【自然语言处理】对评论进行处理的推荐系统的论文总结
【自然语言处理】对评论进行处理的推荐系统的论文总结
- NLP语料库介绍的以及连接
-
- 腾讯语料库
- github上40个nlp中文语料库
- 推荐系统中常见的文本处理方法
-
- 词袋模型 BOW
-
- 推荐系统中的应用
- 存在的问题
- 解决思路
- 词袋模型升级版 N-gram词袋模型
- TF-IDF权重计算方法
- 隐语义模型LSA (Latent Semantic Analysis)
- 阿里自然语言处理部总监分享:NLP技术的应用及思考
-
- 标题分析
- 舆情文本分析
NLP语料库介绍的以及连接
腾讯语料库
数据链接:
https://ai.tencent.com/ailab/nlp/embedding.html
数据简介:
腾讯AI实验室宣布,正式开源一个大规模、高质量的中文词向量数据集。
该数据包含800多万中文词汇,相比现有的公开数据集,在覆盖率、新鲜度及准确性上大幅提高。
在对话回复质量预测、医疗实体识别等自然语言处理方向的业务应用方面,腾讯内部效果提升显著。
数据特点:
总体来讲,腾讯AI实验室此次公开的中文词向量数据集包含800多万中文词汇,其中每个词对应一个200维的向量。
具体方面,腾讯自称,该数据集着重在3方面进行了提升:
覆盖率(Coverage):
该词向量数据集包含很多现有公开的词向量数据集所欠缺的短语,比如“不念僧面念佛面”、“冰火两重天”、“煮酒论英雄”、“皇帝菜”、“喀拉喀什河”等。
以“喀拉喀什河”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
墨玉河、和田河、玉龙喀什河、白玉河、喀什河、叶尔羌河、克里雅河、玛纳斯河
新鲜度(Freshness):
该数据集包含一些最近一两年出现的新词,如“恋与制作人”、“三生三世十里桃花”、“打call”、“十动然拒”、“供给侧改革”、“因吹斯汀”等。
以“因吹斯汀”为例,利用腾讯AI Lab词向量计算出的语义相似词如下:
一颗赛艇、因吹斯听、城会玩、厉害了word哥、emmmmm、扎心了老铁、神吐槽、可以说是非常爆笑了
准确性(Accuracy):
由于采用了更大规模的训练数据和更好的训练算法,所生成的词向量能够更好地表达词之间的语义关系,如下列相似词检索结果所示:
在开源前,腾讯内部经历了多次测评,认为该数据集相比于现有的公开数据集,在相似度和相关度指标上均达到了更高的分值。
github上40个nlp中文语料库
数据链接:
https://github.com/fighting41love/funNLP
数据简介:
包括中英文敏感词、语言检测、中外手机/电话归属地/运营商查询、名字推断性别、手机号抽取、身份证抽取、邮箱抽取、中日文人名库、中文缩写库、拆字词典。
词汇情感值、停用词、反动词表、暴恐词表、繁简体转换、英文模拟中文发音、汪峰歌词生成器、职业名称词库、同义词库、反义词库。
否定词库、汽车品牌词库、汽车零件词库、连续英文切割、各种中文词向量、公司名字大全、古诗词库、IT词库、财经词库、成语词库。
地名词库、历史名人词库、诗词词库、医学词库、饮食词库、法律词库、汽车词库、动物词库、中文聊天语料、中文谣言数据。
推荐系统中常见的文本处理方法
词袋模型 BOW
认为文档是文档中的词组成的多重集合(和普通集合不同,考虑集合中元素出现的次数),不考虑语法和次序,只考虑词的出现次数。
推荐系统中的应用
在推荐系统中,如果将一个物品看作一个词袋,我们可以根据袋中的词来召回相关物品,例如用户浏览了一个包含“羽绒服”关键词的商品,我们可以召回包含“羽绒服”的其他商品作为该次推荐的候选商品,并且可以根据这个词在词袋中出现的次数(词频)对召回商品进行排序。
存在的问题
首先,将文本进行分词后得到的词里面,并不是每个词都可以用来做召回和排序,例如“的地得你我他”这样的“停用词”就该去掉,此外,一些出现频率特别高或者特别低的词也需要做特殊处理,否则会导致召回结果相关性低或召回结果过少等问题。
其次,使用词频来度量重要性也显得合理性不足。以上面的“羽绒服”召回为例,如果在羽绒服的类别里使用“羽绒服”这个词在商品描述中的出现频率来衡量商品的相关性,会导致所有的羽绒服都具有类似的相关性,因为在描述中大家都会使用类似数量的该词汇。所以我们需要一种更为科学合理的方法来度量文本之间的相关性。
解决思路
我们还可以将词袋中的每个词作为一维特征加入到排序模型中。例如,在一个以LR为模型的CTR排序模型中,如果这一维特征的权重为w,则可解释为“包含这个词的样本相比不包含这个词的样本在点击率的log odds上要高出w”。在排序模型中使用词特征的时候,为了增强特征的区分能力,我们常常会使用简单词袋模型的一种升级版——N-gram词袋模型。
词袋模型升级版 N-gram词袋模型
N-gram指的就是把N个连续的词作为一个单位进行处理。例如**“John likes to watch movies.Mary likes movies too.”这句话处理为简单词袋模型后的结果为:**
![]()
处理为2-gram的结果为
![]()
TF-IDF权重计算方法
计算公式

将之前使用词频对物品进行排序的方法,改进为根据TF-IDF得分进行排序。
隐语义模型LSA (Latent Semantic Analysis)
阿里自然语言处理部总监分享:NLP技术的应用及思考
原文链接:https://mp.weixin.qq.com/s/LntGZmP5jp0PgdcOGo-nWg
用户需求:我要买秋天穿的红色连衣裙。
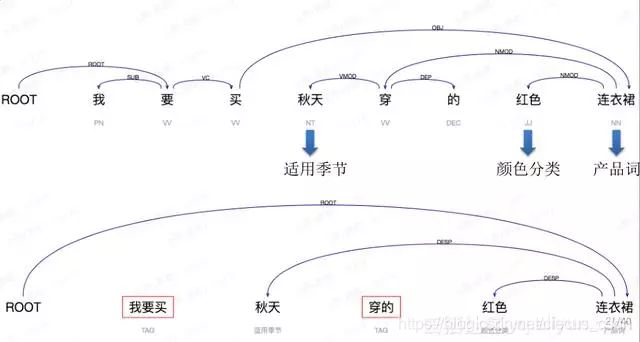
结构句法分析结果

对于电商而言,光有句法分析是不够的,比如我要知道秋天的含义是说这是个适用季节,红色是一个颜色分类,连衣裙是一个产品,要做到这一步才会使得真正在电商里面用起来。
比如我们用的是通用领域依存分析器,我们针对商品标题决定某一个依存句法分析器,假设某一个商品标题写的是“我要买秋天穿的红色连衣裙”,只需要把“秋天”、“红色”、“连衣裙”这几个关键的成分标出来,“我要买”和“穿的”对电商而言是没有意义的,但会去做进一步的组合。

评论:
“虽然有点贵,不是很修身,但是颜色很亮,布料摸起来挺舒服的,图案也好看。挺喜欢的。”

上图是我们的情感分析结果,我们情感分析不但要知道整句的信息,比如说整句有蓝色、淡蓝色,淡蓝色表示情感是正向的,整个句子表达的是一个比较褒义的结果,但不是非常满意。
标题分析

标题分析主要分四步:
第一步先做分词。把第一行变成第二行,打空格用了很多算法、词表、人工、优化的思路;
第二步是实体打标。需要知道每个词语是什么含义,粉红大布娃娃是个品牌,泡泡袖是个袖型等等,这样你的搜索引擎就更加智能一点;
第三步是热度计算。把热度分数识别出来,因为串里面每个词不是等价的,有些重要性非常高,有些重要性非常低;
第四步是中心识别。我们用依存句法分析方法来做,表达这个句子的最核心关系就是春装连衣裙,这里面可以做进一步的简化,选取合适的某一个维度的信息。这样,你的数据库就非常好了,可以做很多深入的工作。
舆情文本分析
关于舆情文本分析,我们有文本的分类、标签和文档聚类技术。假如你在手机淘宝app评价写了一堆东西,就进入了我们的流程。我们的系统叫摩天轮,会自动的把你写的每一条评论做各种各样的分析和处理,包括聚类的和标签的很细粒度的解析。
