pandas分析数据常用代码【自用】
目录
-
- 列批量处理
- 替换列内容
- 改变列顺序
- 去除前三列
- pd.concat 数据拼接
- 重置索引
- 重命名表头
- 匹配查找特定值
- groupby()
-
- 1、分组,并分别输出每组数据
df = pd.read_csv(‘D:/driver/raw_data/Freeway.csv’)
列批量处理
df[[’列1‘,’列2‘,’列n‘]]
注意双括号
示例1
取’frameNum’, ‘carId’, ‘speed’, ‘headXft’,‘tailXft’,'laneId’列,保存在save_columns中
save_columns = df[['frameNum', 'carId', 'speed', 'headXft','tailXft','laneId']]
示例2
对[‘speed’],[‘followDis’],[‘accel’]进行Savitzky-Golay滤波
smooth1 = savgol_filter(df[['speed','followDis','accel']],31,1,mode='nearest')#对['speed'],['followDis'],['accel']进行滤波
替换列内容
直接df[‘列’]=xxx即可
smooth1 = savgol_filter(df['speed'],31,1,mode='nearest')
df['speed'] = smooth1
改变列顺序
原顺序
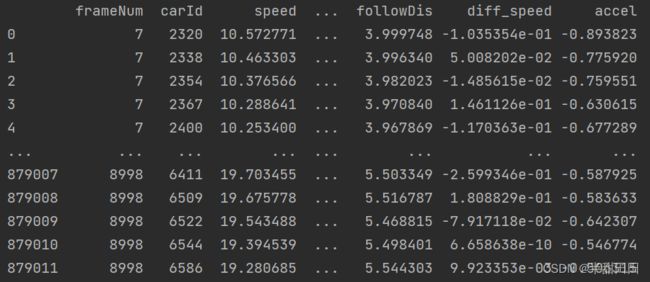
更改顺序
order = ['frameNum','carId','laneId','speed','disdanceft','followDis','diff_speed','accel']#期望顺序
df1=df[order]#改变顺序
更改后
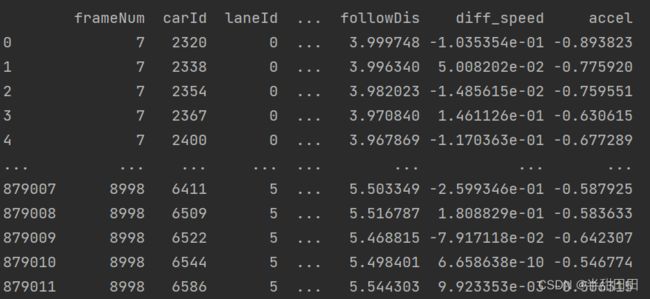
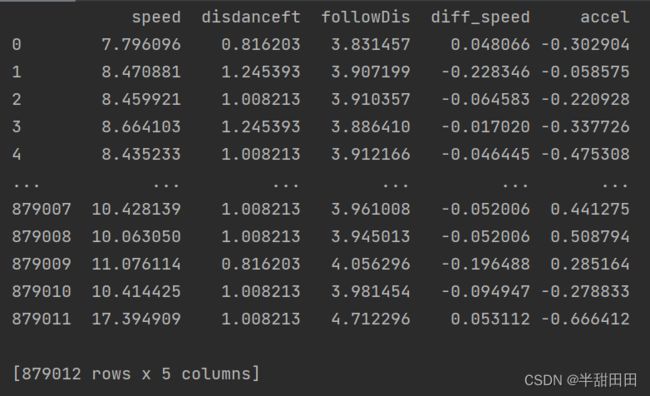
去除前三列
原数据

代码
import pandas as pd
df=pd.read_csv('D:/driver/Analysis/jiangwei.csv')
df1=df.iloc[:,3:]#去除前3列
print(df1)
运行结果
pd.concat 数据拼接
需求:按相同索引将数据横向拼接
想把下面三个数据,按索引拼接为一个
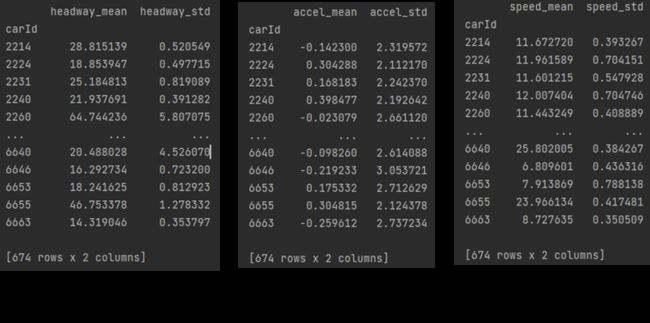
代码
last_result = pd.concat([speed,accle,headway_no0],axis=1)#合并
结果:
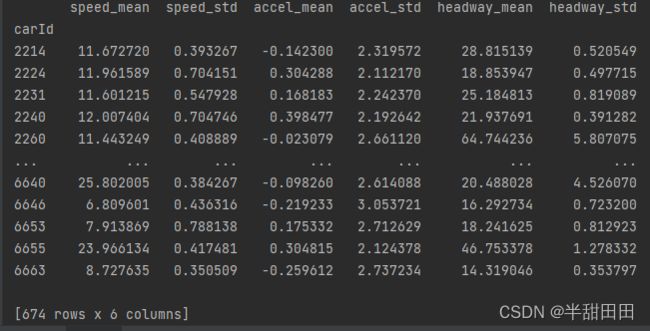
重置索引
如 pd.concat 数据拼接所示,last_result的索引是‘carId’。想着希望将‘carId’变为列值,使用默认索引
代码
last_result= last_result.reset_index()
结果
重命名表头
首先,将两个数据合并在一起
r = pd.concat([type_num, center], axis=1)
type_num数据
center数据


重命名表头
r.columns = pca_scores.columns.tolist() + ['类别数目'] # 重命名表头
结果

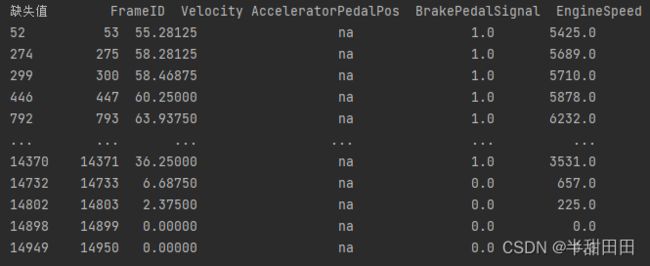
匹配查找特定值
这个数据中缺失值写为na
#查找缺失值na的数据
df_lack=df[df.isin(['na']).values == True]
print('缺失值',df_lack)
结果
groupby()
1、分组,并分别输出每组数据
import pandas as pd
df = pd.read_csv('D:/driver/raw_data/data.csv')
grouped = df.groupby('carId')
for name,group in grouped:
print(name)
print(group)
输出结果(部分),carId相同的聚合