Python算法:随机森林分类
Python算法:随机森林分类
文章目录
- Python算法:随机森林分类
-
- 一、前言
- 二、随机森林算法原理
- 三、随机森林算法函数介绍
- 四、编写Python随机森林程序并运行
- 五、最后我想说
一、前言
上次更新Python算法还是在上次,已经过去一个多月时间了,这一个多月以来也发生了很多事情,总得来说过得不是特别好,但没关系的,不能把我打败的,只会让我变的更强,你们也是,虽然失败总是贯穿人生始终,但我们仍然要勇往直前,永不言败。
好啦,说完鼓励话,我们还是要回归主题,本期博客我们将学习另一个算法——随机森林,它跟决策树有密切的关联,一起来看看吧。
二、随机森林算法原理
通过前面的实验,我们了解了决策树的基本原理,而随机森林则是由多棵决策树组合而成的一个分类器。因为如果只有一棵决策树,预测的结果可能会有比较大的偏差,而利用多棵决策树进行决策,再对所有决策树的输出结果进行统计,取票数最多的结果作为随机森林的最终输出结果。
随机森林由Leo Breiman(2001)提出,它通过自助法(bootstrap)重采样技术,从原始训练样本集N中有放回地重复随机抽取k个样本生成新的训练样本集合,然后根据自助样本集生成k个分类树组成随机森林,新数据的分类结果按分类树投票多少形成的分数而定。其实质是对决策树算法的一种改进,将多个决策树合并在一起,每棵树的建立依赖于一个独立抽取的样品,森林中的每棵树具有相同的分布,分类误差取决于每一棵树的分类能力和它们之间的相关性。特征选择采用随机的方法去分裂每一个节点,然后比较不同情况下产生的误差。能够检测到的内在估计误差、分类能力和相关性决定选择特征的数目。单棵树的分类能力可能很小,但在随机产生大量的决策树后,一个测试样品可以通过每一棵树的分类结果经统计后选择最可能的分类。
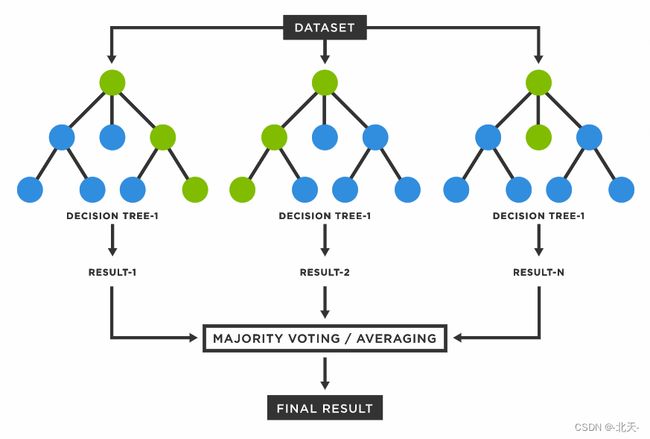
随机森林是由很多决策树构成的,不同决策树之间没有关联。
当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。
三、随机森林算法函数介绍
RandomForestClassifier函数来自sklearn.ensemble,用于创建随机森林分类器。其用法如下:
clf = RandomForestClassifier ()
因为随机森林是建立决策树原理之上的,所以其参数中有很大一部分是关于决策树,该部分参数可参考前面关于决策树分类器的实验。下面只介绍与随机森林相关的参数:
| 参数 | 说明 |
|---|---|
| n_estimators | 决策树的个数,默认为10 |
| bootstrap | 是否有放回的采样,默认为True |
| max_depth | int or None,可选(默认为"None")。表示树的最大深度 |
| n_jobs | 并行任务的个数,默认为1,表示不并行,-1表示与CPU核数相同 |
四、编写Python随机森林程序并运行
我们使用SSH工具连接到学习平台的虚拟机之后,我们直接使用如下命令创建一个python文件用于编写我们的随机森林代码:
vim randomForest.py
然后我们输入如下随机森林代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
if __name__=="__main__":
dataset = load_iris()
X = dataset.data
y = dataset.target
Xd_train, Xd_test, y_train, y_test = train_test_split(X, y, random_state=14)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf = clf.fit(Xd_train, y_train)
y_predicted = clf.predict(Xd_test)
accuracy = np.mean(y_predicted == y_test) * 100
print "y_test ",y_test
print "y_predicted",y_predicted
print "accuracy:",accuracy
然后使用命令运行如上代码:
python randomForest.py
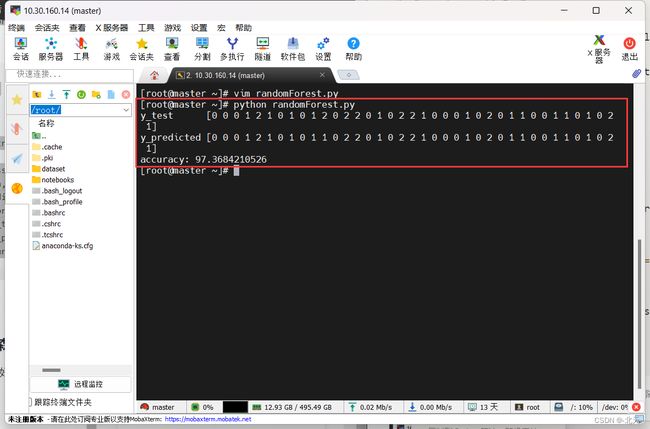
可以看见我们运行成功了。
需要说明的是,学校虚拟机上有python3和python2,但是这个是使用python2运行的,我尝试过将代码改成python3的格式,却发生缺少库,所以就使用了python2来跑程序了,如果要在python3环境跑的话需要改成如下代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
import numpy as np
if __name__=="__main__":
dataset = load_iris()
X = dataset.data
y = dataset.target
Xd_train, Xd_test, y_train, y_test = train_test_split(X, y, random_state=14)
clf = RandomForestClassifier(max_depth=2, random_state=0)
clf = clf.fit(Xd_train, y_train)
y_predicted = clf.predict(Xd_test)
accuracy = np.mean(y_predicted == y_test) * 100
print("y_test ",y_test)
print("y_predicted",y_predicted)
print("accuracy:",accuracy)
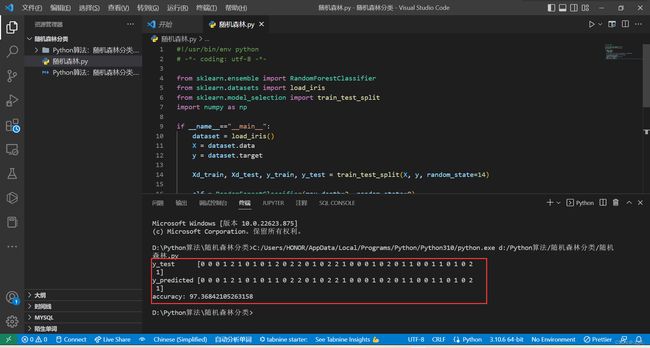
我们在本地VsCode内跑这个代码也可以成功。
五、最后我想说
随机森林是一种有监督的机器学习算法。 由于其准确性,简单性和灵活性,它已成为最常用的一种算法。 事实上,它可以用于分类和回归任务,再加上其非线性特性,使其能够高度适应各种数据和情况。
随机森林是一组决策树。但是,两者之间存在一些差异。决策树往往会创建规则,用来做出决策。随机森林将随机选择要素并进行观测,构建决策树林,然后计算平均结果。
随机森林算法有诸多优点,在这里我就不一一叙述了,感兴趣的朋友可以去网上查阅一下。
在这里我推荐一篇文章大家可以去看看:什么是随机森林?
好啦,本期的Python算法学习就到这里结束了,也不知道下一期我会什么时候更新,我还是太懒了,最后谢谢大家的阅读!