京东基于时序知识图谱的问答系统

分享嘉宾:商超博士 京东硅谷研究院 研究员
编辑整理:张存旺 北航杭州创新研究院
出品平台:DataFunTalk
导读:本文将分享Temporal Knowledge Graphs方向的一个最新尝试,如何在时序知识图谱上去做问答系统,主要包括以下几部分:
时序知识图谱背景介绍
基于时序知识图谱的问答系统中的问题
TSQA方法
实验结果分析
01
时序知识图谱背景介绍

首先介绍一下时序知识图谱的概念,时序知识图谱本质上是想把传统的静态知识图谱在时间维度上做一个延伸。大部分人所研究的知识图谱集中在静态知识图谱领域,这类知识图谱由三元组关系组成,其中包含着点和边,但是很多图谱其实还隐含着一些动态信息,比如点上的时间变化、边上的时间变化,本次分享中所关注的主要是知识图谱里边的时间变化。
以上图为例,如果边上带有时间信息,那么可以基于边上的时间将图谱拆分成时间维度上的多个图,相当于是多个静态知识图谱在时间维度上进行串联,后续我们的关注点就是时序知识图谱的问题研究。

Temporal Knowledge Graphs跟传统的知识图谱相比,多了额外的信息,原来的知识图谱中的每个表示都是三元组,而时序知识图谱中的每个表示则是一个四元组,不仅包含头实体、尾实体和关系,同时还有关系所成立的时间点或者时间范围。
举例来说,对于奥巴马是美国总统这个事实(fact),只有在2009-2017这个时间段成立,并不是在所有的时间段都成立,所以说时序知识图谱中的事实是有时间依赖性的,对于事实的时间考虑是非常重要的。当我们提出一个问题时,需要了解具体的发生时间才能很准确找到我们想要的那个尾实体,所以如何建模时序知识图谱中的时间是一个非常难的问题。

下面我会介绍时序知识图谱中表示学习以及关系预测任务是如何去做的。
这些方法可以分为两类,第一类方法是将时序知识图谱中的四元组拆分成基于时间的三元组,再用基于三元组的建模方法来实现对时序知识图谱的建模。在这类方法中我举两个例子,第一个例子是基于时间变换的方法,HyTE这篇文章中把每一个时间都映射到一个超平面,相当于不同的时间点都会映射成不同的超平面,然后在每个超平面上建模关系其实就是对三元组关系的建模。将这个逻辑进行拓展之后可以得到第二个例子,将图做成切片状的形式,原本的时序知识图谱是一个非常大的图,但是从每个时间点来看其实是一个子图。在一个时间段内,并不是所有的边都成立,我们将不同时间段内成立的边分别挑出来就可以得到基于时间变化的多个子图。Temp这篇文章中就是这样拆分成多个子图的,然后把每个子图通过GNN做一次卷积,再基于RNN建模多个图直接的时间顺序,将GNN的结果连接起来,这样的方法不仅考虑了空间维度,还有时间维度上的表示学习。
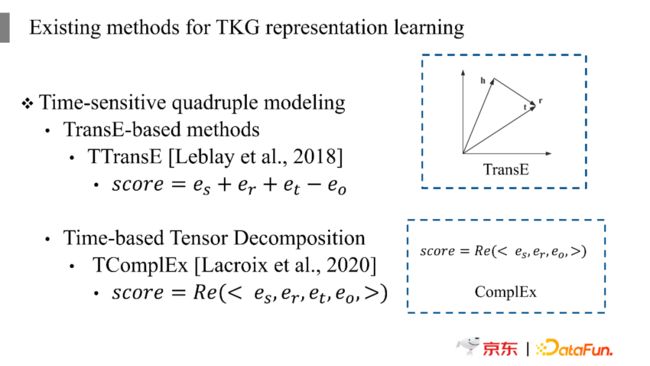
第二类方法思路不一样,没有将四元组转换为三元组,而是直接对四元组进行建模,在这类方法中有两种角度来做。第一个角度比较简单,可以参考TransE中的方法,在TransE中一个头实体经过一个关系(Relation)转换后能够到达对应的尾实体。将这个概念拓展到四元组关系上,我们可以在头实体(![]() )和关系(
)和关系(![]() )之外再加一个时间(
)之外再加一个时间(![]() ),使其与尾实体的表示(
),使其与尾实体的表示(![]() )相等,这是最直接的建模四元组关系的方法。除此之外还有更复杂的方法,基于Tensor Decomposition的双曲空间变换,比如对于三元组可以用ComplEx来对三个复数做乘积,再取其实数部分作为函数的输出结果,这种思路也可以在四元组上进行拓展,就变成了TcomplEx,这类方法相对来说比较新颖并且简单易用。
)相等,这是最直接的建模四元组关系的方法。除此之外还有更复杂的方法,基于Tensor Decomposition的双曲空间变换,比如对于三元组可以用ComplEx来对三个复数做乘积,再取其实数部分作为函数的输出结果,这种思路也可以在四元组上进行拓展,就变成了TcomplEx,这类方法相对来说比较新颖并且简单易用。
总结而言,关于如何学习时序知识图谱的表达主要就是这两大方向,可以对三元组建模再基于时间串联起来,也可以直接对四元组进行建模。
02
基于时序知识图谱的问答系统中的问题
现在我们已经了解了什么是时序知识图谱,以及如何去学习时序知识图谱的Embeddings,接下来需要探索如果在时序知识图谱上做问答系统会遇到什么样的问题。

探索基于时序知识图谱的问答系统,首先需要来看一下这里的时序问题或者时间相关的问题是什么样子的。
这些问题大致上可以分为两类,第一类是比较简单的问题,比如表格中的Simple Time,问的是时序知识图谱中一个四元组里所缺失的时间,假如问题是“奥巴马是在哪一年担任美国总统的?”,问答系统需要把对应的时间找出来或者预测出来。当然四元组中缺失的也可能是个实体,这是Simple Entity问题,需要预测的对象是实体,比如在知道头实体、关系、时间的情况下,问答系统需要告诉我们对应的尾实体是哪个。这两种都是简单的问题,因为他们只是一跳关系,是基于一个四元组来回答问题。
除此之外,我们会遇到一些更难的问题,这里称之为复杂问题。在上表中将复杂问题分为3种:Before/After类问题是想了解一个事情之前或者之后发生的事件,需要对应事件的内容或者与问题相对应的信息作为答案,这类问题中需要考虑的时间变化是向前或者向后;First/Last类问题是一个比较型问题,比如当美国总统的人有很多,那第一个当美国总统的是谁呢?问答系统需要在一个大的时间段内找到第一个是谁,即最早的时间点的美国总统是谁。再举一个例子,比如问梅西第一场比赛是在哪个球队踢的,需要先找到最早的时间点,然后再去做推理预测,最终找到对应的答案。对于Time Join类问题,有时候会涉及到两个事实,比如二战和美国总统这两个事实,他们的时间区间上会有交叉,而我们想要的就是交叉时间点的事实信息,如果所找到的交叉时间点比较准确,那么就能比较好地回答问题。由于回答这些问题需要时间推理,所以复杂问题会比较难解决。

我们通过一个例子来解释如何理解复杂问题并且如何在知识图谱里寻找答案。在这个例子中,我们想问二战之前的美国总统是谁,基于这个问题首先会根据“二战”,“美国总统”这两个关键词去时序知识图谱中做检索来减小答案搜索空间。因为一个时序知识图谱是非常大的,包含几百万、几千万的节点,没必要去所有的节点中寻找答案,只需要看跟当前问题相关的节点就可以了。根据二战和美国总统节点,结合其相关节点从时序知识图谱中抽取子图来进行下一步的搜索。
第二步在对问题进行分析的时候,会发现这是一个Before问题,涉及到“二战之前”的一个逻辑推理,我们需要找到二战,并了解二战所发生的时间范围(这里是1939年-1945年),其次还需要知道Before相当于是在时间轴上的操作,需要的是1939-1945这个时间段之前的时间,大概是1938年这个时间,基于找到的时间点,关键词“美国总统”和“谁是美国总统”这个关系去时序知识图谱中进行事实查询,可以发现当时Franklin是美国总统,也就是我们最终想要的答案。
在此过程中我们可以看到,问答系统是需要通过多步来一点点缩减搜索空间和做时间推理,基于推理出来的时间再去做预测,所以是一个多步推理的过程,这是解决时序知识图谱问答中复杂问题的基本思路。

想要更好地解决时序知识图谱问答中的复杂问题场景,就需要解决三个小问题:
理解输入的问题,并且推测问题中隐含的时间是什么。
如何建模时序知识图谱中的时间点和时间线。
时间表达不一致:在时序知识图谱中的时间是一个值或者一个时间范围,比如1939年是一个值,但是在问题中提到的时间往往是一段文字描述,比如包含Before的时间描述,所以如何学习其中的关系,对时间以及时间的限制条件进行建模,是一个非常难且重要的问题。

接下来介绍ACL2021上的一篇文章,关于在时序知识图谱中的问答。这篇文章的逻辑比较简单,就是把时序知识图谱中的所有关系都映射到一个新的空间中,相当于在Embedding空间做预测,首先在前半部分会利用TComplEx方法来获取时序知识图谱中的实体、关系,以及时间的Embedding表示,然后对于用户输入的问题,不管问题难不难,都用BERT这类语言模型去获取问题的表达,将其映射到相同的空间中去,然后在这个空间上将问题的表示与时序知识图谱中的表示逐个计算相似度来预测时间或者实体。

刚才介绍的方法以及其他一些相关文章的方法都存在一些没有考虑到的方面:
无法处理复杂问题:这类方法中没有时间推理的过程,因此并不能针对比如“二战之前的时间点”来进行预测,而时间推理能力对于复杂问题来说是非常重要的。
预训练语言模型对时间词不敏感:预训练语言模型对于时间词的理解是比较难的,比如一个句子中出现了Before/After这类简单的词,语言模型是很难去区分和理解应该是向前还是向后的。因为预训练语言模型中,有时候一个简单词的变化并不会特别影响到整个句子学习出来的表达,便会显得对时间词不敏感。所以如何提升对这些时间词的敏感度是一个非常重要的问题。
缺乏对隐含关系的考虑:在传统的时序知识图谱中,其实是有很多隐含关系的。知识图谱中存在很多时间,这些时间放到对应的事实中就是一个四元组的关系,使得这个事实成立,但是这些四元组之间到底存在什么关系呢?比如1999年发生的事件和1998年发生的事件其实是有时间错乱的先后顺序的,但是传统的时序知识图谱并没有把这种时序关系给建模出来。
基于以上的三个问题,我们提出了我们的TSQA方法,下面将对TSQA方法进行详细介绍。
03
TSQA方法
TSQA方法的最终目的是提升整个问答系统对时间的敏感度,不仅考虑时序知识图谱的角度,也考虑从问答系统中来提升时间敏感度。
1. 如何推理出正确的时间点?

因为基于时序的问答本身是一个推理的过程,这种时序推理过程中最重要的一步就是如何把所关注的时间点找得更准确。
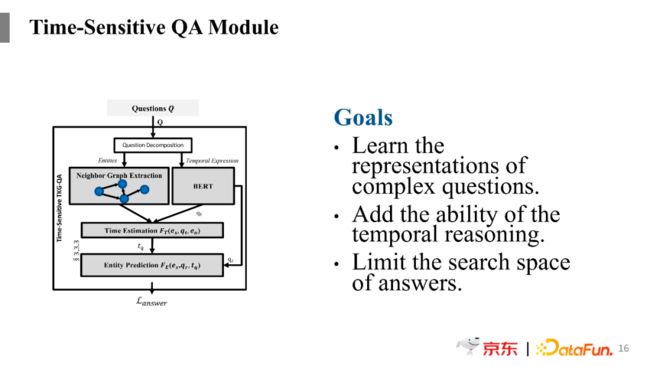
所以我们这里就提出了一个时间敏感度的问答子模块,这个模块的目标主要有三个:
学习复杂问题的表示
增加时间敏感度推理
限制答案的搜索空间

首先第一步,对问题进行简单的拆分,需要把问题中最核心的关键词抽取出来。抽取核心关键词是为了以此为基础去时序知识图谱中进行搜索,通过搜索可以得到一个子图,在子图上找答案会更加准确,也更加容易。对问题的拆分过程是将其拆成实体和时序问题的表达模板,例子中的模板中将美国总统和奥巴马两个实体当作一个特殊的token来进行表示建模。

在将问题进行拆分之后,下一步就是要基于拆分出来的实体在时序知识图谱中进行检索,抽取出对应的子图。比如基于美国总统和奥巴马两个实体来进行检索,将图谱中和这两个实体相关的其他关系和实体都取出来,形成一个进一步检索的子图。这个子图相对来说就比较小,在此基础上查找答案就比较容易。
图中右边是语言模型部分,这里的输入是问题拆分后的时序句式模板。模板已经将问题中的重点词去掉,用相应的subject或者object等通用词汇进行代替,这样再放到预训练语言模型中进行训练就会通用很多,比如同一个句式既可以用来说奥巴马如何,也可以用来说特朗普如何。通过句式模板这样的表示学习,可以使得问题的表达更加通用。
以上两个操作一是为了减小搜索空间,二是为了更好的表达问题。在我们的例子中,减小搜索空间抽出来的子图已经非常小了,对比原有的时序知识图谱,只有小于5%的比例被留下来了。
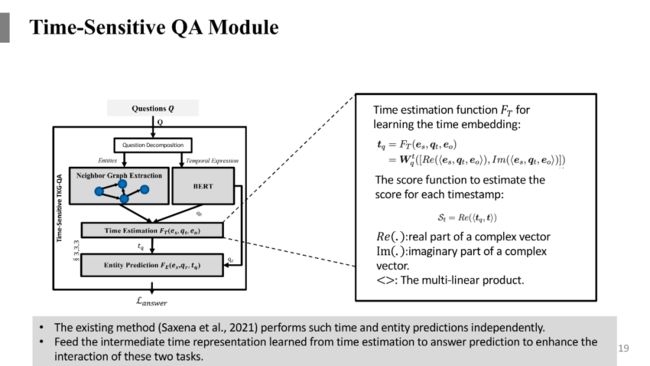
在缩小了搜索空间以及学到问题的表达之后,下一步需要去预测对应的时间。
这里参考了TcomplEx做法,TcomplEx是在复数基础上做tensor decomposition,将头实体、关系、时间和尾实体做一个复数乘积来作为打分函数。类似地,在Time Estimation模型部分,将从图谱中学习到的头实体、尾实体的表示,以及预训练语言模型对于问题的表示作为输入,构建一个神经网络模型来对时间进行预测。在模型内部,会根据上述三个输入来计算出来实部结果和虚部结果,将这两部分进行拼接之后,在经过一个线性变换层就得到了时间的表示。然后将预测出来的时间表示与我们抽取出来的子图中的时间点表示进行相似度的计算,来找到时序知识图谱中正确的时间点。以上就是时间预测的过程。
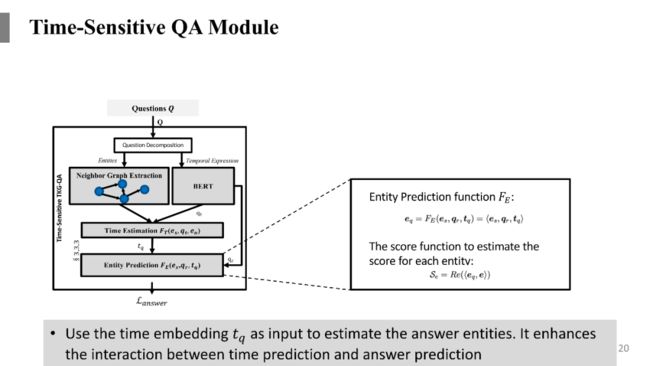
上面是进行时间的预测,但是一个问题的答案不都是时间,也有可能是实体,所以还需要进行实体的预测。用上一步预测出来的时间作为实体预测的输入,加上所知道的其中一个实体的表示和问题的表示,来预测缺失的另一个实体的信息。比如问题是“奥巴马之前的美国总统是谁?”,相当于已经预测出来奥巴马之前的那个时间点是什么,然后再加上美国总统这个信息,我们就能够预测出来奥巴马之前的美国总统是乔治布什。
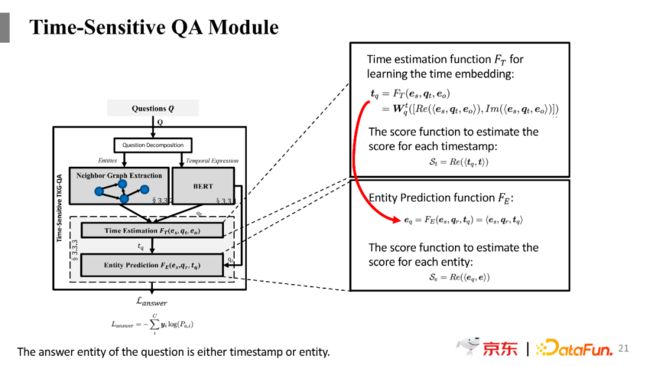
前面的预测步骤是模拟人理解一个时序问题并且回答的逻辑,首先是要预测出来准确的时间点,然后再用预测出来的时间点辅助预测最终的答案实体是谁,其实是一个多步推理的过程。
2. 如何提高时间词的敏感度?

上边讲到如何去做时间推理,通过时间推理来预测答案实体。但是在这个过程中模型对于时间词依旧是不敏感的,我们需要在这个过程中解决时间词的敏感度问题。

举个例子,对于问题“给定事件之前发生了什么?”和“给定事件之后发生了什么?”,他们在表述上的差别很小,只是前和后的差别,但是问题的答案却是完全不同的,因为一个是往前找答案,一个是往后找答案。预训练语言模型很难学习到这种细微变化,它并不清除时间词的变化蕴含着什么样的变化。
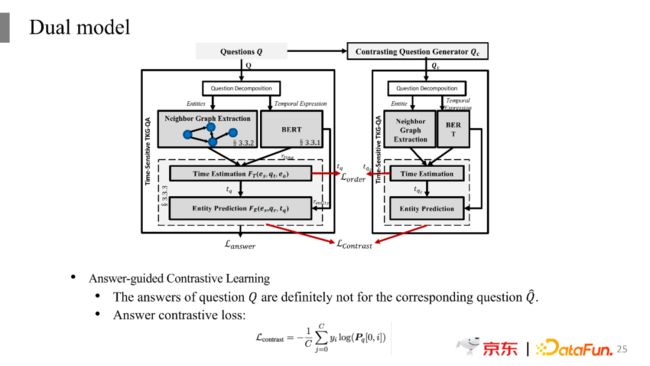
基于这个问题,我们构建了对比问题对。如果问题中出现了词典中的其中一个词,那么就将其替换为另一个,比如如果出现first,就替换为last;出现before则替换为after;反过来如果出现after,则替换为before。经过这样的变换之后,同样一个问题在时间上就会有不同的角度,比如会有往前找和往后找的样本。

有了对比样本之后,我们建立了一个Dual model,模型中包含两部分,一部分是对原始问题的时间推理以及答案的寻找;另外一部分则是将对比问题作为输入。本质上这两部分的结构是一样的,只是在输入部分不一样,这会带来最终损失函数值的不同,所以这里可以看到定义了两个loss。其中一个loss是对时间顺序进行计算的损失,比如问“奥巴马之前的美国总统是谁?”,对应的答案的时间预测是奥巴马当总统之前的时间点,而其对比问题“奥巴马之后的美国总统是谁?”所对应的答案的时间预测是奥巴马结束当总统之后的时间点,所以后者预测出来的时间点一定是在前者之后的。可以看到两者是有时间按顺序的,我们将Before->After转换定义为0,将After->Before定义为1。对比词典中其他词之间的相互转化定义也是类似的,比如First->Last定义为0,Last->First定义为1。
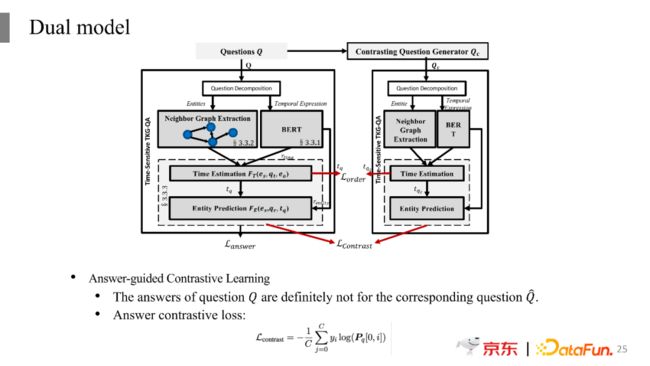
另外一个loss是基于实体不交叉来进行定义的。一般情况下,原始问题和对比问题的答案实体是不相同的,比如在之前的例子中,奥巴马之前的美国总统和奥巴马之后的美国总统不会是同一个人。所以针对原始问题进行预测时为1的实体,在针对对比问题的答案预测时为0,原始问题和对比问题预测出来的实体是没有交集的。
通过以上两个loss,我们希望模型在学习的过程中能够捕捉到时间词的变化所带来的影响,这样便提高了模型对于时间词的敏感度,可以更有效、更准确地找到问题的答案。
3. 如何建模时间线?

接下来介绍如何建模时间线。刚才介绍的两个问题是在问答部分怎么去做时间推理、怎么提高模型对于时间词的敏感度。但是还有一个问题是在对时序知识图谱进行表示学习的时候忽略了事件之间的先后顺序,并没有模块对先后顺序进行建模。

比如对于事件“奥巴马是美国总统”和“拜登是美国总统”这两个事实,在关系中加上时间之后形成了两个四元组事实,时间只是相对于每个事实的,而两个事实之间的先后顺序并没有被表达出来。针对这个问题我们做了简单的尝试,即在常规的embedding中加入Time position embedding,这是借鉴了transformers中的position embedding概念,如果把时间点根据先后顺序放在一个时间线上,那么这些时间点是有先后顺序的,也就有了各自的前后位置,可以进行Time position embedding的添加,所用的公式与transformer中的一模一样。

除此之外我们还添加了一个BCE Loss Function,希望预测出来的不同时间点之间是一个二分类问题,比如1995年和2020年需要通过二分类模型来区分出谁在前谁在后。通过在学习过程中加入time-order的损失来保证模型更好地学习到时间上的相互关系。

04
实验结果分析
接下来介绍一下模型的效果。
1. 数据集介绍

实验所用的数据集是ACL去年一篇文章中提供的数据集。从问题类别上可以看到有简单问题和复杂问题,我们想要解决的是如何在复杂问题上进行更好的推理;从答案的类别来看,可以分为问实体的问题和问时间的问题。
2. 实验结果

我们对比了四个模型,EmbedKGQA是传统基于embedding的方法,T-EaE-add和T-EaE-replace是在此基础上的改进方法;CronKGQA是前边介绍过的ACL2021文章中的模型。表中可以看到TSQA对整个效果的提升是非常大的,尤其是在复杂问题上减少了32%的错误,这也符合我们针对复杂问题去实现更好推理的做法,说明我们的时间推理是非常有效的。
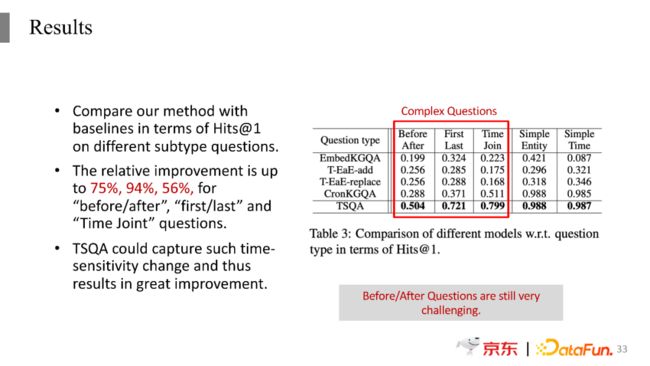
我们也进行了更深入的结果分析,验证模型对于复杂问题中的具体哪一类提升最大,分别提升的效果有多少。在表格中我们列出了每一类子问题,可以看到在三类问题(Before/After, First/Last, Time Join)的相对提升百分比分别为75%,94%,56%。在First/Last问题上提升的最多,在Time Join类问题上提升较少,这是因为Time Join类问题本身比较容易,之前的方法已经取得了相对好的效果。同时我们也可以看到Before/After类问题是最难的,更好地预测Before/After类问题中的内容需要知道在时间轴上进行什么操作,需要定义出所找的时间具体是什么样的形式,这仍然是比较难的问题。
3. 消融实验
另外我们也做了一些消融实验,想要更好地了解整个模型中哪部分的设计对最终效果的影响最大,进而知道哪部分才是最重要的模块。表中的“-”表示是从TSQA中去掉哪一部分。NG和TE是对整体效果影响最大的两个模块。NG是Neighbor Graph的选择,在这个部分只选出原始图谱的5%作为搜索的子图,进而在子图中进行答案的推理,所以这部分对模型整体的效果的影响是巨大的,子图找得越准确,对效果的提升也就越明显。TE是Time Estimation的时间推理部分,如果时间能够预测得比较好,并且把多步推理的过程建模出来,对最终的效果有比较大的提升,这里我们看到整体效果从0.661提升到0.757,是一个非常大的进步;同时在复杂问题上从0.412提升到了0.583,提升效果也非常明显。
05
总结
我们整个模型的目的是提升基于时序知识图谱的问答系统对时间的敏感性。所谓的敏感性既包括在问答部分如何实现时间推理、如何增加对时间词的敏感度,同时也包括在时序知识图谱的表示学习时如何将时间更好地建模。从以上这三个问题出发,我们分别设计了相应的模块来提升整体时间敏感性。
以上就是我们文章的核心内容,非常感谢能有机会和大家分享!
06
Q&A
Q1:如何判断找到的子图是合适的?或者说如何选择合适的子图?
A:怎么样更好地选择合适的子图是非常重要的一步,但是在这个地方我们用的方法并不复杂,对于一个问题,比如“奥巴马是美国总统”,他的核心词“奥巴马”和“美国总统”已经非常明显了,我们将其提取出来后,一定要围绕这两个核心词来找子图,可以是1跳、2跳或者多跳的一个子图。具体几跳是需要基于问题来定义的,比如在这个例子中其实不需要很多跳的信息来进行回答,只需要把时间找对就可以了。但是可能有更复杂的问题需要抽取一个更大范围的子图出来,然后在这个大的子图上来更准确地推理答案。从另一个角度来讲其实是所谓的一个平衡,就看你需要是recall更高还是precision更高,所以是一个trade-off。
Q2:在所讲的推理过程中,是基于图谱路径搜索来做推理好还是加入机器学习的方法来做推理比较好?
即基于规则的方法和基于deep learning的方法各有什么优势或者是区别呢?
A:这涉及到两个方面,一方面是所谓的逻辑推理或者最近提到的symbolic的概念,相当于把明确的逻辑推理信息加入进来去实现推理;另一方面是直接建立神经网络来进行学习。这两方面哪种更好,这个问题没有明确的答案,但是我们在时间推理上感觉并没有所谓的路径来让我们用,因为我们更关心的是一个时间上的预测,而你在图中的一个路径上,无论怎么走也走不出一个时间的变化,只能说从一个点走到另一个点,再跳转的别的点。除非是在时间轴上进行跳转,经过时间轴上的变化到达其他点,所以时间轴的路径选择就很重要了。但是在传统的时序知识图谱中我们没有办法建模时间轴上的变化,所以说路径的选择还是很难的。
Q3:可以将文章的主要contributions做一个summary,这些contributions是否能拓展到其他时间敏感的问题上去?
A:我们文章的核心点就是增加时间的敏感性,其中包含主要有三个贡献点。第一点是说如果问答里的问题是关于时间的,能把问题中的时间推理过程建模出来;第二点是在建模时间推理的过程中,提高对时间词的敏感性,让模型理解时间词的变化。因为所有问答部分都是基于前面的学到的Embeddings,所以我们的第三个贡献点就是在前面的表示学习时如何更好地建模时间,把所谓的时间轴建模出来。
今天的分享就到这里,谢谢大家。
在文末分享、点赞、在看,给个3连击呗~
01/分享嘉宾

商超 博士
京东硅谷研究院 研究员
商超,现就职于京东硅谷研究院,担任研究科学家。博士毕业于University of Connecticut大学计算机系。他的研究主要集中在图神经网络和自然语言处理,近期致力于知识图谱的表征学习,问答系统设计,和图神经网络在时序数据和生化等领域的应用。

分享、点赞、在看,给个3连击呗!