一篇CVPR顶会论文是如何炼成的(一)
一、何为idea?

1、idea的重要性
idea的重要性其实怎么强调都不为过,它是一篇科研论文的灵魂,它是你的论文区别于其他论文最显著的一个差异。
我们要理解:做科研到底是在干什么?科研的本质,是在创新。不论你是找到一些新理论也好,还是有了一些新发现、新方法,还是有了一些新现象,这些东西都是需要有新的东西出来,那你的idea就是你找到的那个新内容最核心的一个观点。
到写论文的时候会通过学术论文的形式,给它整理出来一种既定的格式,然后表达出你的idea,那其实到这儿的话,你可能知道idea是个什么东西了,我们再从两个角度来说一下。
一个是审稿人的角度。审稿人去评审一篇论文,比如说在顶会论文上,就拿CVPR举例,我看了这篇论文之后去评价别人论文的novelty,我其实就看他的核心idea,他的核心idea如果让我觉得哇眼前一亮,觉得的确是很新,那我可能就对它的论文有一个非常好的印象,可能我会给他一个中等偏上的分数,如果他的论文novelty很差劲,那我可能就直接去掉,所以说论文的novelty就是为了专门评价这一项——新颖性(novelty),这个点大家一定要注意,novelty对于你论文最终被接收还是不被接收,有很大的影响。
一个是研究者的角度。那同样的,对于研究者来说,你的论文发出来之后,你是给别人看的,你是要给这个研究领域的其他研究者一些启发的,那别人看你的论文其实就看你论文的idea,他想知道的是,你的idea是不是能在我的问题上用得上,如果的idea能用在她关注的问题上,这个时候你的论文就会引用量很高,那你的学术影响力就会很大,这个时候对你来说,你在学术这个圈子里就越来越成功,但是这一切一切其实都是从一个idea开始,所以你要知道idea到底有多重要。

2、idea为如此难想?
然后第二个点,这可能是大家更关注的点——为什么我们都想不出来很好的idea,到底要怎么去创新?这个问题其实是真的困扰过很多人。也可能每个人刚做科研的时候都会有这个问题,包括我之前也是一直在思考这个问题,也问了很多师兄师姐啊,包括一些教授啊,大牛啊,都会有这种问题。
我自己也总结了一下,可能会有以下这几个原因:
2.1思维差异
第一个就是思维的差异。我们作为国内教育体系背景下成长起来的一代,在上大学之前,甚至在读研究生之前,你的所有的问题都是有标准答案的。但是在做科研的时候,你其实不是在找标准答案,这是一个开放的问题,这种情况下很多时候你可能不知道怎么入手。
2.2问题理解
第二个问题是你对自己研究的问题理解不够深,这个“深入”怎么理解?就是你得知道我现在研究的这个问题现有的解决方案,它的来龙去脉,它是怎么一步一步一步发展到现在的?所以这个时候你要回溯,就像计算机一种常见的思想,你要回溯到那个根节点,回溯到最根本的那个idea。
你现在这个问题的解决方案,肯定是经过了一次一次又一次前人的努力,才提出来,那你要对这个现有的研究方案的脉络非常清晰,同时你还得对它的理解非常深刻,很多时候你想到的idea的新颖程度就直接代表着你对这个问题理解的深入程度,这是有非常相关的关系的。
在这里我想问大家一个问题,你在你自己的这个研究领域看过多少篇相关的论文?直接能解决这个问题的论文你看过多少篇?
那如果我再问:现在让你马上能想到解决方案的论文,你能给我列出几类来?这又是一个问题。你看的所有的文献给它归个类,然后你要知道每篇都是要用什么样的方法来解决这个问题。
第三个问题,这个领域如果让你选出最重要的一篇文章,你能非常清晰地知道是哪篇吗?关于这一点很重要,我问这个问题就是想让大家去理解到:如果你对一个问题理解得足够深入,然后你能回溯到它最原始最重要的那篇文章,然后你又能再回到现在最新的这些文章来。如果你把这个关系理得非常的清楚,这些脉络也很清楚的话,其实在这个过程中你就会有一些idea出来,你就会去思考很多问题,这是问题的理解。
2.3逻辑断层
然后第三个点是逻辑的断层,这个地方会涉及到很多问题,但是无论是在义务教育阶段也好,在本科教育阶段也好,很少会涉及到教你怎么去训练你的逻辑思维,然后你解决问题的时候,可能逻辑里面很长时间是会有跳跃,swin transformer,clif transformer,这个时候这个逻辑思维,它可能真的在你遇到问题的解决的时候才会出来。
2.4及时反馈
那还有一个点就是及时的反馈,很多时候你有了想法,你也不知道这个想法靠不靠谱,你想跟别人交流你都找不到一个合适的人,你多想有个人给你一个合适的反馈,有经验的给你一个反馈和指导,那这个时候可能你的idea就可以慢慢慢慢被打磨成一个很简单有效的idea,可能可以发顶会的idea。
拿我自己的经验举例,我当时在读硕士期间其实也是属于导师放养。我那个时候就除了自己看网上各种资料,可能就是只能跟身边的个别同学去交流一下,这个是很无奈的一件事情,但其实真正的科研应该是导师在这个时候要起很重要的作用,要去跟你沟通,去指出你思维逻辑上的一些漏洞,指出你应该学习的方向,然后以她的经验告诉你你的idea到底可不可行,免得你自己就在那吭哧吭哧吭哧搞半天,然后发现诶原来是就是竹篮打水一场空,这个就是导师的作用,或者说是能有一些有经验的人给到你及时的反馈和指导的作用。
最终这些东西的缺失导致的一个结果就是,我们想不出来idea,我们想不出来那些能发顶会的idea,这就是现有的一个问题。

二、论文idea找寻方法
寻找idea的方案,或者说思考方向,我自己总结了几个点,一个是简化,第二个是结合,第三个是迁移,第四个是解释分析,第五个是寻新,这些都是足够发顶会的,是找到发顶会idea的一个方式,那接下来我会以很多的实际例子为例,来跟大家交流一下为什么这么说?

1、简化
idea的寻找方法,第一个我称之为叫简化,其实也很简单,就是把一个复杂的问题找到它最关键的核心点,或者说现有很多方法里面其实并不一定要那么复杂,你如果能找到一种简单的方法,能替代它,还能有好的效果,那这个时候对整个研究领域来说,就是一个很大的贡献,比如这篇论文,我们也知道,它就是(何)恺明当时2016年的CVPR的best paper。
他要解决的问题是,在当时那个阶段,深度学习你的网络如果再进一步的加深,性能反而会下降,并不是网络越深性能就会越好。(何)恺明为了解决这个问题,他猜测,不是因为网络深了,其实是因为没有一种合适的方式来训练,没有把网络给训练好。他自己就提到了这样一种网络结构,叫residual learning,就是图中的residual block。
当时这篇文章发出来之后,他的摘要部分也都说得很清楚,就是我的效果就是很好,然后我用了一个什么样的这种长x的结构。我们也知道现在他的单篇论文的引用就是12万,这也是恺明大神的一个成名之作。
这是关于简化这个点。
简化这个点要求你对问题有非常深入的思考,或者你对现有的方案非常熟悉,甚至在一些理论上能从一些角度去解释它的时候,或者是你们发现了一些很好的特性,然后从那些特性入手,提出一些很巧妙很简单有效的方案。
2、结合
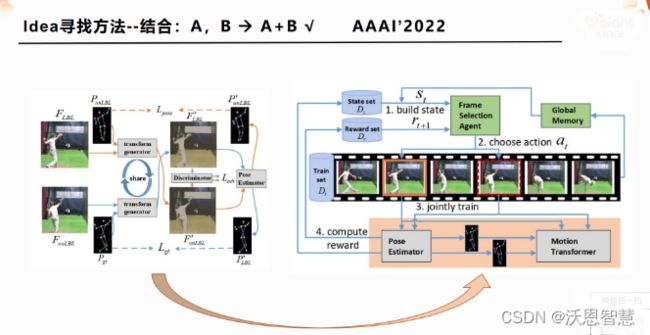
然后第二个叫结合,这个结合其实就是a+b,就是说在一个问题上,单纯用a也解决不好,单纯用b也解决不好,但是如果你把a+b合起来,当然这种合起来并不就是简单的相加,而是需要一个有机的结合,a的优点可以弥补b的缺点,b也可以弥补a的缺点,他俩优势可以结合,然后同时劣势又可以互补,那这样你找到一个a+b的方案之后再解决某个问题的时候,就会非常好,那这个地方我找了一篇AAAI' 2022的论文。
他做了一件什么事情呢?我们先看推导的部分吧,结合是大多数人采用的方法,很直观,我们先看为什么它的a+b就可以发顶会论文。
那我们先看a的部分叫做jointly train PE and MT,这篇文章他是用了两张图片,就是从视频帧里面取了两张图片,一个叫F LBL,一个叫F unLBL,一张是有标签的图片,一张是没有标签的图片,这个时候要解决的问题是什么?就是说我在一段视频序列当中只有少量的标签,他做的是一个叫samistlize learning的问题,他最终的目标是为了提高通过这种少量标签的那些视频,然后让姿态估计器去学到一个更精确的姿态,再尽可能的用少量的标签,多用它视频中那种免费的天然存在的持续信息来解决这个问题。
我们看一下那个橙色的线经过transfomer generator,然后就从一个P unLBL就这个pose然后跟F LBL这两个作为输入,然后输出了一个另外一张图,那这个F unLBL就是下面这个F unLBL的姿态,那相当于对他做了一个姿态的一个转换,那转换后的图,这个F'LBL其实是可以用F unLBL去监督的,所以说这个地方有一个自监督,你可以把任意的视频当中的一张图片用一种transform的一种形式,把它变成另一个姿态下的图片,但是这个姿态下的图片,他天然的,他有原图,她就可以做一个自监督,然后自监督这个时候再去更新的时候,就会同时更新这个姿态的这种迁移transform generator 和discriminator,这个时候就能让这个姿态估计器的性能不断去提升。
那这个时候有个问题,他当时论文里面就提到说,如果这两张图片离得过于接近,那就没有这种转换图的必要了,反正图都是一样的,你转换啥?没有新信息进来,你的姿态估计系统就不能学到新信息,就不能提升。另外一点就是如果两张图片差异过大的话,那这个transform enerator就没有办法能很好的去生成,它就会失效了,它的capacity是有限的,它就会失效,然后最终导致这个姿态估计不准确,所以说它接着会引来一个问题,就是我现在单纯用a这种方式不能解决这个姿态估计的问题,因为这两张图片是有一个合适的运动间距的,这两张图片的运动差异不能过大也不能过小。
那这个时候很自然的,强化学习就可以用来干这件事情,我们看a这个部分其实就对应的是第二张图里面3的jointly train,用这个粉色框表示的,这个时候选哪两张图来做这个jointly train呢?那这个时候就用了强化学习的一个策略,它会去判断,我到底把哪两张图给到这个联合训练的时候,它的姿态估计器的性能会变好,它就这样反复地去尝试迭代,就会找到一些合适的方案,那这个点就是把a和b给巧妙的结合了起来,b可以解决a的一些问题,a和b综合在一起,整体的一个学习框架就可以更好地去解决这个姿态估计器的问题,然后就是这个问题就是a不能解决这个问题,b也不能解决,但是a+b就可以解决,就是一种结合的方式,也是很常见的方式.
怎么去结合,你怎么去把你的结合说的非常的让审稿人去信服,然后你是怎么去思考这个问题?那这个时候就有很多的一些细节需要去考虑,直接结合肯定是不行的,难道我现在就直接拿一个强化学习的方案?强化学习有很多种策略,那我到底选哪一种呢?它的优化策略有很多种,那这个时候到底应该用哪一个去跟a做这个结合呢,这个时候你就要考虑所以这个实际的问题,他的这个视频这个序列,他的那个整体的一个情况,运动变化的情况,然后再来选择具体的这个强化学习的优化策略和优化方案.
所以说,你把这两个整体结合之后,它就是很漂亮的一个方案,别人就会觉得你把强化学习用在这个问题上,然后你又做了这个点,嗯,效果又很好,那一般就很难会拒绝,CVPR的审稿中稿率是15%吧,今年其实是很低的,好像是创了历史新低吧,但这篇文章还是中稿了。

3、迁移
第三个点也是很常用的点,就是迁移。
就是方法a在b这个领域可以做得很好,那方法a在c这个领域能不能做好?这个其实是一个很自然的迁移,这里面我举了一个现在大家耳熟能详的例子啊,就是transformer,然后在视觉领域的应用是这篇叫image divorce,16×16的一个words,这篇文章就是叫vit,它把transformer这种架构引入到了计算机视觉的领域来,他做的任务是image recognition,就是识别任务,最简单的识别和分类任务。它在尽可能的保留了原有transformer的架构上做了最小的改动,然后就印证了transformer这种架构可以很有效的去解决视觉里面的分类问题。这是前人从来没有过的尝试。
Vision Transformer(VIT)这篇文章最重要的点就是,它是第一个把已经在NLP领域运用的很成熟的transformer架构用在了CV当中,他把一张图切成了很多的patch,然后把这个patch作为了word embedding,给它输入到transformer encoder,再加上它里面的一些position embedding ,经过transformer encoder不断地去做self attention...然后得到了这个最终的特征,再做一个MLP的分类,然后我们可以得到一个输出结果。这是他的贡献,2020年就发表了,到现在两年过去了,已经有5000的引用量,这是什么水平?很多研究者一辈子可能引用量都达不到5000,他一篇文章就到5000。
这就是迁移,那我们要做这个迁移,可能对我们现在其实很难,那接下来呢,还可以再继续迁移下,现在是transformer在识别这个任务上去做,那它在其他的分割,目标检测领域怎么样呢?那肯定会有人接着这个思路再继续探究下去,那这个时候swim transformer这个架构也就出来了,当时swim transformer不光能解决这个分类问题,还可以解决检测问题,也可以解决分割这个问题。
它也是20年的ICCV的best paper,然后现在引用量已经很高了,嗯,可能有人觉得迁移不太好想,因为能迁移的都让人想到了,那这个时候就看谁会先想到,你可以问为什么不是你先想到这个,为什么不是你先把它做出来?其实很多idea都有人在做,那为什么就只有那几个人成功了,这里面是有一些问题你可以思考的。有很多人会这样想,但是最终谁能做出来,这又是一回事。
还有一点,我们再继续看,我们再回到一个更小的一个问题上,叫domain-adaptation,这个domain-adaptation是什么意思呢?就是叫预迁移,也是我研究的方向之一,它就相当于是你在原域上去学模型的一些知识,然后把它用在目标域上,目标域上是没有标签的,就是想把原域上的知识迁移到目标域上来,之前一直都是在用DeepLabV2,或者ResNet这些最经典的一些架构,但从2022年才有人用transformer来做这件事情,然后我们可以看图片右下角,它的性能提升是非常非常明显的。相对于其他的方案来说,它的提升非常非常明显,这里面有DeepLabV2,有DeepLabV 3+,但是DAFormer这种架构可以实现的很好。
迁移要求我们对各个领域都很熟悉吗?那也不一定。很多时候也不是说,我好像对所有的知识都很清楚了之后我一下就想到了一个很有效的方案,很多时候思维过程不是这样,它是一步步去探索,我现在想这个transformer能不能用在我的idea这个领域?你先有了这个想法,有了这个问题,然后你就开始要去调研,开始去做一些实验,去逐步的验印证你的想法,如果你实验做的快,然后实验结果又好,那你基本就可以写完就投稿先挂上。
4、解释分析
接着我们再看下一个点,叫解释分析。
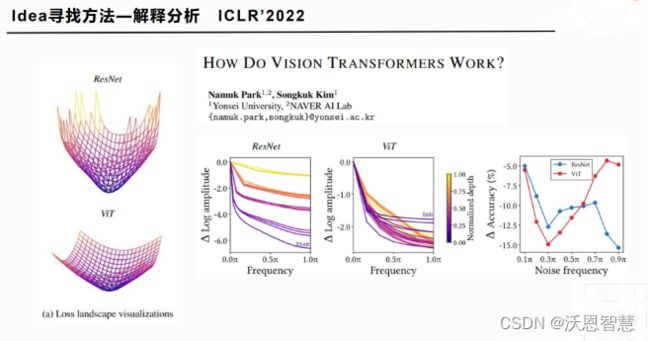
解释分析是什么意思呢?就是你不需要去提新方法,只需要给出一些insight,给出一些原因的猜想,或者是一些动静,或者你通过大量的实验证明了某种方法为什么好,或者某些方法就是比其他方法要更好,这个地方就是ICLR 2022年的那篇论文,可解释性,这种文章你不需要去提新方法,也不需要搜它的结果,你只需要在现有的别人已经提出的模型等这些基础上,能去找到一些分析的工具,然后给它做一下综合的分析,能得到一些初步的结论,就能发文章,但是这个要求理论的水平或者研究的适应性要很广泛,还有就是你要有一定的基础。并不是每个人都想去解释,也并不是每个人都能解释,一个是你的意愿,你想做,另外一个是你的能力,你做不做得到,这是两回事。
这篇文章他想解释为什么vision transformer这么有效,他在noise的下降啊,做了一些可视化,也做了一些分析,包括noise frequency,它都有一些分析,最终给出了一些结论。这种文章都发在哪?他发在了ICLR这个顶会上,它是一个机器学习的顶会。
那另外一篇我觉得也很有意思,可以给大家看一下,这篇是发在NIPS上的一篇spotlights,spotlights的含义,就相当于是已经中稿的论文里面会再选一部分文章,然后给一个更高的奖项。best paper这种就是最最顶尖那种,一个会议就那么一两篇。

那我们看一下这篇文章到底是在干什么?它是一个图像恢复网络,然后他发现了一个很神奇的东西,就是一个网络当中有一些这种filter,是专门用来做deblur(去模糊)的,有一些filter是专门用来做denoise的,这是他的一个发现,我们可以看两张图,前面的两个输入,也就是1和5。
图5里面明显在原图上加了一些什么东西,其实很简单,这是两种退化类型,一种是模糊,一种是噪声,然后又通过这同一个网络,2和6它可以把这两个东西都去掉,不论你是噪声还是模糊,都可以把它去掉,这是这个网络本来有的一种特性,一种功能。
那我们再看第三列,第三列是叫mask1%的deblur的filter,它把网络中那部分专门用来做去模糊的这些滤波把它给mask掉了,不起作用了,那现在它的结果变成什么?1到3的去模糊性能没有了,现在只能去噪了,有没有觉得很神奇?一个网络,你竟然可以去控制它的功能。
然后再看第四列,有什么差别呢?
第四列也是同样的mask1%去噪的filter(过滤器/滤波器),这种滤波器把去噪那部分去掉之后,果然带噪声的图片它就去不掉了,它现在只能去掉模糊的图片。
怎么去判断哪一部分的滤波器负责去噪,哪一部分负责去模糊?
同一个网,如何控制?这就是这篇论文最核心的一个发现,他发现网络在filter的层面,它们竟然是各自有一些特性,它自己会去区分,有一些filter就是用来做去模糊了,有一些就是用来做去噪的,那这个是怎么控制的?我们得具体深入到他论文里面去,怎么去定义这个deblurring filter和denoising filter,这个大家后续有兴趣可以去看一下那篇论文。
然后这个之外的话,我们再看,我们现在已经发现网络有这种很神奇的现象,它自己有一些分别的区分不同噪声的能力,那作者就在下面做了一个可视化,这个可视化有两张图,第一张图discovered filters for deblurring,它通过类似归因的一种方式,找到了用来做deblur的那些filter,他会发现这些filter其实是偏向于网络的后侧,网络的深层,就是靠后的那些层,但是后来去噪的那些filter,它其实比较均匀,前后都有。
这篇论文其实就介绍了这些,他也没有提什么新方法,他也可以发NIPS,但其实这个点对大家去做这个方向,提供了很多insight,他会告诉你这个网络其实在不同层,它的不同的filter其实有不同的功能,你是可以做到去控制网络的,通过控制它的filter来控制它最终的一个性能的。上面的deblur和denoise这两种最明显,这就相当于你是在有一点点去解释,试着去解释图像恢复网络一些功能上的差异,其他人也可以基于此在你的技术上去做进一步的探索,那这个时候别人就会引用你的论文,就会觉得你的论文很不错,会给你的论文很高的评价。
那这几种idea的方式,有没有优劣之分?评价一个论文idea的优劣,其实你找的方式它本身是没有优劣之分的,每一种方式你都可以做出足够优秀的文章,可以做出足够的贡献,关键是你要做的深入,不论是沿着哪个方向去做,你要做的深入,能给大家很多的insight,或者说你的论文效果很好,或者说你能给上我说的这种解释分析的这些文章,你可以给很多的人一些别人可以参考的点。

5、寻新
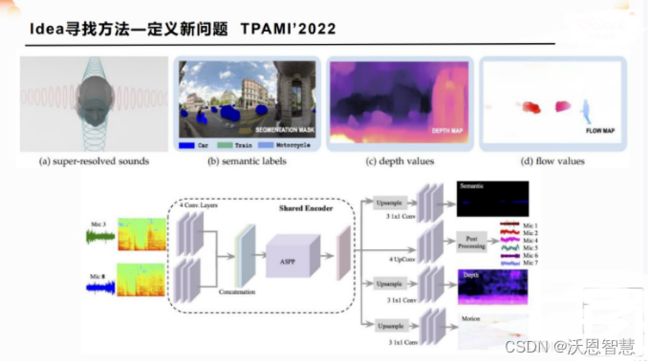
然后再回到最后一点,叫新问题,我当时是想到这一点之后,我觉得我看过的一篇很重要的论文就很自然地浮现出来。
这个也属于自动驾驶的一篇论文,然后它是做什么的?它是做的音频信号,靠耳朵,可以说是让神经网络去听周围的这些东西是啥,去听周围的这些场景的深度信息,去听现在这些人的一个变化,他的motion,他的运动变化。我们做的很多都是用RGB去看,那现在是让这个cn网络去听,你只需要有两个麦克风,然后去把音频信息输进去,它也可以同样地去处理,然后得到一些语音信息。
比如说,一个车是不是在离我越来越近?那个东西是个人,离我多远地方的是个人还是个车,还是一个建筑,那就是一个静态物体,他还能感知场景的一些深度信息,包括人类的运动,这个就是今年2022年TPAMI刚发表的一篇文章,在我看来就是非常的巧妙,这种就是挖坑嘛,你定义了一个新问题之后,别人就会关注到这个信息,他有兴趣的话就会去进一步地研究这个新问题,他会知道哦,那我还能用其他的方式来做这件事情吗?我之前想到的一些方法能用在这个上面吗?
那这个时候就会有一个很有意思的事情,你把这个坑挖了之后,别人就会不断地朝里面跳。
第二个是叫做ACDC:adverse conditions dataset with correspondences for semantic driving scene understanding,它提到了一个叫恶劣场景,它把四种天气的恶劣场景,比如说夜晚,包括有雾的场景,雨天的场景,还有雪天的场景,这些场景他给它们分门别类地去做了整理,然后提供了一些数据集,而且还进行了一些人为的标注,就可以去做有监督的这种训练,也可以去做无监督的适应,然后他把这个任务定义出来了,发了一篇论文,你可以说这是一类的做数据集,或者定义新问题的时候常见的一种套路,但是你得有嗅觉,你得知道这是你去引领一个研究方向,你自己在引领一个研究方向,你这篇文章肯定就是开山之作,那别人如果觉得你这个方向很有搞头,他可能就会跳进来,接着你的方向去探索,那所有的人都会引用你的论文,你论文的流量就会很高。
他的论文里面把这个数据集提出来之后,就把现有的方法在他的数据集上去做了一个评测,我在四种天气下,大家提了各种各样的分割模型,到底怎么样?这种预迁移的模型到底怎么样?那我们就来比一比,我用这种实际的场景的数据,我们来比一比看看,然后就会发现好像大家都不太好,这个R出口就是你本来模型应该有的性能,然后中间的这些迁移方法也可以看到,没有很明显的提升,跟这个baracle其实差别挺大的。
除了这个点之外,他还做了一个网站,是一个在线提交的榜单,会实时更新,你们提交上去的方法,它的一个性能,它的数据集,它的测试集部分的标签没有公布出来,你只能提交到服务器上,然后你有一个成绩之后,在这上面公布出来,我们可以看到形象很活跃,各种各样的方法,6月3号,6月13号,6月4号,很多人在那上面去提自己的方法,然后去验证自己的一些思路,那就说明其实现在这个领域肯定就会越来越火,大家的关注就会越来越多。这就是定义新方法。

三、近期研究热点解析
这个东西是我在知乎上有一天刷到了,发现这是一个专门做数据挖掘的,他去分析了一下近三年的CVPR,他定义了一个影响因子叫交叉影响因子,这个影响因子代表的含义就是中稿的量和它的引用量的一个综合评分。在热点方向上和可综合学习范式上,你们可以看一下自己做的方向,在这个热点方向的排名也好,或者在这个可学习范式相关的都排在哪个水平,或者它的热度现在到底有多少。
给大家这样一个参考之后,大家就知道原来目标检测其实在现在CVPR顶会上经常会发表,GAN啊,NeRF啊,NeRF可以说是近两年最火的方向,在三维视觉越来越火的今天是起了一个非常大的作用,然后在可学习范式里面也是自监督学习self-supervised learning,SSL,你们应该经常能见到,然后小样本学习,还有domain adaption,还有OOD分布外学习。这个就是整体的一个情况。