【目标检测】ObjectDetection结构组成理解
目标检测结构理解
文章目录
- 目标检测结构理解
-
- 1.目标检测的核心组成
-
- 1.1 Backbone
- 1.2 Neck
- 1.3 Head
- 1.4 总结
- 2. 目标检测其他组成部分
-
- 2.1 Bottleneck
- 2.2 GAP
- 2.3 Embedding
- 2.4 Skip-connections
- 2.5 正则化和BN方式
- 2.6 损失函数
- 2.7 激活函数
- 3. 举例
-
- 3.1 YOLOv4目标检测网络结构
- 3.2 说明
- 4. 其他概念
-
- 4.1 Downstream Task
- 4.2 Temperature Parameters
- 4.3 Warm up
- 4.4 End-to-End
- 4.5 Domain Adaptation 和Domain Generalization
- 4.6 数据增强
- 4.7 Label Smoothing
- 后话
- 参考资料
通常来说,对于目标检测而言,我们经常听到别人讲,”更换一下这个网络的backbone试试?“、”换个检测头吧“等相关这方面的术语。本篇讲围绕目标检测结构中的几个概念进行介绍、解释和理解。
1.目标检测的核心组成
简单来说,目标检测的结构可以分成三个部分Backbone、Head、Neck。无论是哪一个目标检测网络都可以讲整个网络划分为这三个结构。
1.1 Backbone
Backbone,中文翻译为骨干网络、主干网络。既然说他是网络,Backbone充当了整个目标检测网络的一部分。Backbone在整个目标检测网络当中指的是特征提取网络,其作用是提取图片当中的特征信息。从某种意义上来说,如何设计好的Backbone,更好地从图像中提取信息,是至关重要的,特征提取不好,自然会影响到后续的定位检测。
在CV领域,使用卷积神经网络(CNN)来提取所输入的图片的特征,提取彼此之间的共同点,通过不断地卷积,缩小特征图尺寸,从而找到最核心的部分。
常用的Backbone主要有
- 提取能力强:VGG、ResNet(ResNet18,50,100)、ResNeXt、DenseNet、SqueezeNet、Darknet(Darknet19,53)、DetNet、DetNASSpineNet、EfficientNet(EfficientNet-B0/B7)、CSPResNeXt50、CSPDarknet53等。
- 轻量:MobileNet、GhostNet、VoVNet、ShuffleNet、ThunderNet等。
1.2 Neck
Neck,中文翻译为颈部、脖子。Neck是目标检测框架中承上启下的关键环节。Neck在目标检测网络主要是把Backbone提取的特征进行融合,使得网络学习到的特征更具备多样性,提高检测网络的性能。更好地融合/提取Backbone所给出的feature,然后再交由后续的Head去检测,从而提高网络的性能。
它对Backbone提取到的重要特征进行再加工及合理利用,有利于下一步Head的具体任务学习,如分类、回归、keypoint、instance mask等常见的任务。Neck放在backbone和head之间的,是为了更好的利用backbone提取的特征。 像是最著名的FPN——《Feature Pyramid NetworksforObject Detection》 提出的FPN结构,将不同尺度的特征进行融合,充分利用Backbone提取的特征信息。
常用的Neck主要有
-
Additional blocks:SPP、ASPP、RFB、SAM
-
Path-aggregation blocks:FPN、PAN、NAS-FPN、Fully-connected FPN、BiFPN、ASFF、SFAM、NAS-FPN
1.3 Head
Head,中文翻译为头部。在目标检测网络中一般叫做检测头。Head是获取网络输出内容的网络,利用之前提取的特征,Head利用这些特征,做出预测。Head可以理解为是根据Backbone提取出来的特征,从这些特征中预测目标的位置和类别。目标检测除了识别出物体的类别,更重要的是还要对物体进行定位,主要作用是定位和分类
常用的Head主要有
-
Dense Prediction (one-stage):RPN、SSD、YOLO、RetinaNet(anchor based)、CornerNet、CenterNet、MatrixNet、FCOS(anchor free)
-
Sparse Prediction (two-stage):Faster R-CNN、R-FCN、Mask RCNN (anchor based)、RepPoints(anchor free)
1.4 总结
通过对目标检测各个组成部分的介绍和描述。一个目标检测网络的组成可以由一个公式来描述
D e t e c t o r = B a c k b o n e + N e c k + H e a d Detector = Backbone + Neck + Head Detector=Backbone+Neck+Head
其中
- Backbone:提取基础特征网络
- Neck:提出一个好的结构或模块,更好适应feature
- Head:分类+定位
2. 目标检测其他组成部分
2.1 Bottleneck
bottleneck:瓶颈的意思,通常指的是网网络输入的数据维度和输出的维度不同,输出的维度比输入的小了许多,就像脖子一样,变细了。经常设置的参数 bottle_num=256,指的是网络输出的数据的维度是256 ,可是输入进来的可能是1024维度的。换成Bottleneck design以后,网络的参数减少了很多,深度也加深了,训练也就相对容易一些。
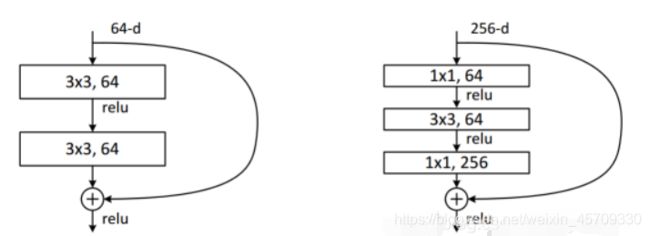
Resnet论文里的原图如上(即Bottleneck V1 ),左图是普通的残差结构,右图是瓶颈结构。具体而言,block的输入和输出channel_num是一样的(上右图中是256),而在block结构中的channel_num(上右图中是64)是小于输入/输出channel_num的,很形象。
2.2 GAP
在设计的网络中经常能够看到gap这个层,GAP——Global Average Pool 全局平均池化,就是将某个通道的特征取平均值,经常使用AdaptativeAvgpoold(1),在pytorch中,这个代表自适应性全局平均池化,说人话就是将某个通道的特征取平均值。作用是通过降低模型的参数数量来最小化过拟合效应。类似最大池化层,GAP层可以用来降低三维张量的空间维度。
self.gap = nn.AdaptiveAvgPool2d(1)
2.3 Embedding
Embedding,深度学习方法都是利用使用线性和非线性转换对复杂的数据进行自动特征抽取,并将特征表示为向量(vector),这一过程一般也称为“嵌入”(embedding)

假设:我们有一个2 x 6的矩阵,然后乘上一个6 x 3的矩阵后,变成了一个2 x 3的矩阵。先不管它什么意思,这个过程,我们把一个12个元素的矩阵变成6个元素的矩阵,直观上,大小是不是缩小了一半?
Embedding层,在某种程度上,是用来降维的,降维的原理就是矩阵乘法。在卷积网络中,可以理解为特殊全连接层操作,跟1x1卷积核异曲同工。也就是说,假如我们有一个100W X10W的矩阵,用它乘上一个10W X 20的矩阵,我们可以把它降到100W X 20,瞬间量级降了。。。10W/20=5000倍
这就是嵌入层的一个作用——降维。
2.4 Skip-connections
skip connections中文翻译叫跳跃连接,通常用于残差网络中。它的作用是:在比较深的网络中,解决在训练的过程中梯度爆炸和梯度消失问题。
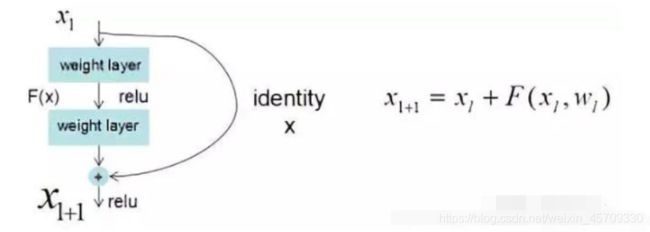
- 常用Skip-connections:Residual connections、Weighted residual connections、Multi-input weighted residual connections、Cross stage partial connections (CSP)
2.5 正则化和BN方式
-
正则化:DropOut、DropPath、Spatial DropOut、DropBlock
-
BN:Batch Normalization (BN)、Cross-GPU Batch Normalization (CGBN or SyncBN)、Filter Response Normalization (FRN)、Cross-Iteration Batch Normalization (CBN)
2.6 损失函数
- 常用损失函数:MSE、Smooth L1、Balanced L1、KL Loss、GHM loss、IoU Loss、Bounded IoU Loss、GIoU Loss、CIoU Loss、DIoU Loss
2.7 激活函数
- 常用激活函数:ReLU、LReLU、PReLU、FReLU、ReLU6、Scaled Exponential Linear Unit (SELU)、Swish、hard-Swish、Mish
3. 举例
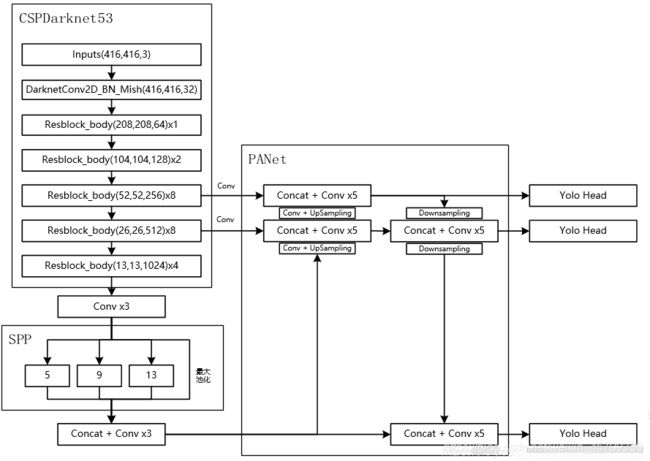
光靠文字说明还是让人对于目标检测的结构懵懂懵懂,下面使用YOLOv4目标检测网络的结构来更直观地看到目标检测的结构。
3.1 YOLOv4目标检测网络结构
3.2 说明
对于YOLOv4而言,其整个网络结构可以分为三个部分。
分别是:
1、主干特征提取网络 (Backbone) ,对应图像上的CSPdarknet53
2、加强特征提取网络 (Neck) ,对应图像上的SPP和PANet
3、预测网络 (Head) YOLOHead,利用获得到的特征进行预测
其中:
-
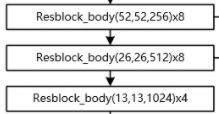
第一部分主干特征提取网络的功能是进行初步的特征提取,利用主干特征提取网络,我们可以获得三个初步的有效特征层。(这里是指大小为52×52×256、26×26×512、13×13×1024这三个特征层)
-
第二部分加强特征提取网络的功能是进行加强的特征提取,利用加强特征提取网络,我们可以对三个初步的有效特征层进行特征融合,提取出更好的特征,获得三个更有效的有效特征层。
-
第三部分预测网络的功能是利用更有效的特征层获得预测结果。
在这三部分中,第1部分和第2部分可以更容易去修改。第3部分可修改内容不大,毕竟本身也只是3x3卷积和1x1卷积的组合。
4. 其他概念
4.1 Downstream Task
用于预训练的任务被称为前置/代理任务(pretext task),用于微调的任务被称为下游任务(downstream task)
4.2 Temperature Parameters
在论文中经常能看到这个温度参数的身影,那么他都有什么用处呢?比如经常看到下面这样的式子:
p ( i ∣ x t , i ) = e x p ( K [ i ] T f ( x t , i ) / β ∑ j = 1 N t e x p ( K [ i ] T f ( x t , i ) / β ) p(i|x_{t,i})=\frac{exp(K[i]^Tf(x_{t,i})/\beta}{\sum^{N_t}_{j=1}exp(K[i]^Tf(x_{t,i})/\beta)} p(i∣xt,i)=∑j=1Ntexp(K[i]Tf(xt,i)/β)exp(K[i]Tf(xt,i)/β
里面的 β \beta β就是temperature parameter,他在运算的时候可以起到平滑softmax输出结果的作用,举例子如下:
import torch
x = torch.tensor([1.0,2.0,3.0])
y = torch.softmax(x,0)
print(y)
x1 = x / 2 # beta 为2
y = torch.softmax(x1,0)
print(y)
x2 = x/0.5 # beta 为0.5
y = torch.softmax(x2,0)
print(y)
输出结果如下:
tensor([0.0900, 0.2447, 0.6652])
tensor([0.1863, 0.3072, 0.5065])
tensor([0.0159, 0.1173, 0.8668])
当 β > 1 \beta>1 β>1的时候,可以将输出结果变得平滑,当 β < 1 \beta<1 β<1的时候,可以让输出结果变得差异更大一下,更尖锐一些。如果 β \beta β比较大,则分类的crossentropy损失会很大,可以在不同的迭代次数里,使用不同的 β \beta β数值,有点类似于学习率的效果。
4.3 Warm up
Warm up指的是用一个小的学习率先训练几个epoch,这是因为网络的参数是随机初始化的,一开始就采用较大的学习率容易数值不稳定。
4.4 End-to-End
End-to-End,在论文中经常能遇到End-to-End这样的描述,那么到底什么是端到端呢?其实就是给了一个输入,我们就给出一个输出,不管其中的过程多么复杂,但只要给了一个输入,机会对应一个输出。比如分类问题,你输入了一张图片,肯呢个网络有特征提取,全链接分类,概率计算什么的,但是跳出算法问题,单从结果来看,就是给了一张输入,输出了一个预测结果。End-To-End的方案,即输入一张图,输出最终想要的结果,算法细节和学习过程全部丢给了神经网络。
4.5 Domain Adaptation 和Domain Generalization
-
第一种Domain Adaptation域适应。常见的设置是源域 D S D_S DS完全已知,目标域 D T D_T DT有或无标签。域适应方法试着将源域知识迁移到目标域。
-
第二种Domain Generalization域泛化。这种更常见因为将模型应用到完全未知的领域,正因为没有见过,所以没有任何模型更新和微调。这种泛化问题就是一种开集问题,由于所需预测类别较多,所以比较头疼 。
4.6 数据增强
-
常用操作:random erase、CutOut、MixUp、CutMix、色彩、对比度增强、旋转、裁剪

-
解决数据不均衡:Focal loss、hard negative example mining、OHEM、S-OHEM、GHM(较大关注easy和正常hard样本,较少关注outliners)、PISA

4.7 Label Smoothing
这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
后话
2020年开始,除了这一框架之外,初露锋芒的基于transformer结构的新的目标检测范式正如荼如火、势不可挡地横扫CV各个领域。感兴趣的可以DETR工作开始了解。
参考资料
- 目标检测——Backbone与Detection Head
- 目标检测之Neck选择
- CV目标检测中的数据增强、backbone、head、neck、损失函数
- 汇总|目标检测中的数据增强、backbone、head、neck、损失函数
- 目标检测 Backbone、Neck、Detection head
- backbone、head、neck等深度学习中的术语解释
- 睿智的目标检测49——Pytorch 利用mobilenet系列(v1,v2,v3)搭建yolov4-lite目标检测平台
- 深入理解Embedding层的本质
- 神经网络bottleneck layer的特点和作用
- skip connection
- Skip-connections
- 分类问题训练的GAP-CNN在目标检测中定位能力的探究