365天深度学习训练营-第P3周:天气识别
>- ** 本文为[365天深度学习训练营](https://mp.weixin.qq.com/s/xLjALoOD8HPZcH563En8bQ) 中的学习记录博客**
>- ** 参考文章:[Pytorch实战 | 第P3周:彩色图片识别:天气识别](https://www.heywhale.com/mw/project/633567aadfae0249670d0990)**
>- ** 原作者:[K同学啊|接辅导、项目定制](https://mtyjkh.blog.csdn.net/)**
- 难度:新手入门⭐
- 语言:Python3、Pytorch
要求:
- 本地读取并加载数据。
- 测试集accuracy到达93%
拔高:
- 测试集accuracy到达95%
- 调用模型识别一张本地图片
我的环境:
- 语言环境:Python3.8
- 编译器:jupyter notebook
- 深度学习环境:Pytorch
- 数据:百度网盘(提取码:hqij )
一、 前期准备
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
[out]:device(type='cuda')
2. 导入数据
import os,PIL,random,pathlib
data_dir = r'C:\Users\Lenovo\Desktop\第5天-没有加密版本\第5天\weather_photos'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[-1] for path in data_paths]
classeNames
[out]:['cloudy', 'rain', 'shine', 'sunrise']
total_datadir = r'C:\Users\Lenovo\Desktop\第5天-没有加密版本\第5天\weather_photos'
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
[out]:Dataset ImageFolder
Number of datapoints: 1125
Root location: ./data/
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
3. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset
[out]:(
train_size,test_size
[out]:(900, 225)
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
[out]:Shape of X [N, C, H, W]: torch.Size([32, 3, 224, 224])
Shape of y: torch.Size([32]) torch.int64
二、构建简单的CNN网络
对于一般的CNN网络来说,都是由特征提取网络和分类网络构成,其中特征提取网络用于提取图片的特征,分类网络用于将图片进行分类。
⭐1. torch.nn.Conv2d()详解
函数原型:
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
关键参数说明:
- in_channels ( int ) – 输入图像中的通道数
- out_channels ( int ) – 卷积产生的通道数
- kernel_size ( int or tuple ) – 卷积核的大小
- stride ( int or tuple , optional ) -- 卷积的步幅。默认值:1
- padding ( int , tuple或str , optional ) – 添加到输入的所有四个边的填充。默认值:0
- padding_mode (字符串,可选) – 'zeros', 'reflect', 'replicate'或'circular'. 默认:'zeros'
⭐2. torch.nn.Linear()详解
函数原型:
torch.nn.Linear(in_features, out_features, bias=True, device=None, dtype=None)
关键参数说明:
- in_features:每个输入样本的大小
- out_features:每个输出样本的大小
⭐3. torch.nn.MaxPool2d()详解
函数原型:
torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
关键参数说明:
- kernel_size:最大的窗口大小
- stride:窗口的步幅,默认值为
kernel_size
- padding:填充值,默认为0
- dilation:控制窗口中元素步幅的参数
3. 编写测试函数
测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4. 正式训练
1. model.train()
model.train()的作用是启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
2. model.eval()
model.eval()的作用是不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
[out]:Epoch: 1, Train_acc:61.4%, Train_loss:0.986, Test_acc:72.0%,Test_loss:0.865
Epoch: 2, Train_acc:76.7%, Train_loss:0.674, Test_acc:83.6%,Test_loss:0.558
Epoch: 3, Train_acc:80.8%, Train_loss:0.561, Test_acc:88.4%,Test_loss:0.447
Epoch: 4, Train_acc:83.6%, Train_loss:0.485, Test_acc:90.2%,Test_loss:0.431
Epoch: 5, Train_acc:86.3%, Train_loss:0.423, Test_acc:89.8%,Test_loss:0.354
Epoch: 6, Train_acc:86.3%, Train_loss:0.418, Test_acc:88.4%,Test_loss:0.306
Epoch: 7, Train_acc:87.6%, Train_loss:0.389, Test_acc:88.4%,Test_loss:0.401
Epoch: 8, Train_acc:90.0%, Train_loss:0.340, Test_acc:92.9%,Test_loss:0.488
Epoch: 9, Train_acc:90.7%, Train_loss:0.321, Test_acc:92.4%,Test_loss:0.260
Epoch:10, Train_acc:91.0%, Train_loss:0.316, Test_acc:92.9%,Test_loss:0.240
Epoch:11, Train_acc:92.6%, Train_loss:0.288, Test_acc:93.3%,Test_loss:0.254
Epoch:12, Train_acc:91.3%, Train_loss:0.291, Test_acc:92.4%,Test_loss:0.231
Epoch:13, Train_acc:93.9%, Train_loss:0.238, Test_acc:92.4%,Test_loss:0.226
Epoch:14, Train_acc:93.9%, Train_loss:0.255, Test_acc:93.3%,Test_loss:0.200
Epoch:15, Train_acc:93.7%, Train_loss:0.239, Test_acc:94.7%,Test_loss:0.236
Epoch:16, Train_acc:93.4%, Train_loss:0.224, Test_acc:93.3%,Test_loss:0.201
Epoch:17, Train_acc:94.1%, Train_loss:0.265, Test_acc:94.7%,Test_loss:0.187
Epoch:18, Train_acc:93.7%, Train_loss:0.222, Test_acc:94.2%,Test_loss:0.193
Epoch:19, Train_acc:95.4%, Train_loss:0.224, Test_acc:93.8%,Test_loss:0.199
Epoch:20, Train_acc:95.1%, Train_loss:0.201, Test_acc:93.3%,Test_loss:0.175
Done
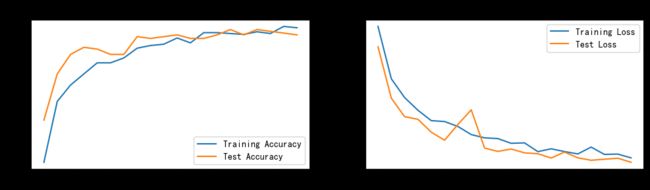
四、 结果可视化
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()