【文献阅读】具有循环一致性的鲁棒VQA与数据集VQA-Rephrasings(M. Shah等人,CVPR,2019)
一、文章概况
文章题目:《Cycle-Consistency for Robust Visual Question Answering》
这篇文章和前面介绍的MirrorGAN几乎是同一个idea,作者主要来自facebook,找到了第三和第四作者的个人主页,其中Marcus Rohrbach一直在做VQA,可以关注下,但是他的个人主页已经很久没有更新了:
[1] Marcus Rohrbach的个人主页
[2] Devi Parikh的个人主页
文章下载地址:http://openaccess.thecvf.com/content_CVPR_2019/papers/Shah_Cycle-Consistency_for_Robust_Visual_Question_Answering_CVPR_2019_paper.pdf
文章引用格式:M. Shah, X. Chen, M. Rohrbach, D. Parikh. "Cycle-Consistency for Robust Visual Question Answering." In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
项目地址:暂时没有
二、文章导读
网上目前找到了一篇关于这篇文献的解读:
[3] CVPR2019 | 基于循环一致性增强视觉问答模型鲁棒性的方法
下面先给出文章的摘要部分:
Despite significant progress in Visual Question Answering over the years, robustness of today’s VQA models leave much to be desired. We introduce a new evaluation protocol and associated dataset (VQA-Rephrasings) and show that state-of-the-art VQA models are notoriously brittle to linguistic variations in questions. VQA-Rephrasings contains 3 human-provided rephrasings for 40k questions spanning 40k images from the VQA v2.0 validation dataset. As a step towards improving robustness of VQA models, we propose a model-agnostic framework that exploits cycle consistency. Specifically, we train a model to not only answer a question, but also generate a question conditioned on the answer, such that the answer predicted for the generated question is the same as the ground truth answer to the original question. Without the use of additional annotations, we show that our approach is significantly more robust to linguistic variations than state-of-the-art VQA models, when evaluated on the VQA-Rephrasings dataset. In addition, our approach outperforms state-of-the-art approaches on the standard VQA and Visual Question Generation tasks on the challenging VQA v2.0 dataset.
尽管这些年VQA已经取得了一些进步,但是VQA的鲁棒性问题却鲜有关注。作者介绍了一个新的评估思路和数据集VQA-Rephrasings。数据集VQA-Rephrasings来自于VQAv2,是对40万个问题改述生成的40万张图的描述。为了改善VQA的鲁棒性,作者提出了使用循环一致性的model-agnostic框架。模型不仅能够回答问题,还能够根据答案生成问题。在没有使用另外的标注信息,基于VQA-Rephrasings数据集的结果表明该模型比其他的VQA模型更具有鲁棒性。
三、文献详细介绍
作者指出,目前尽管VQA取得了一些进步,但是对于语言不一致的问题仍显得非常脆弱(brittle to such linguistic variations),比如:

可以看到,对于同一张图片,如果稍微改变一下问题,那么回答就完全不一样了。解决这个问题的办法之一是收集更多样的数据集,因此作者提出了一个新的model-agnostic框架,该框架用循环一致性来学习鲁棒的VQA,而不需要任何外部人为知识。而且,这个模型不仅仅能够回答问题,还能够生成问题。
作者提出方法的优点在于它是two-fold,首先,执行一致性能够使得模型概括出问题的语义变化,这一步的实现是生成改写的多样性的问题而实现的,其次,模型能够根据给定的答案和图像生成一个有效的答案,而且生成的答案有更小的语言偏见。
最后,作者还发现目前VQA鲁棒性的研究很少是因为缺少一个基准,为了进行鲁棒性和一致性的质量评估,作者提出了一个数据集VQA-Rephrasings。这篇文章的主要贡献在于:
• We propose a model-agnostic cycle-consistent training scheme that enables VQA models to be more robust to linguistic variations observed in natural language open-ended questions. (提出了一个循环一致性的训练机制,能够使得VQA更鲁棒)
• To evaluate the robustness of VQA models to linguistic variations, we introduce a large-scale VQA-Rephrasings dataset and an associated consensus score. VQA-Rephrasings consists of 3 rephrasings for ∼40k questions on ∼40k images from the VQA v2.0 validation dataset, resulting in a total of ∼120k question rephrasings by humans. (为了评价VQA模型的鲁棒性,作者提出了一个新的大规模数据集VQA-Rephrasings)
• We show that models trained with our approach outperform state-of-the-art on the standard VQA and Visual Question Generation tasks on the VQA v2.0 dataset and are significantly more robust to linguistic variations on VQA-Rephrasings. (作者的方法比其他的方法更好)
1.相关工作
视觉问答Visual Question Answering:一般是用LSTM和卷积网络,作者的方法是model-agnostic的,可以用在任何VQA结构。
鲁棒性Robustness:有少量的文章进行了VQA的鲁棒性研究。作者希望能够在问题改写的情况下能够学习到鲁棒的VQA模型,这里的鲁棒性研究还涉及到了文本偏见(contexts of bias),域转换(domain-shift),语法变异(syntactic variations)。
视觉问题生成(Visual) Question Generation:VQG其实和VQA类似,目前已有变种LSTM实现该任务。不同于现有的一些研究,作者的模型不限制于生成指定类型的问题,作者的目标是能够自动改写VQG,据作者所知,它的模型是第一个能够将VQG模块用在VQA的循环一致性研究中的。
循环一致学习Cycle-Consistent Learning:一致性能够使得模型更为鲁棒,它通过正则变化(regularizing transformations),能够将一种模态映射到另一种模态当中。循环一致性(cycle-consistency)目前广泛的用于单模态当中,对于多模态交互,比如VQA,目前还没有应用。VQA中的循环一致性也可以视为一种在线的数据增广(online data-augmentation)
2. 方法
作者采用的模型结构如下所示:
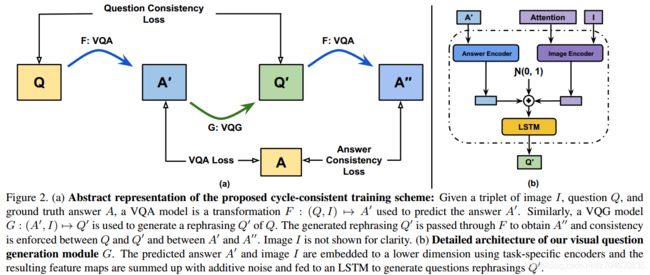
如果用Q表示问题,I表示图像,A表示答案,那么一个VQA问题(上图中的a)可以表示为:F : (Q, I) → A′,一个VQG问题(上图中的b)可以表示为:G : (A, I) → Q′。如果给定一个(I,Q,A)元组,我们首先可以根据原始问题Q在VQA模型中获得一个预测答案A',然后用预测答案A'和图像I可以在VQG模型中生成一个问题Q‘,最后我们可以根据Q'再生成A''。
这里其实是基于两个假设,①模型如果能够生成语义和语法正确的问题,则模型较好的理解了交叉模态的衔接;②假设生成问题Q′是一个原始问题Q的有效改写,一个鲁棒的VQA模型对改写问题Q'的答案应该与对原始问题Q的答案一致。
(1)问题生成模块Question Generation Module
VQA问题中,QA是一种对图像的压缩表示,这是有很大的损失,学习多个模态之间的映射绝非易事。一般的循环一致模型能够处理单个模态,然而像VQG这种多模态变换则需要额外的监督信息。在VQG中,这种监督信息作者用attention补充,这里的attention是由原问题定位到图像中相应的区域生成的,这样就使得VQG最后生成的问题和原始问题类似。
实际上问题生成模型G(question generation module G)和条件看图说话模型(conditional image captioning model)类似。问题生成模块由两个线性编码器组成,它们将VQA中获得的图像特征和答案空间的分布转换成低维特征向量。将这些特征向量添加噪声,然后传入LSTM网络,以重构原始问题Q,优化方式采用的是负对数似然(negative log likelihood)。这里表示获得的答案向量并没有用one-hot或者词嵌入,而是预测答案的分布。
模型所有的损失分成3部分,分别是Q-consistency(VQG生成的问题Q'和原始问题Q的损失),A-consistency(答案A和预测答案A'之间的损失),还有一个循环损失(答案A和对生成问题Q'的预测答案A'')。所有损失就是这三部分损失之和:
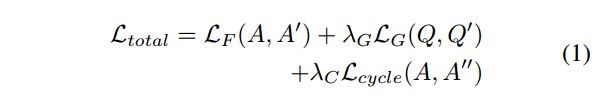
(2)门机制Gating Mechanism
之前的一个假设就是生成的Q'的语义和语法总是正确的,然而这些假设并不总是正确的。之前生成的问题,没有经过任何过滤,就进行增广,制作训练集,这样是没有任何用的。因此用问题生成器生成的问题中,并非所有问题都能够与I-Q-A一致。因此作者提出了一个门机制,以过滤掉一些不适合的问题。对于生成的问题Q',只保留答案与原始答案的余弦相似度阈值大于Tsim的。
(3)后激活Late Activation
设计循环一致的关键是需要阻止模式倒塌(mode collapse)现象。因为循环一致模型有多个连接的子网络,因此确保各个子网络之间的正常工作是必要的。为了确保VQA和VQG都能有效的产生合理的输出,作者通过在训练的最后阶段激活循环一致(activating cycle-consistency at later stages of training)来解决这个问题。
以上的三个模块都是非常有必要的,作者后续又进行了ablation study进行了说明。VQA模型中对Q的回答和Q'的回答是权值共享的。另外,这里的循环一致处理也可以认为是一种在线的数据增广方式。
3. VQA-Rephrasings数据集
这是首个能够进行一致性和鲁棒性(robustness and consistency)VQA模型评估的数据集。
作者的base dataset来自于VQAv2验证集的一部分(validation split of VQAv2),一共包含了214354个问题和40504张图片。作者随机采样了40504个问题(一个问题一张图片)构成采样子集。作者用两阶段方式对每个问题用人工标注的方式生成3个改写问题,第一阶段,根据原始的Q-A改写问题,改写后的问题回答要与原始答案一致;第二阶段,对第一阶段的问题进行语法和语义检查,以下两种情况标记为无效答案:a.改写后的问题答案对于原始问题来说貌似合理,但两个问题的目的不同,b.改写后的语法错误。第一个阶段从40504个问题收集到了121512个改写问题,第二阶段标记出1320个无效问题,最后获得了162016个问题(包括改写的121512个和原始的40504个)和40504张图片,平均每张图片约3个改写问题,一些样本示例如下:

一个问题的改写和原始问题,二者的答案应该是相同的,因此我们可以用一致得分CS(k)来评价数据集,一个问题组Q有n个改写,我们选取出其中的k个,那么一致得分则可以用下式来计算:

其中:
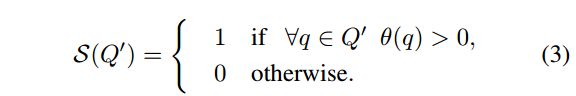
4. 实验
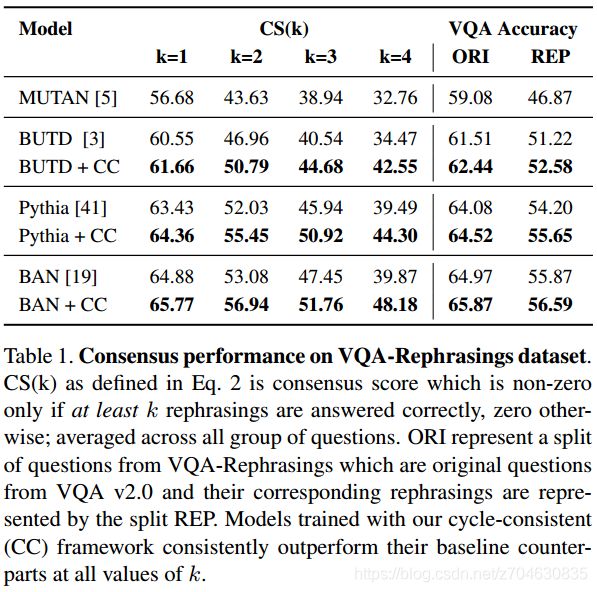
(1)一致性表现:
作者基于VQA-Rephrasings数据集对一系列模型进行评价,模型包括:
MUTAN:参考https://github.com/Cadene/vqa.pytorch
Bottom-Up Top-Down Attention (BUTD):参考https://github.com/hengyuan-hu/bottom-up-attention-vqa
Pythia:参考https://github.com/facebookresearch/pythia
Bilinear Attention Networks (BAN):参考https://github.com/jnhwkim/ban-vqa
来看一下各个模型比较的结果:
之后作者在4个改写上进行了文本和视觉注意力的比较,结果也体现出了模型的鲁棒性:
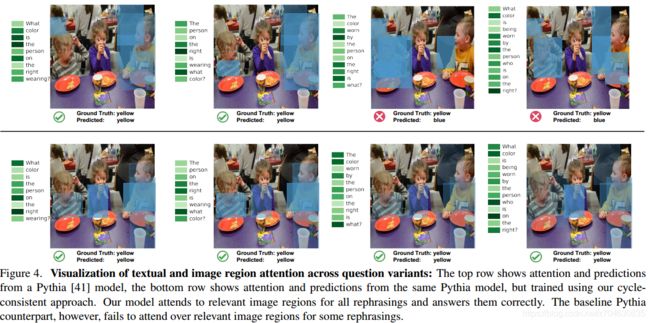
(2)VQA表现
这部分作者进行了ablation study,对各个模块进行了分析,结果如下:

(3)VQG性能
这里作者进行了两个模型的比较——iVQA和iQAN,实验结果如下所示:

(4)失败预测的表现
前面介绍过提高模型鲁棒性的办法之一就是生成问题,产生更丰富的数据集;另一个办法就是看模型能否预测他们的失败(to see if models can predict their own failures)。所以作者使用了两个预测失败机制,首先,用置信阈值来区分答案,其次,作者设计了一个失败预测二值分类模型FP(failure prediction binary classification module),通过给定(I,Q)来预测答案是否正确,实验结果如下:
