卓越产品计划丨神策分析性能优化详解:批量导入优化
![]()


![]()
追求卓越
打造极致文化与产品研发结合的最佳实践
神策已启动「卓越产品计划」
产品功能、性能、稳定性不断迈向新台阶
在为客户提供服务时,我们通常会根据导入数据量、用户资源以及用户对于延时的要求来决定数据导入方案。接下来,本文将重点围绕批量导入性能优化,从“避免数据倾斜”和“提高并行度”两个维度,详细讲述神策分析性能优化之批量导入性能优化的进化历程。
数据仓库常采用分区的方式进行数据组织。神策将数据分区分为三层:第一层为 Project_id,代表用户项目;第二层是 Day_id,代表日期;第三层为 EventBucket(默认为 10 个,可自主配置),代表数据对应事件的分桶。批量导入会涉及多个项目、多个日期的多个事件,同一个项目、同一天的同一个事件桶数据应该输出到同一个文件,在保证文件质量(文件大小以及压缩比)的基础上,导入性能优化核心要解决两个问题:第一,避免数据倾斜;第二,尽可能提高并行度。
三层分区作为 PartitionKey 导入方案
PartitionKey 导入方案跟三层分区保持一致,使用(Project_id, Day_id, EventBucket)三元组作为 MapReduce 任务的 PartitionKey,直接对 PartitionKey.hashCode()%reduceNum 进行数据 shuffle。
数据 shuffle 拥有更优的文件质量,可以保证一个分区下的数据文件数最少,但却不能避免数据倾斜问题,如果相同的(Project_id, Day_id, EventBucket)一次性导入大量数据,那么便会导致导入性能急剧下降。
slice 导入方案
为了解决(Project_id, Day_id, EventBucket)三元组作为 PartitionKey 可能引起的数据倾斜问题,我们在优化方案中引入了递增的 slice 补充到 PartitionKey 中。也就是说,如果相同的(Project_id, Day_id, EventBucket)一次性导入大量数据,则会将原来的一个 PartitionKey 变成 n 个 slice,如(Project_id, Day_id, EventBucket, slice_id=0),(Project_id, Day_id, EventBucket, slice_id=1)……该 shuffle 方案可以很好地避免数据倾斜问题。
如何切分 slice?在优化过程中,我们会按照数据量切分 slice。slice_capacity 表示一个切分slice的数据条数阈值,比如 slice_capacity=10 万,那么第一个 10 万对应的 slice_id=0,第二个 10 万对应的 slice_id=1,以此类推。
但是,按照固定数量进行 slice 切分可能会面临以下两个问题:
相同(Project_id, Day_id, EventBucket)下 slice_id=0 的数据较多,可能会导致数据倾斜
切分 slice 的 slice_capacity 阈值参数设置难度较大,阈值太大容易引起数据倾斜,阈值过小会导致数据被切分得太碎,文件质量无法保障
对此,我们做了进一步优化:第一,slice_id 依然从 0 开始,但第二个 slice_id 则从 100-10000 之间随机生成初始值,然后依次递增;第二,slice_capacity 不设置固定阈值,只设置最大/最小值,初始化为最小值,然后按照 2 的次幂递增到最大值。
举个例子,对于相同的(Project_id, Day_id, EventBucket)数据,假设slice_capacity 初始值是 5 万,最大值为 50 万,则第一个 5 万对应的 slice_id=0;第二个 10 万对应的 slice_id=rand(100-10000),若 slice_id=3000,那么第三个 40 万的 slice_id=3001,第四个 50 万的 slice_id=3002 ,以此类推。
slice_id=0 的数据量变少,可以在保证文件质量的前提下减少数据倾斜的概率。与此同时,非 slice_id=0 的数据采用随机方式可以有效打散之后的大数据量分区,进一步提升导入并行度。
数据分布预估导入方案
引入 slice 后,虽然可以一定程度上提升导入的性能,但依旧很难 100% 精准地避免数据倾斜。因此,我们进一步优化,提出了数据分布预估的导入策略。
1、后置预估
后置预估假设:用户导入的数据分布在一定时间范围内是一致的。比如,用户在 10 点导入了 100 万 key=(Project_id=2, Day_id=19902, EventBucket=3),那么用户在 11 点也会继续导入 100 万左右的 key=(Project_id=2, Day_id=19902, EventBucket=3)。
于是我们设计了后置预估方式的导入优化策略。
首次导入使用 slice 导入,假设导入后的 key 分布如下:
(Project_id=2, Day_id=19902, EventBucket=3)100 万 3 个文件 1G
(Project_id=2, Day_id=19902, EventBucket=0)10 万 1 个文件 100M
(Project_id=2, Day_id=19902, EventBucket=1)20 万 1 个文件 100M
(Project_id=2, Day_id=19903, EventBucket=1)20 万 1 个文件 100M
(Project_id=3, Day_id=19903, EventBucket=1)20 万 1 个文件 100M
……
据此,我们可以预估下一次批量导入的分布。在提交 MapReduce 之前计算好每一个 key 对应的 reduce 分布,假设一个 reduce 分配 50 万数据,那么 10 个 reduce(Project_id=2, Day_id=19902, EventBucket=3)将分布在 reduce = (0,1)上,(Project_id=2,Day_id=19902,EventBucket=0)(Project_id=2,Day_id=19902,EventBucket=1)(Project_id=2, Day_id=19903, EventBucket=1)将分布在 reduce=2 上,(Project_id=3, Day_id=19903, EventBucket=1)分布在 reduce=3 上, 其余未知 key 分配到剩下的 reduce。
我们可以看到,该导入策略不仅可以保证文件质量,还可以提高数据导入的并行度。但我们仍需要关注这两个问题:第一,每日 0 点前后,数据分布会发生质的改变,因为 Day_id 变了,因此在 0 点左右关闭导入策略可能会导致数据导入速度骤降;第二,当导入历史数据时,会造成数据分布发生根本性改变进而导致策略失效,因此一旦有较大延迟时可关闭此导入策略。
2、前置预估
前置预估是指针对本次导入的数据计算数据分布,然后精确控制每一个 key 对应的 reduce。这种策略除了会带来一定的前置计算额外开销,近乎完美。在客户环境的单个任务具体应用中,对于导入数据量大的客户,优化效果明显;对于常规数据量的客户,前置预估的带来额外开销较多,难以带来导入性能的提升。
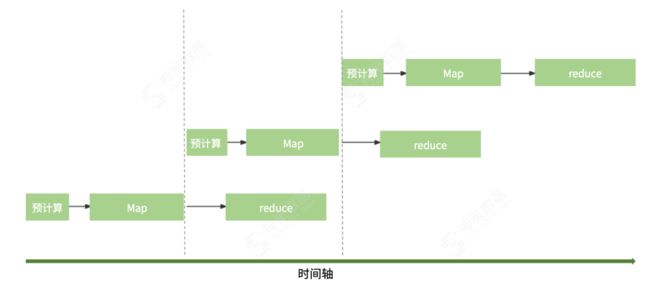
流水线提交导入方案
流水钱提交导入方案能够有效避免前置预估带来的额外开销。在此次导入的 MapReduce 运行期间,如果未导入的数据量足够多且本次的 Map 已完成,那么便会启动下一次的预计算,保证下一次的导入只需要计算资源而没有预计算的额外开销;如果预计算任务先于此次导入完成,那么在具备充足资源的前提下会直接提交下一次的导入任务,进一步提高数据导入的并行度。提交流水线如下:
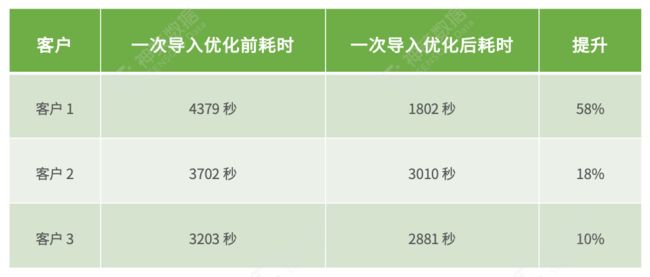
在完成以上批量导入性能优化之后,神策数据能够帮助企业客户在数据量增大的业务场景中有效降低延时,已经获得了众多客户的认可。这也为神策数据的「卓越产品计划」落地实践提供了更多价值层面支持,我们将持续推动产品功能、性能、稳定性不断迈向新台阶,打造更多打造极致文化与产品研发结合的最佳实践!
✎✎✎
【更多内容】
神策分析之五重性能优化
数据重组织查询优化
神策分析之报错优化、服务治理
▼ 点击“阅读原文”,免费体验神策分析 demo