Argoverse--Motion Forecasting Dataset评价指标minADE/minFDE详细介绍
文章目录
- 前言
- 一、概念解释
- 二、代码
- 总结
前言
最近接触了Argoverse数据集中运动预测部分v1.1版本(Motion Forecasting Dataset)。评价指标为K=1/6时,minADE、minFDE、MR、DAC等参数,详情见:
Argoverse 数据集详解
官方解释
但是没有找到关于minADE、minFDE详细的定义,于是找到了Argoverse在GitHub上的代码,对计算两个参数的部分代码进行了学习,明白了其具体含义。
https://github.com/argoai/argoverse-api
一、概念解释
Argoverse数据集链接:
Argoverse运动预测数据集
官网中说明了原始文件中包含agent、AV以及others,没有做详细说明,查了一些资料,应该是以每帧中的agent作为轨迹预测目标。

原始数据中每一帧包含5s内的多种目标的位置:
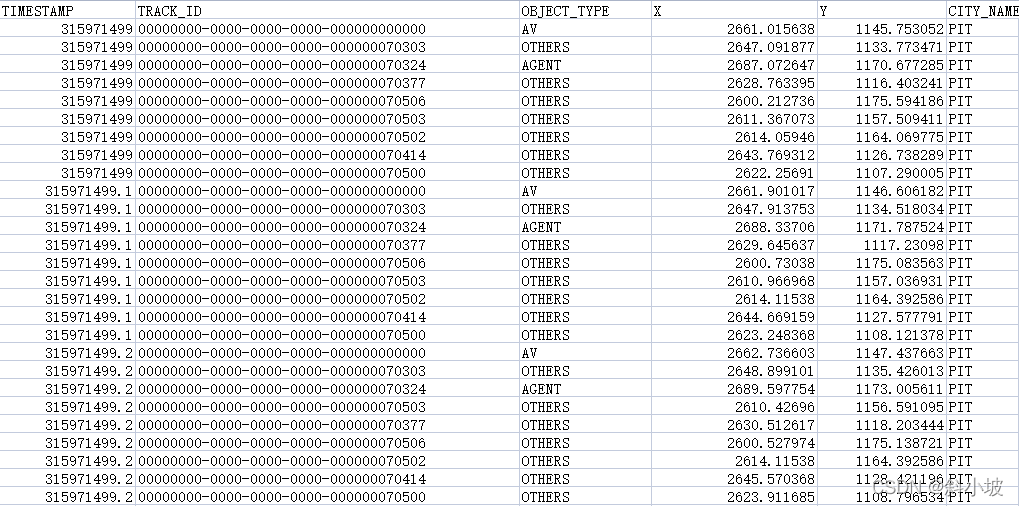
argoverse-api代码中对minADE、minFDE计算流程如图所示:

min_fde是一个样本中对agent预测的轨迹中最小的fde,min_ade是与之对应的轨迹的ade
minFDE是对所有样本的min_fde取平均值,minADE是与之对应的所有min_ade的平均值
k一般取1和6,这也是argoverse轨迹预测赛所设定的指标,排行榜链接:
argoverse轨迹预测大赛排行榜
二、代码
argoverse-api对minADE、minFDE计算的代码及注释如下:
(删掉了部分关于brier-minADE/FDE指标的代码)
代码所在文件的目录:argoverse-api/argoverse/evaluation/eval_forecasting.py
github链接
def get_ade(forecasted_trajectory: np.ndarray, gt_trajectory: np.ndarray) -> float:
"""Compute Average Displacement Error.
Args:
forecasted_trajectory: Predicted trajectory with shape (pred_len x 2) #2代表两列xy
gt_trajectory: Ground truth trajectory with shape (pred_len x 2)
Returns:
ade: Average Displacement Error
"""
pred_len = forecasted_trajectory.shape[0] #预测单条轨迹的行数==每个轨迹包含轨迹点的个数
ade = float( #单条轨迹中所有轨迹点坐标与真值的欧氏距离的平均值
sum(
math.sqrt(
(forecasted_trajectory[i, 0] - gt_trajectory[i, 0]) ** 2
+ (forecasted_trajectory[i, 1] - gt_trajectory[i, 1]) ** 2
)
for i in range(pred_len)
)
/ pred_len
)
return ade
def get_fde(forecasted_trajectory: np.ndarray, gt_trajectory: np.ndarray) -> float:
"""Compute Final Displacement Error.
Args:
forecasted_trajectory: Predicted trajectory with shape (pred_len x 2)
gt_trajectory: Ground truth trajectory with shape (pred_len x 2)
Returns:
fde: Final Displacement Error
"""
fde = math.sqrt( #单条轨迹中最后一个轨迹点坐标与真值的欧氏距离
(forecasted_trajectory[-1, 0] - gt_trajectory[-1, 0]) ** 2
+ (forecasted_trajectory[-1, 1] - gt_trajectory[-1, 1]) ** 2
)
return fde
def get_displacement_errors_and_miss_rate(
forecasted_trajectories: Dict[int, List[np.ndarray]],
gt_trajectories: Dict[int, np.ndarray],
max_guesses: int,
horizon: int,
miss_threshold: float,
forecasted_probabilities: Optional[Dict[int, List[float]]] = None,
) -> Dict[str, float]:
"""Compute min fde and ade for each sample.
Note: Both min_fde and min_ade values correspond to the trajectory which has minimum fde.
The Brier Score is defined here:
Brier, G. W. Verification of forecasts expressed in terms of probability. Monthly weather review, 1950.
https://journals.ametsoc.org/view/journals/mwre/78/1/1520-0493_1950_078_0001_vofeit_2_0_co_2.xml
Args:
#所有样本agent的top-k条轨迹预测值 字典的格式 以样本序号作为key 预测的top-k条轨迹的坐标列表作为value
forecasted_trajectories: Predicted top-k trajectory dict with key as seq_id and value as list of trajectories.
Each element of the list is of shape (pred_len x 2).
#所有样本agent轨迹的真值 同样是字典的格式
gt_trajectories: Ground Truth Trajectory dict with key as seq_id and values as trajectory of
shape (pred_len x 2)
max_guesses: Number of guesses allowed #top-k中的k
horizon: Prediction horizon #预测范围
miss_threshold: Distance threshold for the last predicted coordinate #fde的阈值
forecasted_probabilities: Probabilites associated with forecasted trajectories. #与brier_min_ade/fde相关的概率 暂时不考虑
Returns:
metric_results: Metric values for minADE, minFDE, MR, p-minADE, p-minFDE, p-MR, brier-minADE, brier-minFDE
"""
metric_results: Dict[str, float] = {}
min_ade, prob_min_ade, brier_min_ade = [], [], []
min_fde, prob_min_fde, brier_min_fde = [], [], []
n_misses, prob_n_misses = [], []
for k, v in gt_trajectories.items(): #k->样本的序号 v->每个样本中agent的真值轨迹
curr_min_ade = float("inf") #curr_min_ade初始化 设为无穷大
curr_min_fde = float("inf") #curr_min_fde初始化 设为无穷大
min_idx = 0 #min_idx初始化 fde最小的轨迹序号 设为0
max_num_traj = min(max_guesses, len(forecasted_trajectories[k])) #第k帧样本对agent预测轨迹的列表长度(预测n条)与max_guesses(top-k)中的较小值 选择多少条预测的轨迹进行后续计算
# If probabilities available, use the most likely trajectories, else use the first few
if forecasted_probabilities is not None: #忽略
sorted_idx = np.argsort([-x for x in forecasted_probabilities[k]], kind="stable")
pruned_probabilities = [forecasted_probabilities[k][t] for t in sorted_idx[:max_num_traj]]
# Normalize
prob_sum = sum(pruned_probabilities)
pruned_probabilities = [p / prob_sum for p in pruned_probabilities]
else:
sorted_idx = np.arange(len(forecasted_trajectories[k])) #仅考虑此条件 以0为起点,以第k帧样本对agent预测的轨迹条数为终点,步长为1,构成数组sorted_idx
pruned_trajectories = [forecasted_trajectories[k][t] for t in sorted_idx[:max_num_traj]] #判断结束 把第k帧样本中前max_num_traj条轨迹存入pruned_trajectories数组
#构建pruned_trajectories的目的是防止预测算法输出的轨迹数量与设定的top-k值不符
for j in range(len(pruned_trajectories)): #pruned_probabilities对数组进行遍历计算其中最小的fde
fde = get_fde(pruned_trajectories[j][:horizon], v[:horizon]) #函数中第一个参数为最终坐标预测值 第二个参数为真值
if fde < curr_min_fde:
min_idx = j
curr_min_fde = fde
curr_min_ade = get_ade(pruned_trajectories[min_idx][:horizon], v[:horizon]) #curr_min_ade是fde最小的轨迹的ade
min_ade.append(curr_min_ade) #存储当前帧样本的min_ade
min_fde.append(curr_min_fde) ##存储当前帧样本的min_fde
n_misses.append(curr_min_fde > miss_threshold)
metric_results["minADE"] = sum(min_ade) / len(min_ade) #对所有样本的min_ade求平均值得到最终输出的指标minADE
metric_results["minFDE"] = sum(min_fde) / len(min_fde) #对所有样本的min_fde求平均值得到最终输出的指标minFDE
metric_results["MR"] = sum(n_misses) / len(n_misses)
总结
初学者,有理解或表达错误请大家指正~