论文笔记:COOKIE: Contrastive Cross-Modal Knowledge Sharing Pre-training for Vision-Language Representati
面向视觉语言表示的跨模态知识共享预训练
- 摘要
- 介绍
- 预训练
-
- 整体结构
- 跨模态对比学习
- 单模态对比学习
- 部分介绍
- 结论
摘要
最近,人们对跨模态预培训的兴趣激增。然而,现有的方法预先训练一个单流模型来学习联合视觉语言表示,这在进行跨模态检索时会受到计算爆炸的影响。在这项工作中,我们提出了对比跨模态知识共享预训练(COOKIE)方法来学习通用文本图像表示。
其中有两个关键设计,一个是视觉和文本编码器上的权重共享transformer ,用于对齐文本和图像语义,另一个是三种对比学习,用于在不同模式之间共享知识。跨模态知识共享极大地促进了单峰表示的学习。
在多模态匹配任务(包括跨模态检索、文本匹配和图像检索)上的实验表明了我们的预训练框架的有效性和效率。我们的COOKIE在跨模式数据集MSCOCO、Flickr30K和MSRVTT上进行了微调,与单流模型相比,仅使用了3/1000的推断时间,从而获得了新的最先进的结果。在图像检索和文本匹配方面也分别提高了5.7%和3.9%。
介绍
跨模态预训练极大地促进了视觉语言领域表征学习的发展。它旨在缩小视觉和语言之间的异质差距[27,11,30]。最新的视觉语言预训练(VLP)方法利用大规模的图像-文本对学习视觉和文本输入的统一表示,极大地提高了V+L任务的性能,如跨模态检索[19,48,12]、图像字幕[46,15]和视觉问题回答[2,1]。本文主要研究多模态检索任务,包括跨模态检索(图像-文本匹配和视频-文本匹配)和单模态匹配(文本匹配和图像检索)。
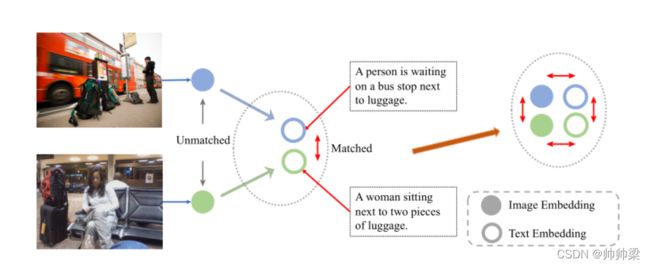
跨模式知识共享的说明。语义相近的图像有时在结构、主题、背景、风格等方面存在差异,导致匹配不准确。通过与对应文本的语义进行匹配,缩小文本在公共空间中的嵌入距离。
人类感知世界的能力并非只有一种。模型预训练也是如此,单纯使用单模监督似乎是不够的。如图1所示,两个具有相同语义的图像可能看起来完全不同。在这种情况下,我们需要采用跨模式的预训练。
单流VLP方法最近被用于跨模态预训练。他们使用多层transformers[45]作为联合编码器。输入是可视标记和文本标记的串联。
然而,这种方法有两个明显的缺点:
a)基于FAST R-CNN的两阶段视觉特征提取非常耗时,可能会丢失一些全局信息。
b) 单流方法需要处理图像和文本标记的串联。这种计算将导致检索任务的推理时间爆炸。
双流方法也常用于跨模式预培训。它们使用视觉路径和文本路径分别对图像和文本进行编码。
这使得跨模式检索的效率很高,但性能非常有限。
有两个明显的限制:a)缺乏跨模态交互削弱了图像和文本的语义对齐。b) 来自跨模态对比学习(CCL)的简单监督失去了单模态编码器从原始图像或文本中学习到的知识。
在这项工作中,我们提出了一个为多模态检索任务设计的新框架:对比跨模态知识共享预训练。我们的COOKIE框架能够利用单流VLP方法和双流方法的优点,同时避免它们前面提到的缺点。该框架主要有两种设计:具有权重共享转换器编码器(WS-TE)的双流视觉语义嵌入结构和跨模态和单模态对比学习方法。
前一种设计是基于WS-TE的双流视觉语义嵌入结构,它加快了跨模态训练和测试,同时加强了图像和文本的语义对齐。更具体地说,COOKIE是以双流方式设计的,因此避免了由单流方法引起的推理时间爆炸。在视觉流中,特征由ResNet而不是更快的RCNN提取。这样,在保持全局视觉信息的同时,避免了巨大的计算开销。为了解决以前的双流方法所缺乏的跨模态交互的缺乏,设计了一个权重共享转换器编码器(WS-TE),以迫使模型更多地关注具有相同语义的标记,从而保证精确的视觉语言对齐。
其次,通过跨模态对比学习、单模态视觉对比学习(VCL)和语篇对比学习(TCL)三种对比学习方式对COOKIE进行优化。与单模态方法相比,跨模态对比预训练分享了预训练图像编码器和文本编码器的知识,例如ResNet和BERT。跨模态知识共享的解释如图1所示。
这两张照片有着相同的语义“一个人拿着行李在等着”,但由于拍摄角度和背景的不同,这两张照片有着很大的不同。在跨模态对比学习的帮助下,在文本嵌入的引导下,图像嵌入被拉近。同时,我们不期望单模态编码器丢失从大规模单模态预训练中学到的太多信息。
因此,添加了VCL和TCL来维护从原始图像和文本中学习到的单模态知识。我们的单一模式目标不同于结构保持损失[47,43]。通过手动搜索模态对内的正模态,它们促进了跨模态语义的对齐。而我们的设计由于自动生成对而更加简单和有效。此外,我们的VCL和TCL还允许视觉和文本编码器保留捕获模态相似性的能力,这有助于完成单模态检索任务。
1.我们提出了一种新的跨模态预训练范式COOKIE。通过特别设计的权重共享变压器编码器(WS-TE),COOKIE提供了双流结构的效率和单流方法的可比性。
2.设计了三个培训前目标,包括跨模态对比学习(CCL)和单模态对比学习(VCL和TCL),以促进多模态检索的跨模态知识共享。
3.该COOKIE在图像文本匹配、视频文本匹配、文本匹配和图像检索等多模式匹配任务上的性能优于以往的方法。
具体而言,我们的COOKIE在Flickr30K和MSCOCO上仅使用3/1000的推断时间,就可以获得与sota方法Oscar[30]相当的结果。
预训练
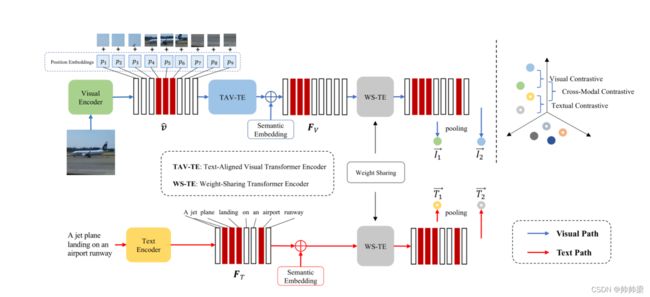
COOKIE的概述。它由两条路径组成,视觉路径和文本路径。 视觉路径包含一个用于提取面片特征的CNN、一个文本对齐的可视化转换器和一个权重共享转换器。文本路径有一个BERT编码器和相同的权重共享转换器。我们设计了三个对比学习目标。
在本节中,我们将详细介绍视觉语言表达的跨模态知识共享对比预培训。在第3.1,我们描述了模型架构,该架构由图像编码器、文本编码器、文本对齐视觉转换器编码器和权重共享转换器编码器组成。在第3.2、介绍了以跨模态对齐和知识转移为目标的跨模态对比预训练。在第3.3、详细介绍了单模态对比预训练。
整体结构
结构如图2所示。以往的视觉语言预训练方法[34,11,30]是以Faster RCNN[41]提取的图像区域特征与文本词嵌入的拼接作为输入,并用基于变压器的模型[17]进行处理。与它们不同的是,我们直接使用ResNet[21,35]和BERT[17]分别对图像和文本进行处理。具体来说,给定一个图像-文本对(V, C),目标是学习个人嵌入,可用于多模态检索。
视觉表征学习:我们直接使用ResNet进行视觉特征提取。以往的VLP方法利用自底向上和自顶向下(BUTD)注意来提取区域特征,其结果是两个阶段的训练和推理过程。我们的端到端方式保证了效率,并且比BUTD方法考虑了更多的全局特性。
我们移除ResNet[21]或ResNeXt[35]的最后一个全连接层,并在池化之前平坦输出特性,接下来是一个完全连接的层。为了学习图像中特征的相对位置,我们添加了位置嵌入。输出的视觉特征是
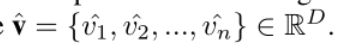
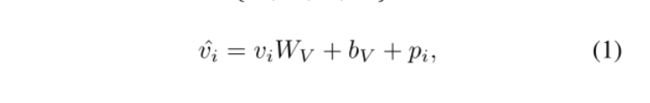
然后 W v W_v Wv和 b v b_v bv是全连接层的超参数, p i p_i pi是patch i i i的位置编码。
patch:在CNN学习训练过程中,不是一次来处理一整张图片,而是先将图片划分为多个小的块,内核 kernel (或过滤器或特征检测器)每次只查看图像的一个块,这一个小块就称为 patch,然后过滤器移动到图像的另一个patch,以此类推。
D v D_v Dv是视觉特征维度,
文本表征学习:我们将预训练的BERT基模型[17]最后一层的输出作为文本特征。我们在特征中添加了文本语义嵌入向量。文本特征表示为 t = t 1 , t 2 , . . . , t m ∈ R D T t={t_1, t_2, ..., t_m} ∈R^{D_T} t=t1,t2,...,tm∈RDT,FC将字特征编码到与图像特征相同的空间中。输出文本特性是 F T = { f T 1 , f T 2 , . . . , f T m } ∈ R D F_T=\{{f_{T_1}, f_{T_2}, ..., f_{T_m}}\} ∈R^D FT={fT1,fT2,...,fTm}∈RD.
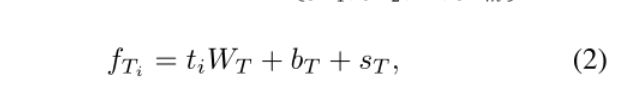
其中 w t ∈ R D T × D w_t∈R^{D_T×D} wt∈RDT×D b t ∈ R D b_t∈R^{D} bt∈RDin eq .2为FC参数。我们在特性中添加了一个文本语义嵌入向量 s T s_T sT。
Text-Aligned Visual Transformer:文本对齐可视转换器,由于CNN中使用的卷积是局部算子,而BERT中使用的变换层是全局算子,因此从CNN中提取的视觉特征可能与文本特征具有不同的分布。为了对齐视觉特征和文本特征的分布,我们添加了一个文本对齐的视觉转换器编码器(TA V-TE)。TA V-TE为图像端提供了一个全局注意力计算(这里没有说他是怎么用的啊)。本文中的变压器编码器(TE)遵循标准定义[45]。我们在特征中添加了视觉语义嵌入向量。

Weight-Sharing Transformer:为了提示图像和文本关注相同的语义,我们在网络顶部添加了一个weightsharing transformer编码器(WS-TE)。WS-TE包含一个多头自我注意过程和一个前馈网络,使得输入标记更加关注显著区域(这里也只说了实现了什么,没说怎么实现啊)。最初在CNN中,在卷积核之间共享权重不仅可以减少参数,还可以实现平移等变[26]。也就是说,无论图像如何翻译,网络都会提取相同的特征。样,对于图像和文本,参数共享使自我关注层能够为图像和文本的相似语义提供密切关注值。由于我们的目标是对齐视觉和文本表示,如果图像和文本的相似语义被赋予更大的权重,那么最终的表示也将更好地对齐。
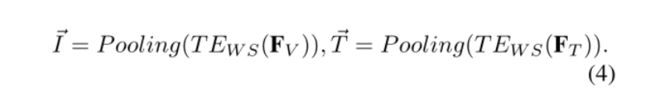
跨模态对比学习
跨模态对比学习在跨模态检索中起着关键作用。它学习图像和文本在语义上对齐的公共子空间。同时,这种学习过程可以实现跨模态的知识转移,即从图像到语言理解,反之亦然。
图像和文本编码器以及权重共享TE使用InfoNCE loss[36]进行优化,InfoNCE loss广泛用于对比学习。
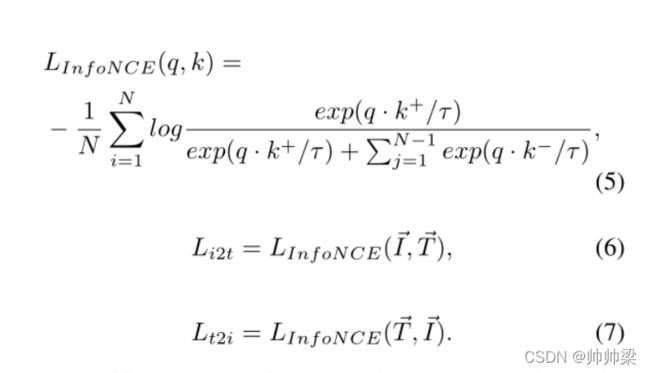
单模态对比学习
跨模态对比学习促进了图像编码器和文本编码器之间的知识共享。但是,我们不希望编码器丢失太多从单模态数据中获取的信息。因此,我们设计了视觉对比学习和文本对比学习,以保持单模态编码器处理自身模态数据的能力。
视觉对比学习:图像自监督学习可以有效地提高深层神经网络理解图像的能力[8,9,10]。在我们的框架中,我们利用视觉对比学习来增强图像编码器对图像的理解,同时接受来自文本的知识。原始图像的两个增强作为输入,目标是使两个学习的表示更接近。具体来说,我们直接最小化正对之间的距离,同时最大化负对之间的距离。给定原始图像V,图像编码器和权重共享TE。我们优化了visual InfoNCE 损失。
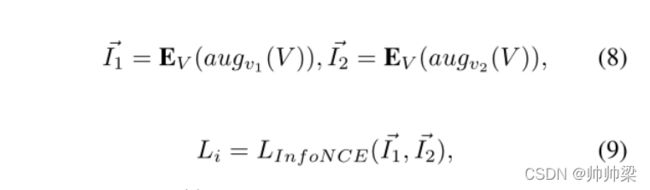
augv(·)代表图像增强,对于我们的方法,图像增强包括随机裁剪、翻转、颜色抖动、高斯模糊和颜色下降。
文本对比学习:对于文本,自我监督学习通常由屏蔽语言建模(MLM)[17]组成,而不是由对比学习组成。在我们的模型中,使用了随机屏蔽、替换、删除等方法来增强文本。这样的随机操作可以增强模型的鲁棒性。文本编码器在接受来自图像的知识的同时,保持对句子语义特征的关注。图像也一样,我们优化了文本编码器通过权重共享TE通过InfoNCE损失。
给一个原始的句子C
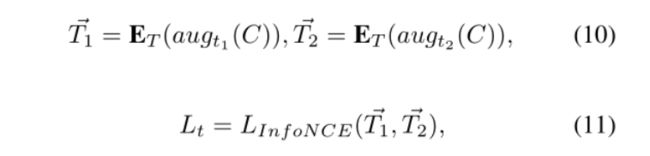
avg t(·)表示文本扩充
COOKIE的整体培训前目标定义如下:
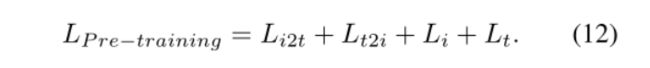
(上面两个对比学习说明了,常规意义的对比学习都是使用的其他方法而不是我们提出的对比学习,我们在两方面都使用对比学习来操作,感觉就是换了一个损失,提出一个对比学习方法)
部分介绍
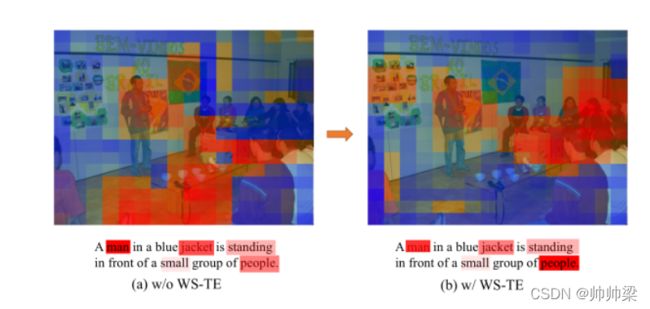
重量共享变压器编码器的效果说明。在WS-TE中,图像和文本专注于相同的语义。
我们在图中可视化WS-TE学到的注意力。从图中可以看出,如果没有WS-TE(左边的图),图像和句子注意的语义是不同的。在文本中,“人”,“夹克”和“人”是突出的,而在图像中,更多的关注无关紧要的“旗帜”和“桌子”。使用WS-TE(右图),图像和文本倾向于强调相同的语义,即“人”和“一群人”。
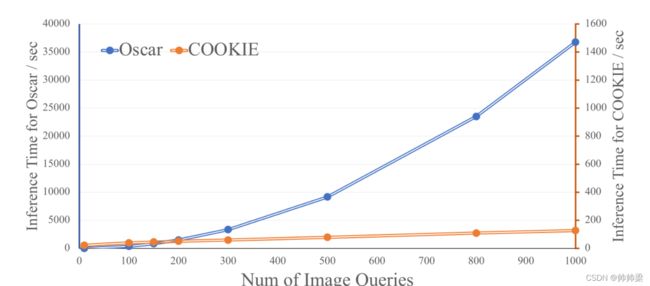
COOKIE是一种没有跨模式交互的双流方法,大大提高了图像文本检索的速度。我们在Flickr30K测试集上进行实验,记录推断时间(特征提取+相似度计算)。如图4所示,像Oscar[30]这样的单流方法的时间复杂度为O(n2),而我们的模型的时间复杂度为sto (n)。
结论
在本文中,我们提出了一种新的Crontrastive-CrossModal-Knowledge Sharing-Pre-training(COOKIE),用于学习下游匹配任务的通用分离视觉和语言表示。我们设计了一个权重共享transformer encoder,以更好地对齐视觉和文本语义,并使用5.9M的图像-文本对进行跨模态对比学习和单模态对比学习的预训练模型。COOKIE在单模态匹配任务上设置了新的最先进的结果,同时在跨模态检索上仅用3/1000的推理时间就获得了可比的结果。