Spring事务处理
事务(Transaction)是并发控制的单位,是用户定义的一个操作序列。这些操作要么都做,要么都不做,是一个不可分割的工作单位。
数据库向用户提供保存当前程序状态的方法,叫事务提交(commit);当事务执行过程中,使数据库忽略当前的状态并回到前面保存的状态的方法叫事务回滚(rollback)
事务特性(ACID)
原子性(atomicity):将事务中所做的操作捆绑成一个原子单元,即对于事务所进行的数据修改等操作,要么全部执行,要么全部不执行。
一致性(Consistency):事务在完成时,必须使所有的数据都保持一致状态,而且在相关数据中,所有规则都必须应用于事务的修改,以保持所有数据的完整性。事务结束时,所有的内部数据结构都应该是正确的。
隔离性(Isolation):由并发事务所做的修改必须与任何其他事务所做的修改相隔离。事务查看数据时数据所处的状态,要么是被另一并发事务修改之前的状态,要么是被另一并发事务修改之后的状态,即事务不会查看由另一个并发事务正在修改的数据。这种隔离方式也叫可串行性。
持久性(Durability):事务完成之后,它对系统的影响是永久的,即使出现系统故障也是如此。
事务隔离(Isolation Level)
事务隔离意味着对于某一个正在运行的事务来说,好像系统中只有这一个事务,其他并发的事务都不存在一样。
大部分情况下,很少使用完全隔离的事务。但不完全隔离的事务会带来如下一些问题。
更新丢失(Lost Update):两个事务都企图去更新一行数据,导致事务抛出异常退出,两个事务的更新都白费了。
脏数据(Dirty Read):如果第二个应用程序使用了第一个应用程序修改过的数据,而这个数据处于未提交状态,这时就会发生脏读。第一个应用程序随后可能会请求回滚被修改的数据,从而导致第二个事务使用的数据被损坏,即所谓的“变脏”。
不可重读(Unrepeatable Read):一个事务两次读同一行数据,可是这两次读到的数据不一样,就叫不可重读。如果一个事务在提交数据之前,另一个事务可以修改和删除这些数据,就会发生不可重读。
幻读(Phantom Read):一个事务执行了两次查询,发现第二次查询结果比第一次查询多出了一行,这可能是因为另一个事务在这两次查询之间插入了新行。针对由事务的不完全隔离所引起的上述问题,提出了一些隔离级别,用来防范这些问题。
读操作未提交(Read Uncommitted):读取未提交的数据是允许的。说明一个事务在提交前,其变化对于其他事务来说是可见的。这样脏读、不可重读和幻读都是允许的。当一个事务已经写入一行数据但未提交,其他事务都不能再写入此行数据;但是,任何事务都可以读任何数据。这个隔离级别使用排写锁实现。
读操作已提交(Read Committed):读取未提交的数据是不允许的,它使用临时的共读锁和排写锁实现。这种隔离级别不允许脏读,但不可重读和幻读是允许的。
可重读(Repeatable Read):说明事务保证能够再次读取相同的数据而不会失败。此隔离级别不允许脏读和不可重读,但幻读会出现。
可串行化(Serializable):提供最严格的事务隔离。这个隔离级别不允许事务并行执行,只允许串行执行。这样,脏读、不可重读或幻读都可发生。
1. 1事务隔离与隔离级别的关系
| 隔离级别 |
脏读(Dirty Read) |
不可重读(Unrepeatable read) |
幻读(Phantom Read) |
| 读操作未提交(Read Uncommitted) |
可能 |
可能 |
可能 |
| 读操作已提交(Read Committed) |
不可能 |
可能 |
可能 |
| 可重读(Repeatable Read) |
不可能 |
不可能 |
可能 |
| 可串行化(Serializable) |
不可能 |
不可能 |
不可能 |
事务的传播(Propagation)
| 事务传播行为类型 |
说明 |
| PROPAGATION_REQUIRED |
如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是 最常见的选择。 |
| PROPAGATION_SUPPORTS |
支持当前事务,如果当前没有事务,就以非事务方式执行。 |
| PROPAGATION_MANDATORY |
使用当前的事务,如果当前没有事务,就抛出异常。 |
| PROPAGATION_REQUIRES_NEW |
新建事务,如果当前存在事务,把当前事务挂起。 |
| PROPAGATION_NOT_SUPPORTED |
以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。 |
| PROPAGATION_NEVER |
以非事务方式执行,如果当前存在事务,则抛出异常。 |
| PROPAGATION_NESTED |
如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与 PROPAGATION_REQUIRED 类似的操作。 |
当使用 PROPAGATION_NESTED 时, 底层的数据源必须基于 JDBC 3.0 ,并且实现者需要支持保存点事务机制。
readOnly
事务属性中的readOnly标志表示对应的事务应该被最优化为只读事务。这是一个最优化提示 。在一些情况下,一些事务策略能够起到显著的最优化效果,例如在使用Object/Relational映射工具 (如:Hibernate或TopLink)时避免dirty checking(试图“刷新”)。
Timeout
在事务属性中还有定义“timeout”值的选项,指定事务超时为几秒。在JTA中,这将被简单地传递到J2EE服务器的事务协调程序,并据此得到相应的解释。
例子:
ServiceA {
void methodA() {
try {
//savepoint
ServiceB.methodB();
}
catch (SomeException) {
// 执行其他业务, 如 ServiceC.methodC();
}
}
}
1: PROPAGATION_REQUIRED
加入当前正要执行的事务不在另外一个事务里,那么就起一个新的事务
例如:
ServiceB.methodB的事务级别定义为PROPAGATION_REQUIRED
ServiceA.methodA已经起了事务,这时调用ServiceB.methodB,ServiceB.methodB就加入ServiceA.methodA的事务内部,就不再起新的事务。ServiceA.methodA没有在事务中,这时调用ServiceB.methodB,
ServiceB.methodB就会为自己分配一个事务。
在ServiceA.methodA或者在ServiceB.methodB内的任何地方出现异常,事务都会被回滚。即使ServiceB.methodB的事务已经被提交,但是ServiceA.methodA在接下来fail要回滚,ServiceB.methodB也要回滚
2: PROPAGATION_SUPPORTS
如果当前在事务中,即以事务的形式运行,如果当前不再一个事务中,那么就以非事务的形式运行
3: PROPAGATION_MANDATORY
必须在一个事务中运行。也就是说,他只能被一个父事务调用。否则,他就要抛出异常
4: PROPAGATION_REQUIRES_NEW
例如:
ServiceA.methodA的事务级别为PROPAGATION_REQUIRED,ServiceB.methodB的事务级别为PROPAGATION_REQUIRES_NEW,
当调用ServiceB.methodB的时候,ServiceA.methodA所在的事务就会挂起,ServiceB.methodB会起一个新的事务,等待ServiceB.methodB的事务完成以后,他才继续执行。
PROPAGATION_REQUIRES_NEW与PROPAGATION_REQUIRED 的事务区别在于事务的回滚程度:
因为ServiceB.methodB和ServiceA.methodA两个不同的事务。如果ServiceB.methodB已经提交,那么ServiceA.methodA失败回滚,ServiceB.methodB是不会回滚的。如果ServiceB.methodB失败回滚,
如果他抛出的异常被ServiceA.methodA捕获,ServiceA.methodA事务仍然可能提交。
5: PROPAGATION_NOT_SUPPORTED
当前不支持事务。
例如:
ServiceA.methodA的事务级别是PROPAGATION_REQUIRED ,而ServiceB.methodB的事务级别是PROPAGATION_NOT_SUPPORTED ,
调用ServiceB.methodB时,ServiceA.methodA的事务挂起,而以非事务的状态运行完,再继续ServiceA.methodA的事务。
6: PROPAGATION_NEVER
不能在事务中运行。
假设ServiceA.methodA的事务级别是PROPAGATION_REQUIRED, 而ServiceB.methodB的事务级别是PROPAGATION_NEVER ,
那么ServiceB.methodB就要抛出异常了。
7: PROPAGATION_NESTED
理解Nested的关键是savepoint。他与PROPAGATION_REQUIRES_NEW的区别是,PROPAGATION_REQUIRES_NEW另起一个事务,将会与他的父事务相互独立,
而Nested的事务和他的父事务是相依的,他的提交是要等和他的父事务一块提交的。也就是说,如果父事务最后回滚,他也要回滚的。
而Nested事务的好处是他有一个savepoint。
Spring中的事务管理
作为企业级应用程序框架,Spring在不同的事务管理API之上定义了一个抽象层。而应用程序开发人员不必了解底层的事务管理API,就可以使用Spring的事务管理机制。
Spring既支持编程式事务管理(也称编码式事务),也支持声明式的事务管理
编程式事务管理:将事务管理代码嵌入到业务方法中来控制事务的提交和回滚,在编程式事务中,必须在每个业务操作中包含额外的事务管理代码
声明式事务管理:大多数情况下比编程式事务管理更好用。它将事务管理代码从业务方法中分离出来,以声明的方式来实现事务管理。事务管理作为一种横切关注点,可以通过AOP方法模块化。Spring通过Spring AOP框架支持声明式事务管理。
Spring的事务管理器
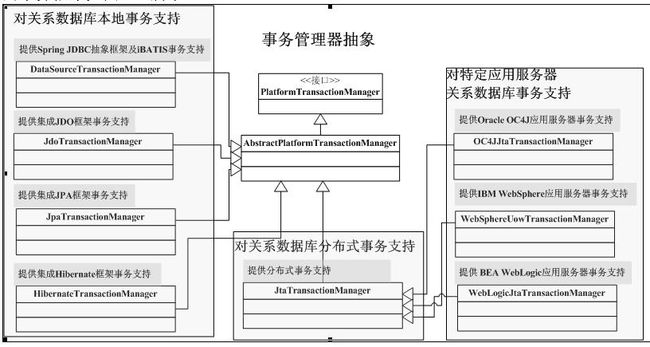
Spring并不直接管理事务,而是提供了多种事务管理器,它们将事务管理的职责委托给JTA或其他持久化机制所提供的平台相关的事务实现。每个事务管理器都会充当某一特定平台的事务实现的门面,这使得用户在Spring中使用事务时,几乎不用关注实际的事务实现是什么。
Spring提供了许多内置事务管理器实现:
- DataSourceTransactionManager:位于org.springframework.jdbc.datasource包中,数据源事务管理器,提供对单个javax.sql.DataSource事务管理,用于Spring JDBC抽象框架、iBATIS或MyBatis框架的事务管理;
- JdoTransactionManager:位于org.springframework.orm.jdo包中,提供对单个javax.jdo.PersistenceManagerFactory事务管理,用于集成JDO框架时的事务管理;
- JpaTransactionManager:位于org.springframework.orm.jpa包中,提供对单个javax.persistence.EntityManagerFactory事务支持,用于集成JPA实现框架时的事务管理;
- HibernateTransactionManager:位于org.springframework.orm.hibernate3包中,提供对单个org.hibernate.SessionFactory事务支持,用于集成Hibernate框架时的事务管理;该事务管理器只支持Hibernate3+版本,且Spring3.0+版本只支持Hibernate 3.2+版本;
- JtaTransactionManager:位于org.springframework.transaction.jta包中,提供对分布式事务管理的支持,并将事务管理委托给Java EE应用服务器事务管理器;
- OC4JjtaTransactionManager:位于org.springframework.transaction.jta包中,Spring提供的对OC4J10.1.3+应用服务器事务管理器的适配器,此适配器用于对应用服务器提供的高级事务的支持;
- WebSphereUowTransactionManager:位于org.springframework.transaction.jta包中,Spring提供的对WebSphere 6.0+应用服务器事务管理器的适配器,此适配器用于对应用服务器提供的高级事务的支持;
- WebLogicJtaTransactionManager:位于org.springframework.transaction.jta包中,Spring提供的对WebLogic 8.1+应用服务器事务管理器的适配器,此适配器用于对应用服务器提供的高级事务的支持。
Spring不仅提供这些事务管理器,还提供对如JMS事务管理的管理器等,Spring提供一致的事务抽象如图9-1所示。
Spring事务的事务超时
为了使应用程序更好的运行,事务不能运行太长的时间。因此,声明式事务的第四个特性就是超时。
Spring事务的回滚规则
默认情况下,事务只有在遇到运行期异常时才会回滚,而在遇到检查型异常时不会回滚,但是也可以声明事务在遇到特定的检查型异常时像遇到运行期异常那样回滚。同样,你还可以声明事务遇到特定的异常不回滚,即使这些异常是运行期异常。
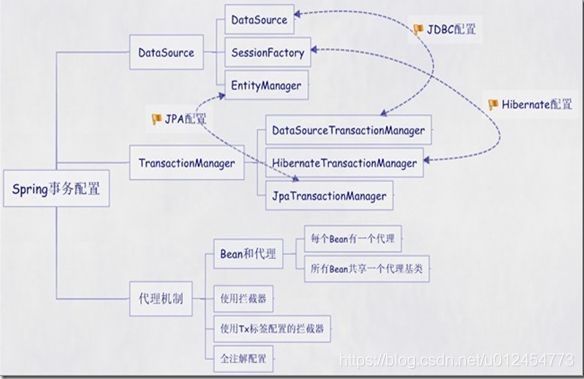
Spring事务处理
Spring配置文件中关于事务配置总是由三个组成部分,分别是DataSource、TransactionManager和代理机制这三部分,无论哪种配置方式,一般变化的只是代理机制这部分。
DataSource、TransactionManager这两部分只是会根据数据访问方式有所变化,比如使用Hibernate进行数据访问 时,DataSource实际为SessionFactory,TransactionManager的实现为 HibernateTransactionManager。
具体如下图:
第一种方式:每个Bean都有一个代理
PROPAGATION_REQUIRED
第二种方式:所有Bean共享一个代理基类
PROPAGATION_REQUIRED
第三种方式:使用拦截器
PROPAGATION_REQUIRED
*Dao
transactionInterceptor
第四种方式:使用tx标签配置的拦截器
第五种方式:全注解
此时在DAO上需加上@Transactional注解,如下:
package com.bluesky.spring.dao;
import java.util.List;
import org.hibernate.SessionFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.orm.hibernate3.support.HibernateDaoSupport;
import org.springframework.stereotype.Component;
import com.bluesky.spring.domain.User;
@Transactional
/**
@Transactional 可以作用于接口、接口方法、类以及类方法上。当作用于类上时,该类的所有 public 方法将都具有该类型的事务属性,
同时,我们也可以在方法级别使用该标注来覆盖类级别的定义,
并且我们在方法级使用注解时,也可以在方法内部手动回滚事务:
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
虽然 @Transactional 注解可以作用于接口、接口方法、类以及类方法上,但是 Spring 建议不要在接口或者接口方法上使用该注解,因为这只有在使用基于接口的代理时它才会生效。
另外, @Transactional 注解应该只被应用到 public 方法上,
这是由 Spring AOP 的本质决定的。如果你在 protected、private 或者默认可见性的方法上使用 @Transactional 注解,这将被忽略,也不会抛出任何异常。
默认情况下,只有来自外部的方法调用才会被AOP代理捕获,也就是,类内部方法调用本类内部的其他方法并不会引起事务行为,即使被调用方法使用@Transactional注解进行修饰。
*/
@Component("userDao")
public class UserDaoImpl extends HibernateDaoSupport implements UserDao {
public List listUsers() {
return this.getSession().createQuery("from User").list();
}
[点击并拖拽以移动]
} Spring事务处理原理
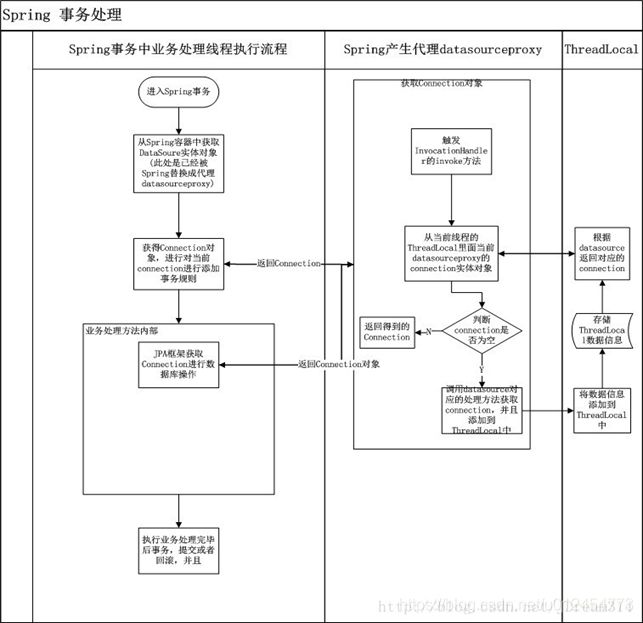
问题:
1、当JPA框架对数据库进行操作的时候,是从那里获取Connection?
2、jdbc对事务的配置,比如事务的开启,提交以及回滚是在哪里设置的?
3、Spring是通过aop拦截切面的所有需要进行事务管理的业务处理方法,那如何获取业务处理方法里面对数据库操作的事务呢?
解答:
1、既然在JPA的框架里面配置了datasource,那自然会从这个datasource里面去获得连接。
2、jdbc的事务配置是在Connection对消里面有对应的方法,比如setAutoCommit,commit,rollback这些方法就是对事务的操作。
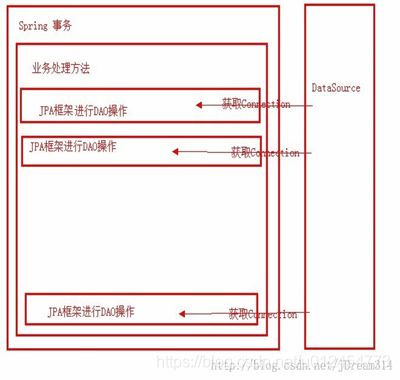
3、Spring需要操作事务,那必须要对Connection来进行设置。Spring的AOP可以拦截业务处理方法,并且也知道业务处理方法里面的 DAO操作的JAP框架是从datasource里面获取Connection对象,那么Spring需要对当前拦截的业务处理方法进行事务控制,那 必然 需要得到他内部的Connection对象。整体的结构图如下:
JAVA检查时异常(checked异常)、运行期异常(unchecked异常)说明
引用:详解Java中的checked异常和unchecked异常
(1)Java的异常层次结构
要想明白Java中checked Exception和unchecked Exception的区别,我们首先来看一下Java的异常层次结构。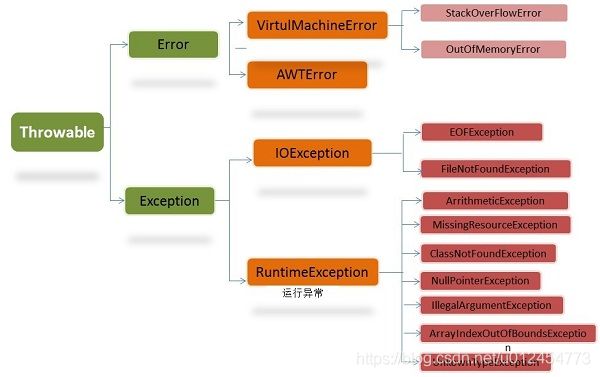
这是一个简化的Java异常层次结构示意图,需要注意的是所有的类都是从Throwable继承而来,下一层则分为两个结构,Error和Exception。其中Error类层次描述了Java运行时系统的内部错误和资源耗尽错误,这种错误除了简单的报告给用户,并尽力阻止程序安全终止之外,一般也米有别的解决办法了。
(2)unchecked异常和checked异常的区别
有了上面的认识之后,我们再来看什么是checked异常,什么是unchecked的异常。其实,Java语言规范对这两个定义十分简单,将派生于Error或者RuntimeException的异常称为unchecked异常,所有其他的异常成为checked异常。尽管,这个定义十分简单,但是RuntimeException却是一个非常让人容易混淆的观念,似乎我们所有的异常都是在程序运行的过程中。我《Effective Java》中关于Ru ntimeException异常的阐述也不是那么尽如人意,
Use checked exceptions for recoverable conditions and runtime exceptions for programming errors (Item 58 in 2nd edition)不过从这句话中我们可以简单引申一下,也就是说,如果出现了RuntimeException,就一定是程序员自身的问题。比如说,数组下标越界和访问空指针异常等等,只要你稍加留心这些异常都是在编码阶段可以避免的异常。如果你还是觉得这两个概念不好区分,那么“最暴力“的方法就是将常见的RuntimeException背下来,这样就可以省去很多判断的时间。
(3)为什么要对unchecked异常和checked异常进行区分?
原因其实很简单,编译器将检查你是否为所有的已检查异常提供了异常处理机制,比如说我们使用Class.forName()来查找给定的字符串的class对象的时候,如果没有为这个方法提供异常处理,编译是无法通过的。
Use checked exceptions for recoverable conditions and runtime exceptions for programming errors (Item 58 in 2nd edition)(4)我们应该对哪些异常进行声明?
我们前面说,RuntimeException是在programing过程中可以避免的错误,那是不是我们就不需要抛出这些异常呢?原则上来说,是这样的,但是Java规范中并没有对此进行限制,只是看上去你抛出一个数组越界的异常并没有多少实际意义,相反还会对性能造成一定的损失。那么我们应该如何来设计抛出异常呢?我们要记住以下两种情况是必声明throws异常的:
1、 调用一个checked异常的方法,例如IOException,至于原因我们前面已经讨论过了,如果抛出所有的checked异常时无法通过编译的。
2、程序运行过程中发现错误,利用throw语句抛出一个异常。
3、 对于unchecked异常,无非主要是两种情况要么是可以避免的(Runtime Exception),要么是不可控制的。这些也是需要声明异常的。
Exception不回滚解决方案
1、 原因
(1) Checked异常必须被显式地捕获或者传递,如Basic try-catch-finally Exception Handling一文中所说。而unchecked异常则可以不必捕获或抛出。
(2)Checked异常继承java.lang.Exception类。Unchecked异常继承自java.lang.RuntimeException类。
(3)Runtime Exception: 在定义方法时不需要声明会抛出runtime exception;在调用这个方法时不需要捕获这个runtime exception;runtime exception是从java.lang.RuntimeException或java.lang.Error类衍生出来的。例如:nullpointexception,IndexOutOfBoundsException就属于runtime exception
(4)Exception:定义方法时必须声明所有可能会抛出的exception;在调用这个方法时,必须捕获它的checked exception,不然就得把它的exception传递下去;exception是从java.lang.Exception类衍生出来的。例如:IOException,SQLException就属于Exception
默认情况下,如果被注解的数据库操作方法中发生了unchecked异常,所有的数据库操作将rollback;如果发生的异常是checked异常,默认情况下数据库操作还是会提交的。而Exception是checked异常,所以不会回滚。
2、 解决方案
参数增加如下,即可:
@Transactional(rollbackFor = { Exception.class })
public void test() throws Exception {
doDbStuff1();
doDbStuff2();//假如这个操作数据库的方法会抛出异常,现在方法doDbStuff1()对数据库的操作会回滚。
} 3、spring +springmvc 注解事务无效解决方案
3.1原因
SpringMVC启动时的配置文件,包含组件扫描、url映射以及设置freemarker参数,让spring不扫描带有@Service注解的类。
为什么要这样设置?
因为servlet-context.xml与service-context.xml不是同时加载,如果不进行这样的设置,那么,spring就会将所有带@Service注解的类都扫描到容器中,等到加载service-context.xml的时候,会因为容器已经存在Service类,使得cglib将不对Service进行代理,直接导致的结果就是在service-context中的事务配置不起作用,发生异常时,无法对数据进行回滚。
3.2解决方案
spring mvc 自动扫描注解的时候,不去扫描@Service
spring 自动扫描注解的时候,不去扫描@Controller
3.3 try catch后事务不回滚解决方案
在Spring的配置文件中,如果数据源的defaultAutoCommit设置为True了,那么方法中如果自己捕获了异常,事务是不会回滚的,如果没有自己捕获异常则事务会回滚。
情况1:如果没有在程序中手动捕获异常,正常回滚
@Transactional(rollbackFor = { Exception.class })
public void test() throws Exception {
doDbStuff1();
doDbStuff2();//假如这个操作数据库的方法会抛出异常,现在方法doDbStuff1()对数据库的操作 会回滚。
} 情况2:如果在程序中自己捕获了异常,不会回滚
@Transactional(rollbackFor = { Exception.class })
public void test() {
try {
doDbStuff1();
doDbStuff2();//假如这个操作数据库的方法会抛出异常,现在方法doDbStuff1()对数据库的操作 不会回滚。
} catch (Exception e) {
e.printStackTrace();
}
} 3.4 原因
springaop异常捕获原理:被拦截的方法需显式抛出异常,并不能经任何处理,这样aop代理才能捕获到方法的异常,才能进行回滚
现在如果我们需要手动捕获异常,并且也希望抛异常的时候能回滚肿么办呢?以下给出3种解决方案,供大家参考,项目中使用解决方案3。
3.5 解决方案1-不使用try catch
@Transactional所在函数不进行try catch捕获,而是放到上层函数进行异常捕获。比如@Transactional放在service层,我们在service层不进行异常处理,只抛出,而在controller层进行异常捕获。
3.6 解决方案2-在catch中throw
catch后再throw,显示回滚
@Transactional(rollbackFor = { Exception.class })
public void test() {
try {
doDbStuff1();
doDbStuff2();//假如这个操作数据库的方法会抛出异常,现在方法doDbStuff1()对数据库的操作 不会回滚。
} catch (Exception e) {
e.printStackTrace();
throw new Exception(“error”);
}
} 3.7 解决方案3-手动回滚
TransactionAspectSupport手动回滚事务:
@Transactional(rollbackFor = { Exception.class })
public void test() {
try {
doDbStuff1();
doDbStuff2();
} catch (Exception e) {
e.printStackTrace(); TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();//就是这一句了,加上之后,如果doDbStuff2()抛了异常, //doDbStuff1()是会回滚的
}
}Spring 事务中无法查到新增的数据原因
数据库:MySql
持久化框架:MyBatis
Srping 全局事务配置了两种:
1. 读写事务:使用了 PROPAGATION_REQUIRED 如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。
对应生效的方法如:insert* add* update* delete*等。
2. 只读事务:readOnly = true 使用了 PROPAGATION_NOT_SUPPORTED 以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
对应生效的方法如:除了读写事务和使用了注解@Transactional的方法之外的所有方法
模拟代码:
@Service
class ServiceA {
@Autowired
private UserMapper userMapper;
//这个方法会使用事务的 PROPAGATION_NOT_SUPPORTED 特性
public User getUserById(long id){
return userMapper.getById(id);
}
}
@Service
class ServiceB {
@Autowired
private UserMapper userMapper;
@Autowired
private ServiceA serviceA;
//这个方法会使用事务的 PROPAGATION_REQUIRED 特性
public void addUser(User user){
userMapper.insert(user);
System.out.println(user.getId()); //这里有打印出id,代表插入成功了
user = serviceA.getUserById(user.getId());
System.out.println(user); //再去查询就返回的user是null,查询不到刚插入的数据了
user.getId(); //再使用user,因为user是null,会报空指针异常,然后事务回滚了,user也没添加成功
}
}
原因:
serviceA.getUserById(long) 方法使用了PROPAGATION_NOT_SUPPORTED,把原来serviceB.addUser(User) 的事务挂起来了,没在同一个事务中, 一个事务提交后才能被其他事务读取到(Repeatable Read(可重读):这是MySQL的默认事务隔离级别,它确保同一事务的多个实例在并发读取数据时,会看到同样的数据行。不过理论上,这会导致另一个棘手的问题:幻读 (Phantom Read)。简单的说,幻读指当用户读取某一范围的数据行时,另一个事务又在该范围内插入了新行,当用户再读取该范围的数据行时,会发现有新的“幻影” 行。InnoDB和Falcon存储引擎通过多版本并发控制(MVCC,Multiversion Concurrency Control)机制解决了该问题。参考:MYSQL事务隔离级别)。因为 addUser 的事务还没提交,getUserById 又不在同一个事务中,由于事务的隔离性,所以 getUserById 就查询不到新增的数据。
解决方法:
把 serviceA.getUserById(long) 事务的隔离级别设为 READ_UNCOMMITTED 最低隔离级别、事务未提交前,就可被其他事务读取。这样就可以读取到其它事务的数据了,但这样有个坏处,会出现幻读、脏读、不可重复读。所以要根据业务场景来使用。
@Transactional(isolation = Isolation.READ_UNCOMMITTED)
public User getUserById(long id){
return userMapper.getById(id);
}