AGI&意识科学每周速递 | 2022年11月第四期
AGI&意识科学每周速递 | 2022年11月第四期
心识研究院 Mindverse Research 2022-11-28 17:00 发表于上海
收录于合集#AGI&意识科学每周速递24个

本周主要内容:程序辅助语言模型 PAL、AI 外交官 CICERO、视觉语言图灵测试、NLP 的持续学习、胎儿的大脑皮层复杂性、意识理论的演化、语言模型的意识、 扩展整合世界模型理论 IWMT
AGI 每周速递
[1] PAL:程序辅助语言模型
标题:PAL: Program-aided Language Models
链接:https://arxiv.org/abs/2211.10435
作者:Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, Graham Neubig
摘要:
大型语言模型(LLM)最近在测试时提供了几个例子(few-shot prompt),显示出令人印象深刻的执行算术和符号推理任务的能力。这种成功在很大程度上可以归功于 prompt 推理的方法,例如 chain-of-thought(COT),这些方法使用 LLM 通过将问题分解为步骤来理解问题描述,以及解决问题的每个步骤。虽然 LLM 似乎擅长这种循序渐进的分解,但 LLM 经常在解决方案部分犯逻辑和算术错误,即使问题被正确分解。本文提出了程序辅助语言模型(PAL):一种新的方法,它使用 LLM 来理解自然语言问题并生成程序作为中间推理步骤,但将求解步骤转移到编程运行时,如 Python 解释器。对于 PAL,将自然语言问题分解成可运行的步骤仍然是 LLM 唯一的学习任务,而解决问题则委托给解释器。我们从 BIG-Bench Hard 和其他基准测试中实验了12个推理任务,包括数学推理、符号推理和算法问题。在所有这些自然语言推理任务中,使用 LLM 生成代码并使用 Python 解释器进行推理会产生比更大的模型更准确的结果,并且我们在所有 12 个基准测试中设置了新的最先进的结果。例如,当模型只被允许一次解码时,使用 CODEX 的 PAL 在 GSM 数学字问题基准上达到了最先进的 few-shot 准确率,在 COT 提示的情况下绝对超过了 PaLM-540B 8%。在来自 bit-bench 基准的三个推理任务中,PAL 的性能比 COT 高出 11%。在本文创建的更具挑战性的 GSM 版本 GSM-Hard 上,PAL 的表现绝对比 COT 高出 40%。
[2] AI 外交官 CICERO
标题:Human-level play in the game of Diplomacy by combining language models with strategic reasoning
链接:https://doi.org/10.1126/science.ade9097
作者:Anton Bakhtin, Noam Brown, Emily Dinan 等
摘要:
尽管在训练人工智能系统模仿人类语言方面取得了很大进展,但构建在交互环境中使用语言故意与人类交流的代理仍然是一个重大挑战。本文引入了第一个在外交中达到人类水平的 AI 代理 CICERO,这是一款既涉及合作又涉及竞争的战略游戏,强调七个玩家之间的自然语言谈判和战术协调。CICERO 通过从对话中推断玩家的信念和意图,并为追求其计划而生成对话,将语言模型与规划和强化学习算法相结合。在一场匿名的在线外交联盟的 40 场比赛中,CICERO 的平均得分是人类玩家的两倍多,在玩了不止一场比赛的参与者中排名前 10%。
[3] 人类还是机器?视觉语言图灵测试
标题:Human or Machine? Turing Tests for Vision and Language
链接:https://arxiv.org/abs/2211.13087
作者:Mengmi Zhang, Giorgia Dellaferrera, Ankur Sikarwar 等
摘要:
随着人工智能算法越来越多地参与曾经是人类独有的日常活动,我们不可避免地被要求考虑机器在多大程度上真的像我们。为了解决这个问题,作者求助于图灵测试,并系统地对当前人工智能的模仿人类能力进行基准测试。本文建立了一种在类似图灵的测试中评估人与机器的方法,并系统地评估了一组具有代表性的选定域、参数和变量。这些实验包括测试 769 名人类代理,24 名最先进的人工智能代理,896 名人类法官和 8 名人工智能法官,在包括视觉和语言模式的 6 项任务中进行 21,570 次图灵测试。令人惊讶的是,结果显示,目前的人工智能距离能够在复杂的视觉和语言挑战中模拟不同年龄、性别和教育水平的人类法官并不遥远。相比之下,简单的人工智能裁判在区分人类答案和机器答案方面优于人类裁判。这里介绍的经过精心策划的大规模图灵测试数据集及其评估指标为评估代理人是否为人类提供了有价值的见解。拟议的在当前人工智能中对人类模仿能力进行基准的提法,为研究界将图灵测试扩展到其他研究领域和条件铺平了道路,相关资源可以参考:https://tinyurl.com/8x8nha7p
[4] 自然语言处理任务的持续学习研究综述
标题:Continual Learning of Natural Language Processing Tasks: A Survey
链接:https://arxiv.org/abs/2211.12701
作者:Zixuan Ke, Bing Liu
摘要:
持续学习是一种新兴的学习范式,其目的是模仿人类不断学习和积累知识的能力,而不是忘记以前学到的知识,并将知识转移到新的任务中,以便更好地学习。本文综述了连续学习在自然语言处理领域的最新进展。它涵盖(1)所有 CL 设置以及现有技术的分类。除了处理遗忘,它还关注(2)知识迁移,这对 NLP 特别重要,但是(1)和(2)在现有的综述中均未提及。最后,本文还讨论了未来的发展方向。
意识科学 每周速递
[1] 大脑皮层复杂性随着人类早期的发育成熟而降低
标题:The complexity of event-related MEG signals decreases with maturation in human fetuses and newborns
链接:https://doi.org/10.1101/2022.11.21.517302
作者:Joel Frohlich, Julia Moser, Pedro A. M. Mediano, Hubert Preissl, Alireza Gharabaghi
摘要:
皮质熵或者说「复杂性」(complexity)是意识的一个标志,但是目前尚不清楚,它在人类早期发展中是如何演变的。为了检验皮层信号的熵在接近出生时增加的假设,本研究首次将胎儿皮质熵与成熟(maturation)联系起来。研究者从具有感知意识的胎儿和新生儿样本中采集了脑电图记录。利用皮层对听觉不规则的反应,研究者用多种测量方式计算了信号熵。结果与其假设相反,胎儿和新生儿的皮层熵随着成熟而明显下降,最强烈的效应发生在两组样本中 4-10 Hz 的置换熵(permutation entropy)。在胎儿和新生儿中,置换熵的下降是由振幅变化驱动的,而相位及其与振幅的相互作用则驱动了熵的增加,这可能与意识有关。这些结果为未来围产期意识的测量和新的子宫内神经发育障碍风险评估奠定了基础。
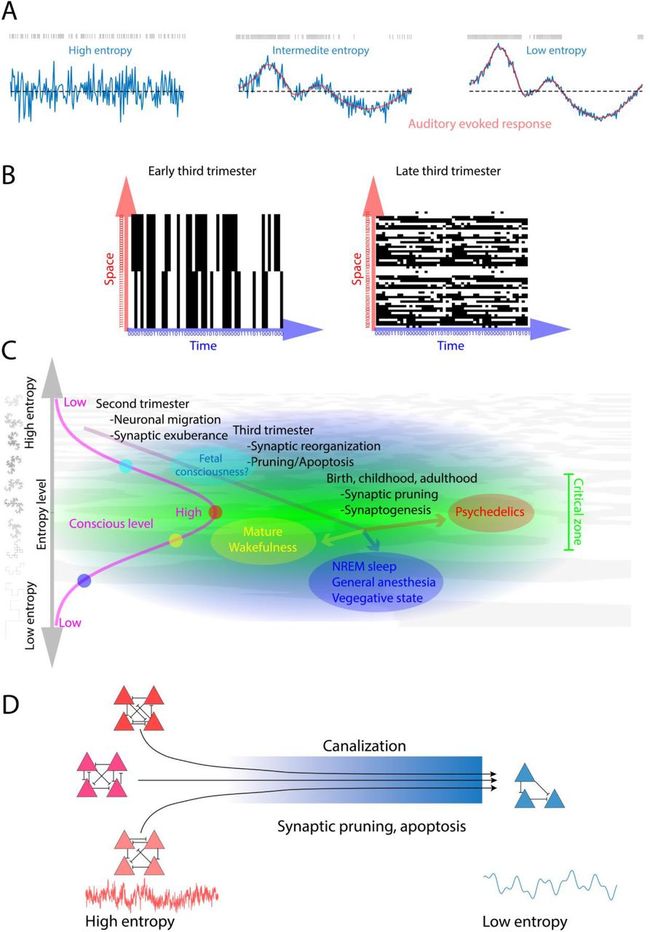
对胎儿皮质熵随子宫内成熟而下降的可能解释。(A) 胎儿的皮质熵可能随着胎龄的增长而下降,这是因为对听觉音调的诱发反应的成熟,这会对皮质信号施加结构,从而使其熵最小。这种情况解释了熵驱动的事件相关场(ERFs)的减少,但却没有解释非 ERF 驱动的变化。即使在减去模拟听觉 ERF 的皮质反应模板(CRTs)后,我们发现皮质熵随成熟度下降的现象仍然存在;因此,熵的下降似乎部分或大部分是非 ERF 驱动的。(B)熵下降的结果也可能是令人困惑的,因为它排除了皮质反应的空间维度,而这是将扰动复杂性(perturbational complexity)与成年人的意识联系起来所必需的。有可能的是,虽然胎儿的时间皮质熵随着胎龄的增加而减少,但空间皮质熵的更大变化可能发生在相反的方向上(即增加)。(C) 本研究结果可以在熵脑假说(EBH)的背景下理解,该假说预测,存在于意识全局最佳水平(即临界点)之上的超熵水平应该与意识水平的下降有关;因此,向这个临界点的熵的下降应该与意识水平的提高相对应。然而,研究者并没有在年轻的胎儿身上发现更多的噪音(即随机性)证据,因此对这种解释表示怀疑。在此处图表中,纵轴对应的是熵水平,粉红色的曲线对应的是意识水平,绿色突出的区域代表的是意识的最佳临界区。(D) 最后,胎儿熵在成熟过程中的下降可能与意识无关。相反,它可能反映了发育过程,如细胞凋亡和突触修剪,减少神经回路排列方式(即熵)的数量。在 D 图中,多种神经回路配置(左)可能是在管化过程之前,而管化过程将回路带向一个由基因决定的表型(右)。
[2] 意识理论的演化
标题:The Evolution of Consciousness Theories
链接:https://europepmc.org/article/PPR/PPR572590
作者:Farhadi A
摘要:
意识通常被认为是一种对环境和自我的觉知状态。尽管它在人类的生活中无处不在,但对这一概念的理解是颇具挑战性的,这就产生了几种试图解释意识性质的理论,以及意识的困难(hard)和简单(soft)问题。但事实上,这些理论所定义的意识的边界是一个连续讨论的主题,特别是考虑到最近人工智能(AI)的进展。其中一些理论认为意识是一种简单的信息整合,而另一些理论则声称在整合过程中需要有一个主体代理,才能使一个实体被视为有意识的。有些理论认为意识是一个有等级的实体,有些理论则将意识等同于意识的内容。在这项工作中,作者对意识的主要理论进行了回顾和比较,重点是觉知、注意力和自我感。这些发现被理解为与人工智能有关,以确定是什么使人工智能与自然智能不同。

意识和自我意识是自然智能中 ABCS 和 DSIA 两种心理功能的结果
[3] 去人格化的自然语言模型: 语言模型是有意识的吗?
标题:Deanthropomorphising NLP: Can a Language Model Be Conscious?
链接:https://arxiv.org/abs/2211.11483
作者:Matthew Shardlow, Piotr Przybyła
摘要:
这项工作旨在为最近关于 LaMDA(一种基于 Transformer 模型架构的预训练语言模型)是有生命的说法讨论提供一个回应。由于类似模型被广泛使用,这一说法如果得到证实,将在自然语言处理(NLP)界产生严重影响。作者通过整合信息理论分析 Transformer 架构进行证明,得出观点是,这样的语言模型不可能是有知觉的,或是有意识的,特别是 LaMDA 与其它类似的模型相比,没有表现出任何的进步,从而之符合 IIT 的条件。论文认为关于意识的说法是在 NLP 报告中使用拟人化语言广泛趋势的一部分。但不管这些说法的真实性如何,目前是一个很好的时机来评估语言建模的进展,并考虑这类工作的伦理意义。为了使这项工作对 NLP 社区以外的读者有所帮助,作者还介绍了语言建模的必要背景。
[4] 扩展整合世界模型理论(IWMT):对意识未来的影响(更新版)
标题:Integrated World Modeling Theory (IWMT) Expanded: Implications for the Future of Consciousness
链接:https://doi.org/10.3389/fncom.2022.642397
作者:Adam Safron
摘要:
拓展整合世界模型理论(IWMT)是一种关于意识的整合理论,它使用自由能量原理(Free energy principle)和主动推理(FEP-AI)框架来综合整合信息理论(IIT)和全局神经工作空间理论(GNWT)两种见解。在这篇文章中,作者首先回顾了有助于IWMT整合视角的哲学和神经系统原理,然后描述大脑的预测处理模型及其与机器学习架构的联系,特别强调自编码器(感知和主动推理)、Turbo 码(为多模态整合和协同推理建立共享的潜在空间)和图神经网络(空间和体态建模与控制),通过探索如何将各种模块和工作空间评估为整合信息的复合体和迭代贝叶斯模型选择的舞台,来考虑 IIT 和 GNWT 的未来方向。
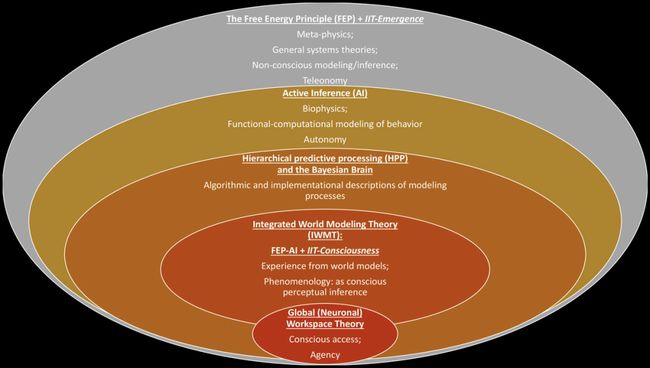
FEP-AI、IIT、GNWT 和 IWMT 之间的交叉关系

从现象学的对应关系、计算(功能)、算法和实现层四方面来描述人脑