Kafka保证消息可靠性配置
文章目录
- 前言
- Broker配置
-
- 复制系数
- 副本分布
- 不完全的首领选举
- 最少在同步的副本
- 生产者配置
-
- 发送确认
- 重试
- 可靠的消费者
-
- 消费组
- 自动重置偏移量
- 自动提交
- 显示提交偏移量
- 再均衡
- 心跳
- 参考
前言
这篇内容是保证 Kafka 消息可靠性的相关配置,内容主要来自《Kafka权威指南》这本书,再根据 Apache - Kafka文档2.8 总结出来的。文中每个配置项是个超链接,可以定位到配置的官方文档。代码例子可以访问 GitHub - fruitbasket-litchi-kafka
Broker配置
复制系数
指一个主题(Topic)每个分区(Partition)共有多少个副本(Replica)。比如指定系数 3,代表这个主题每个分区会有 3 个副本,1 个作为首领(Leader)提供读写,另外 2 个跟随者(Follower)向主同步数据来保证高可用。
假设复制系数为 N,那就意味着可以容忍 N-1 个副本失效,需要 N 个 Broker,并且会占用 N 倍的磁盘空间。
更高的副本系数会带来更高的可用性和存储成本,所以一般需要在可用性和存储硬件之间作权衡。如果 Broker 故障导致一段时间不可用是可以容忍的,那设置成 1 就可以了,相当于节省了硬件成本降低了可用性;如果可用性和安全性有一定的要求可以适当增加系数,大多数情况为 3 ,少数更高的安全性要求可以调整为 >=5。
在 Broker 配置文件(config/server.properties)中指定默认复制系数 default.replication.factor(类型=int,默认值=1),一般作用于自动创建的主题。比如:
# 默认副本系数为3
default.replication.factor=3
# 自动创建Topic开启
auto.create.topics.enable=true
创建主题的时候也可以单独指定副本系数 replication-factor(类型=int,默认值=1),只对创建的这个主题有效。如果Kafka版本 >=2.4 可以设置为 -1 来使用 Broker 中的默认值 default.replication.factor。比如:
echo "通过node1上的broker创建主题名为my-topic,拥有2个分区,复制系数为3" > /dev/null
kafka-topics.sh --bootstrap-server node1:9092 --create --topic my-topic --partitions 2 --replication-factor 2
即使在主题创建后,可以通过重新分配来改变复制系数。
kafka-topics.sh --bootstrap-server node1:9092 --describe --topic my-topic
通过主题描述我们可以看到 my-topic 有 2 个分区 0 和 1,每个分区各有 2 个副本,副本后面的编号代表副本所在 Broker 的ID。

创建一个描述 Topic 分配的 JSON 配置文件,再使用指令根据这个配置重新分配 Topic。我们这里将两个分区都增加到了 3 个副本。
echo "创建重新分配的json文件" > /dev/null
echo '{
"version": 1,
"partitions": [
{
"topic": "my-topic",
"partition": 0,
"replicas": [
1,
2,
3
]
},
{
"topic": "my-topic",
"partition": 1,
"replicas": [
1,
2,
3
]
}
]
}' > reassign-my-topic.json
echo "根据json文件重新分配" > /dev/null
kafka-reassign-partitions.sh --bootstrap-server node1:9092 --reassignment-json-file reassign-my-topic.json --execute
再次查看主题描述可以看到 2 个分区副本数量按配置增加到了 3 个。
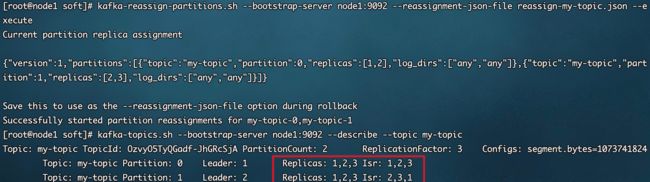
副本分布
默认情况下 Kafka 会确保分区的每个副本分布在不同的 Broker 上。如果这些Broker处于同一个机架上,一旦机架的交换机、电源等公共设施发生故障,这些 Broker 都会受影响,那不管多少个副本如何分布在不同的 Broker 都不管用。
为了避免这种问题,建议尽量将 Broker 分布在不同的机架上,并且在配置文件中指定所在机架名字 broker.rack(类型=string,默认值=null),这样 Kafka 会尽量将副本分布在不同机架的 Broker 上来达到更高的可用性。
不完全的首领选举
Kafka 分区是有主集群,只有首领(Leader)提供读写服务,跟随者(Follower)只负责跟首领同步,当首领不可用时,一个跟随者会被选举成为新首领。
假如选主过程中有在同步的副本(In Sync Replica,ISR),那新首领会从 ISR 中选择,因为这些副本数据几乎是跟旧主同步的,这种选主就是“完全的”。
假如首领不可用时,其他副本都是不在同步的副本(Out Sync Replica,OSR)该怎么办?这种情况会在下面两种场景中出现:
- 分区有 3 个副本,其中 2 个跟随者都不可用,这时候首领继续接收新数据都会得到确认并提交(因为此时首领是唯一处于 ISR 的副本),那 2 个跟随者数据会滞后。假如现在首领不可用,2 个跟随者任一重新启动,就成为了分区中唯一可用的并且处于 OSR 的副本。
- 分区有 3 个副本,由于网络问题导致 2 个跟随者复制消息滞后成为了 OSR 中的副本,首领作为唯一 ISR 副本继续接收消息。假如首领不可用,而另外两个副本也无法追平滞后消息成为 ISR 副本。
这时候就需要做出抉择,是否让 OSR 副本成为新首领,也就是是否要完成“不完全”的首领选举。
通过 Broker 配置参数 unclean.leader.election.enable (类型=boolean,默认值=false)指定是否允许 OSR 成为首领。
如果不允许,则分区在旧首领(最后一个ISR副本)恢复前不可用;如果允许,那么旧主后面写入的,OSR 未同步的数据将丢失。简单来说允许会有丢失数据和出现数据不一致的风险,不允许会降低可用性。
像支付这种对数据一致性要求比较高的场景建议设置成 false;类似接收界面实时点击流这种对可用性要求较高的场景建议设置成 true。
最少在同步的副本
最少在同步的副本(min.insync.replicas) 可以在 Broker (类型=int,默认值=1)配置文件中配置。
# 最少在同步的副本数为2
min.insync.replicas=2
也可以在创建 Topic(类型=int,默认值=1)的时候单独指定。
echo "创建my-topic同时指定最少在同步的副本数量为2" > /dev/null
kafka-topics.sh --bootstrap-server node1:9092 --create --topic my-topic --partitions 2 --replication-factor 2 --config min.insync.replicas=2
当生产者(Producer)将发送确认(acks)配置成需要所有 ISR 副本同步(all或者-1)时,最少在同步的副本会限制要求最少同步的 ISR 副本数量,如果不能满足这个值,生产者会收到 NotEnoughReplicas 或 NotEnoughReplicasAfterAppend 异常,这样可以保证更好的消息持久性。
比如生产者将 acks 设置成 all 向一个 3 副本的分区生产消息,如果 2 个跟随者因为宕机或者网络问题成为了 OSR,此时只有首领一个 ISR。如果没有配置最少在同步的副本,消息就能正常提交返回,只有首领保存了消息,如果首领宕机,将只能被迫在不完全的首领选举中抉择,允许则会有丢失消息的风险;如果将最少在同步的副本配置成 2,由于 ISR 数量不满足,生产者会收到异常,除非恢复其他副本让 ISR 数量满足条件才有可能正常生产。
生产者配置
在创建生产者时,通过构造函数接收的 Properties 指定生产者配置,比如:
Properties p = new Properties();
// 指定 Broker 地址
p.setProperty(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
KafkaProducer<String, String> producer = new KafkaProducer<>(p);
发送确认
这个配置为 acks(类型=string,默认值=1,有效值=[all, -1, 0, 1])。
p.setProperty(ProducerConfig.ACKS_CONFIG, "-1");
acks=0 生产者将消息发出去之后不等待确认,比较容易丢数据,比如网卡故障,网络问题,对象无法序列化等等。但是运行速度非常快,很多基准测试会基于这个模式,得到非常高的吞吐量和带宽利用率。
acks=1 只等待分区首领写入(不一定同步到磁盘)后的确认或者错误响应。如果这个模式下发生首领选举,生产者会收到 LeaderNotAvailableException 异常,如果生产者正确的处理异常进行重试,消息可以正常的到达首领。但是如果到达首领后,未复制到跟随者时首领奔溃,还是会导致消息丢失。
acks=all(或-1) 需要等待所有 ISR 副本同步后,首领才会返回确认。这个搭配最少在同步的副本(min.insync.replicas)能保证更高的消息可靠性。但是这种模式吞吐量较低,可以使用异步或者更大的提交批次来加快速度。
重试
生产者向Broker发送消息时,会收到成功响应码或者错误响应码,错误响应码(参考 org.apache.kafka.common.protocol.Errors)分为两种。一种是可以通过重试解决的错误,比如 LEADER_NOT_AVAILABLE 错误,因为新首领选举成功后就可以正常接收重试发送的消息;还有一种是无法通过重试解决的错误,比如 INVALID_CONFIG 错误,无论如何重试都无法改变配置,无意义的重试还是会返回错误。
可重试的错误可以通过指定重试次数 retries(类型=int,默认值=2147483647)让生产者自动解决。
p.setProperty(ProducerConfig.RETRIES_CONFIG, "10");
重试无法处理的错误就需要开发者手动进行处理了,比如:消息大小、认证错误、发送消息前的序列化错误、生产者重试次数达到上限时或者在消息占用内存达到上限时发生的错误。
重试可以在产生错误情况下让消息尽可能的到达 Broker,但是有可能会产生重复消息。比如网络问题导致生产者没收到 Broker 返回的确认,但是实际消息已经写入到 Broker,这时候重试会导致两条同样的消息出现。如果业务场景不能允许重复消息,就需要进行幂等处理。比如 MySQL 唯一约束保证相同消息只会消费一次;使用有幂等含义的消息,比如“将账户余额修改为 110”,这种消息无论消费多少个,账户余额始终一致。
一般情况下如果目标是不丢失任何消息,那么最好让生产者遇到可重试错误时候保持重试,因为像首领选举或者网络连接这种问题都可以在几秒内得到解决,让生产者重试就不需要额外去处理这些问题了。
重试次数需要根据业务场景决定,重试次数达到上限可以选择丢弃消息,因为重试造成的延迟让这条消息失去了意义,也可以通过其他方式保存起来,人工处理或者用补偿程序进行处理。
可靠的消费者
创建消费者方式和生产者方式一样,可以通过构造函数接收的 Properties 指定消费者配置,比如:
Properties p = new Properties();
// 指定 Broker 地址
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "node1:9092,node2:9092,node3:9092");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
消费组
group.id(类型=string,默认值=null)相同消费组的消费者会分配到所有分区的一个子集,一个消费者可以对应多个分区,但是一个分区只会分配给一个消费者,如果消费者不可用会触发再均衡,重新将分区分配给消费组成员来保证高可用。
p.setProperty(ConsumerConfig.GROUP_ID_CONFIG, "my-group");
自动重置偏移量
auto.offset.reset(类型=string,默认值=latest,有效值=[latest, earliest, none])没有偏移量可提交时(比如消费者第 1 次启动),或者当前提交的偏移量在服务器上不存在时(可能是数据被删除了)
earliest 从分区开始的位置开始读数据,这样会导致消费者读取大量的重复数据,但可以保证最少的数据丢失;latest 从分区的末尾开始读,这样可以减少重复的消息处理,但是很有可能会错过一些消息;none 抛出异常给消费者。
p.setProperty(AUTO_OFFSET_RESET_CONFIG, "latest");
自动提交
开启自动提交 enable.auto.commit(类型=string,默认值=true)开启后消费者会定期的提交已经处理过的偏移量,优点是让开发者编程更简单,缺点是可能重复消费或者丢失消息。
p.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
如果提交偏移量前停止消费消息,重新拉取消息会从上次拉取的地方开始,导致消费到重复消息;如果把消息交给另外的后台线程处理,自动提交机制可能在消息还没处理完毕前就提交偏移量,此时停止消费再重新拉取就会从最后提交的偏移量开始,导致未处理的消息丢失。
自动提交间隔 auto.commit.interval.ms(类型=int,默认值=5000)控制自动提交的频率,频率提升会增加额外的开销,但是可以降低重复处理消息的概率。
p.setProperty(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "5000");
显示提交偏移量
关闭自动提交,可以在代码中显示提交偏移量来更细粒度的控制,在处理完消息后,按每条消息、每个分区或者每个消息批次。提交频率越高,重复消息概率越低,性能越低,选择时需要在性能和重复消息数量之间的权衡。下面是不同批次提交偏移量的例子代码:
- 按每条消息。消费一条提交一次,可靠性高,提交频繁性能较低
/*
poll()中参数是没有数据的时候阻塞等待的策略,ZERO代表一直阻塞
一个分区只能由一个消费者消费,但是一个消费者可以消费多个分区,所以这里是一个集合,来自不同的分区
*/
ConsumerRecords<String, String> records = consumer.poll(Duration.ZERO);
for (ConsumerRecord<String, String> record : records) {
// 消费消息
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
offsets.put(new TopicPartition(ConsumerCommitSample.TOPIC, record.partition()), new OffsetAndMetadata(record.offset()));
consumer.commitSync(offsets);
}
- 按分区提交。一次拉取的消息是从多个分区获得的,不同分区偏移量是单独维护,不同分区分开消费、提交偏移量互不影响,这种情况可以通过多线程并行提高效率,这里使用的并行流(Parallel Stream)可以替换成线程池。
ConsumerRecords<String, String> records = consumer.poll(Duration.ZERO);
Set<TopicPartition> partitions = records.partitions();
// 不同分区并行分开消费、提交偏移量
partitions.parallelStream().forEach(partition -> {
List<ConsumerRecord<String, String>> crs = records.records(partition);
// 同一分区也可以并行处理,最终提交最大的offset就行,如果需要保证顺序消费这里就应该串行
crs.parallelStream().forEach(cr -> System.out.println("消费消息"));
Map<TopicPartition, OffsetAndMetadata> offsets = new HashMap<>();
long offset = crs.get(crs.size() - 1).offset();
offsets.put(partition, new OffsetAndMetadata(offset));
consumer.commitSync(offsets);
});
- 按批次提交。提交粒度大,性能较高。
ConsumerRecords<String, String> records = consumer.poll(Duration.ZERO);
for (ConsumerRecord<String, String> record : records) {
// 消费消息
}
consumer.commitSync();
再均衡
新消费者费者加入群组、消费者离开群组、主题变化(如增减分区)、都会触发再均衡,由群组协调器(GroupCoordinator)来将分区消费所有权重新分配。消费者一定要实现再均衡监听器(ConsumerRebalanceListener)的两个接口,在分区撤销前提交偏移量,并在分配到新分区时,清理之前的状态。
public class HandRebalanceSample {
private final Map<TopicPartition, OffsetAndMetadata> currentOffsets = new HashMap<>();
/**
* 消费者
*
* @param consumerGroup 消费者归属的消费组
*/
public void consumer(String consumerGroup) {
Properties p = new Properties();
p.setProperty(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, BROKER_ADDRESSES);
p.setProperty(GROUP_ID_CONFIG, consumerGroup);
p.setProperty(KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class.getName());
p.setProperty(ENABLE_AUTO_COMMIT_CONFIG, "false");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(p);
ConsumerRebalanceListener rebalanceListener = new ConsumerRebalanceListener() {
/**
* 方法会在消费者停止读取消息之后和再均衡开始之前被调用。
*
* @param collection 拥有的分区集合
*/
@Override
public void onPartitionsRevoked(Collection<TopicPartition> collection) {
// 如果在这里提交偏移量,下一个接管分区 的消费者就知道该从哪里开始读取了
consumer.commitSync(currentOffsets);
}
/**
* 方法会在重新分配分区之后和消费者开始读取消息之前被调用
*
* @param collection 拥有的分区集合
*/
@Override
public void onPartitionsAssigned(Collection<TopicPartition> collection) {
// 清除之前状态。。。
}
};
try {
consumer.subscribe(Collections.singleton(TOPIC), rebalanceListener);
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ZERO);
for (ConsumerRecord<String, String> record : records) {
System.out.printf("消费的分区信息————partition:%s, offset:%s, key:%s, value:%s%n",
record.partition(), record.offset(), record.key(), record.value());
this.currentOffsets.put(
new TopicPartition(record.topic(), record.partition()),
new OffsetAndMetadata(record.offset() + 1));
}
consumer.commitAsync(this.currentOffsets, null);
}
} catch (Exception e) {
// 忽略或者记录日志
} finally {
try {
consumer.commitSync(this.currentOffsets);
} finally {
consumer.close();
}
}
}
}
心跳
消费者通过向被指派为群组协调器的 Broker(不同消费组的协调器可能不同)发送心跳来证明自己是存活的,如果超过会话过期时间 session.timeout.ms(类型=int,默认值=45000)群组协调器会认为它已经死亡,从而触发一次再均衡。
p.setProperty(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "45000");
老版本是通过拉取消息和提交偏移量来保持心跳,而新版本是一个单独线程定时发送的,可以通过 heartbeat.interval.ms(类型=int,默认值=3000)配置间隔时间,必须小于 session.timeout.ms,否则会报错,一般是它的 1/3 或者更小。
参考
《Kafka权威指南》
Apache - Kafka文档2.8