深度学习Review【四】编解码
课程地址
动手学深度学习笔记【三】
- 一、编码-解码
- 二、Seq2seq
-
- torch
一、编码-解码
编码(训练):处理输出,把输入编程成中甲你表达形式(特征)
解码(预测):生成输出,把特征解码成输出
from torch import nn
class Encoder(nn.Module):
"""编码器-解码器结构的基本编码器接口。"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
"""编码器-解码器结构的基本解码器接口。"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
class EncoderDecoder(nn.Module):
"""编码器-解码器结构的基类。"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args)
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state)
二、Seq2seq
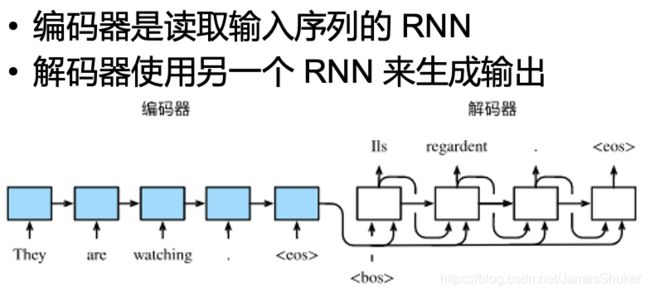
训练过程,即Encode的过程(一个RNN)是双向的
解码器是单向的
RNN也不需要定长的序列作为输入输出

把编码器的RNN最后一层的输出放在解码器里,作为初始隐状态
torch
import collections
import math
import torch
from torch import nn
from d2l import torch as d2l
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器Encode"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
#对每个词embedding
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers,
dropout=dropout)
#numlayers是RNN的层数 numhiddens是隐藏层的层数
def forward(self, X, *args):
# 输出'X'的形状:(`batch_size`, `num_steps`, `embed_size`)
X = self.embedding(X)
# 在循环神经网络模型中,第一个轴对应于时间步,交换batchsize和numstep
X = X.permute(1, 0, 2)
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# `output`的形状: (`num_steps`, `batch_size`, `num_hiddens`)
# `state[0]`的形状: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
encoder = Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
X = torch.zeros((4, 7), dtype=torch.long)
output, state = encoder(X)
#output和state的形状torch.Size([7, 4, 16]) torch.Size([2, 4, 16])
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器。"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
#分类
def init_state(self, enc_outputs, *args):
return enc_outputs[1] #enc_outputs[1]为state
def forward(self, X, state):
# 输出'X'的形状:(`batch_size`, `num_steps`, `embed_size`)
X = self.embedding(X).permute(1, 0, 2)
# 广播`context`,使其具有与`X`相同的`num_steps`
context = state[-1].repeat(X.shape[0], 1, 1)
X_and_context = torch.cat((X, context), 2)
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# `output`的形状: (`batch_size`, `num_steps`, `vocab_size`)
# `state[0]`的形状: (`num_layers`, `batch_size`, `num_hiddens`)
return output, state
decoder = Seq2SeqDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
state = decoder.init_state(encoder(X))
output, state = decoder(X, state)
# output和state的shape(torch.Size([4, 7, 10]), torch.Size([2, 4, 16]))