将4组模型输出的结果进行二次平均得到最终结果
面向黑灰产治理的恶意短信变体字还原 :
本赛题提供的数据是用户举报的各种垃圾短信文本内容,其中一部分恶意短信包含变体字,另一部分则没有出现变体字。变换方式包括使用发音或字形相近的变体字或繁体字,以及在文字中插入各种干扰字符进行间隔。每一条样本都由原始短信和还原短信组成。

第四名解题方案https://mp.weixin.qq.com/s/2gA50GSDlqrIHulf469_vg
工具选择:使用了FairSeq工具库实现
数据处理:根据训练集数据,基于字符特征生成字典
模型选择:使用了ConvS2S+kfold5折验证的方法
ConvS2S介绍:https://blog.csdn.net/sinat_25394043/article/details/103988092
第二名解题方案 https://mp.weixin.qq.com/s/X3-avMnaRki2FJsxN4kdGA
特征提取:参考了ChineseBert思想的基础,用偏旁部首以及四角编码的方式,先对中文字符进行转换分解,而后再提取信息。四角编码是指把每个字分成四个角,每个角确定一个号码,再把所有的字按着四个号码组成的四位数的大小排列。其中每个角的号码按照汉字笔形分成10类并编号。
Chinese bert介绍:https://zhuanlan.zhihu.com/p/386010496

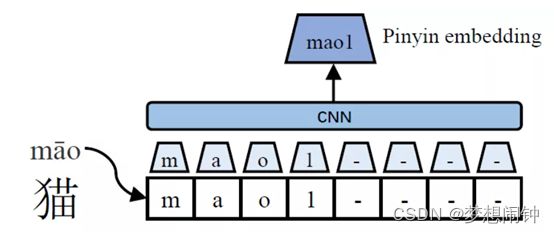

通过pypinyin获取文字的拼音然后转化成id

通过char-feature获取偏旁信息和四角编码信息
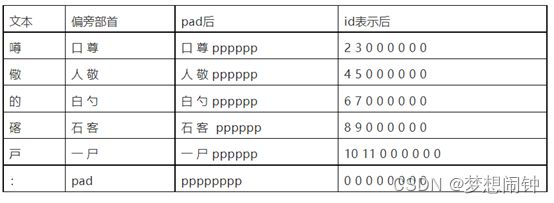
之后使用卷积神经网络进行处理
其中使用了Beam-search和incremental decoding解码方法
Beam-search介绍: https://zhuanlan.zhihu.com/p/82829880
incremental decoding解码:https://www.telesens.co/2019/04/21/understanding-incremental-decoding-in-fairseq/
违规使用手机的识别赛题
题目要求:由于工业场景特性,存在目标过小、物体区分度不明显、周围背景复杂等问题,给正确识别带来较大的挑战,目前,业界平均识别正确率维持在80%左右,存在进一步优化和提升的空间。参赛团队需要结合提供的数据训练集,识别判断图片上的人物是否存在使用手机行为,提高识别的正确率。方法不限,分类方法、目标检测方法等均可。比赛提供了约添加链接描述张图像,分为两类,分别是0_phone 带有手机的图像8202张,1_no_phone不带手机图像10060张 ,主办方还采用了PASCALVOC格式标注了0_phone的图像数据中手机位置, 0_phone的手机标注一共约8300个
三等奖解法:https://mp.weixin.qq.com/s/5fRxPgUGIk5-Hcr99G0JAA
使用了Mosaic方法进行数据增强
Mosaic方法介绍: https://blog.csdn.net/weixin_44791964/article/details/105996954
然后是使用了YOLOX和YOLOv5模型并进行结合
Yolox介绍: https://zhuanlan.zhihu.com/p/392221567
Yolov5介绍: https://www.zhihu.com/question/399884529
令一个三等奖解法:https://mp.weixin.qq.com/s/VzhAAEVqEm59uJX65zqsTQ
也是使用的yolox方法,在此基础上还使用了三种数据增强方法,采用SimOTA的分配策略划分正负样本,同时损失函数使用的是GIOU损失函数
使用了Mosaic ,MixUp,伪标签生成方法进行数据增强
Mosaic方法介绍: https://blog.csdn.net/weixin_44791964/article/details/105996954
MixUp方法介绍:https://zhuanlan.zhihu.com/p/443193386
伪标签生成方法介绍:https://blog.csdn.net/lizz2276/article/details/106865527
GIOU损失方法介绍:https://xw.qq.com/amphtml/20210527A030GI00
字节跳动安全AI挑战赛
赛道一题目:
随着互联网的快速发展,网络黑产特别是色情导流也日益增多,给用户带来了极大的伤害。色情导流用户发布色情/低俗内容吸引用户,并且通过二维码、联系方式、短网址等完成导流。本赛题旨在通过提供用户相关数据,运用机器学习等方法对色情导流用户进行识别,提高模型检测的效果。
赛题描述:
本次比赛的主要目的是以端到端的方式对色情导流用户进行识别:
输入:用户的特征,包括基础信息、投稿信息、行为信息。
输出:用户的标签(1表示色情导流用户,0表示正常用户)
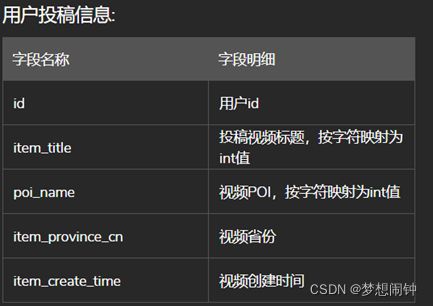
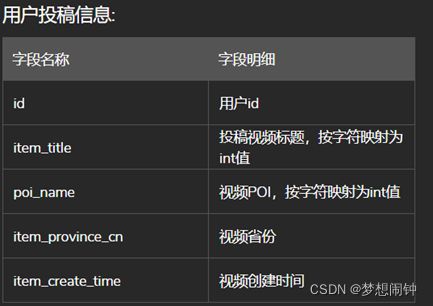
第二名解法:https://github.com/rooki3ray/2021BytedanceSecurityAICompetition_track1
特征选择:
log1p 数据平滑(log1p() 函数返回 log(1+number))
类别特征(LabelEncoder)
时间特征(min-max 归一化)
文本特征(长度、WordVec)
交叉特征
模型训练:
使用lgb模型,10折交叉验证,以及伪标签的方法
第七名解法:https://github.com/imqxms/2021_bytedance_security_ai_track1_open
其中比较特别的是该队根据https的特征进行匹配找出了https这几个字符对应的编码(给定数据集中所有字符均用数字进行了替代),并统计用户标签里不常出现的字符作为特征,使用TF-IDF算法,每个用户提取3个关键字作为特征。然后也是将几种特征进行组合获得交叉特征。
模型选择方面是选择了catboost然后进行5折交叉验证
赛道二题目:
在真实的社交网络中,存在的作弊用户会影响社交网络平台。在真实场景中,会受到多方面的约束,仅能获取到少部分的作弊样本和一部分正常用户样本,现需利用已有的少量带标签的样本,去挖掘大量未知样本中的剩余作弊样本。
给定一段时间内的样本,其中包含少量作弊样本,部分正常样本以及标签未知的样本。参赛者应该利用这段时间内已有的数据,提出自己的解决方案,以预测标签未知的样本是否为作弊样本。

第三名解法:https://x9j23ym5yl.feishu.cn/docs/doccnHHmmY7BkRIBpLZzBsNQRNh
特征选择:对数据进行分析发现黑产用户因为有在同一时间大量注册,发送大量请求行为的特点,因此在’user_register_time’,‘user_register_app’,‘user_least_login_app’,'request_time’这几个数据上和正常用户有较大差别,之后通过ip,设备和关注目标来构建图关系,
关联性强弱对比排序为 model>IP>target

在最终模型里混合使用了GBDT,社区划分算法Louvain Method和图嵌入方法node2vec
GBDT介绍:https://zhuanlan.zhihu.com/p/29765582
Louvain Method介绍:https://zhuanlan.zhihu.com/p/62715109
node2vec介绍:https://zhuanlan.zhihu.com/p/46344860
赛道二第五名解法:https://mp.weixin.qq.com/s/WDiCX_a8wLcM8j5P3jrLaw
特征提取方法是,先把用户的信息和请求的信息分开,然后将这两类信息交叉组合构建新特征。
在处理用户特征时使用图嵌入表示,在处理行为特征时使用时间段内行为序列进行表示
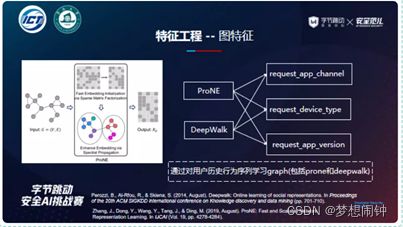

模型选择:使用了lgb,xboos,catboost三种模型的融合模型
第六名解法:https://github.com/librauee/ByteDanceAI
特征选择:
用户侧特征:
账户本身的基础特征
账户本身的特征计数统计
粉丝量、关注量、发帖量、被点赞量 除法交叉
登录时间、注册时间 减法交叉
请求侧特征:
点赞、关注基础特征
机型、ip、app_version、app_channel统计
聚合特征1,在每个请求ip下有多少不同的用户,用户请求的所有ip的用户数的均值和方差
聚合特征2, 用户请求时间的均值方差等等
w2v特征, 每个用户的请求ip序列、机型序列等等建模
模型只单独使用了lightbgm模型
2021 CCF BDCI
答辩直播:https://meeting.tencent.com/l/aSYR6C9gVF7m
方案分享:https://discussion.datafountain.cn/articles/detail/580
2021Datacon 赛题解答
域名体系安全writeip
https://datacon.qianxin.com/blog/archives/335
域名赛道的题是给出了一系列黑产网站的网址,要求选手判断这些网站是否为黑产网站,然后需要判断这些网站是涉黄涉赌涉诈类型中的哪类,还需要判断这些黑产网站所属的黑产集团
数据爬取:使用现有的轮子 dns-crawler 抓取和域名有关的信息,包括 DNS、HTTP、HTTPS 等相关信息,还使用了 Playwright + Chromium 进行了动态渲染和记录,
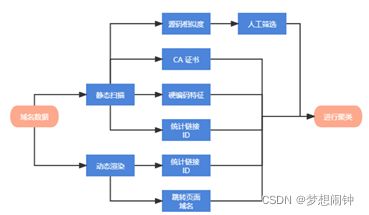
通过关联图的方式来对网站进行家族划分
1.搜集支持 HTTPS 访问的域名所使用的 CA 证书,如果有两个域名出现在同一个 CA 证书的 Alternaive Name 中,则在两个对应结点之间连边
2.通过正则匹配提取 HTML 中硬编码的 IP 地址和邮箱地址,如果有两个域名的 HTML 源码中出现了相同的元素,则在两个对应结点之间连边
3.通过正则匹配提取网站统计链接,根据链接中的 ID 来进行判断,如果有两个域名的 HTML 源码中出现了相同的统计链接 ID,则在两个对应结点之间连边
4、动态加载并渲染页面,如果有两个域名跳转后的 URL 一致,则在两个对应结点之间连边
5.动态加载并渲染页面,如果有两个域名在加载时请求了相同的统计链接,则在两个对应结点之间连边
6.属于同个黑产集团的域名 HTML 源码可能会有一些相同的特征,需要人工提取,如果有7.两个域名的 HTML 源码存在相同的人工提取特征,则在两个对应结点之间连边
如果有两个域名的 HTML 源码相似度极高,则在两个对应结点之间连边
设计了一套判断html源码相似度的算法:
首先将 HTML 源码中的非 ASCII 码字符、字母、数字和某些转义字符组合 &#; 过滤去除,然后两两计算之间的最长公共子序列长度。因为该算法的时间复杂度意味着想要在短时间内跑完整一轮是不现实的,还引入了一些优化。将数值性问题改为判定性问题,不再考虑最长公共子序列长度的数值本身,只关心有哪些域名对同时满足了「最长公共子序列占比超过 90%」「最长公共子序列和原串相差不超过 100 个字符」这两个条件,若同时满足则表明该域名对的两个域名源码相似度极高。通过预处理出过滤后的长度,并进行一轮桶排序,使得某些长度差距过大的域名对不会参与到计算中来。
邮件赛道writeup
分两部分,一部分是通过信息来判断异常用户登录,另一部分是伪造邮件
判断异常用户登录这块,还要区分是哪种类型的异常行为
邮件登录异常判断wtiteup:https://datacon.qianxin.com/blog/archives/275
首先是需要定义异常的类型
从邮箱行为:
1.同一邮箱短时间内多个不同ip登录
2.同一邮箱登录失败的日志太多或比例太高
3.某一个邮箱日志记录非常多
4.邮箱频繁更换密码
5.发送过垃圾邮件
从ip行为:
1.ip有尝试爆破的行为
2.该ip发过垃圾邮件
从时序:
1.某一天或者某一时段邮件日志明显增多
最终采用的方法并没有使用到机器学习,而是简单的基于规则的黑名单策略。
黑名单总体分为两部分,一是垃圾邮件的黑名单,二是高威胁IP的黑名单,下面针对这两部分详细展开介绍。
策略是将发过垃圾邮件的ip和邮箱全部加入一个黑名单,在auth_log.json中通过黑名单匹配筛选出一些日志,得到244w条日志
绝大多数黑名单中的邮箱/IP发过的邮件几乎全部都是垃圾邮件,但是其中有一小部分邮箱/IP只发过一两封垃圾邮件,它们的总邮件数远大于垃圾邮件数
根据使用邮箱的经验,这部分可能属于偶尔存在一两封邮件被误判为了垃圾邮件
为了剔除这部分误判,设置了一个经验阈值0.1,如果只有十分之一的邮件被判为垃圾邮件,有很大可能属于系统误判,则将该email从黑名单里剔除。
之后再对登录ip这部分进行处理,同一个邮箱多个ip登录,多次登录失败等行为都可以看做是异常行为。
发件人伪造writeup: https://datacon.qianxin.com/blog/archives/277
使用了swaks这个邮件伪造工具
Swaks介绍: https://zhuanlan.zhihu.com/p/147373196?ivk_sa=1024320u