python+selenium实现微博自动登录+用户微博信息爬取
1主要内容
目的:实现微博的自动登录,实现对某个用户所发微博的时间,客户端,文案,转发数,评论数以及点赞数的爬取。
难点:如下图所示:
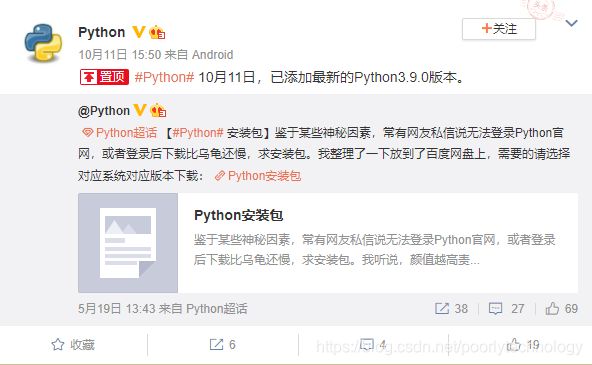
这个微博时是用户转载的自己以前的博文,而且在对目标信息进行爬取时会出现两个不一样的信息,由于我最后会将这个信息形成列表进行提取,所以会出现时间,客户端,文案,转发数,评论数以及点赞数不匹配的情况,所以需要将爬取到的多余的信息删除。需要分辨出哪个是多余的信息,这里两个时间以及客户端的节点元素信息是一样的并且在同一个div下面,所以无法从HTML的角度着手;而另外的三个信息由于其对应的class属性不同,所以可以直接从源码入手,爬取本次发博的信息。
工具:python,selenium ,pycharm
1.1微博自动登录
自动登录无非就是自动输入用户名和密码,如果需要验证时,暂停程序,手动出入验证码,然后自动点击登录button,代码段如下:
def loginFoc(url,username,password):
# driver = webdriver.Chrome("C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe")
# driver.get("https://login.sina.com.cn/")
driver.get(url)
elem=driver.find_element_by_name("username")
elem.clear()
elem.send_keys(username)
time.sleep(2)
elem1=driver.find_element_by_name("password")
elem1.clear()
elem1.send_keys(password)
time.sleep(1)
elem2=driver.find_element_by_xpath("//div[@class='btn_mod']/input").click()#取消“下次自动登录的打勾”
time.sleep(1)
#elem1.send_keys(Keys.RETURN)#也可以直接点击回车登录
#elem3=driver.find_element_by_xpath("//input[@class='W_btn_a btn_34px']").click() #多种爬取方式
#elem3=driver.find_element_by_xpath("//div[@class='form_mod']/ul/li[7]").click()
driver.find_element_by_xpath("//div[@class='form_mod']/ul/li[7]").click()
time.sleep(15)
print("登录成功")
time.sleep(2)
driver.close()
直接使用https://login.sina.com.cn/网站进行登录
1.2自动搜索关键词
将所要查询的内容输入搜索框,然后点击搜索button,代码段如下:
driver.get(url_s)
elem4=driver.find_element_by_xpath("//div[@class='search-input']/input")
elem4.send_keys(keyword)
elem4.send_keys(Keys.RETURN)#相当于回车
print("搜索成功") #也可以定位搜索元素,实现点击登录
1.3跳转到用户微博界面
点击用户名称就可以进入用户界面,同时输出用户名称和用户微博超链接。首先定位名称节点,然后就可以看到text为用户名称,href就是用户微博超链接,然后用鼠标实现点击就可以了,代码段如下:
elem5=driver.find_element_by_xpath("//div[@class='info']/div/a[1]")
# print(elem5)
url_into=elem5.get_attribute("href")
print('[作者]:',elem5.text)
print('[链接:]', url_into)
# print("\r\n")
now_handle=driver.current_window_handle#记录未点击时的网页窗口
elem5.click()
注意:当跳转到页面窗口后,只是网页跳转了,源码并没有跳转,所以如果现在去定位用户微博信息,selenium是找不到节点位置的,所以必须实现对网页的源码的跳转,可以使用句柄的方式。
源码跳转代码段如下:
all_handle=driver.window_handles
for handle in all_handle:
if handle != now_handle:
now_handle=driver.switch_to.window(handle)
time.sleep(5)
找出所有的窗口句柄,实现一个循环,当窗口发生了改变的时候跳转到指定的窗口。
1.4网页滑动下拉加载
有的网页是需要下拉加载的,这次用户博客的网页就是这种情况,下面是实现下拉加载的代码段:
# 实现自动下拉滚动条
js = "return action=document.body.scrollHeight" # 获取页面初始高度
height = driver.execute_script(js)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 将滚动条滚至页面底部
t1 = int(time.time()) # 定义初始时间戳
state = True#设置一个状态值
while state:
t2 = int(time.time())#当前时间戳
if t2 - t1 > 2:#2为设置的加载时间,电脑或者网速不太顶的可以加长时间
new_height = driver.execute_script(js)
if new_height > height:
time.sleep(1)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
height = new_height
t1 = int(time.time())
else:
if new_height == height:
state = False
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
原理:首先获取当前页面高度,使用execute_script执行,并将滚动条滚至页面底部,然后记录一个时间,并且设置一个状态值(后面循环会用到),当状态为True时,进行一个循环,如果时间超过了所设置的时间阈值,就会此时的页面高度与初始的页面高度进行比较,如果当前的页面高度比其大,就表示成功加载了一次下拉页面,再以当前页面高度作为初始页面高度,当前时间作为初始时间戳,然后进行下一次的循环;如果当前页面高度与初始页面高度相同就要分两种情况讨论。情况一:此页面的下拉加载完毕,也就是达到了页面的最底部;情况二:电脑太卡在给定阈值内没有加载出来(此时可以增加阈值)或者网速太卡没有加载出来。也可以设置容错机制,当出现当前高度等于初始高度的时候重试三次,如果三次都是同样的结果就可以基本认定加载到了页面底部。
此处参考链接如下:
https://blog.csdn.net/xu_cxiang/article/details/104539223
1.5发博时间,客户端爬取
将这两个信息放在一起是因为它们的爬取方式相同,在爬取到所有的时间和来源客户端后,需要删除来自于转载的博文下面的信息,像上面那张图就是要删除5月19日 13:43和python超话这两个内容。
注意:这是用户转载的自己的之前发的博文,所以当按时间顺序进行爬取时,这篇博文是会在后面出现的,也就是说最后时间和客户端列表里会出现两个5月19日 13:43和python超话元素,由于后面也有很多这种情况,不可能一一找到每个元素对应的索引,因此只能进行值删除,但是值删除就是出现将两个元素都删除的情况。最后,决定使用代替的办法。爬取信息代码段如下:
elem6=driver.find_elements_by_xpath("//div[@class='WB_from S_txt2']/a[1]")
elem6_1=driver.find_elements_by_xpath("//div[@class='WB_func clearfix']/div/a[1]")
for e6_1 in elem6_1:
em6_1.append(e6_1.get_attribute('title'))
for e6 in elem6:
title=e6.get_attribute('title')
# print(title, '123')
em6.append(title)
time.sleep(2)
elem7=driver.find_elements_by_xpath("//div[@class='WB_from S_txt2']/a[2]")
elem7_1=driver.find_elements_by_xpath("//div[@class='WB_func clearfix']/div/a[2]")
for e7_1 in elem7_1:
em7_1.append(e7_1.text)
# print(len(em7_1))
for e7 in elem7:
em7.append(e7.text)
elem6表示定位的所有的时间信息,elem6_1则是表示转载的博文的时间信息,也就是5月19日 13:43这些信息,elem7以及elem7_1则是对应的客户端的信息。定位转载的博文时间以及客户端信息的时候可以准确定位,但是定位当时发的博文的时间和客户端时会连带着转载的博文的信息,没办法精确定位到当时发的博文的信息,所以需要删除多余的信息。删除信息代码段如下:
for i in range(len(elem12)):
for j in range(len(em6_1)):
if em6[i]==em6_1[j]:
em6.remove(em6[i])
em7.remove(em7[i])
em7_1[j]='0'
em6_1[j]='0'
em6为当时发的博文的时间列表,em6_1为当时发的博文的客户端列表,em7与em7_1则是对应的客户端列表。
思路:
(1)将当前所发博文的时间与转载的博文时间进行比较,如果两者出现相等,表明转载的这个时间在后面出现了(以5月19日 13:43这个转载博文时间为例,由于用户是转载的自己以前的博文,表明在以时间排序的情况下,后面的博文中有这个时间,即这个被转载的博文是我们在后面也会爬取的博文)。
(2)此时就需要将em6中首次出现的这个时间删除,然后将后面的出现的时间留下。上面代码使用了循环嵌套,第一个循环遍历em6中的元素,第二个循环遍历em6_1中的元素,当两个列表元素出现相等时,将em6列表的元素remove,此时对于列表em6_1的处理需要格外注意。对于这个相同的元素,如果em6_1不进行删除,就会导致em6后面出现的这个元素也被删除,如果将这个元素删除就会在下一次遍历em6_1的时候出现索引超出列表范围的情况(因为em6只需要遍历一次,所以不会出现这种情况)。
(3)为了避免这种情况,采用变相删除法(我自己命名的),即用元素代替,可以使用’0’元素代替对应相等的em6_1中的元素,这样在em6后面的元素也不会出现被删除的情况。因为em7_1与em6_1的列表长度相同,所以可以将它们看作一一对应的,所以只需要对着em6_1的索引,对em7_1进行相同的操作就可以了。
1.6文案,转发数,评论数以及点数爬取
这三个信息是可以通过精确定位解决之前那种问题的,所以只需要爬取对应信息即可,代码段如下:
time.sleep(2)
elem8=driver.find_elements_by_xpath("//div[@class='WB_text W_f14']")
for e8 in elem8:
em8.append(e8.text)
time.sleep(2)
elem9=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[2]")
for e9 in elem9:
e_9=re.compile(r"\d+")
num9=e_9.findall(e9.text)
if num9==[]:
num9.append(0)
a=list(map(int,num9))
em9.append(a[0])
time.sleep(2)
elem10=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[3]")
for e10 in elem10:
e_10=re.compile(r"\d+")
num10=e_10.findall(e10.text)
if num10==[]:
num10.append(0)
b=list(map(int,num10))
em10.append(b[0])
time.sleep(2)
elem11=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[4]")
for e11 in elem11:
e11=e11.text
e_11=re.compile(r"(\d+)")
num11=e_11.findall(e11)
if num11==[]:
num11.append(0)
c=list(map(int,num11))
em11.append(c[0])
这一部分也有需要注意的几点:
(1)爬取数字时存在’ñ’符号,而这个位置不方便实现对19的精确定位,所以为了删除这个符号可以使用正则表达式e_11=re.compile(r"(\d+)"),将爬取到的内容中的数字提取出来,这样就可以实现对19的单独爬取。
<span node-type="like_status" class=""><em class="W_ficon ficon_praised S_txt2">ñem><em>19em>span>
(2)当转发数,评论数以及点赞数存在为0的情况时,会直接爬取到“转发”,“评论”,“点赞”这些字样,这就不美观了,所以需要将这种情况下的对应数字设置为0,这里也使用到了前面的正则表达式,在爬取的过程中只爬取数字,碰到刚才说的情况就会形成一个空集[],此时可以将数字0填入对应的[],这样就可以实现在此情况下0的输出。
(3)由于输出的是列表元素,所以最后的结果都是形如[‘1’]这种,影响美观,此时使用调用list里面的map函数,将列表数字元素转换为对应的Int型数输出,a=list(map(int,num9))。
2完整代码
2.1代码
代码如下:
#-*-coding:utf-8-*-
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import re
driver = webdriver.Chrome("C:/Users/Administrator/AppData/Local/Google/Chrome/Application/chromedriver.exe")
def loginFoc(url,username,password):
driver.get(url)
elem=driver.find_element_by_name("username")
elem.clear()
elem.send_keys(username)
time.sleep(2)
elem1=driver.find_element_by_name("password")
elem1.clear()
elem1.send_keys(password)
time.sleep(1)
elem2=driver.find_element_by_xpath("//div[@class='btn_mod']/input").click()#取消“下次自动登录的打勾”
time.sleep(1)
#elem1.send_keys(Keys.RETURN)#也可以直接点击回车登录
#elem3=driver.find_element_by_xpath("//input[@class='W_btn_a btn_34px']").click() #多种爬取方式
elem3=driver.find_element_by_xpath("//div[@class='form_mod']/ul/li[7]").click()
time.sleep(15)
driver.find_element_by_xpath("//div[@class='form_mod']/ul/li[7]").click()
print("登录成功")
time.sleep(2)
driver.close()
def searchFoc(url_s,keyword):
driver.get(url_s)
elem4=driver.find_element_by_xpath("//div[@class='search-input']/input")
elem4.send_keys(keyword)
elem4.send_keys(Keys.RETURN)
print("搜索成功")
time.sleep(5)
elem5=driver.find_element_by_xpath("//div[@class='info']/div/a[1]")
# print(elem5)
url_into=elem5.get_attribute("href")
print('[作者]:',elem5.text)
print('[链接:]', url_into)
# print("\r\n")
now_handle=driver.current_window_handle
elem5.click()
time.sleep(5)
em6=[]
em6_1=[]
em7=[]
em7_1=[]
em8=[]
em9=[]
em10=[]
em11=[]
all_handle=driver.window_handles
for handle in all_handle:
if handle != now_handle:
now_handle=driver.switch_to.window(handle)
time.sleep(5)
# 实现自动下拉滚动条
js = "return action=document.body.scrollHeight" # 获取页面初始高度
height = driver.execute_script(js)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)') # 将滚动条滚至页面底部
t1 = int(time.time()) # 定义初始时间戳
state = True
while state:
t2 = int(time.time())
if t2 - t1 > 2:
new_height = driver.execute_script(js)
if new_height > height:
time.sleep(1)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
height = new_height
t1 = int(time.time())
else:
if new_height == height:
state = False
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
elem12=driver.find_elements_by_xpath("//div[@action-data='cur_visible=0']")
print(len(elem12))
# print(elem12)
elem6=driver.find_elements_by_xpath("//div[@class='WB_from S_txt2']/a[1]")
elem6_1=driver.find_elements_by_xpath("//div[@class='WB_func clearfix']/div/a[1]")
for e6_1 in elem6_1:
em6_1.append(e6_1.get_attribute('title'))
#print(len(em6_1))
for e6 in elem6:
title=e6.get_attribute('title')
# print(title, '123')
em6.append(title)
time.sleep(2)
elem7=driver.find_elements_by_xpath("//div[@class='WB_from S_txt2']/a[2]")
elem7_1=driver.find_elements_by_xpath("//div[@class='WB_func clearfix']/div/a[2]")
for e7_1 in elem7_1:
em7_1.append(e7_1.text)
# print(len(em7_1))
for e7 in elem7:
em7.append(e7.text)
# print(e7.text)
time.sleep(2)
elem8=driver.find_elements_by_xpath("//div[@class='WB_text W_f14']")
for e8 in elem8:
em8.append(e8.text)
# print(e8.text)
time.sleep(2)
elem9=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[2]")
for e9 in elem9:
e_9=re.compile(r"\d+")
num9=e_9.findall(e9.text)
if num9==[]:
num9.append(0)
a=list(map(int,num9))
em9.append(a[0])
# print(e9.text)
time.sleep(2)
elem10=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[3]")
for e10 in elem10:
e_10=re.compile(r"\d+")
num10=e_10.findall(e10.text)
if num10==[]:
num10.append(0)
b=list(map(int,num10))
em10.append(b[0])
# print(e10.text)
time.sleep(2)
elem11=driver.find_elements_by_xpath("//div[@class='WB_handle']/ul/li[4]")
for e11 in elem11:
e11=e11.text
e_11=re.compile(r"(\d+)")
num11=e_11.findall(e11)
if num11==[]:
num11.append(0)
c=list(map(int,num11))
em11.append(c[0])
# print(e11.text)
for i in range(len(elem12)):
for j in range(len(em6_1)):
if em6[i]==em6_1[j]:
# print(em6[i])
em6.remove(em6[i])
em7.remove(em7[i])
em7_1[j]='0'
em6_1[j]='0'
print('[发布时间]',em6[i])
print('[来自]',em7[i])
print('[文案]',em8[i])
print('[转发数]',em9[i])
print('[评论数]',em10[i])
print('[点赞数]',em11[i])
print('\r\n\r\n')
driver.close()
if __name__=='__main__':
username = ("输入用户名")
password = ("输入密码")
url=("https://login.sina.com.cn/")
loginFoc(url,username,password)
time.sleep(3)
keyword=("输入关键词")
url_s=("https://s.weibo.com/")
searchFoc(url_s,keyword)
driver.close()
2.2结果
部分运行结果:

经检查,每个输出的时间,客户端,文案,转发数,评论数与点赞数都是正确对应的。这里由于需要登录才能点击下一页,所以就只爬取了第一页的内容,有兴趣的朋友可以登录之后,爬取所有的博文内容。(可以使用每页的超链接,然后加上一个for循环来实现逐页爬取)