从IC曲线提取特征,采用随机森林对电池SOH进行估计
从IC曲线提取特征,采用随机森林对电池SOH进行估计
什么是SOH?
本文采用电池容量衰减定义SOH,,给出的 SOH定义如下:

即电池当前容量处于电池额定容量的百分数。
随机森林
随机森林可以看我的文章https://blog.csdn.net/qq_51444641/article/details/122783753?spm=1001.2014.3001.5501
本个项目意义
如今电动汽车越来越普及,对于电池的要求也越来越高。现在已经有额定续航500~600km的电池,特斯拉所推出的Roadster额定续航高达1000km。
但是电池的实际容量往往是不能达到额定容量的,所以电车的实际续航也不可能达到额定的续航里程,此时对电池容量的准确估计便十分重要。对电池容量的准确估计能够使驾驶人准确判断何时应进行充电。同时在电池回收市场中,电池的实际容量对于电池的估价有重要的参考价值。
估计方法
不废话,开始正文。
特征提取
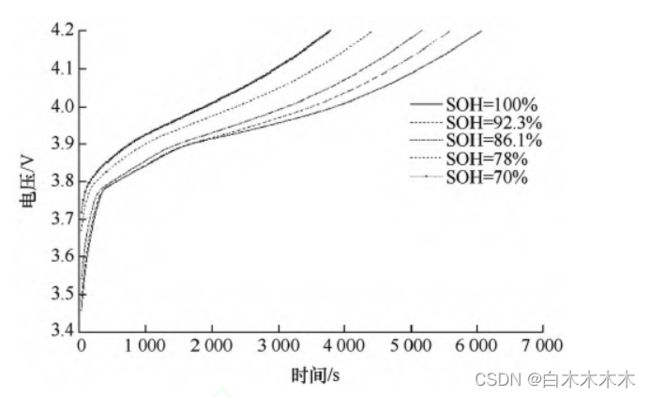
IC曲线即电池充放电过程中电流随电压的变化曲线。
由于不同电池的放电以及电池的每个周期放电情况由于使用人的习惯会产生很大的差异,所以我们并不采用放电周期的IC曲线。我们从充电周期的IC曲线中提取特征。将不同SOH下的充电周期IC曲线画出来进行一个渐进对比,我们可以看出曲线随着容量的下降变化明显。
接着,我们对不同电压位置的dQ/dV进行计算,具体计算公式:
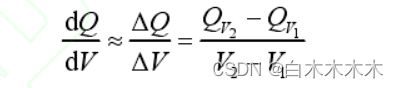
画出dQ/dV随电压变化的曲线:
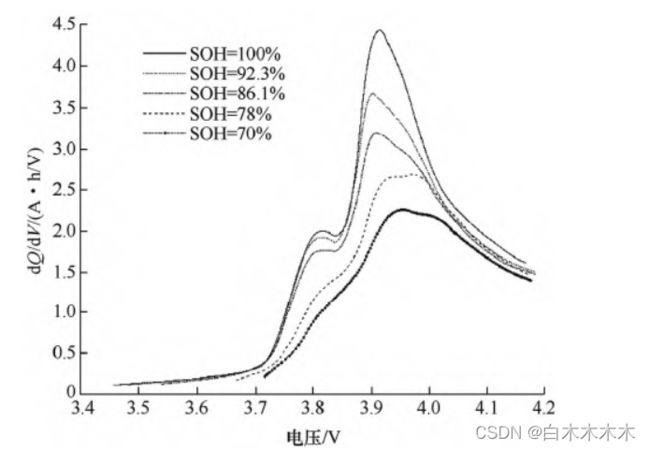
可以看出该曲线随容量的下降变化也较明显,尤其是峰值与峰值所处位置,于是我们将峰值与峰值所处位置作为选定的两个特征。紧接着根据文献
再结合实际情况,电动车的充电范围一般在40%~90%的范围内,于是我们将选取的电压范围限定在3.85v-4.09v。0.03v作为一个选取区间,每隔0.03v取一个dQ/dV值,将其作为特征F1-F8。而后将0.04v作为一个区间,对每个区间的充电时间进行测量,将其作为特征F9-F14,最后将峰值与峰值所处位置作为F15-F16,共提取16个特征。
利用xgboost实现SOH的预测
本个项目采用马里兰数据集,我们先将马里兰数据集中的每个Cell转换为csv文件,具体转换方法见我文章https://blog.csdn.net/qq_51444641/article/details/124974293?spm=1001.2014.3001.5501
转换完成后进行数据的读取
###Cell1提取文件名
strseq = []
for i in range(10):
strseq.append('cyc'+'0'+str(i)+'00')
for i in range(10,15):
strseq.append('cyc'+str(i)+'00')
strseq.append('cyc1600')
for i in range(18,34):
strseq.append('cyc' + str(i) + '00')
for i in range(35,47):
strseq.append('cyc' + str(i) + '00')
strseq.append('cyc4800')
for i in range(50,83):
strseq.append('cyc' + str(i) + '00')
每个Cell类似,先将文件名全部输出,每个文件名对应每个Cell充电循环中的一个circle。
path = 'Cell1.'
path_q = '.C1ch.q.xlsx'
C1ch_q = []
for i in strseq:
C1ch_q.append(pd.read_excel(path+i+path_q,header=None))
path_v = '.C1ch.v.xlsx'
C1ch_v = []
for i in strseq:
C1ch_v.append(pd.read_excel(path+i+path_v,header=None))
path_t = '.C1ch.t.xlsx'
C1ch_t = []
for i in strseq:
C1ch_t.append(pd.read_excel(path+i+path_t,header=None))
将每个Cell的数据分别输出到t(充电时间)、v(充电电压)、q(电量电荷)
###计算出每个充电周期的电池容量,即训练所用y值
C1ch_SOH = np.arange(len(C1ch_q))
for i in range(len(C1ch_q)):
C1ch_SOH[i] = float(max(C1ch_q[i].values))
C1ch_SOH = C1ch_SOH.astype(float)
for i in range(1,len(C1ch_q)):
C1ch_SOH[i] = C1ch_SOH[i]/C1ch_SOH[0]
C1ch_SOH[0] = C1ch_SOH[0]/C1ch_SOH[0]
C1ch_SOH = pd.DataFrame(C1ch_SOH)
y_Cell1 = C1ch_SOH
而后提取出每个电池电荷量中的电量最大值(基本是第一个circle的第一个电荷量值)作为每个circle的电池容量。将其输出到y_Cell中,每个Cell的操作一样。
而后将每个circle对应的容量都转化为百分数,即SOH。
##将电池剩余电量转化为百分比
C1ch_q_m = []
for q in C1ch_q:
q = np.array(q,dtype=float)
qmax = q[-1]
for i in range(len(q)):
q[i] = q[i]/qmax
q = pd.DataFrame(q)
C1ch_q_m.append(q)
而后将电池的产量与容量整理为一个Dataframe.
而后进行特征的提取
##选取电压范围:3.85~4.09,提取特征
highest_v = []
for i in range(len(C1ch_q)):
highest_v.append(C1ch_v_q_1[i].iloc[-1,0])
min_highest_v = min(highest_v)
###提取不同电压段电压上升所需时间
feature1 = []
for i in range(len(C1ch_q)):
count_1 = []
for j in range(6):
count_1.append(len(C1ch_v_q_1[i][(C1ch_v_q_1[i].v > 3.85 + 0.04*j) & (C1ch_v_q_1[i].v < (3.85+0.04*(j+1)) )]))
feature1.append(count_1)
###提取IC曲线的特征
feature2 = []
for i in range(len(C1ch_q)):
count_2 = []
for j in range(8):
d = C1ch_v_q_1[i][(C1ch_v_q_1[i].v > 3.85 + 0.03*j) & (C1ch_v_q_1[i].v < (3.85+0.03*(j+1) ) ) ]
d_q_v = (d.iloc[-1 ,1]-d.iloc[0 ,1])/(d.iloc[-1 ,0]-d.iloc[0 ,0])
count_2.append(d_q_v)
max_d_q_v = max(count_2)
max_d_q_v_id = count_2.index(max_d_q_v)
print(max_d_q_v_id)
count_2.append(max_d_q_v)
feature2.append(count_2)
feature = []
for i in range(len(C1ch_q)):
feature.append(feature1[i]+feature2[i])
feature = pd.DataFrame(feature) #样本特征
将样本特征全部提取完毕后带入xgboost进行预测:
###随机森林
X_train, X_test, y_train, y_test = train_test_split(feature,y,test_size=0.2,random_state=0)
regressor = RandomForestRegressor(n_estimators=200, random_state=0)
regressor.fit(X_train, y_train)
y_pred = regressor.predict(X_test)
from sklearn import metrics
print('Mean Absolute Error:', metrics.mean_absolute_error(y_test, y_pred))
print('Mean Squared Error:', metrics.mean_squared_error(y_test, y_pred))
print('Root Mean Squared Error:',
np.sqrt(metrics.mean_squared_error(y_test, y_pred)))
最终所的误差小于0.4%,采用随机取样所得预测与实际值对比图:
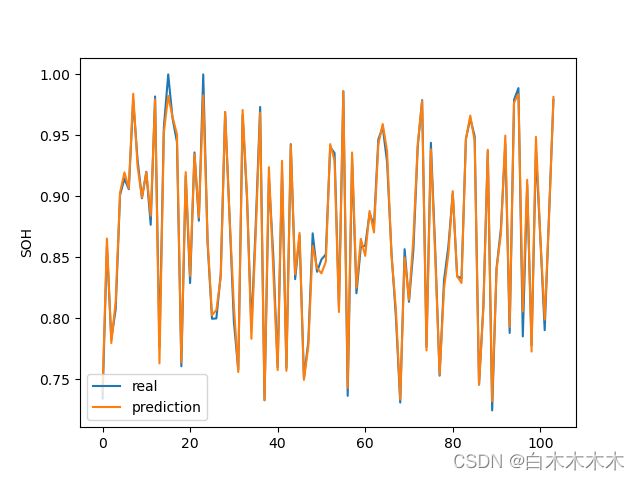
由图可见预测效果不错。
下面是寻找最优参数代码:
##以下代码用于寻找最优参数
def build_model(optimizer):
grid_model = Sequential()
grid_model.add(LSTM(100,return_sequences=True,input_shape=(12000,3)))
grid_model.add(LSTM(50))
grid_model.add(Dropout(0.2))
grid_model.add(Dense(1))
grid_model.compile(loss = 'mse',optimizer = optimizer)
return grid_model
grid_model = KerasRegressor(build_fn=build_model, verbose=1, validation_data=(testX, testY))
parameters = {'batch_size' : [16,20],
'epochs' : [8,10],
'optimizer' : ['adam','Adadelta'] }
grid_search = GridSearchCV(estimator = grid_model,
param_grid = parameters,
cv = 2)
grid_search = grid_search.fit(trainX,trainY)
my_model=grid_search.best_estimator_.model
所需导入库:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.layers import LSTM
from tensorflow.python.keras.layers import Dense, Dropout
from sklearn.preprocessing import MinMaxScaler
from keras.wrappers.scikit_learn import KerasRegressor
from sklearn.model_selection import GridSearchCV
import os
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestRegressor
其实最终所得结果较好在意料之中,因为特征中包含了dQ/dv,一个电池容量有关的特征,相当于特征中包含了预测对象中的某些属性。这在实际中并不实用,因为你不能在预测前就知道一个电池的容量。本文仅供参考,引用请标注来源。