深度学习从入门到精通——图像分割实战DeeplabV3
DeeplabV3算法
-
- 参数配置
-
- 关于数据集的配置
- 训练集参数
- 数据预处理模块
-
- DataSet构建模块
- 测试一下数据集
- 去正则化
- 模型加载模块
- DeepLABV3+
参数配置
关于数据集的配置
parser = argparse.ArgumentParser()
# Datset Options
parser.add_argument("--data_root", type=str, default=r'D:/',
help="path to Dataset")
parser.add_argument("--dataset", type=str, default='voc',
choices=['voc', 'cityscapes'], help='Name of dataset')
parser.add_argument("--num_classes", type=int, default=None,
help="num classes (default: None)")
# Deeplab Options
# 选择模型的架构,特征提取模块分为moiblienet或者resnet50
parser.add_argument("--model", type=str, default='deeplabv3plus_resnet50',
choices=['deeplabv3_resnet50', 'deeplabv3plus_resnet50',
'deeplabv3_resnet101', 'deeplabv3plus_resnet101',
'deeplabv3_mobilenet', 'deeplabv3plus_mobilenet'], help='model name')
parser.add_argument("--separable_conv", action='store_true', default=False,
help="apply separable conv to decoder and aspp")
parser.add_argument("--output_stride", type=int, default=16, choices=[8, 16])
训练集参数
# Train Options
# 制作测试
parser.add_argument("--test_only", action='store_true', default=False)
parser.add_argument("--save_val_results", action='store_true', default=False,
help="save segmentation results to \"./results\"")
parser.add_argument("--total_itrs", type=int, default=60e3,
help="epoch number (default: 30k)")
# 学习率
parser.add_argument("--lr", type=float, default=0.01,
help="learning rate (default: 0.01)")
parser.add_argument("--lr_policy", type=str, default='poly', choices=['poly', 'step'],
help="learning rate scheduler policy")
parser.add_argument("--step_size", type=int, default=10000)
parser.add_argument("--crop_val", action='store_true', default=False,
help='crop validation (default: False)')
parser.add_argument("--batch_size", type=int, default=8,
help='batch size (default: 16)')
parser.add_argument("--val_batch_size", type=int, default=4,
help='batch size for validation (default: 4)')
parser.add_argument("--crop_size", type=int, default=513)
# 预训练权重路径
parser.add_argument("--ckpt", default="./checkpoint/best_deeplabv3_resnet50_voc_os16.pth", type=str,
help="restore from checkpoint")
parser.add_argument("--continue_training", action='store_true', default=True)
parser.add_argument("--loss_type", type=str, default='cross_entropy',
choices=['cross_entropy', 'focal_loss'], help="loss type (default: False)")
parser.add_argument("--gpu_id", type=str, default='0',
help="GPU ID")
# 正则化参数
parser.add_argument("--weight_decay", type=float, default=1e-4,
help='weight decay (default: 1e-4)')
parser.add_argument("--random_seed", type=int, default=1,
help="random seed (default: 1)")
parser.add_argument("--print_interval", type=int, default=10,
help="print interval of loss (default: 10)")
parser.add_argument("--val_interval", type=int, default=100,
help="epoch interval for eval (default: 100)")
parser.add_argument("--download", action='store_true', default=False,
help="download datasets")
数据预处理模块
分别针对训练集、验证集、测试集做三种数据增强变换
def get_dataset(opts):
""" Dataset And Augmentation
"""
if opts.dataset == 'voc':
train_transform = et.ExtCompose([
#et.ExtResize(size=opts.crop_size),
et.ExtRandomScale((0.5, 2.0)),
et.ExtRandomCrop(size=(opts.crop_size, opts.crop_size), pad_if_needed=True),
et.ExtRandomHorizontalFlip(),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
if opts.crop_val:
val_transform = et.ExtCompose([
et.ExtResize(opts.crop_size),
et.ExtCenterCrop(opts.crop_size),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
else:
val_transform = et.ExtCompose([
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
train_dst = VOCSegmentation(root=opts.data_root, year=opts.year,
image_set='train', download=opts.download, transform=train_transform)
val_dst = VOCSegmentation(root=opts.data_root, year=opts.year,
image_set='val', download=False, transform=val_transform)
if opts.dataset == 'cityscapes':
train_transform = et.ExtCompose([
#et.ExtResize( 512 ),
et.ExtRandomCrop(size=(opts.crop_size, opts.crop_size)),
et.ExtColorJitter( brightness=0.5, contrast=0.5, saturation=0.5 ),
et.ExtRandomHorizontalFlip(),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
val_transform = et.ExtCompose([
#et.ExtResize( 512 ),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
train_dst = Cityscapes(root=opts.data_root,
split='train', transform=train_transform)
val_dst = Cityscapes(root=opts.data_root,
split='val', transform=val_transform)
return train_dst, val_dst
DataSet构建模块
def voc_cmap(N=256, normalized=False):
def bitget(byteval, idx):
return ((byteval & (1 << idx)) != 0)
dtype = 'float32' if normalized else 'uint8'
cmap = np.zeros((N, 3), dtype=dtype)
for i in range(N):
r = g = b = 0
c = i
for j in range(8):
r = r | (bitget(c, 0) << 7-j)
g = g | (bitget(c, 1) << 7-j)
b = b | (bitget(c, 2) << 7-j)
c = c >> 3
cmap[i] = np.array([r, g, b])
cmap = cmap/255 if normalized else cmap
return cmap
class VOCSegmentation(data.Dataset):
"""`Pascal VOC 测试一下数据集
import numpy as np
from datasets import VOCSegmentation
from utils import ext_transforms as et
import cv2
train_transform = et.ExtCompose([
# et.ExtResize(size=opts.crop_size),
et.ExtRandomScale((0.5, 2.0)),
et.ExtRandomCrop(size=(224, 224), pad_if_needed=True),
et.ExtRandomHorizontalFlip(),
et.ExtToTensor(),
et.ExtNormalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]),
])
data = VOCSegmentation(root=r"D:/", year="2012", image_set='train', download=False, transform=train_transform)
if __name__ == '__main__':
print(data[0][0].shape)
print(data[0][1].shape)
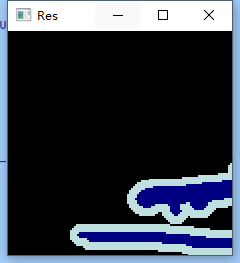
res = data.decode_target(data[0][1])
cv2.imshow("Res",np.array(res))
cv2.waitKey(0)
去正则化
class Denormalize(object):
def __init__(self, mean, std):
mean = np.array(mean)
std = np.array(std)
self._mean = -mean/std
self._std = 1/std
def __call__(self, tensor):
if isinstance(tensor, np.ndarray):
return (tensor - self._mean.reshape(-1,1,1)) / self._std.reshape(-1,1,1)
return normalize(tensor, self._mean, self._std)
模型加载模块
# Set up model
model_map = {
'deeplabv3_resnet50': network.deeplabv3_resnet50,
'deeplabv3plus_resnet50': network.deeplabv3plus_resnet50,
'deeplabv3_resnet101': network.deeplabv3_resnet101,
'deeplabv3plus_resnet101': network.deeplabv3plus_resnet101,
'deeplabv3_mobilenet': network.deeplabv3_mobilenet,
'deeplabv3plus_mobilenet': network.deeplabv3plus_mobilenet
}
model = model_map[opts.model](num_classes=opts.num_classes, output_stride=opts.output_stride)
def deeplabv3_resnet50(num_classes=21, output_stride=8, pretrained_backbone=True):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
def deeplabv3_resnet101(num_classes=21, output_stride=8, pretrained_backbone=True):
"""Constructs a DeepLabV3 model with a ResNet-101 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3', 'resnet101', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
def deeplabv3_mobilenet(num_classes=21, output_stride=8, pretrained_backbone=True, **kwargs):
"""Constructs a DeepLabV3 model with a MobileNetv2 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3', 'mobilenetv2', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
# Deeplab v3+
def deeplabv3plus_resnet50(num_classes=21, output_stride=8, pretrained_backbone=True):
"""Constructs a DeepLabV3 model with a ResNet-50 backbone.
Args:
num_classes (int): number of classes.
output_stride (int): output stride for deeplab.
pretrained_backbone (bool): If True, use the pretrained backbone.
"""
return _load_model('deeplabv3plus', 'resnet50', num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
加载模块
def _load_model(arch_type, backbone, num_classes, output_stride, pretrained_backbone):
if backbone=='mobilenetv2':
model = _segm_mobilenet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
elif backbone.startswith('resnet'):
model = _segm_resnet(arch_type, backbone, num_classes, output_stride=output_stride, pretrained_backbone=pretrained_backbone)
else:
raise NotImplementedError
return model
def _segm_resnet(name, backbone_name, num_classes, output_stride, pretrained_backbone):
if output_stride==8:
replace_stride_with_dilation=[False, True, True]
aspp_dilate = [12, 24, 36]
else:
replace_stride_with_dilation=[False, False, True]
aspp_dilate = [6, 12, 18]
backbone = resnet.__dict__[backbone_name](
pretrained=pretrained_backbone,
replace_stride_with_dilation=replace_stride_with_dilation)
inplanes = 2048
low_level_planes = 256
if name=='deeplabv3plus':
return_layers = {'layer4': 'out', 'layer1': 'low_level'}#
classifier = DeepLabHeadV3Plus(inplanes, low_level_planes, num_classes, aspp_dilate)
elif name=='deeplabv3':
return_layers = {'layer4': 'out'}
classifier = DeepLabHead(inplanes , num_classes, aspp_dilate)
#提取网络的第几层输出结果并给一个别名
backbone = IntermediateLayerGetter(backbone, return_layers=return_layers)
model = DeepLabV3(backbone, classifier)
return model
DeepLABV3+
class DeepLabHeadV3Plus(nn.Module):
def __init__(self, in_channels, low_level_channels, num_classes, aspp_dilate=[12, 24, 36]):
super(DeepLabHeadV3Plus, self).__init__()
self.project = nn.Sequential(
nn.Conv2d(low_level_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(inplace=True),
)
self.aspp = ASPP(in_channels, aspp_dilate)
self.classifier = nn.Sequential(
nn.Conv2d(304, 256, 3, padding=(1,1), bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, num_classes, 1)
)
self._init_weight()
def forward(self, feature):
#print(feature.shape)
low_level_feature = self.project( feature['low_level'] )#return_layers = {'layer4': 'out', 'layer1': 'low_level'}
#print(low_level_feature.shape)
output_feature = self.aspp(feature['out'])
#print(output_feature.shape)
output_feature = F.interpolate(output_feature, size=low_level_feature.shape[2:], mode='bilinear', align_corners=False)
#print(output_feature.shape)
return self.classifier( torch.cat( [ low_level_feature, output_feature ], dim=1 ) )
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
其中,空洞融合ASPP模块
class ASPP(nn.Module):
def __init__(self, in_channels, atrous_rates):
super(ASPP, self).__init__()
out_channels = 256
modules = []
modules.append(nn.Sequential(
nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)))
rate1, rate2, rate3 = tuple(atrous_rates)
modules.append(ASPPConv(in_channels, out_channels, rate1))
modules.append(ASPPConv(in_channels, out_channels, rate2))
modules.append(ASPPConv(in_channels, out_channels, rate3))
modules.append(ASPPPooling(in_channels, out_channels))
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(
nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout(0.1),)
def forward(self, x):
res = []
for conv in self.convs:
#print(conv(x).shape)
res.append(conv(x))
res = torch.cat(res, dim=1)
return self.project(res)
卷积转深度可分离卷积
def convert_to_separable_conv(module):
new_module = module
if isinstance(module, nn.Conv2d) and module.kernel_size[0]>1:
new_module = AtrousSeparableConvolution(module.in_channels,
module.out_channels,
module.kernel_size,
module.stride,
module.padding,
module.dilation,
module.bias)
for name, child in module.named_children():
new_module.add_module(name, convert_to_separable_conv(child))
return new_module
class AtrousSeparableConvolution(nn.Module):
""" Atrous Separable Convolution
"""
def __init__(self, in_channels, out_channels, kernel_size,
stride=1, padding=0, dilation=1, bias=True):
super(AtrousSeparableConvolution, self).__init__()
self.body = nn.Sequential(
# Separable Conv
nn.Conv2d( in_channels, in_channels, kernel_size=kernel_size, stride=stride, padding=padding, dilation=dilation, bias=bias, groups=in_channels ),
# PointWise Conv
nn.Conv2d( in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=bias),
)
self._init_weight()
def forward(self, x):
return self.body(x)
def _init_weight(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)