一文吃透AI芯片技术路线,清华尹首一教授演讲全文:GTIC2020
转载自:https://mbd.baidu.com/newspage/data/landingsuper?context=%7B%22nid%22%3A%22news_9972291866667704481%22%7D&n_type=1&p_from=4
GTIC 2020全球AI芯片创新峰会刚刚在北京圆满收官!在这场全天座无虚席、全网直播观看人数逾150万次的高规格AI芯片产业峰会上,19位产学界重磅嘉宾从不同维度分享了对中国AI芯片自主创新和应用落地的观察与预判。
清华大学微纳电子系副主任、微电子所副所长尹首一教授首登GTIC,围绕《中国AI芯片的创新之路》主题,深入浅出地探讨了AI芯片在中国的进展,并对AI芯片产业的关键技术与创新机会进行了系统的梳理与预判。
在演讲期间,尹首一教授重点为大家梳理了当前AI芯片的技术路线分类,分别介绍了指令集架构处理器、数据流处理器、存内计算处理器、可重构处理器、脉冲神经网络处理器及神经形态器件等AI芯片的不同研究方向,并对AI芯片进行了阶段性回顾和展望。
他总结道,目前AI芯片仍处起步阶段,在科学研究和产业应用方面具有广阔的创新空间,而中国AI芯片产业创新正与国际同步,未来大有可为。
以下为尹首一教授演讲实录整理:
一、2025年全球AI芯片市场规模将达700亿美元
AI芯片产业发展至今已有五六个年头,现在进入攻坚阶段。大家已经达成这样一个共识,人类社会正从信息化迈向智能化,人工智能(AI)成为实现智能化的一个关键手段,而在这其中,芯片是核心基石和战略制高点。
耳熟能详的AlphaGo、自动驾驶,手机上的人脸解锁、智能拍照,无线耳机的人机交互……都离不开AI芯片的支撑。
在推动智能化发展方面,AI芯片有两个最核心的作用:一是芯片的“绝对算力”是决定智能化所能达到的最高水平的关键因素之一;二是“计算能效”是决定智能化应用范围的关键因素之一。
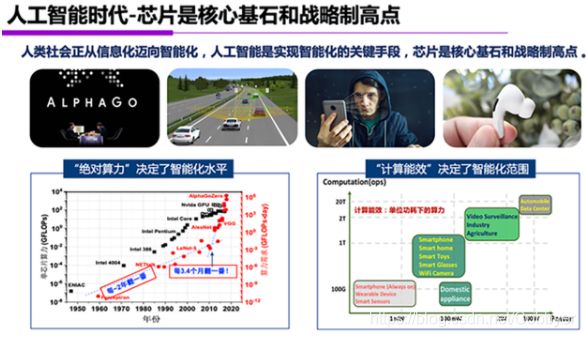
从“绝对算力”来看,今年OpenAI推出的GPT-3非常火,成为今年自然语言处理中最强大的模型,这个模型有1700亿个参数,使用了一万张GPU卡进行训练。没有这样强大的算力,GPT-3无法达到目前的智能化水平,可以说“绝对算力”决定了今天智能化的水平。
芯片算力的发展速度与人工智能算法对算力的需求增长之间存在巨大的差距,通用处理器平均每两年性能翻一番,而算法模型对算力的需求大概每3.4个月就翻一番,这是AI芯片需要解决的问题。
从“计算能效”来看,今天有非常多的应用领域面临迫切的智能化需求,人工智能技术正从云端向边缘和物联网设备快速渗透。然而人工智能技术能否实用化,受限于软硬件系统的计算能效。比如,语音识别颠覆了传统的人机交互接口,如果没有低功耗高能效的AI芯片,在智能耳机等便携穿戴设备上就无法实现令人满意的用户体验。
伴随着人工智能产业的快速发展,AI芯片展现出巨大的发展潜力。据第三方机构预测,全球AI市场规模到2025年将达到6.4万亿美元,其中全球AI芯片市场规模预计在2025年将达到700亿美金,今年中国AI芯片市场规模已超过75亿人民币,未来有非常强劲的增长潜力。
二、两大维度整体梳理AI芯片分类
大家经常问:“AI芯片用在哪里?”、“AI芯片属于什么类别的产品?”在峰会现场,尹首一教授从应用场景和技术路线两个维度,概述了AI芯片尤其是中国AI芯片的发展全貌。
他认为,中国的AI芯片发展起步和国际产业基本同步。据不完全统计,今天中国在做AI芯片的企业超过100家,从地域划分来看,北京、上海、长三角、珠三角是最为活跃的区域。
从应用场景的角度做划分,AI芯片可以分成云端、边缘端两类。
云端可以进一步细分成推理应用和训练应用。推理应用是大家每天都在互联网服务中能感受到的,比如搜索引擎中的自然语言翻译、电商网站的用户推荐系统、很多地方在建的城市大脑等;而训练应用是今天所有人工智能系统开发的基础。
边缘侧的应用场景非常繁多,比如智能手机、智能音箱、安防监控、智能驾驶、无人系统等,在这些终端设备上都是推理应用。
今天AI芯片成长非常速度,从2017年到2022年,不同应用领域的AI芯片的复合增长率都在50%左右。综合来看,五年间以55%的年均复合增长率快速发展。
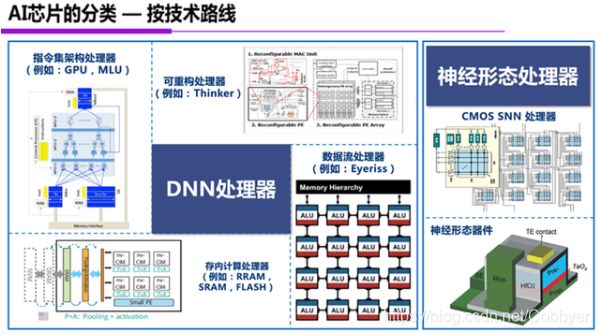
从技术路线的角度,今天的AI芯片可以分成两大类。
一类是深度神经网络处理器,对今天深度学习的核心基础——深度神经网络——进行计算加速。
另一类是神经形态处理器,通过对人脑结构的研究,设计电路或器件来复制或模仿人脑机理,实现智能处理能力。
三、实现深度神经网络处理器的四类典型架构
深度神经网络处理器,从计算架构的角度可分成四种不同的类型:(1)指令集处理器(2)数据流处理器(3)存内计算处理器(4)可重构处理器。
无论哪种技术路线,最终目标都是实现对深度神经网络的计算加速。
首先来看一下指令集架构AI处理器。
指令集架构AI处理器可以定义为一类使用专门为神经网络运算而设计的指令集的处理器。
说到指令集,大家熟悉的CPU是最典型的指令集处理器的例子,采用一套预定义的定长或者变长的指令作为数据处理的基本单元,通过对这些指令的组合构成指令流,由指令流来驱动处理器完成复杂计算任务。
通过对神经网络计算特征的抽象,构造出神经网络专用指令集,设计硬件架构高效执行这些指令,就实现了专用的AI处理器。
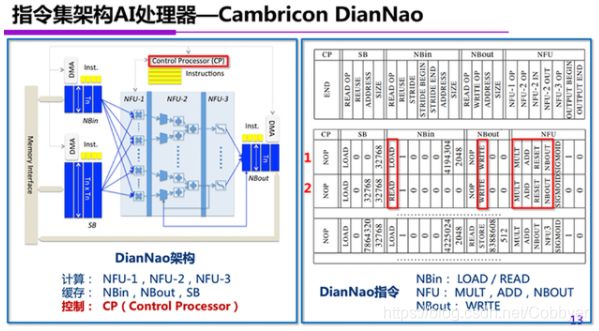
尹首一教授通过寒武纪的例子进一步解释了神经网络专用指令集和处理器架构。上图是寒武纪公开发表的DianNao架构结构示意图,其中典型的计算部件有三个NFU(神经功能单元),分别是并行乘法器、加法树、激活函数三类单元,另外还有三个不同的存储单元,分别存储着输入特征数据、模型权重、输出数据。
寒武纪DianNao架构的运行受到CP控制器的控制,神经网络指令集中有存储指令LOAD、READ、WRITE等、运算指令MULT、ADD等。典型的神经网络被表达为通过这些指令组合构成的指令流,从而驱动处理器完成计算。
第二类是数据流AI处理器,这是一种计算行为由数据调度决定的数据流驱动的张量处理架构,其特点是优化数据复用和计算并行度。
在典型的数据流处理器中,神经网络张量会被划分成不同的tile,每个tile内的计算被映射到一个处理单元(PE)阵列中。典型的数据流包括两种:一种称为权重稳定数据流,一种称为输出稳定数据流,分别对应着充分复用权重数据、充分复用输出数据,通过不同数据流提高数据复用、减少缓存,提高计算并行度,从而最终提高芯片的处理能力和处理能效。
第三类存内计算处理器,如今吸引了很多研究机构、创业公司及投资机构的兴趣。
什么是存内计算?逻辑电路或处理单元被放置到存储器内部,使数据更接近处理单元;或者直接在存储电路中执行计算,而无需进行数据传输,这就是我们今天所说的存内计算概念。
它能解决什么问题?在传统计算架构中,处理单元和存储器是分离的结构,每次计算都要在处理单元和存储器之间进行一定的数据搬移。而存内计算架构,不需要在存储器和计算单元间大量搬移数据,解决了今天传统计算架构面临的“存储墙”问题。
存内计算根据采用存储器类型的不同,可以分成不同的技术路线,包括:阻变存储器(RRAM)、闪存(Flash)、静态随机存储器(SRAM)等。

RRAM和Flash属于非易失存储。以RRAM为例,每个存储单元里面的电阻值通过电流来调节,每个单元可以调节多种阻值,典型忆阻器结构是交叉开关形式。AI算法中大量存在的是矩阵和张量计算,在RRAM中,将神经网络权重以电导的形式写到cross-point上,再把输入值以电压形式输入到存储器的字线上,当电压施加到电阻上,就有电流流过,这些电流在位线上自然地被累加起来。这就形成了在矩阵和张量计算中的乘法累加过程,把数学上的矩阵和张量计算转化成了物理上的基尔霍夫定律和欧姆定律表达的电压和电流的关系,用物理方式完成了数学计算。这也就是今天存内计算最吸引人的地方,我们不再采用传统的数字计算部件,而是采用模拟、物理的方式去实现计算。
除了前面提到的RRAM、Flash非易失存储以外,芯片中用到最多的是SRAM,有制造上的优势。SRAM中也能够通过模拟方式实现矩阵/张量计算,免除了数据搬移,降低了计算功耗、提高了计算能效。
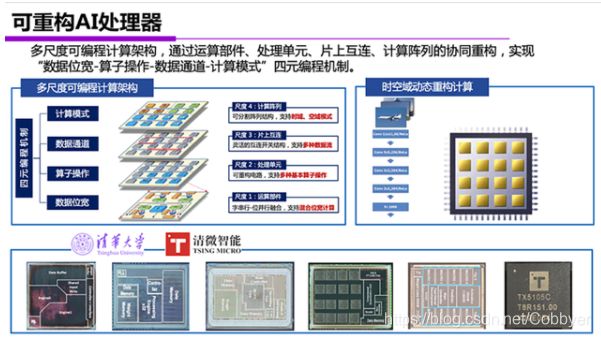
第四类是可重构AI处理器。用简单的词来概括可重构架构的特点,可以说它是一种空间阵列,计算单元在空间排成一个阵列结构,具有计算并行性;它也是近存计算,每个计算单元附近有存储单元,这样减少了数据搬移的距离;另外,它还具有弹性粒度的计算单元,通过电路重构支持多种数据位宽;随着算法需求变化,动态重构计算架构,灵活支持多种数据流,由数据驱动完成计算。
可重构AI处理器在运算部件、处理单元、片上互连、计算阵列等方面实现了分层次架构重构,各个层次在运算中协同配合,实现了多元编程机制,这样的架构克服了传统计算架构中数据位宽固定或者数据流固定的缺点,提升了AI计算的算力和能效。
例如,今天的神经网络中有一个典型需求是多数据位宽量化,一个神经网络中不同神经层可被量化成不同的数据位宽,可重构AI处理器的多尺度编程能力与之配合,可以显著减小模型体积、提高计算速度和能效。
四、解读神经形态处理器的两大研究路径
接着,尹首一教授讲解了AI芯片的另一大技术路线——神经形态处理器。
从技术路线角度来看,神经形态处理器可以被细分为两类:一是脉冲神经网络处理器,二是神经形态器件。
脉冲神经网络从数学上模拟了大脑神经网络中的脉冲放电机制,是对人脑神经网络的一种抽象。把脉冲神经网络的典型数学模型,通过电路方式实现出来,芯片在运行中就能模仿人脑计算的特点,即实现了一定程度的类脑计算。
例如,清华大学的天机(Tianjic)芯片,通过优化电路设计,不仅支持脉冲神经网络,而且同时支持深度神经网络,实现了深度神经网络和脉冲神经网络的“二合一”。此前大家看过一段演示视频,通过天机芯片控制实现了自行车的自动驾驶,展现了脉冲神经网络的智能处理能力。
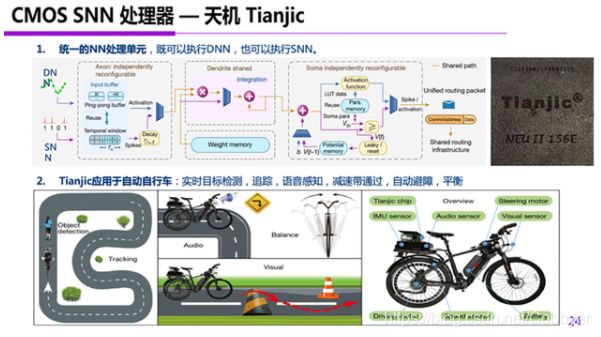
神经形态器件,则是设计一种物理器件,在物理上模拟神经元的行为。
应用离子动力学可以逼真地模拟生物突触的可塑性以及神经元工作机制,通过物理方式实现能够模拟神经元放电过程的器件。假如我们把大量的模拟人类神经元行为的器件互连起来,就有机会制造一个非常接近于人脑神经网络的系统,有望实现类脑智能。
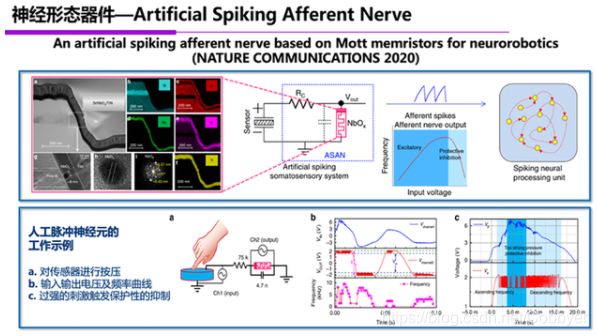
这里的代表性工作是中科院微电子所和麻省大学的合作成果,设计制备出了一种新型器件结构,当施加电脉冲以后,它的响应曲线和人脑神经元受到刺激后的响应曲线非常接近。大量的器件连起来,就能构造出类似人脑的神经网络系统。这就是通过神经形态器件的方式去实现人工智能计算的技术路线。
五、中国AI芯片产业创新正与国际同步
在演讲尾声,尹首一教授对AI芯片发展做了阶段性回顾和总结。
首先,经过五六年的发展,AI芯片已经取得非常大的成绩,但它仍然处于起步阶段,无论在科学研究还是产业应用方面,都具有非常广阔的创新空间。
其次,人工智能从算法和应用角度来讲,给芯片提出大量新需求,它将促使AI芯片去探索很多颠覆性的技术,彻底突破传统架构的性能和能效瓶颈,实现跨越式发展。
最后,中国的AI芯片创新与国际同步,今天中国AI芯片的技术路线最全面、应用领域最丰富,伴随着人工智能产业快速发展,中国AI芯片将大有可为。