【读点论文】MicroNet: Towards Image Recognition with Extremely Low FLOPs,在极高限制下的轻量化网络
MicroNet: Towards Image Recognition with Extremely Low FLOPs
Abstract
- 这篇论文旨在以极低的计算成本解决性能大幅下降的问题。提出了微分解卷积,将卷积矩阵分解为低秩矩阵,将稀疏连接整合到卷积中。 提出了一个新的动态激活函数-- Dynamic Shift Max,通过最大化输入特征图与其循环通道移位之间的多个动态融合来改善非线性。在这两个新操作的基础上,得到了一个名为 MicroNet 的网络系列,它在低 FLOP 机制中实现了比现有技术显着的性能提升。 例如,在 12M FLOPs 的约束下,MicroNet 在 ImageNet 分类上达到了 59.4% 的 top-1 准确率,比 MobileNetV3 高 9.6%。发表在ICCV2021
- 在本文中,本文提出了MicroNet,这是一种高效的卷积神经网络,使用极低的计算成本(例如,ImageNet分类上的6 MFLOPs)。这种低成本的网络在边缘设备上是非常需要的,但通常会遭受显著的性能下降。
- 本文基于两个设计原则来处理极低的FLOPs:
- (a) 通 过 降 低 节 点 连 通 性 来 避 免 网 络 宽 度 的 减 少 \textcolor{red}{通过降低节点连通性来避免网络宽度的减少} 通过降低节点连通性来避免网络宽度的减少,
- (b) 通 过 在 每 层 引 入 更 复 杂 的 非 线 性 激 活 函 数 来 补 偿 网 络 深 度 的 减 少 \color{blue}{通过在每层引入更复杂的非线性激活函数来补偿网络深度的减少} 通过在每层引入更复杂的非线性激活函数来补偿网络深度的减少。
- 首先,本文提出微分解卷积,将点卷积和深度卷积分解为低秩矩阵,在通道数量和输入/输出连通性之间取得良好的权衡。
- 其次,本文提出了一种新的激活函数Dynamic shift-max,通过最大限度地实现输入特征映射与其环形通道位移之间的多次动态融合来改善非线性。
- 融合是动态的,因为它们的参数适应输入。基于微分解卷积和动态Shift-Max,微处理器家族在低FLOP体制中取得了显著的性能提升。例如,MicroNet-M1在ImageNet分类中使用12个MFLOPs实现61.1%的top-1准确率,比MobileNetV3表现要好11.3%。
- 论文地址:[2011.12289] MicroNet: Towards Image Recognition with Extremely Low FLOPs (arxiv.org)
- 本文设计的MicroNet主要是在MobileNet系列上进行改进和对比,提出了两项改进方法:
- Micro-Factorized convolution:将MobileNet中的point-wise卷积以及depth-wise卷积分解为低秩矩阵,从而使得通道数目和输入输出的连通性得到一个良好的平衡。
- Dynamic Shift-Max:使用一种新的激活函数,通过最大化输入特征图与其循环通道偏移之间的多重动态融合,来增强非线性特征。之所以称之为动态是因为,融合过程的参数依赖于输入特征图。
- 论文将研究定义在一个资源十分紧张的场景:在6MFLOPs的限定下进行分辨率为224x224的1000类图片分类。对于MobileNetV3,原版的计算量为112M MAdds,将其降低至12M MAdds时,top-1准确率从71.7%降低到了49.8%。可想而知,6M MAdds的场景是十分苛刻的,需要对网络进行细心的设计。常规的做法可直接通过降低网络的宽度和深度来降低计算量,但这会带来严重的性能下降。
- 为此,论文在设计MicroNet时主要遵循两个设计要领:1)通过降低特征节点间的连通性来避免网络宽度的减少。2)通过增强非线性能力来补偿网络深度的减少。MicroNet分别提出了Micro-Factorized Convolution和Dynamic Shift-Max来满足上述两个原则,Micro-Factorized Convolution通过低秩近似减少输入输出的连接数但不改变连通性,而Dynamic Shift-Max则是更强有力的激活方法。从实验结果来看,仅需要6M MAdds就可以达到53.0%准确率,比12M MAdds的MobileNetV3还要高。
Introduction
-
近年来,设计高效的CNN架构[squeezenet,mobilenets,mobilenetV3,shufflenetV1,shufflenetV2,efficientnet]已经成为一个活跃的研究领域。这些工作能够在边缘设备上提供高质量的服务。然而,即使是最先进的高效的CNNs(例如MobileNetV3),当计算成本变得非常低时,性能也会显著下降。
-
例如,在分辨率为224 × 224的图像分类上,将MobileNetV3从112M到12M MAdds进行约束,top-1精度从71.7%下降到49.8%。这使得它在低功耗设备(如物联网设备)上的应用更加困难。
-
在本文中,通过削减一半的预算来解决一个更具挑战性的问题:能否在6MFLOPs下,在分辨率为224 × 224的1000类以上进行图像分类?
-
这种极低的计算成本(6MFLOPs)需要对每一层进行仔细的重新设计。例如,即使是在112×112网格(stride=2)上包含一个带有3个输入通道和8个输出通道的3 × 3卷积的薄干层也需要2.7MMAdds。
-
用于设计卷积层和用于1000个类的分类器的资源有限,无法学习一个良好的表示。为了适应如此低的预算,应用现有的高效cnn(如MobileNet[V1,V2,V3]和ShuffleNet[V1,V2])的一个naive的策略是显著降低网络的宽度或深度。这将导致严重的性能下降。
-
本文提出了一种名为MicroNet的新体系结构来处理极低的FLOPs。它建立在以下两个设计原则之上:
- 通过降低节点连通性来避免网络宽度的减少。
- 通过提高每层非线性来补偿网络深度的减小
-
这些原则指导我们设计更有效的卷积和激活函数。
-
首先,本文提出了微分解卷积,将点卷积和深度卷积分解为低秩矩阵。这在输入/输出连接和通道数量之间提供了一个很好的平衡。
- 具体地,本文设计了组自适应卷积来分解点态卷积。它通过平方根关系调整组的数量和通道的数量。将两个群自适应卷积叠加,本质上是将一个点卷积矩阵近似为一个块矩阵,每个块的秩为1。深度卷积的分解(rank-1)是直接的,通过将一个k × k深度卷积分解为一个1 × k和一个k × 1深度卷积(inceptionV3?)。本文展示了这两个近似在不同级别上的适当组合在不牺牲信道数量的情况下显著降低了计算成本。
-
其次,本文提出了一种新的激活函数Dynamic shift-max,从两个方面改进了非线性问题:
- (a)它最大限度地实现了输入特征映射与其环形通道位移之间的多次融合;
- (b)每次融合的参数都是动态的,因为它的参数适应输入。
- 此外,它以较低的计算成本在一个函数中有效地增强了节点连通性和非线性。
-
实验结果表明,MicroNet在很大程度上优于最先进的技术(见下图)。
-
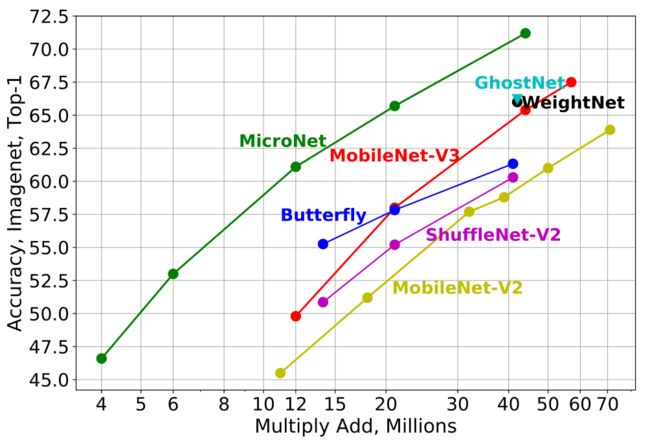
-
Computational Cost (MAdds) vs. ImageNet Accuracy.
-
在极低的FLOPs(从4M到45M MAdds)下,MicroNet显著优于最先进的高效网络。
-
-
例如,与MobileNetV3相比,本文的方法在ImageNet分类的top-1准确率分别提高了11.3%和7.7%,分别在12M和21M FLOPs的约束下。在极具挑战性的6 MFLOPs约束下,本文的方法达到53.0% top-1精度,比具有两倍复杂性的MobileNetV3获得3.2% (12 MFLOPs)。此外,一组micronet为两个像素级任务提供了强大的基线,这两个任务的计算成本非常低:语义分割和关键点检测。
-
要想实现低FLOPs, 主 要 是 要 限 制 网 络 宽 度 ( 通 道 数 ) 和 网 络 深 度 ( 网 络 层 数 ) \color{red}{主要是要限制网络宽度(通道数)和网络深度(网络层数)} 主要是要限制网络宽度(通道数)和网络深度(网络层数)。如果把一个卷积层抽象为一个图,那么该层输入和输出中间的连接边,可以用卷积核的参数量来衡量。因此作者定义了卷积层连通性(connectivity)的概念,即每个输出节点所连接的边数。
-
如果把一个卷积层的计算量设为固定值,那么更多的网络通道数就意味着更低的连通性(比如深度可分离卷积,具有较多的通道数但是有很弱的连通性)。作者认为平衡好通道数目和连通性之间的关系,避免减少通道数,可以有效地提升网络的容量。除此之外,当网络的深度(层数)大大减少时,其非线性性质会受到限制,从而导致明显的性能下降。因此,作者提出以下两个设计原则:
- 通过降低节点连接性来避免网络宽度的减小,作者是通过分解points-wise卷积以及depth-wise卷积来实现如上原则。
- 增强每一层的非线性性质来弥补网络深度减少所带来的损失,作者是通过设计了一个全新的激活函数来实现如上原则,称为Dynamic Shift-Max
Related Work
Efficient CNNs:
- MobileNets系列将k × k卷积分解为深度卷积和点向卷积。ShuffleNets系列使用组卷积和信道shuffle来简化点卷积。butterfly使用butterfly transform来近似点卷积。effentnet系列在输入分辨率和网络宽度/深度之间找到一个合适的关系。MixNet在一个卷积中混合了多个内核大小。AdderNet用更便宜的附加功能换取了大量的乘法运算。GhostNet应用廉价的线性变换来生成幻影的特征图。sandglass翻转了反向残块的结构,减少了信息的丢失。[once for all]和[Slimmable neural networks]可以使一个网络支持多个子网。
Efficient Inference:
- 高效推理[Runtime neural pruning,Optimizing accuracy-efficiency trade-offs by selective execution,Skipnet,Blockdrop]可以根据每个输入自适应地定制一个合适的子网络。[skipnet]和[Blockdrop]使用强化学习学习控制器,跳过现有模型的一部分。MSDNet允许基于预测置信度的简单样本提前dropout。[S2dnas]搜索最优的MSDNet。[Resolution adaptive networks for efficient inferenc]适应图像分辨率,实现高效推理。
Dynamic Neural Networks:
- 动态网络通过自适应输入参数来增强表示能力。HyperNet使用另一个网络为主网络生成参数。SENet通过压缩全局上下文来重加权信道。SKNet对不同大小的内核进行了调整。动态卷积根据多个卷积核的注意力聚合多个卷积核。动态ReLU适应ReLU中两个线性函数的斜率和截距。
- [Weightnet]使用分组全连接层直接生成卷积权值。[Dynamic region-aware convolution]将动态卷积从空间不可知论扩展到空间特异性。[Dynamic group convolution for accelerating convolutional neural networks]提出动态组卷积,自适应分组输入通道。
- [Conditional convolutions for instance segmentation]将动态卷积应用于实例分割。[Learning dynamic routing for semantic segmentation]学习跨尺度的动态路由以实现语义分割。
Our Method: MicroNet
Design Principles
- 极低的FLOPs约束了网络宽度(通道数量)和网络深度(层数),分别对它们进行分析。如果把卷积层看作一个图,输入和输出(节点)之间的连接(边)由核参数加权。这里,本文将连通性定义为每个输出节点的连接数。因此,连接数等于输出通道数和连接数的乘积。
- 当计算成本(与连接数成正比)固定时,通道数与连接数冲突。本文认为,两者之间的良好平衡可以有效地避免信道缩减,提高一层的表示能力。因此,本文的第一个设计原则是:通过降低节点连通性来规避网络宽度的减小。本文通过在更精细的尺度上分解点卷积和深度卷积来实现这一点。
- 当网络的深度(层数)显著减少时,其非线性(用ReLU编码)受到约束,导致性能明显下降。这激发了本文的第二个设计原则:通过提高每层非线性来补偿网络深度的减少。本文通过设计一个新的激活函数Dynamic Shift-Max来实现这一点。
Micro-Factorized Convolution
-
本文在更细的尺度上对点卷积和深度卷积进行分解,微分解卷积的名字就由此而来。目标是平衡通道数量和输入/输出连接性。
-
Micro-Factorized Point-wise Convolution:
-
本文提出群自适应卷积来分解逐点卷积。作者将pointwise卷积和depthwise卷积分解为更为合适的尺度,用来平衡通道数目和输入输出连通性。为了简洁起见,本文假设卷积核W具有相同的输入和输出通道数(Cin = Cout = C),忽略偏差。将核矩阵W分解为两个组自适应卷积,其中群号G与通道c的数量有关,数学上可以表示为:
- W = P Φ Q T , ( 1 ) W=P\Phi{Q^T},(1) W=PΦQT,(1)
-
其中W为C×C矩阵。Q是形状为 C × C R C×\frac{C}{R} C×RC的,按R压缩通道数。P是形状为 C × C R C×\frac{C}{R} C×RC的,将通道数扩展回C作为输出。P和Q是对角分块矩阵,共有G个分块,每个分块对应一个组的卷积。Φ是一个 C R × C R \frac{C}{R}×\frac{C}{R} RC×RC排列矩阵,像[shufflenetV1]一样变换信道。计算复杂度为 O = 2 C 2 R G \mathcal{O}=\frac{2C^2}{RG} O=RG2C2。下图-左是C = 18, R = 2, G = 3的例子。

- Micro-Factorized pointwise and depthwise convolutions.
- 左:将一个点态卷积分解为两个组自适应卷积,组号 G = C / R = 18 / 2 = 3 G=\sqrt{C/R}=\sqrt{18/2} = 3 G=C/R=18/2=3。得到的矩阵W分为G × G块,每个块的秩为1。中:将一个k × k深度卷积分解为k × 1和一个1 × k深度卷积。
- 右:微分解点卷积和深度卷积的简化组合。
-
需要注意的是,组号G并不是固定的,而是根据通道数C和缩减比R来调整为:
-
G = C / R , ( 2 ) G=\sqrt{C/R},(2) G=C/R,(2)
-
这个平方根关系来自于通道C数量和输入/输出连接之间的平衡。这里,本文将连通性E定义为每个输出通道的输入输出连接数。在两个组自适应卷积之间,每个输出通道连接 C R G \frac{C}{RG} RGC隐藏通道,每个隐藏通道连接 C G \frac{C}{G} GC输入通道。因此 E = C 2 R G 2 E=\frac{C^2}{RG^2} E=RG2C2。
-
-
当本文确定计算复杂度 O = 2 C 2 R G \mathcal{O}=\frac{2C^2}{RG} O=RG2C2和缩减比R时,信道数C和连通性E在G上的相反方向变化为:
- C = O R G 2 , E = O 2 G , ( 3 ) C=\sqrt{\frac{\mathcal{O}RG}{2}},E=\frac{\mathcal{O}}{2G},(3) C=2ORG,E=2GO,(3)
-
下图说明了这一点。随着组数G的增加,C增加,E减少。当 G = C / R G =\sqrt{C/R} G=C/R时,两条曲线的截距为C = E,此时每个输出通道与所有输入通道连接一次。
-

-
信道数C vs连接数E /组数g。本文假设计算代价O和缩减率R是固定的。
-
-
在数学上,将得到的卷积矩阵W分成G×G个块,每个块的秩为1(如图【Micro-Factorized pointwise and depthwise convolutions 】-左)。
-
-
Micro-Factorized Depthwise Convolution:
- 如图【Micro-Factorized pointwise and depthwise convolutions】-Middle所示,本文将k×k深度卷积核分解为k ×1核和1×k核。这与微分解点卷积(Eq. 1)具有相同的数学格式。每个通道W的核矩阵形状为k × k,它被分解为k × 1向量P和1 × k向量 Q T Q^T QT。这里Φ是一个值为1的标量。这种低秩近似将计算复杂度从 O ( k 2 C ) \mathcal{O}(k^2C) O(k2C)降低到 O ( k C ) \mathcal{O}(kC) O(kC)。
-
Combining Micro-Factorized Pointwise and Depthwise Convolutions:
- 本文以两种不同的方式组合了微分解点卷积和深度卷积:
- (a)正则组合
- (b)精简组合。
- 前者只是将两个卷积串联起来。lite组合使用微分解深度卷积,通过每个信道应用多个空间滤波器来扩展信道的数量。然后利用一组自适应卷积融合压缩信道数(如图【Micro-Factorized pointwise and depthwise convolutions】-右)。与常规相对应的方法相比,精简组合在较低的层次上更有效,因为它节省了来自信道融合(点向)的计算,以补偿学习更多的空间滤波器(深度)。
- 本文以两种不同的方式组合了微分解点卷积和深度卷积:
Dynamic Shift-Max
-
现在本文提出动态的Shift-Max函数,一个新的激活函数来增强非线性。它动态地将输入特征映射与其循环群移位相融合,其中一组信道被移位。动态Shift-Max还能加强小组之间的联系。这是对专注于组内连接的微分解点卷积的补充。
-
Definition:
-
设 x = { x i } ( i = 1 , … , C ) x =\{x_i\} (i = 1,…, C) x={xi}(i=1,…,C)表示一个输入向量(或张量),它有C个通道,分成G组。每组有 C G \frac{C}{G} GC通道。其N通道圆移可以表示为 x N ( i ) = x ( i + N ) m o d c x_N(i)=x_{(i+N)~ mod ~c} xN(i)=x(i+N) mod c。本文将通道移扩展到群移,定义群圆函数为:
-
x C G = x ( i + j C G ) m o d C , j = 0 , . . . , G − 1 , ( 4 ) x_{\frac{C}{G}}=x_{(i+j\frac{C}{G})~mod~C},j=0,...,G-1,(4) xGC=x(i+jGC) mod C,j=0,...,G−1,(4)
-
其中 x C G ( i , j ) x_{\frac{C}{G}} (i, j) xGC(i,j)对应于将第i个通道xi移动j组。动态Shift-Max组合多个(J)组移位如下:
-
y i = max 1 ≤ k ≤ K { ∑ j = 0 J − 1 a i , j k ( x ) x C G ( i , j ) } , ( 5 ) y_i=\max_{1\leq{k}\leq{K}}\{\sum^{J-1}_{j=0}a^k_{i,j}(x)x_{\frac{C}{G}}(i,j)\},(5) yi=1≤k≤Kmax{j=0∑J−1ai,jk(x)xGC(i,j)},(5)
-
其中参数 a i , j k ( x ) a^k_{i,j}(x) ai,jk(x)通过一个超函数来适应输入x,可以在平均池化后使用两个完全连接的层来轻松实现,类似于Squeeze-and-Excitation。
-
-
Non-linearity:
- Dynamic Shift-Max编码了两种非线性:
- (a)输出J组K种不同融合的最大值,
- (b)参数 a i , j k ( x ) a^k_{i, j} (x) ai,jk(x)不是静态的,而是输入x的函数。
- 这些为Dynamic ShiftMax提供了更多的表示能力,以补偿层数的减少。最近提出的动态ReLU是动态Shift-Max (J = 1)的特殊情况,其中每个通道单独激活。
- Dynamic Shift-Max编码了两种非线性:
-
Connectivity:
-
动态Shift-Max改进了信道组之间的连通性。
-
它是微分解点卷积的补充,重点是每个组内的连通性。下图表明,即使是静态组移位( y i = a i , 0 x C G ( i , 0 ) + a i , 1 x C G ( i , 1 ) y_i=a_{i,0}x_{\frac{C}{G}}(i, 0) + a_{i,1}x_{\frac{C}{G}}(i, 1) yi=ai,0xGC(i,0)+ai,1xGC(i,1))也能有效提高微分解点卷积的秩。
-

- Group shift (a special case of dynamic Shift-Max)
- 改进了微分解点卷积。得到的卷积矩阵中每个块的秩从1增加到2。
-
将其插入到两个组自适应卷积之间,得到的卷积矩阵W (G × G块矩阵)中每个块的秩从1增加到2。注意,静态组移位是动态shift - max的一个简单特殊情况,K = 1, J = 2,静态 a i , j k a^k_{i,j} ai,jk。
-
论文将pointwise convoluton分解成了多个稀疏的卷积,如上图所示,先对输入进行维度压缩,shuffle后进行维度扩展,个人感觉这部分与shufflenet基本一样。这样的操作在保证输入与输出均有关联的情况下,使得输入与输出之间的连接数减少了很多。
-
-
Computational Complexity:
- 动态Shift-Max从输入x生成CJK参数 a i , j k ( x ) a^k_{i,j}(x) ai,jk(x)。计算复杂度包括三个部分:
- (a)平均池化 O ( H W C ) \mathcal{O}(HWC) O(HWC),
- (b)在等式 5, O ( C 2 J K ) \mathcal{O}(C^2JK) O(C2JK)中生成参数 a i , j k ( x ) a^k_{i,j}(x) ai,jk(x),
- ©在每个通道和每个空间位置 O ( H W C J K ) \mathcal{O}(HW CJK) O(HWCJK)中应用动态Shift-Max。
- 当J和K很小的时候,它是轻量级的。根据经验,在J = 2和K = 2时可以实现很好的权衡。
- 动态Shift-Max从输入x生成CJK参数 a i , j k ( x ) a^k_{i,j}(x) ai,jk(x)。计算复杂度包括三个部分:
Relation to Prior Work
- MicroNet与两种流行的高效网络(MobileNet[V1,V2,V3]和ShuffleNet[V1,V2])有关。它与MobileNet共享反向瓶颈结构,与ShuffleNet共享使用组卷积。
- 相比之下,MicroNet在卷积函数和激活函数上都与它们不同。首先,将点卷积分解为组自适应卷积,群数适应信道数 G = C / R G =\sqrt{C/R} G=C/R;其次,对卷积进行深度分解。最后,提出了一种新的激活(即动态Shift-Max),以改善信道连通性和非线性。
MicroNet Architecture
-
现在本文描述了四种微网模型的架构,它们的FLOPs次数从6M到44M不等。它们由三种类型的微块(参见下图)组成,它们以不同的方式结合了微分解点卷积和深度卷积。
-

-
Diagram of three Micro-Blocks.
-
(a) Micro-Block-A,它使用了微分解点卷积和深度卷积的简化组合(见图【Micro-Factorized pointwise and depthwise convolutions】-右)。
-
(b)连接MicroBlock-a和MicroBlock-c的MicroBlock-b。
-
© MicroBlock-C,它使用了微分解点卷积和深度卷积的规则组合。它们的用法见下表。
-
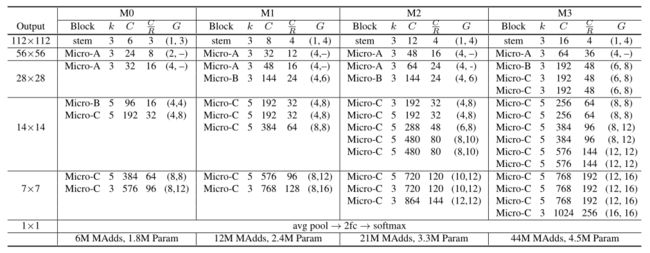
-
MicroNet Architectures.
-
“stem”指茎层。“Micro-A”、“Micro-B”和“Micro-C”指的是三个微块(上图)。k为核大小,C为输出通道数,R为微分解点卷积中的通道缩减比,G为组数。注意,对于“Micro-A”(见上图a), C是微分解深度卷积的输出通道数,C/R是块的输出通道数。
-
-
它们都使用动态ShiftMax作为激活函数。具体描述如下:
-
Micro-Block-A:
- 如上图a所示,Micro-Block-A采用了微分解点卷积和深度卷积的简化组合(如上图【Micro-Factorized pointwise and depthwise convolutions】-右)。它在分辨率更高的较低级别(如112×112或56 × 56)是有效的。注意,信道数通过微分解深度卷积进行扩展,通过群自适应卷积进行压缩。
-
Micro-Block-B:
- Micro-Block-B用于连接micro - block - a和Micro-Block-C。与Micro-Block-A不同,它使用了一个完整的微分解点卷积,包括两个组自适应卷积(如上图所示)。前者挤压了渠道数量,而后者扩大了渠道数量。每个MicroNet只有一个Micro-Block-B(见上表)。
-
Micro-Block-C:
- Micro-Block-C(如上图c所示)使用了连接微分解深度卷积和点卷积的规则组合。它被用于更高的级别(见上表),因为它在信道融合(点态)上比精简组合花费更多的计算。当维度匹配时使用跳过连接。
-
每个Micro-Block有4个超参数:核大小k、输出通道数C、微因式点卷积瓶颈处的减小率R、两个组自适应卷积的组数对(G1、G2)。注意,本文将等式2放宽为G1G2 = C/R,并找到接近整数解。
-
Stem Layer:
- 重新设计了Stem Layer,以满足低FLOP约束。它包括一个3 × 1的卷积和一个1 × 3的群卷积,然后是一个ReLU。第二次卷积将信道数扩大R倍。这大大节省了计算成本。例如,MicroNet-M3的茎层(见上表)只需要1.5M MAdds。
-
Four MicroNet Models (M0–M3):
- 本文设计了四种模型(M0, M1, M2, M3),计算成本不同(6M, 12M, 21M, 44M MAdds)。上表显示了它们的完整规范。这些网络从低到高遵循相同的模式:茎层→微块a→微块b→微块c。注意,所有模型都是手动设计的,没有网络架构搜索(NAS)。
Experiments: ImageNet Classification
- 下面本文评估4种MicroNet模型(M0-M3)以及ImageNet分类的综合消融实验。ImageNet有1000个类,包括1281167张用于训练的图像和50000张用于验证的图像。
Implementation Details
- 训练策略:每个模型都有两种训练方式:
- (a)单独训练,
- (b)相互学习。
- 前者很简单,模型可以自己学习。后者沿着每个MicroNet共同学习一个全阶伙伴,其中全阶伙伴共享相同的网络宽度/高度,但用原始的点向和深度卷积(k ×k)取代微分解点向和深度卷积。 K L 散 度 \textcolor{red}{KL散度} KL散度被用来激励MicroNet向其相应的全级别伙伴学习。
- 训练设置:所有模型都使用0.9动量的SGD优化器进行训练。图片分辨率为224×224。本文使用的小批量大小为512,学习率为0.02。每个模型用余弦学习率衰减训练600个epoch。对于较小的Micornets(M0和M1),权重衰减为3e-5,dropout率为0.05。对于较大的模型(M2和M3),重量衰减为4e-5,dropout率为0.1。为避免过拟合,MicroNet-M3采用了标签平滑(0.1)和Mixup(0.2)。
Main Results
- 下表在四种不同的计算成本下比较了micronet与最先进的imagenet分类。在所有四个FLOP限制条件下,MicroNets明显优于所有先前的作品。
-
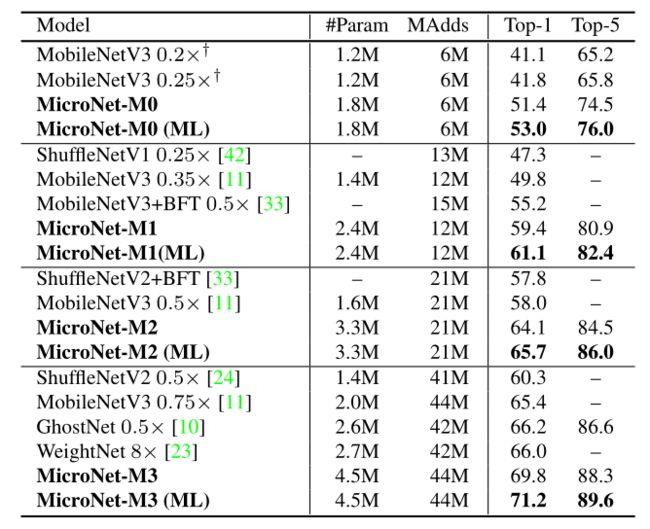
-
ImageNet classification results.
-
“ML”代表与满级伙伴相互学习。†表示本文的执行。MobileNetV3 0.2×只减少了网络宽度,而MobileNetV3 0.25×同时减少了宽度和深度(移除两个块)。“-”:论文原文中没有。
-
- 例如,在没有相互学习的情况下,micronet的6M、12M、21M和44M FLOPs次数分别比MobileNetV3高出9.6%、9.6%、6.1%和4.4%。在相互学习的训练下,所有4个micronet都能持续获得约1.5%的top-1精度。
- 本文的方法在6M次FLOPs时达到53.0%的top-1准确率,比复杂性加倍的MobileNetV3 (12M次FLOPs)高出3.2%。当与最近对MobileNet和ShuffleNet的改进进行比较时,如GhostNet , WeightNet和Butterfly Transform,本文的方法在类似的FLOPs中获得了超过5%的top-1精度。这证明了MicroNet能够有效地处理极低的FLOPs。
Ablation Studies
-
本文进行了一些消融实验来分析MicroNet。MicroNet-M1 (12M FLOPs)用于所有消融实验,每个模型都经过300个epoch的训练。动态Shift-Max的默认超参数设置为J = 2, K = 2。
-
From MobileNet to MicroNet:
- 下表显示了从MobileNet到本文的MicroNet的路径。
-

-
利用ImageNet分类对从MobileNet到MicroNet的路径进行了评估。
-
在这里,本文修改了MobileNet-V2,使其具有类似于三种微分解卷积选项的FLOPs(约10.6M):深度(DW)、点(PW)和低水平的lite组合(lite)。本文也比较动态的Shift-Max与它的静态对应(静态 a i , j k a^k_{i,j} ai,jk在Eq. 5)。
-
- 两者共享反向瓶颈结构。在这里,修改了MobileNetV2(不含SE),使其具有类似的复杂性(10.5M MAdds),具有三个微分解卷积变化(第2-4行)。微分解点卷积和深度卷积及其在低水平上的精简组合将top-1的精度从44.9%逐步提高到51.7%。
- 此外,使用静态和动态Shift-Max可以分别获得2.7%和6.8%的top-1精度,并增加少量额外成本。这表明提出的微分解卷积和动态Shift-Max在处理极低的计算成本方面是有效的和互补的。
- 下表显示了从MobileNet到本文的MicroNet的路径。
-
Group number G:
-
微分解点卷积包括两个组自适应卷积,它们的组号是通过放松 G = C / R G=\sqrt{C/R} G=C/R来关闭整数来选择的。下表a将其与具有相似结构和FLOPs(约10.5M MAdds),但使用固定组号的网络进行了比较。组自适应卷积具有更高的精度,在通道数量和输入/输出连通性之间表现出良好的平衡。
-

-
ImageNet分类中微分解卷积的消融。⭐表示论文其余部分的默认选择。
-
上表b比较了由乘数λ控制的自适应群数的不同选择,其 G = λ C / R G=λ\sqrt{C/R} G=λC/R。λ值越大,对应的通道越多,但输入/输出连接越少(见图【Number of Channels C vs. Connectivity】)。当λ在0.5和1之间时,可以达到较好的平衡。
-
当λ增加(更多的通道,但更少的连通性)或减少(更少的通道,但更多的连通性)时,top-1精度下降。因此,在本文的其余部分使用λ = 1。请注意,上表b中的所有模型都有类似的计算成本(约10.5m MAdds)。
-
-
Lite combination at different levels:
- 上表c比较了在不同层次上使用微分解点卷积和深度卷积的简化组合(见图【Diagram of three Micro-Blocks】-右)。仅在低水平使用它就能达到最高的精度。这验证了精简组合在较低的级别上更有效。与常规组合相比,它节省了来自信道融合(点向)的计算量,以补偿学习更多的空间滤波器(深度)。
-
Comparing with other activation functions:
- 本文将动态Shift-Max与现有的三种激活函数ReLU、SE+ReLU和动态ReLU进行了比较。结果如下表所示。
-

-
动态Shift-Max与ImageNet分类上的其他激活函数。 MicroNet-M1 is used.
-
- 本文的动态Shift-Max以明显的优势(2.5%)超过了其他三款,显示了它的优越性。注意动态ReLU是J = 1的动态Shift-Max的特殊情况(见Eq. 5)。
- 本文将动态Shift-Max与现有的三种激活函数ReLU、SE+ReLU和动态ReLU进行了比较。结果如下表所示。
-
Dynamic Shift-Max at different layers:
- 下表显示了在一个微块的三个不同层中使用动态Shift-Max的最高精度(参见图【Diagram of three Micro-Blocks.】)。
-

-
Dynamic Shift-Max at different layers evaluated on ImageNet.
-
A1、A2、A3依次表示Micro-Block-B和Micro-Block-C中的三个激活层(见图【Diagram of three Micro-Blocks.】)。Micro-Block-A只包括A1和A2。 MicroNet-M1 is used.
-
- 在更多层中使用它会产生一致的改进。当对所有三层都使用它时,可以获得最好的精度。如果只允许一层使用动态Shift-Max,建议在深度卷积之后使用。
- 下表显示了在一个微块的三个不同层中使用动态Shift-Max的最高精度(参见图【Diagram of three Micro-Blocks.】)。
-
Different hyper parameters in dynamic Shift-Max:
- 下表显示了使用K和J不同组合的结果(在Eq. 5中)。
-
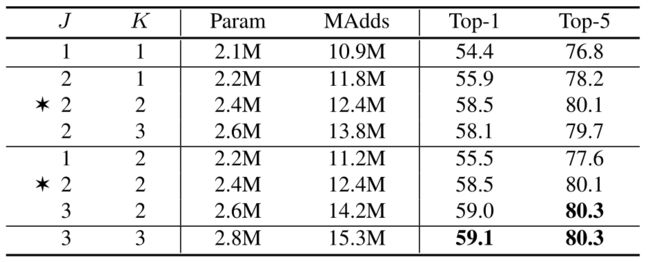
-
Ablations of two hyper parameters in dynamic ShiftMax (J, K in Eq. 5) on ImageNet classification.
-
⭐表示论文其余部分的默认选择。
-
- 当K = 1时,由于max算子中只剩下一个元素,本文添加ReLU。第一行的基线(J = 1, K = 1)相当于SE+ReLU。固定J = 2(融合两组)时,两次融合(K = 2)的优胜者优于一次融合(K = 1)。添加第三次融合没有帮助,因为它主要被其他两次融合覆盖,但涉及更多参数。当固定K = 2(最多两次融合)时,加入更多J组始终更好,但引入更多FLOPs。在J = 2和K = 2时实现了良好的权衡,其中通过额外的1。5M MAdds实现了4.1%的增益。
- 下表显示了使用K和J不同组合的结果(在Eq. 5中)。
MicroNet for Pixel-Level Classification
- MicroNet不仅对图像级分类有效,而且对像素级任务也有很好的效果。本文将展示它在人体姿态估计和语义分割中的应用。
Human Pose Estimation
- 本文利用COCO 2017数据集在单点关键点检测上对MicroNet进行评估。本文的模型在train2017上进行训练,包括57K张图片和150K个带有17个关键点的人实例。本文在包含5000幅图像的val2017上评估本文的方法,并使用超过10个目标关键点相似度(OKS)阈值的平均精度(AP)作为度量标准。
- Implementation Details:与图像分类类似,本文有四个MicroNet模型(M0-M3)用于不同FLOPs下的关键点检测。通过增加一组选定块(例如步幅为32的所有块)的分辨率(×2),对模型进行修改以适应关键点检测任务。不同的MicroNet型号的选择不同(详见附录)。每个模型都有一个头部,其中包括三个微块(一个步幅为8,两个步幅为4)和一个点卷积,用于生成17个关键点的热图。本文使用双线性上采样来增加头部的分辨率,每层使用空间注意。
- Training Setup: 使用[Deep high-resolution representation learning for human pose estimation.]中的培训设置。人体检测盒被裁剪并调整为256 × 192。数据增强包括随机旋转([−45°,45°])、随机缩放([0.65,1.35])、翻转和半体数据增强。所有模型都是使用Adam优化器从头训练250个epoch。初始学习率设定为1e-3,在第210和240阶段分别下降到1e-4和1e-5。
- Testing: 测试采用两阶段自顶向下的范式[Simple baselines for human pose estimation and tracking,Deep high-resolution representation learning for human pose estimation]:先检测人的实例,然后预测关键点。使用[Simple baselines for human pose estimation and tracking]提供的相同的人员检测器。将原始图像和翻转图像的热图相结合,通过调整最高热值的位置以四分之一偏移向第二高响应来预测关键点。
- Main Results:下表比较了MicroNets与之前的研究[Dynamic relu,Dynamic convolution]在有效姿态估计方面的差异,其中计算成本小于850 MFLOPs。
-

-
COCO keypoint detection results.
-
将micronet比作两个动态网络(动态卷积和动态ReLU),它们建立在MobileNet V2和V3之上,在骨干和头部共享相同的结构。
-
- 两项工作都使用了MobileNet在主干和头部的反向剩余瓶颈块,并通过对输入的卷积和激活函数的参数进行调整,显示了明显的改进。在这些工作中,本文的MicroNet-M3只消耗33%的FLOPs,但取得了类似的性能,表明本文的方法对于关键点检测也是有效的。此外,MicroNet-M2、M1、M0以更低的计算复杂度(从77M到163M flps)为关键点检测提供了良好的基线。
Semantic Segmentation
-
本文在带有精细标注的Cityscape数据集上进行了实验,以评估MicroNet在语义分割方面的效果。本文的模型在训练精集上训练,包括2975张图像。本文在包含500张图像的值集上评估本文的方法,并使用mIOU作为度量。
-
Implementation Details:本文修改了4个作为骨干的MicroNet模型(M0-M3),将步幅为32的所有区块的分辨率提高到16,类似于MobileNetV3。本文的模型具有非常低的计算成本,从2.5B到0.8B的图像分辨率1024×2048的FLOPs。本文在分割头部采用Atrous空间金字塔池(LR-ASPP)[MobilenetV3]的精简设计,将特征映射双线性上采样2,应用空间注意,并在第8步与骨干特征映射合并。本文用微分解卷积代替1 × 1卷积,使LR-ASPP更轻,称之为Micro-Reduce ASPP (MR-ASPP)。
-
Training Setup:所有模型随机初始化并训练240个epoch。初始学习率设为0.2,用余弦函数衰减到1e-4。权重衰减设为4e-5。使用了[Rethinking atrous convolution for semantic image segmentation]中的数据扩充。
-
Main Results:下表报告了所有四个微网的mIOU。与MobileNetV3 (68.4 mIOU, 2.9 b MAdds)相比,本文的MicroNet-M3更准确(69.1 mIOU),计算成本更低(2.52B MAdds)。
-
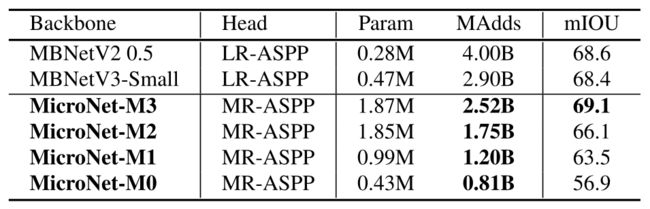
-
Semantic segmentation results on Cityscapes validation set.
-
前两行的结果来自[MobilenetV3]。
-
-
这表明了该方法在语义分割方面的优越性。此外,本文的MicroNet-M2, M1, M0为语义分割提供了良好的基线,FLOPs甚至更低,从1.75B到0.81B MAdds。
Conclusion
- 在本文中,本文提出了处理极低计算成本的微网络。该算法基于微分解卷积算子和动态最大移位算子。前者通过点卷积和深度卷积的低秩近似来平衡通道数量和输入/输出连通性。后者动态融合连续信道组,增强节点连通性和非线性以补偿深度缩减。在极低的FLOPs条件下,一组MicroNets实现了对三项任务(图像分类、人体姿态估计和语义分割)的有效改进。本文希望这项工作为有效的cnn在多种视觉任务提供良好的基线。
- 论文提出应对极低计算量场景的轻量级网络MicroNet,包含两个核心思路Micro-Factorized convolution和Dynamic Shift-Max,Micro-Factorized convolution通过低秩近似将原卷积分解成多个小卷积,保持输入输出的连接性并降低连接数,Dynamic Shift-Max通过动态的组间特征融合增加节点的连接以及提升非线性,弥补网络深度减少带来的性能降低。从实验结果来看,MicroNet的性能十分强劲。
Appendix
- 在附录中,展示了用于人体姿态估计的MicroNet架构的细节
Architectures for Human Pose Estimation
- 本文利用COCO 2017数据集在单点关键点检测上对MicroNet进行评估。人体检测框被裁剪并调整为256×192,每个人实例被标记为17个关键点。
- 下表展示了4个用于人体姿态估计的MicroNet模型(M0-M3)。与ImageNet分类不同的是,关键点检测的主干在stride为16(分辨率为16×12)时停止,以保留更多的空间信息。每个模型都有一个包含三个micro-block的头部。第一个是stride为8(分辨率32×24),而其他两个是stride为4(分辨率64×48)。
-

-
MicroNet Architectures for Keypoint Detection.
-
“stem”指茎层。“Micro-A”、“Micro-B”和“Micro-C”指的是三个微块。k为核大小,C为输出通道数,R为微分解点卷积中的通道缩减比,G为组数。
-
注意,对于“Micro-A”,它使用了微分解点卷积和深度卷积的精简组合,C是微分解深度卷积的输出通道数,C/R是块的输出通道数。头部的最后一个块是Micro-A†,其中微分解深度卷积不扩展信道数。
-
- 注意,最后一个块是Micro-Block-A,它使用精简组合来缩小通道的数量。它与骨干中的Micro-Block-A不同,它的微分解深度卷积不扩大信道数量。然后对头部进行逐点卷积,生成17个关键点的热图。本文使用双线性上采样来提高头部分辨率,并使用每层动态ReLU中的空间注意。