Vue2.0 —— 实现 Mustache 模板引擎的数据结构和算法
Vue2.0 —— 实现 Mustache 模板引擎的数据结构和算法
《工欲善其事,必先利其器》
既然点进来了,麻烦你看下去,希望你有不一样的收获。
大家好,我是 vk。今天我们一起来盘一盘关于 Vue2.0 的模板引擎的实现原理。注意,真实上的 Vue 模板引擎是很复杂的,处理的情况有非常多,包括 AST 解析、虚拟 DOM 和 Diff 算法等等。

本篇文章主要是分析 Mustache.js 的基本原理,目的就是学习其中的数据结构和算法,加以借鉴,为以后的 Vue 源码学习系列做铺垫。
一、什么是 Mustachejs ?
Mustache 是基于 JavaScript 实现的模版引擎,类似于 JQuery Template,但是这个模版更加的轻量级,语法更加的简单易用,很容易上手。
这里贴一个可以下载 Mustache 包的地址,大家可以下载引入体验一下,他是如何进行模板渲染的 —— 《下载地址》
测试一下:
<div id="container">div>
<script src="./mustache.js">script>
<script>
var data = {
arr: [
{ "name": "小明", "age": 12, "sex": "男" },
{ "name": "小红", "age": 11, "sex": "女" },
{ "name": "小强", "age": 13, "sex": "男" }
]
}
var templateStr = `
{{#arr}}
-
{{name}} 的个人信息
姓名: {{name}}
年龄: {{age}}
性别: {{sex}}
{{/arr}}
`;
var domStr = Mustache.render(templateStr, data);
var container = document.getElementById("container");
container.innerHTML = domStr;
script>
来看一下渲染的效果如何:

可以看到,尽管我们把标签写成字符串形式,也没有对数组进行循环,只是通过引入的包,调用了一个API。它就帮我们把字符串结合数据进行 DOM 的渲染了,是不是非常神奇?!接下来我们就开始学习它的底层原理!!!
二、探秘原理
我们先来看一张图,这张图囊括了 Mustache 的每个步骤,清晰的解释了它的底层机理,以及是如何工作的:

上图主要分为了两个步骤:
- 将模板字符串转化为
tokens; - 把
tokens结合数据拼接成DOM字符串。
那么问题来了:
- 请问如何把字符串转化为
tokens数组? - 请问如何收窄
tokens数组的层级? - 请问如何渲染数组成为
DOM字符串?
基本上,涉及到数据结构和算法的编程,就是围绕着这三个问题去进行的。接下来我们就带着问题,逐一击破,彻底把这三个过程搞懂,你就会了解,Vue 它的模板编译,大概也是这么做的!!!
三、实现 tokens 推理算法
- 把字符串推理成分散的
tokens数组,这是非常重要的一步。我们需要遍历字符串,把里面的循环标识、数据字段和普通字符串对象进行规整。例如,普通标签规整为text类型;循环标签规整为#类型;数字字段规整为name类型。先实现扫描字符串类:
// 实现推理类class,达到分析、截取字符串的目的
export default class Scanner {
constructor(templateStr) {
// 字符串赋值
this.templateStr = templateStr;
// 字符串指针
this.pos = 0;
// 被截取剩下的字符串,称为尾巴
this.tail = templateStr;
}
// 侦察函数,传入 tag 参数,侦察到 tag 标签,就跳过该标签
scan(tag) {
if (this.tail.indexOf(tag) == 0) {
this.pos += tag.length;
// 根据 pos 指针,利用 substring api 处理尾巴
this.tail = this.templateStr.substring(this.pos);
}
}
// 推理函数,传入 stoptag 参数,如果遇见该参数就截取字符串
scanUtil(stopTag) {
// 记录上一个原始指针
const pos_back = this.pos;
while(!this.eos() && this.tail.indexOf(stopTag) != 0) {
// 循环字符串,如果没有遇见参数,指针就进行自增
this.pos++;
// 根据 pos 指针,利用 substring api 处理尾巴
this.tail = this.templateStr.substring(this.pos);
}
// 根据 pos_back, pos 指针,利用 substring api 截取需要返回的字符串
return this.templateStr.substring(pos_back, this.pos);
}
eos() {
// 返回判断是否到达了字符串的最后一个字符
return this.pos >= this.templateStr.length;
}
}
- 基于实现的推理类,对字符串进行分类。
什么?!你问我为什么要分类???因为我们推理出来的 tokens 是根据你的字符串而来的,有时候你在字符串里面使用循环标识、数据字段和普通字符串标识,后面我们都是要根据这些类别来进行数据渲染的:

接下来就开始实现,对 tokens 数组的分类:
import Scanner from "./Scanner";
export default function parseTemplateToTokens(templateStr) {
const tokens = [];
// 实例化一个扫描器,构造的时候提供一个参数,这个参数就是模板字符串
// 这个扫描器只针对这个模板字符串工作的
const scanner = new Scanner(templateStr);
let words;
while(!scanner.eos()) {
// 收集开始标记出现之前的文字
words = scanner.scanUtil("{{");
if (words != "") {
// 存起来
tokens.push(["text", words]);
}
// 过双大括号
scanner.scan("{{");
// 收集结束标记出现之前的文字
words = scanner.scanUtil("}}");
if (words != "") {
if (words[0] == "#") {
// 存起来,从下标为1的项开始存,因为下标为 0 的项是 #
tokens.push(["#", words.substring(1)]);
} else if (words[0] == "/") {
// 存起来,从下标为1的项开始存,因为下标为 0 的项是 /
tokens.push(["/", words.substring(1)]);
} else {
// 存起来,普通存储
tokens.push(["name", words]);
}
}
// 过双大括号
scanner.scan("}}");
}
// 返回分类好的数组
return tokens;
}
看一下分类之后的结果:

四、实现 tokens 收窄的数据结构算法
收窄 tokens 的意义是什么?
好问题。收窄的意义就在于把循环标识的子项收纳到一起,整理成跟 data 一样的数据结构,然后方便后续再结合 data 的数据进行渲染的。
非常重要的一点就是,一份扁平化的数据结构,如何变成收窄嵌套的的数据结构呢?而且还是有父子关系的嵌套型数据结构?
对数据结构熟悉的同学可能已经想到了,对了,那就是 —— 栈。
export default function nestTokens(tokens) {
// 定义收窄数组
const nestedTokens = [];
// 利用 js 的引用数据类型的特性,定义收集者,永远指向当前工作栈
let collector = nestedTokens;
// 定义栈数组
const sections = [];
let token;
for(let i = 0; i < tokens.length; i++) {
token = tokens[i];
switch(token[0]) {
case "#":
collector.push(token);
// 收集进栈
sections.push(token);
// 设置子项为空数组,进而继续收窄
collector = token[2] = [];
break;
case "/":
// 出栈
sections.pop();
collector = sections.length == 0 ? nestedTokens : sections[sections.length - 1][2];
break;
default:
collector.push(token);
}
}
// 返回数组
return nestedTokens;
}
接着修改第三步中的,返回的 tokens :
import nestTokens from "./nestTokens";
import Scanner from "./Scanner";
export default function parseTemplateToTokens(templateStr) {
...
// 这里就要对扁平化数组进行收窄,然后返回
return nestTokens(tokens);
}
让我们看看收窄完的数据结构,跟上面第三步中的离散 tokens 进行对比,你就可以发现不同:

可以观察到,每一项具有循环标识的 token,都会被收窄到上一个循环标识的 token 子项里面,我们正是利用了 栈数据结构 的,后入先出原则(FILO),才能实现这种数组的收窄效果。
五、结合数据和 tokens 拼接 DOM 字符串
根据第四步收窄好的 tokens 数组,进行遍历,不同的 token 类型拼接不同的内容:
import lookup from "./lookup";
import parseArray from "./parseArray";
export default function renderTemplate(tokens, data) {
// 声明结果字符串
let resultStr = "";
let token;
for(let i = 0; i < tokens.length; i++) {
token = tokens[i];
if (token[0] == "text") {
// 如果是普通字符串,直接拼接
resultStr += token[1];
} else if (token[0] == "name") {
// 如果是数据字段,需要判断是否有多个层级,再进行拼接
resultStr += lookup(data, token[1]);
} else if (token[0] == "#") {
// 如果是循环标识,则需要递归调用当前方法再进行拼接
resultStr += parseArray(token, data);
}
}
// 返回结果字符串
return resultStr;
}
实现递归的方法:
import lookup from "./lookup";
import renderTemplate from "./renderTemplate";
export default function parseArray(token, data) {
// 声明结果字符串
let resultStr = "";
// 对传进来的 data 进行监听,防止有多层级
let val = lookup(data, token[1]);
// 循环递归调用
for(let i = 0; i < val.length; i++) {
resultStr += renderTemplate(token[2], {
...val[i],
// 处理数据字段为 {{.}} 的情况
".": val[i]
})
}
// 返回拼接数组
return resultStr;
}
然后,我们看一下最终的效果:
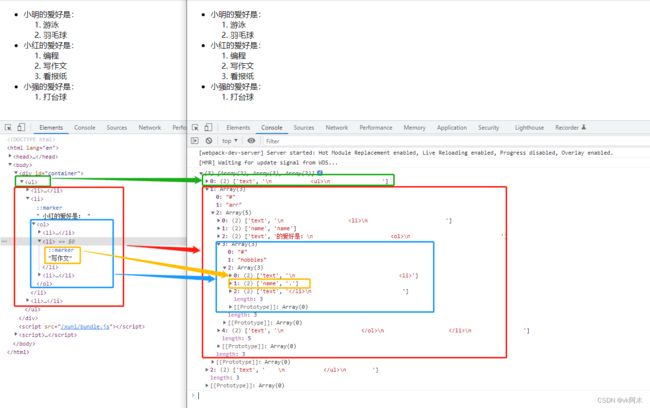
我们所实现的算法已经完成了,结合 data 和 收窄的 tokens ,最终把字符串挂载到了 DOM 树上。data 和 我们处理过后的 tokens 数组的数据结构是一样的,都是收窄成嵌套子项的结构,最后再使用递归把子项循环拼接出来。大功告成拉~~
最后,感谢你的阅读,码字真的很辛苦,给个三连吧!!!
代码已上传至码云,有需要的小伙伴自行下载吧 —— 《下载地址》
参考文献
- B站尚硅谷 Vue Mustache 原理