图像分类以及经典的分类模型
图像分类
图像分类目的
图像分类实质上就是从给定的类别集合中为图像分配对应标签的任务。
例如:
类别集(caegories)有(bird,dog,pig)三个类别,输入一张图片,分类模型会给图像分配多个标签,每个标签的概率不相同,取最大作为其类别,这就完成了图像分类的任务
图像分类经典的分类模型
AlexNet
AlexNet简介:
2012 年的ImageNet图像识别挑战赛中,AlexNet横空出世,它击败了日本选手的传统方法构建的SVM模型,首次证明了学习到的特征可以超越手工设计的特征,从而一举打破计算机视觉研究的方向
AlexNet网络的特点:
- AlexNet包含8层变换,有5层卷积和2层全连接隐藏层,以及1个全连接输出层
- AlexNet第一层中的卷积核形状是1111,第二层中的卷积核形状大小减小到55,之后全部采用33。所有的池化层窗口大小为33、步幅为2(最大池化)
- AlexNet 将sigmoid激活函数变成了relu激活函数,使计算更简单,网络更容易
- 通过dropOut来控制全连接层的模型复杂度
- 引入了大量的图像增强,如翻转、裁剪和颜色变化,从而进一步扩大数据集来缓解过拟合
VGG
2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了LISVRC2014比赛分类项目的第二名,主要贡献是使用很小的卷积核(3*3)构建卷积神经网络结构,能够取得较好的识别精度,常用来提取图像特征的有VGG-16和VGG-19
VGG特点:
- 小卷积核,卷积核全部替换为3*3
- 小池化核,相比AlexNet的33的池化核,VGG全部为22的池化核;
- 相比AlexNet层数更深,证明了可以通过不断加深网络来提高性能(1、增加模型的识别效果/2、更深的网络和更小的卷积核带来的隐式正则化结果,需要的收敛的迭代次数较少许多)
- 使用了Dropout来优化网络结构
VGG块:
在使用tf.keras实现模型时,首先要实现VGG块,它的组成规律是:连续使用多个相同的填充为1、卷积核大小为33的卷积层后接上一个步幅为2、窗口形状为22的最大池化层。卷积层保持输入的高和宽不变,而池化层则对其减半。我们使用vgg_block函数来实现这个基础的VGG块,它可以指定卷积层的数量num_convs和每层的卷积核个数num_filters
# 定义VGG网络中的卷积块:卷积层的个数,卷积层中卷积核的个数
def vgg_block(num_convs, num_filters):
# 构建序列模型
blk = tf.keras.models.Sequential()
# 遍历所有的卷积层
for _ in range(num_convs):
# 每个卷积层:num_filter个卷积核,卷积核大小为3*3,padding是same,激活函数是relu
blk.add(tf.keras.layers.Conv2D(num_filters,kernel_size=3,
padding='same',activation='relu'))
# 卷积块最后是一个最大池化,窗口大小为2*2,步长为2
blk.add(tf.keras.layers.MaxPool2D(pool_size=2, strides=2))
return blk
GoogLeNet
GoogLeNet的名字不是GoogleNet,而是GoogLeNet,这是为了致敬LeNet。GoogLeNet和AlexNet/VGGNet这类依靠加深网络结构的深度的思想不完全一样。GoogLeNet在加深度的同时做了结构上的创新,引入了一个叫做Inception的结构来代替之前的卷积加激活的经典组件。
1. Inception块
GoogLeNet中的基础卷积块叫做Inception块,Inception块的结构比较复杂,如下图所示:
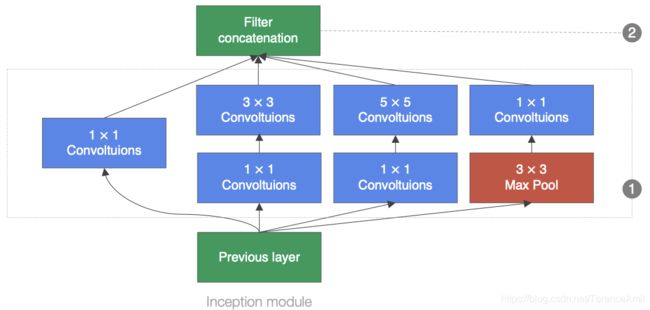
Inception块里有4条并行的线路,前3条线路使用窗口大小分别是11,33,55的卷积层来抽取不同空间尺寸下的信息,其中中间2个线路会对输入先做11卷积来减少通道数,以降低模型的复杂度。第4条线路则使用33最大池化层,后接11卷积层来改变通道数。4条线路都使用了合适的填充来使输入与输出的高和宽一致。最后我们将每条线路的输出在通道维度上连接,并向后进行传输
1*1 卷积核:

- 实现跨通道的交互和信息整合(本质上其实就是channels的线性叠加)
- 卷积核通道数的降维和升维,减少网络参数(只改变了通道数(厚度),不改变宽高)
- 加入非线性,卷积后经过激励层,提高网络表达能力,实现泛化
为什么1*1卷积核可以减少网络参数?
以inception模块为例,来说明1x1的卷积如何来减少模型参数:
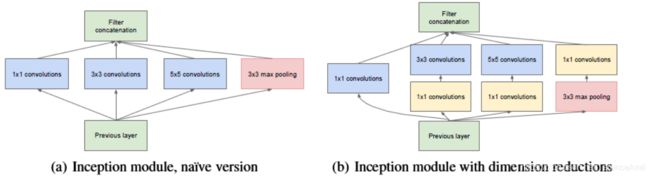
如上图:a是未加入11卷积的inception模块,b是加入了11卷积的inception模块
我们以33卷积线路为例,假设输入的特征图大小为(2828192),卷积核的个数是128:
a图参数个数为:33192128 = 221184
b图参数个数为:1119296 + 3396128 = 129024
对比可知,加入1*1卷积后参数量减少了
2. GoogLeNet模型:
整个网络架构我们分为5个模块,每个模块之间使用步幅为2的33最大池化层来减少输出宽度
B1模块
第一模块使用一个64通道的77卷积层。
B2模块
第二模块使用2个卷积层:首先是64通道的11卷积层,然后是将通道增大3倍的33卷积层
B3模块
第三模块串联2个完整的Inception块,第一个Inception块的输出通道数为64+128+32+32=256,第二个Inception块输出通道数增至128+192+96+64=480
B4模块
第四个模块比较复杂,它串联了5个Inception块,其输出通道数分别是192+208+48+64=512,160+224+64+64=512,128+256+64+64=512,112+288+64+64=528,256+320+128+128=832
并且在第1和第4个Inception后面增加了辅助分类器(根据实验发现网络中间层具有很强的识别能力,为了利用中间层抽象的特征,在某些中间层中添加含有多层的分类器)
辅助分类器:
考虑到GoogLeNet相当深的网络模型会影响反向传播(会出现梯度消失的情况),又想到中间的网络层具有很强的判别例,所以增加了一个辅助分类器
优点:
- 增加这个辅助分类器增加了反向传播的信号值
- 我们额外增加了正则化项来减少过拟合
GoogLeNet论文写到:训练阶段,最后把这两个辅助分类器输出的结果赋予0.3的权重后加入了最后的损失中,验证阶段,这两个auxilary的结果被去掉了
B5模块
第五模块有两个Inception块,输出通道数为256+320+128+128=832,384+384+128+128=1024.
后面紧跟输出层,该模块使用全局平均池化层(GAP)来将每个通道的高和宽变成1。最后输出变成二维数组后接输出个数为标签类别数的全连接层。
全局平均池化层(GAP)
目的是用来替代全连接层前的Flatten。传统的CNN最后一层都是全连接层,参数个数非常之多,容易引起过拟合(如Alexnet),一个CNN模型,大部分的参数都被全连接层给占用了,所以论文提出采用了全局均值池化替代全连接层。与传统的全连接层不同,我们对每个特征图一整张图片进行全局均值池化,这样每张特征图都可以得到一个输出。这样采用均值池化,连参数都省了,可以大大减小网络参数,避免过拟合,另一方面它有一个特点,每张特征图相当于一个输出特征,然后这个特征就表示了我们输出类的特征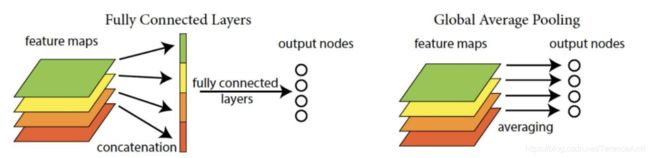
优点:
- 通过加强特征图与类别的一致性,让卷积结构更简单
- 不需要进行参数优化,所以这一层可以避免过拟合
- 对空间信息尽心了求和,因而对输入空间变化更具有稳定性
GoogLeNet延伸版本
GoogLeNet是以InceptionV1为基础进行构建的,所以GoogLeNet也叫做InceptionNet,在随后的⼏年⾥,研究⼈员对GoogLeNet进⾏了数次改进, 就又产生了InceptionV2,V3,V4等版本。
InceptionV2:
在InceptionV2中将大卷积核拆分为小卷积核,将V1中的55的卷积用两个33的卷积替代,从而增加网络的深度,减少了参数(用两个33和一个55产生的特征图相同)

InceptionV3:
将n×n卷积分割为1×n和n×1两个卷积,例如,一个的33
卷积首先执行一个13的卷积,然后执行一个3*1的卷积,这种方法的参数量和计算量都比原来降低(这样改进后特征图形状和原来相同,参数量减少了)。
