Transformer优化之稀疏注意力
最近要开始使用Transformer去做一些事情了,特地把与此相关的知识点记录下来,构建相关的、完整的知识结构体系。
以下是要写的文章,文章大部分都发布在公众号【雨石记】上,欢迎关注公众号获取最新文章。
- Transformer:Attention集大成者
- GPT-1 & 2: 预训练+微调带来的奇迹
- Bert: 双向预训练+微调
- Bert与模型压缩
- Bert与模型蒸馏:PKD和DistillBert
- ALBert: 轻量级Bert
- TinyBert: 模型蒸馏的全方位应用
- MobileBert: Pixel4上只需40ms
- 更多待续
- Transformer + AutoML: 进化的Transformer
- Bert变种
- Roberta: Bert调优
- Electra: 判别还是生成,这是一个选择
- Bart: Seq2Seq预训练模型
- Transformer优化之自适应宽度注意力
- Transformer优化之稀疏注意力
- Reformer: 局部敏感哈希和可逆残差带来的高效
- Longformer: 局部attentoin和全局attention的混搭
-Linformer: 线性复杂度的Attention - XLM: 跨语言的Bert
- T5 (待续)
- 更多待续
- GPT-3
- 更多待续
Overall
和Linformer,Longformer类似,Sparse Attention也是为了解决Transformer模型随着长度的增加,Attention部分所占用的内存和计算呈平方比增加的问题。
但Sparse Attention在时间上比Linformer,Longformer等要早,所以效果上并没有它们好。而另一点与其他模型不同的是,论文[1]是在图像、音乐、文本上分别做的实验,而非其他论文所使用的的GLUE task和QA task。
图像生成问题
Transformer的Decoder部分(应用在GPT上)是一个自回归模型,即基于前面的context去生成下一个位置上的值,然后生成的值也被纳入context中去做下一次预测,以此类推。
依照这个模式,可以生成的不仅仅是文本,还可以是图像。可以把图像的像素点按照从上到下从左到右的方式当成一个序列,然后在序列上去做自回归。
论文首先构造了一个128层的全注意力网络,并在Cifar10生成问题上进行了训练。如下图所示,底部的黑色部分表示还没有生成的部分,白色凸显的部分则是注意力权重高的地方。下图是比较低的层次的注意力,可以看到,低层次的时候主要关注的还是局部区域的部分。

而在第19层和20层,Attention学习到了横向和纵向的规律。

进一步,还有可能学习到和数据本身相关的attention。比如下图,第二列第二张学习到了鸟的边缘。

但无论如何,注意力权重高的地方只占一小部分,这就为稀疏注意力提供了数据上的支持。
Self-Attention的分解
为了实现注意力,将计算Attention的公式进行重写。如下图所示,重写后的公式定义了一个集合S,里面存储的是需要关注的位置的索引。而同样的,Wq, Wk, Wv是针对q,k,v的矩阵。
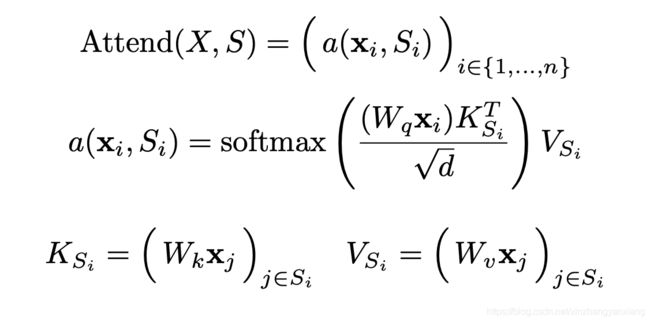
当定义S={j: j<=i}的时候,和正常的Attention计算没有区别,因为都是全注意力。
而分解后的注意力则是:
- 有p个头的注意力
- 对于每个头,都定义Ai(m) 是S={j: j<=i}的子集。
而对于A的定义,期望设计出一些模式,使得 |Ai|正比于sqrt(n, 1/p)。
同时,对于A的定义,虽然直接的attention是稀疏的,但是期望某个位置可以经过一些路径attend到之前所有位置。同时路径长度不超过p+1,这样保证所有原本在全注意力上能够传递的信号在稀疏注意力的框架下仍然可以有效传递,也把时间和空间复杂度变为了: O(n*sqrt(n, 1/p))
稀疏注意力机制
论文帮助我们定义两种符合上述条件的注意力机制。第一种是定义两个这样的注意力头:
- Ai(1) = {t, t+1, … , i} for t = max(0, i-l)
- Ai(2) = {j: (i-j) mod l = 0}
其中l=sqrt(n)。
这个模式如下图所示,被称为strided attention。这种模式在有规律的数据上很有用,比如图像,比如音频。

第二种,类似的,定义两个注意力头:
- Ai(1) = {j: floor(j/l) = floor(i/l)}
- Ai(2) = {j: j mod l ∈ {t, t+1, …, l}},其中t=l-c且c是超参数。
这种被称为fixed attention。一般情况下,l取值为{128, 256}, c取值为{8, 16, 32}。
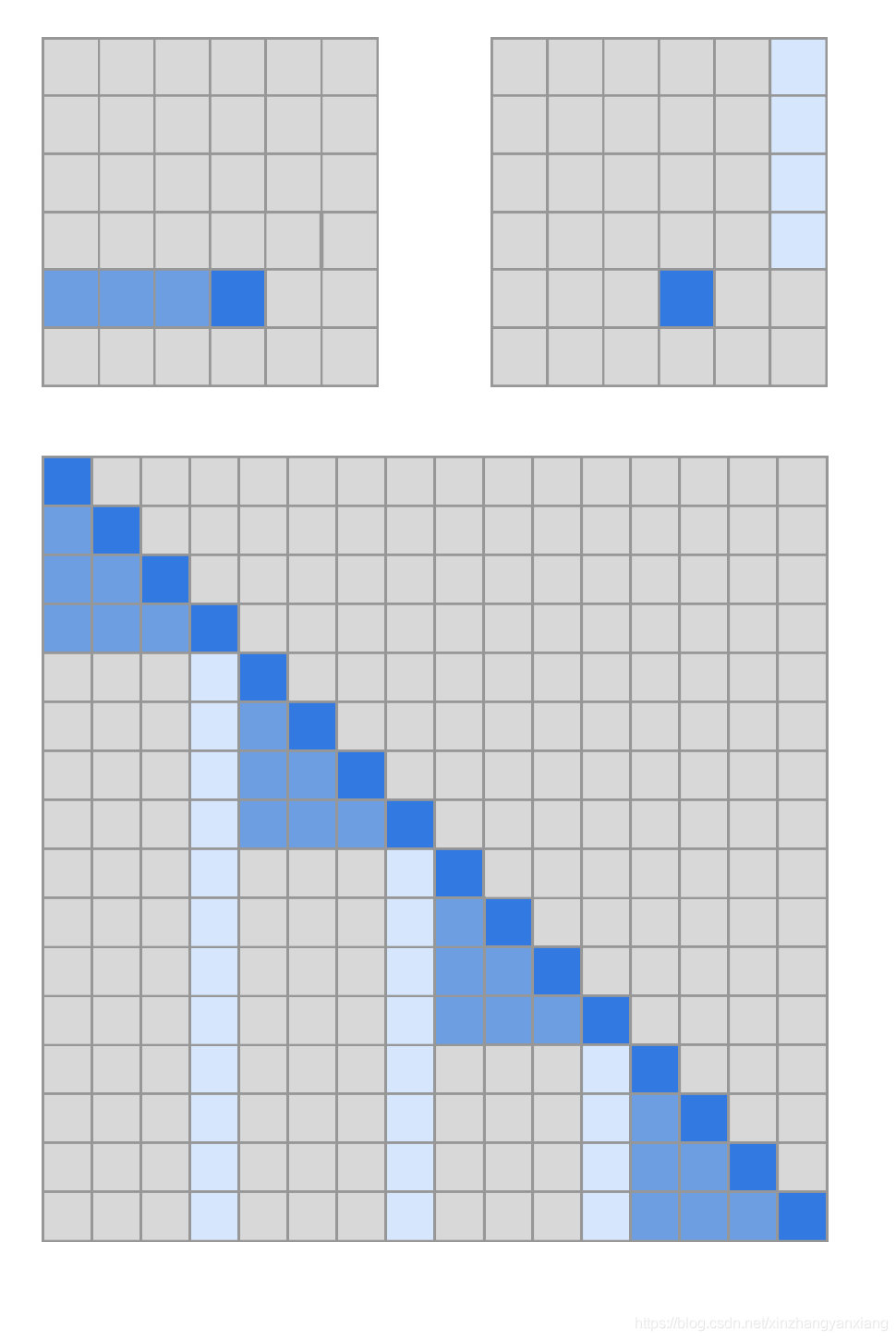
稀疏注意力的组合
一个直接的方法来使用稀疏注意力是在每个残差块使用同样的稀疏机制,在不同的块使用不同的。
另一种方式则是在每个残差块使用组合的稀疏注意力,组合的方法则是把不同的A合并起来。
稀疏注意力的计算
上述所提到的稀疏注意力可以被高效在GPU上进行计算,但是需要做一下操作:
- 切片和聚合
- 自实现的GPU kernel来进行快速计算。
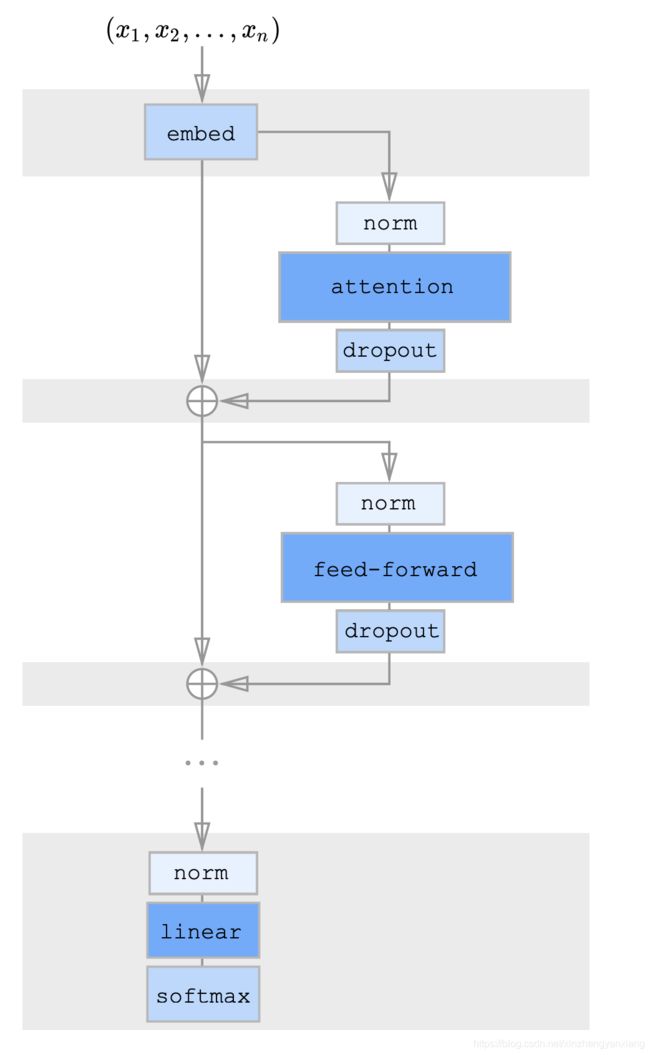
深度残差Transformer
深层次的Transformer训练起来十分困难,因为使用残差的方式会比较好。
公式如下,其中第k层是由k-1层加上当前层结果得到的。
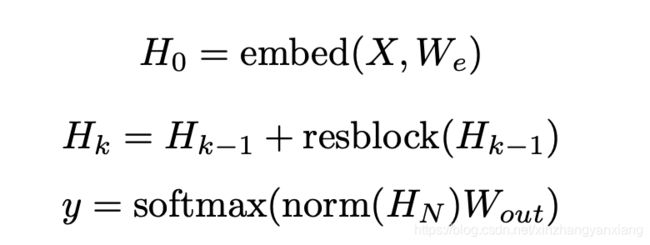
残差块的内部则是这样计算的。

总结与思考
作为解决注意力平方问题的早期论文,论文从图像生成的问题上揭示了attention的原罪,那就是其实不需要那么密集的注意力,Top-k的注意力已经足够可以保证效果了。而无论是Reformer还是Longformer,都是在这一方向上的扩展。
勤思考,多提问是Engineer的良好品德。
- 试解释GPU中如何实现并行化,并实现自定义的一个计算内核。
- 上述的两种稀疏注意力,你认为哪种在文本上应用的好,为什么?
后续答案将会发布在公众号【雨石记】上,欢迎关注。

参考文献
- [1]. Child, Rewon, et al. “Generating long sequences with sparse transformers.” arXiv preprint arXiv:1904.10509 (2019).