(五)SSD----2016ECCV论文解读
SSD: Single Shot MultiBox Detector
摘要
我们提出了一种使用单个深层神经网络检测图像中对象的方法。我们的方法,名为SSD,将边界框的输出空间离散化为一组默认框,该默认框在每个特征图位置有不同的宽高比和尺寸。在预测期间,网络针对每个默认框中的每个存在对象类别生成分数,并且对框进行调整以更好地匹配对象形状。另外,网络组合来自具有不同分辨率的多个特征图的预测,以适应处理各种尺寸的对象。我们的SSD模型相对于需要region proposal的方法是简单的,因为它完全消除了proposal生成和后续的像素或特征重采样阶段,并将所有计算封装在单网络中。这使得SSD容易训练和直接集成到需要检测组件的系统。PASCAL VOC,MS COCO和ILSVRC数据集的实验结果证实,SSD与使用额外的region proposal的方法具有可比较的准确性,并且速度更快,同时为训练和推理提供统一的框架。与其他单级方法相比,SSD具有更好的精度,即使输入图像尺寸更小。对VOC2007,在300×300输入,SSD在Nvidia Titan X上58FPS时达到72.1%的mAP,500×500输入SSD达到75.1%的mAP,优于类似的现有技术Faster R-CNN模型。代码链接:https://github.com/weiliu89/caffe/tree/ssd
1、 引言
当前,现有对象检测系统是以下方法的变体:假设边界框,对每个框重新取样像素或特征,再应用高质量分类器。选择性搜索[1]方法后,Faster R-CNN[2]在PASCAL VOC,MSCOCO和ILSVRC检测取得领先结果,这种流程成为检测领域的里程碑,具有更深的特征,如[3]所述。尽管准确,但这些方法对于嵌入式系统来说计算量过大,即使对于高端硬件,对于实时或接近实时的应用来说也太慢。 这些方法的检测速度通常以每秒帧数为单位进行测量,高精度检测器(基础 Faster R-CNN)最快仅以每秒7帧(FPS)运行。目前,已有广泛的尝试,通过研究检测流程的每个阶段(参见第4节中的相关工作)来建立更快的检测器,但是迄今为止,显着增加的速度仅仅是以显着降低的检测精度为代价。
本文提出了第一个基于深层网络的对象检测器,它不会对边界框假设的像素或特征进行重新取样,但和这种做法一样准确。这使高精度检测速度有显着提高(在VOC2007测试中, 58 FPS下 72.1%mAP,对Faster R-CNN 7 FPS 下mAP 73.2%,YOLO 45 FPS 下mAP 63.4%)。**速度的根本改进来自消除边界框proposal和随后的像素或特征重采样阶段。**这不是第一篇这么做的文章(cf [4,5]),但是通过增加一系列改进,我们设法提高了以前尝试的准确性。我们的改进包括使用不同宽高比检测的单独的预测器(滤波器),预测边界框中的对象类别和偏移,并且将这些滤波器应用于网络后期的多个特征图,以便执行多尺度检测。通过这些修改,我们可以使用相对低分辨率的输入实现高精度检测,进一步提高处理速度。 虽然这些贡献可能独立看起来很小,但我们注意到,所得系统提高了PASCAL VOC的高速检测的准确性,从YOLO的63.4%mAP到我们提出的网络的72.1%mAP。相比近期工作,这是在检测精度上的较大提高,残差网络上的卓越工作 [3]。 此外,显着提高高质量检测的速度可以拓宽计算机视觉有用使用范围。
总结我们的贡献如下:
• 我们引用了SSD,一个单次检测器,用于多个类别,比先前技术的单次检测器(YOLO)速度更快,并且更准确很多,实际上和使用region proposal、pooling的更慢技术一样准确(包括Faster RCNN)
• SSD方法的核心是使用小卷积滤波器来预测特征图上固定的一组默认边界框的类别分数和位置偏移。
• 为了实现高检测精度,我们从不同尺度的特征图产生不同尺度的预测,并且通过宽高比来明确地分离预测。
• 总之,这些设计特性得到了简单的端到端训练和高精度,进一步提高速度和精度的权衡,即使输入相对低分辨率图像。
• 实验包括在PASCAL VOC,MS COCO和ILSVRC上评估不同输入大小下模型耗时和精度分析,并与一系列最新的先进方法进行比较。
2、单次检测器(SSD)
本节介绍我们提出的SSD检测架构(第2.1节)和相关的训练方法(第2.2节)。之后, 第3节呈现特定数据集的模型细节和实验结果。

图1:SSD架构。(a)SSD在训练期间仅需要每个对象的输入图像和真实标签框。 卷积处理时,我们在具有不同尺度(例如(b)和(c)中的8×8和4×4)的若干特征图中的每个位置处评估不同横宽比的小集合(例如4个)默认框。 **对于每个默认框,我们预测所有对象类别((c 1,c2,…,cp))的形状偏移和置信度。**在训练时,我们首先将这些默认框匹配到真实标签框。 例如,两个默认框匹配到猫和狗,这些框为正,其余视为负。 模型损失是位置损失(例如平滑L1 [6])和置信损失(例如Softmax)之间的加权和。
2.1 模型
SSD方法基于前馈卷积网络,其产生固定大小的边界框集合和框中对象类别的分数,接着是非最大化抑制步骤以产生最终检测。早期网络基于高质量图像分类(在任何分类层之前截断(译者注:特征提取网络,例如:VGG、googlenet、alexnet))的标准架构,我们将其称为基础网络(我们的试验中使用了VGG-16网络作为基础,其他网络也应该能产生好的结果)。然后,我们向网络添加辅助结构,产生了具有以下主要特征的检测:
多尺度特征图检测:我们将卷积特征层添加到截断的基础网络的末尾。这些层尺寸逐渐减小,得到多个尺度检测的预测值。检测的卷积模型对于每个特征层是不同的(参见在单个尺度特征图上操作的Overfeat [4]和YOLO[5])。
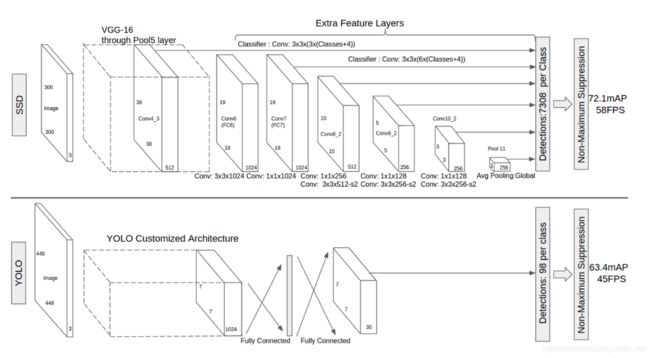
图2:两个单次检测模型之间的比较:SSD和YOLO [5]。 我们的SSD模型在基础网络的末尾添加了几个特征层,这些层预测了不同尺度和宽高比对默认框的偏移及其相关置信度。 300×300输入尺寸的SSD在VOC2007测试中的精度显著优于448×448输入的YOLO的精度,同时还提高了运行速度,尽管YOLO网络比VGG16快。
检测的卷积预测器:每个添加的特征层(或可选的基础网络的现有特征层)可以使用一组卷积滤波器产生固定的预测集合。这些在图2中SSD网络架构顶部已指出。对于具有p个通道的大小为m×n的特征层,使用3×3×p卷积核卷积操作,产生类别的分数或相对于默认框的坐标偏移。在每个应用卷积核运算的m×n大小位置处,产生一个输出值。边界框偏移输出值是相对于默认框测量,默认框位置则相对于特征图(参见YOLO [5]的架构,中间使用全连接层而不是用于该步骤的卷积滤波器)。
默认框与宽高比:我们将一组默认边界框与顶层网络每个特征图单元关联。默认框对特征图作卷积运算,使得每个框实例相对于其对应单元格的位置是固定的。在每个特征映射单元中,我们预测相对于单元格中的默认框形状的偏移,以及每个框中实例的每类分数。具体来说,对于在给定位置的k个框中每个框,我们计算c类分数和相对于原始默认框的4个偏移量。这使得在特征图中的每个位置需要总共(c+4)k个滤波器,对于m×n特征图产生(c+4)kmn个输出。有关默认框的说明,请参见图1。我们的默认框类似于Faster R-CNN [2]中使用的anchor boxes,但我们将其应用于不同分辨率的特征图中。在多个特征图中使用不同的默认框形状,可以有效地离散可能的输出框形状空间。
2.2 训练
训练SSD和训练使用region proposal、pooling的典型分类器的关键区别在于,真实标签信息需要被指定到固定的检测器输出集合中的某一特定输出。Faster R-CNN [2]和MultiBox [7]的regionproposal阶段、YOLO [5]的训练阶段也需要类似这样的标签。一旦确定了该指定,则端对端地应用损失函数和反向传播。训练还涉及选择用于检测的默认框和尺度集合,以及hard negative mining和数据增广策略。
匹配策略:在训练时,我们需要建立真实标签和默认框之间的对应关系。请注意,对于每个真实标签框,我们从默认框中进行选择,这些默认框随位置、纵横比和比例而变化。**开始时,我们匹配每个真实标签框与默认框最好的jaccard重叠。这是原始MultiBox [7]使用的匹配方法,它确保每个真实标签框有一个匹配的默认框。**与MultiBox不同,匹配默认框与真实标签jaccard重叠高于阈值(0.5)的默认框。添加这些匹配简化了学习问题:它使得有多个重叠默认框时网络预测获得高置信度,而不是要求它选择具有最大重叠的那个。
训练:SSD训练来自MultiBox[7,8],但扩展到处理多个对象类别。 以表示第i个默认框与类别p的第j个真实标签框相匹配,相反的 。 根据上述匹配策略,我们有 1,意味着可以有多于一个与第j个真实标签框相匹配的默认框。总体目标损失函数是位置损失(loc)和置信损失(conf)的加权和:
![]()
其中N是匹配的默认框的数量,位置损失是预测框(l)和真实标签值框(g)参数之间的平滑L1损失[6]。 类似于Faster R-CNN [2],我们对边界框的中心和其宽度和高度的偏移回归。 我们的置信损失是softmax损失对多类别置信(c)和权重项α设置为1的交叉验证。


选择默认框的比例和横宽比:大多数卷积网络通过加深层数减小特征图的大小。这不仅减少计算和存储消耗,而且还提供一定程度的平移和尺寸不变性。为了处理不同的对象尺寸,一些方法[4,9]建议将图像转换为不同的尺寸,然后单独处理每个尺寸,然后组合结果。然而,通过用单个网络中的若干不同层的特征图来进行预测,我们可以得到相同的效果,同时还在所有对象尺度上共享参数。之前的研究[10,11]已经表明使用来自较低层的特征图可以提高语义分割质量,因为较低层捕获到输入对象的更精细的细节。类似地,[12]表明,添加从高层特征图下采样的全局文本可以帮助平滑分割结果。受这些方法的启发,我们使用低层和高层的特征图进行检测预测。图1示出了在框架中使用的两个示例特征图(8×8和4×4),当然在实践中,我们可以使用更多具有相对小的计算开销的特征图。
已知网络中不同级别的特征图具有不同的(经验)感受野大小[13]。幸运的是,在SSD框架内,默认框不需要对应于每层的实际感受野。我们可以设计平铺,使得特定位置特征图,学习响应于图像的特定区域和对象的特定尺度。假设我们要使用m个特征图做预测。每个特征图的默认框的比例计算如下:
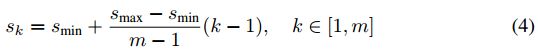
其中smin是0.2,smax是0.95,意味着最低层具有0.2的刻度,最高层具有0.95的刻度,并且其间的所有层是规则间隔的。我们对默认框施以不同的宽高比,表示为ar∈{1,2,3,1/2,1/3}。我们可以计算每个默认框的宽度
![]()
和
![]()
对于宽高比为1,我们还添加了一个缩放为 的默认框,从而使每个特征图位置有6个默认框。设定每个默认框中心为
![]()
,其中fk是第k个正方形特征图的大小
![]()
随后截取默认框坐标使其 始终在[0,1]内。实际上,可以设计默认框的分布以最佳地拟合特定数据集。
通过组合许多特征图在所有位置的不同尺寸和宽高比的所有默认框的预测,我们具有多样化的预测集合,覆盖各种输入对象尺寸和形状。例如图 1中,狗被匹配到4×4特征图中的默认框,但不匹配到8×8特征图中的任何默认框。这是因为那些框具有不同的尺度但不匹配狗的框,因此在训练期间被认为是负样本。
Hard negative mining :在匹配步骤之后,大多数默认框都是负样本,特别是当可能的默认框数量很大时。这导致了训练期间正负样本的严重不平衡。我们使用每个默认框的最高置信度对它们进行排序,并选择前面的那些,使得正负样本之间的比率最多为3:1,以代替使用所有的负样本。我们发现,这导致更快的优化和更稳定的训练。
数据增广:为了使模型对于各种输入对象大小和形状更加鲁棒,每个训练图像通过以下选项之一随机采样:
• 使用整个原始输入图像
• 采样一个片段,使对象最小的jaccard重叠为0.1,0.3,0.5,0.7或0.9。
• 随机采样一个片段
每个采样片段的大小为原始图像大小的[0.1,1],横宽比在1/2和2之间。如果真实标签框中心在采样片段内,则保留重叠部分。在上述采样步骤之后,将每个采样片大小调整为固定大小,并以0.5的概率水平翻转。
3、实验结果
基础网络:我们的实验基于VGG16 [14]网络,在ILSVRC CLS-LOC数据集[15]预训练。类似于DeepLab-LargeFOV [16],**我们将fc6和fc7转换为卷积层,从fc6和fc7两层采样得到参数,将pool5从2×2-s2更改为3×3-s1,并使用atrous算法填“洞”。**我们删除了所有的dropout层和fc8层,使用SGD对这个模型进行fine-tune,初始学习率 ,0.9 momentum, 0.0005 weight decay, batch大小32。每个数据集的学习速率衰减策略略有不同,稍后我们将描述详细信息。所有训练和测试代码在caffe框架编写,开源地址:https://github.com/weiliu89/caffe/tree/ssd。
3.1 PASCAL VOC2007
在这个数据集上,我们比较了Fast R-CNN [6]和Faster R-CNN [2]。所有方法使用相同的训练数据和预训练的VGG16网络。特别地,我们在VOC2007train val和VOC2012 train val(16551images)上训练,在VOC2007(4952图像)测试。
图2显示了SSD300模型的架构细节。我们使用conv4_3,conv7(fc7),conv8_2,conv9_2,conv10_2和pool11来预测位置和置信度(对SSD500模型,额外增加了conv11_2用于预测),用“xavier”方法初始化所有新添加的卷积层的参数[18]。由于conv4_3的大小较大(38×38),因此我们只在其上放置3个默认框 :一个0.1比例的框和另外纵横比为1/2和2的框。对于所有其他层,我们设置6个默认框,如第 2.2节。如[12]中所指出的,由于conv4_3与其他层相比具有不同的特征尺度,我们使用[12]中引入的L2正则化技术,将特征图中每个位置处的特征范数缩放为20,并在反向传播期间学习比例。我们使用 学习速率进行40k次迭代,然后将其衰减到 ,并继续训练另外20k次迭代。表1显示,我们的SSD300模型已经比Fast R-CNN更准确。当以更大的500×500输入图像训练SSD,结果更准确,甚至惊人的超过了Faster R-CNN 1.9% mAP。
为了更详细地了解我们的两个SSD模型的性能,我们使用了来自[19]的检测分析工具。图3显示SSD可以高质量检测(大、白色区域)各种对象类别。它的大部分置信度高的检测是正确的。召回率在85-90%左右,并且比“弱”(0.1 jaccard重叠)标准高得多。与R-CNN [20]相比,SSD具有较少的定位误差,表明SSD可以更好地定位对象,因为它直接回归对象形状和分类对象类别,而不是使用两个去耦步骤。然而,SSD对相似对象类别(尤其是动物)有更多的混淆,部分是因为多个类别分享了位置。

表1 : PASCAL VOC2007测试集检测结果。Fast和Faster R-CNN输入图像最小尺寸为600,两个SSD模型除了输入图像尺寸(300300和512512),其他设置与其相同。很明显,较大的输入尺寸得到更好的结果。
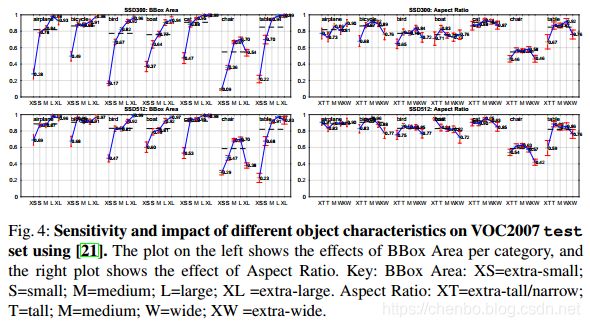
图4显示SSD对边界框尺寸非常敏感。换句话说,它对较小的对象比较大的对象具有更差的性能。这毫不意外,因为小对象在最顶层可能没有任何信息保留下来。增加输入尺寸(例如从300×300到512×512)可以帮助改善检测小对象,但是仍然有很大改进空间。积极的一面是,我们可以清楚地看到SSD在大对象上表现很好。并且对于不同的对象宽高比非常鲁棒,因为我们对每个特征图位置使用各种长宽比的默认框。
3.2 模型分析
为了更好地理解SSD,我们还进行了几个人为控制的实验,以检查每个组件如何影响最终性能。对于所有以下实验,我们使用完全相同的设置和输入大小(300×300),除了变动的组件。

关键的数据增广Fast和Faster R-CNN使用原始图像和水平翻转(0.5概率)图像训练。我们使用更广泛的采样策略,类似于YOLO [5],但它使用了我们没有使用的光度失真。表2显示,我们可以用这个抽样策略提高6.7%的mAP。我们不知道我们的采样策略将对Fast和Faster R-CNN提升多少,但可能效果不大,因为他们在分类期间使用了pooling,比人为设置更鲁棒。

图3:VOC2007测试集上SSD 500对动物、车辆和家具性能的可视化。 第一行显示由于定位不良(Loc),与类似类别(Sim)、其他类别(Oth)或背景(BG)混淆的正确检测(Cor)、假阳性检测的累积分数。 红色实线反映了随着检测次数的增加,“强”标准(0.5 jaccard重叠)的召回率变化。 红色虚线使用“弱”标准(0.1 jaccard重叠)。底行显示排名靠前的假阳性类型的分布。
更多特征图的提升 受许多语义分割工作启发[10,11,12],我们也使用底层特征图来预测边界框输出。我们比较使用conv4_3预测的模型和没有它的模型。从表2,我们可以看出,通过添加conv4_3进行预测,它有明显更好的结果(72.1% vs 68.1%)。这也符合我们的直觉,conv4_3可以捕获对象更好的细粒度,特别是细小的细节。
更多的默认框形状效果更好 如第2.2节所述,默认情况下,每个位置使用6个默认框。如果我们删除具有1/3和3宽高比的框,性能下降0.9%。通过进一步移除1/2和2纵横比的框,性能再下降2%。使用多种默认框形状似乎使网络预测任务更容易。
Atrous算法更好更快 如第3节所述,我们使用了VGG16的atrous版本,遵循DeepLabLargeFOV[16]。如果我们使用完整的VGG16,保持pool5与2×2-s2,并且不从fc6和fc7的采集参数,添加conv5_3,结果稍差(0.7%),而速度减慢大约50%。
3.3 PASCAL VOC2012
采用和VOC2007上一样的设置,这次,用VOC2012的训练验证集和VOC2007的训练验证集、测试集(21503张图像)训练,在VOC2012测试集(10991张图像)测试。由于有了更多的训练数据,模型训练时以 学习率进行60K次迭代,再减小到 继续迭代20K次。
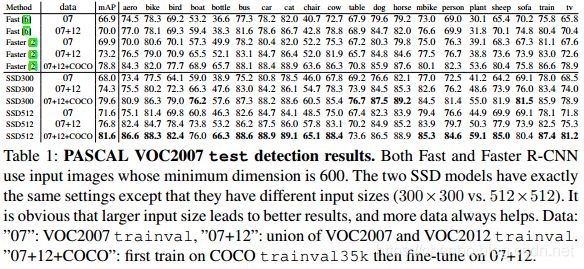
表3显示了SSD300和SSD500模型的结果。我们看到与我们在VOC2007测试中观察到的相同的性能趋势。我们的SSD300已经优于Fast R-CNN,并且非常接近Faster R-CNN(只有0.1%的差异)。通过将训练和测试图像大小增加到500×500,我们比Faster R-CNN高2.7%。与YOLO相比,SSD显著更好,可能是由于使用来自多个特征图的卷积默认框和训练期间的匹配策略。
3.4 MSCOCO
为了进一步验证SSD架构,我们在MS COCO数据集上训练了我们的SSD300和SSD500模型。由于COCO中的对象往往较小,因此我们对所有图层使用较小的默认框。我们遵循第2.2节中提到的策略,但是现在我们最小的默认框具有0.1而不是0.2的缩放比例,并且conv4_3上默认框的缩放比例是0.07(例如,对应于300×300图像的21个像素)。
我们使用trainval35k [21]来训练我们的模型。由于COCO有更多的对象类别,开始时的梯度不稳定。我们首先用8× 的学习率迭代4K次训练模型,接着以 学习率进行140K次迭代,再以 学习率迭代60K次, 学习率迭代40K次。表4显示了test-dev2015上的结果。与我们在PASCAL VOC数据集上观察到的类似,SSD300在[email protected]和mAP@[0.5:0.95]中优于Fast R-CNN,在 mAP @ [0.5:0.95]与Faster R-CNN接近。然而,[email protected]更糟,我们推测,这是因为图像尺寸太小,这阻止了模型精确定位许多小对象。通过将图像大小增加到500×500,我们的SSD500在两个标准中都优于Faster R-CNN。此外,我们的SSD500模型也比ION[21]更好,它是一个多尺寸版本的Fast R-CNN,使用循环网络显式模拟上下文。在图5中,我们展示了使用SSD500模型在MSCOCO test-dev的一些检测示例。

3.5 ILSVRC初步结果
我们将我们用于MS COCO的相同的网络架构应用于ILSVRC DET数据集[15]。我们使用ILSVRC2014 DET train和val1来训练SSD300模型,如[20]中所使用。我们首先以8× 的学习率迭代4K次训练模型,再用 学习率进行320k次迭代训练该模型,然后用 进行100k次迭代和 继续训练60k次迭代。我们可以在val2集上实现41.1mAP[20]。再一次的,它验证SSD是高质量实时检测的一般框架。
3.6 推理期间
考虑到从我们的方法生成的大量框,有必要在推理期间有效地执行非最大抑制(nms)。通过使用0.01的置信度阈值,我们可以过滤掉大多数框。然后,我们使用Thrust CUDA库进行排序,使用GPU计算所有剩余框之间的重叠,对jaccard重叠为0.45的每个类应用nms,并保存每个图像的前200个检测。对于20个VOC类别的SSD300,每个图像该步花费大约2.2毫秒,这接近在所有新添加的层上花费的总时间。
表5显示了SSD、Faster R-CNN[2]和YOLO [5]之间的比较。Faster R-CNN对region proposal使用额外的预测层,并且需要特征下采样。相比之下,我们的SSD500方法在速度和精度上优于Faster R-CNN。 值得一提的是,我们的方法SSD300是唯一的实时实现70%以上mAP的方法。 虽然快速YOLO[5]可以运行在155 FPS,但精度只有差不多20%的mAP。

4、相关工作
目前有两种已建立的用于图像中对象检测的方法,一种基于滑动窗口,另一种基于region proposal分类。在卷积神经网络出现之前,用于检测的两种方法DeformablePart Model(DPM)[22]和选择性搜索[1]性能接近。然而,在R-CNN[20]带来的显着改进之后,其结合了选择性搜索region proposal和基于卷积网络的后分类,region proposal对象检测方法变得普遍。
原始的R-CNN方法已经以各种方式进行了改进。第一组方法提高了后分类的质量和速度,因为它需要对成千上万的图像作物进行分类,这是昂贵和耗时的。SPPnet[9]对原始的R-CNN方法大大提速。它引入了空间金字塔池化层,其对区域大小和尺度更加鲁棒,并且允许分类层重用在若干图像分辨率生成的特征图特征。Fast R-CNN[6]扩展了SPPnet,使得它可以通过最小化置信度和边界框回归的损失来对所有层进行端对端微调,这在MultiBox[7]中首次引入用于学习对象。
第二组方法使用深层神经网络提高proposal生成的质量。在最近的工作中,例如MultiBox[7,8],基于低层图像特征的选择性搜索region proposal被直接从单独的深层神经网络生成的proposal所替代。这进一步提高了检测精度,但是导致了一些复杂的设置,需要训练两个神经网络及其之间的依赖。Faster R-CNN[2]通过从region proposal网络(RPN)中学习的方案替换了选择性搜索proposal,并且引入了通过微调共享卷积层和两个网络的预测层之间交替来集成RPN与Fast R-CNN的方法。用这种方式region proposal池化中层特征图,最终分类步骤更快速。我们的SSD与Faster R-CNN中的region proposal网络(RPN)非常相似,因为我们还使用固定的(默认)框来进行预测,类似于RPN中的achor框。但是,不是使用这些来池化特征和评估另一个分类器,我们同时在每个框中为每个对象类别产生一个分数。因此,我们的方法避免了将RPN与Fast R-CNN合并的复杂性,并且更容易训练,更易于集成到其他任务中。
另一组方法与我们的方法直接相关,完全跳过proposal步骤,直接预测多个类别的边界框和置信度。 OverFeat[4]是滑动窗口方法的深度版本,在知道基础对象类别的置信度之后直接从最顶层特征图的每个位置预测边界框。YOLO [5]使用整个最高层特征图来预测多个类别和边界框(这些类别共享)的置信度。我们的SSD方法属于此类别,因为我们没有提案步骤,但使用默认框。然而,我们的方法比现有方法更灵活,因为我们可以在不同尺度的多个特征图中的每个特征位置上使用不同宽高比的默认框。如果顶层特征图每个位置只使用一个默认框,我们的SSD将具有与OverFeat[4]类似的架构;如果我们使用整个顶层特征图并且添加一个全连接层用于预测而不是我们的卷积预测器,并且没有明确考虑多个宽高比,我们可以近似地再现YOLO[5]。
5、结论
本文介绍了SSD,一种用于多个类别的快速单次对象检测器。我们的模型的一个关键特点是使用多尺度卷积边界框输出附加到网络顶部的多个特征图。这种表示允许我们有效地模拟可能的框形状空间。我们实验验证,给定适当的训练策略,更大量的仔细选择的默认边界框得到了性能的提高。我们建立SSD模型,与现有方法相比,至少相差一个数量级的框预测位置,规模和纵横比[2,5,7]。
我们证明,给定相同的VGG-16基础架构,SSD在精度和速度方面胜过最先进的对象检测器。我们的SSD500型号在PASCAL VOC和MS COCO的精度方面明显优于最先进的Faster R-CNN [2],速度快了3倍。 我们的实时SSD300模型运行在58 FPS,这比当前的实时YOLO[5]更快,同时有显著高质量的检测。
除了它的独立实用程序,我们相信,我们的完整和相对简单的SSD模型为使用对象检测组件的大型系统提供了一个伟大的组成块。一个有希望的未来方向,是探索其作为使用循环神经网络的系统一部分,用以检测和跟踪视频中对象。
6、致谢
这个项目是在谷歌开始的实习项目,并在UNC继续。 我们要感谢亚历克斯·托舍夫有用的讨论,并感谢谷歌的Image Understanding和DistBelief团队。 我们也感谢菲利普·阿米拉托和帕特里克·波尔森有益的意见。我们感谢NVIDIA提供K40 GPU并感谢NSF 1452851的支持。

部分pytorch程序:
class SSD(nn.Module):
"""Single Shot Multibox Architecture
The network is composed of a base VGG network followed by the
added multibox conv layers. Each multibox layer branches into
1) conv2d for class conf scores
2) conv2d for localization predictions
3) associated priorbox layer to produce default bounding
boxes specific to the layer's feature map size.
SSD模型由去掉全连接层的vgg网络为基础组成。在之后添加了多盒转化层。
每个多盒层分支是:
1)conv2d 获取分类置信度
2)conv2d进行坐标位置预测
3)相关层去产生特定于该层特征图大小的默认的预测框bounding boxes
See: https://arxiv.org/pdf/1512.02325.pdf for more details.
Args:
phase: (string) Can be "test" or "train"
size: input image size 输入的图像尺寸
base: VGG16 layers for input, size of either 300 or 500 没有全连接层的vgg网络
extras: extra layers that feed to multibox loc and conf layers
提供多盒定位的格外层 和 分类置信层(vgg网络后面新增的额外层)
head: "multibox head" consists of loc and conf conv layers
由定位和分类卷积层组成的multibox head
(loc_layers, conf_layers) 类似特征金字塔 不同层的特征图进行分类和回归
"""
def __init__(self, phase, size, base, extras, head, num_classes):
super(SSD, self).__init__()
self.phase = phase
self.num_classes = num_classes
self.cfg = (coco, voc)[num_classes == 21]
# 对于每个feature map,生成预测框(中心坐标及偏移量)
self.priorbox = PriorBox(self.cfg)
# 调用forward,返回生成的预测框结果
self.priors = Variable(self.priorbox.forward(), volatile=True)
self.size = size
# SSD network
# vgg网络
self.vgg = nn.ModuleList(base)
# Layer learns to scale the l2 normalized features from conv4_3
# Layer层从conv4_3学习去缩放l2正则化特征
self.L2Norm = L2Norm(512, 20)
# 新增层
self.extras = nn.ModuleList(extras)
self.loc = nn.ModuleList(head[0])
self.conf = nn.ModuleList(head[1])
if phase == 'test':
self.softmax = nn.Softmax(dim=-1)
self.detect = Detect(num_classes, 0, 200, 0.01, 0.45)
def forward(self, x):
"""Applies network layers and ops on input image(s) x.
前向传播
Args:
x: input image or batch of images. Shape: [batch,3,300,300].
Return:
Depending on phase:
test:
Variable(tensor) of output class label predictions,
confidence score, and corresponding location predictions for
each object detected. Shape: [batch,topk,7]
train:
list of concat outputs from:
1: 分类层confidence layers, Shape: [batch*num_priors,num_classes]
2: 回归定位层localization layers, Shape: [batch,num_priors*4]
3: priorbox layers, Shape: [2,num_priors*4]
"""
# sources保存 不同feature map结果,以便使用这些feature map来进行预测
sources = list()
# 保存不同feature map回归和分类的结果
loc = list()
conf = list()
# 原论文中vgg的conv4_3,relu之后加入Normalization正则化,然后保存feature map
# apply vgg up to conv4_3 relu
# 将vgg层的feature map保存
for k in range(23):
x = self.vgg[k](x)
s = self.L2Norm(x)
sources.append(s)
# apply vgg up to fc7
for k in range(23, len(self.vgg)):
x = self.vgg[k](x)
sources.append(x)
# apply extra layers and cache source layer outputs
# 将新增层的feature map保存
for k, v in enumerate(self.extras):
# 每经过一个conv卷积,都relu一下
x = F.relu(v(x), inplace=True)
# 隔一个conv保存一个结果
if k % 2 == 1:
sources.append(x)
# apply multibox head to source layers
# permute 将tensor的维度换位 参数为换位顺序
#contiguous 返回一个内存连续的有相同数据的tensor
for (x, l, c) in zip(sources, self.loc, self.conf):
loc.append(l(x).permute(0, 2, 3, 1).contiguous())
conf.append(c(x).permute(0, 2, 3, 1).contiguous())
# 在给定维度上对输入的张量序列seq 进行连接操作 dimension=1表示在列上连接
loc = torch.cat([o.view(o.size(0), -1) for o in loc], 1)
conf = torch.cat([o.view(o.size(0), -1) for o in conf], 1)
# 测试集上的输出
if self.phase == "test":
output = self.detect(
loc.view(loc.size(0), -1, 4), # loc preds 定位的预测
self.softmax(conf.view(conf.size(0), -1,
self.num_classes)), # conf preds 分类的预测
self.priors.type(type(x.data)) # default boxes 预测框
)
else:
# 训练集上的输出
output = (
loc.view(loc.size(0), -1, 4), # loc preds [32,8732,4] 通过网络输出的定位的预测
conf.view(conf.size(0), -1, self.num_classes), #conf preds [32,8732,21] 通过网络输出的分类的预测
self.priors # 不同feature map根据公式生成的框结果 [8732,4]
)
return output
def load_weights(self, base_file):
other, ext = os.path.splitext(base_file)
if ext == '.pkl' or '.pth':
print('Loading weights into state dict...')
self.load_state_dict(torch.load(base_file,
map_location=lambda storage, loc: storage))
print('Finished!')
else:
print('Sorry only .pth and .pkl files supported.')
# This function is derived from torchvision VGG make_layers()
# 此方法源自torchvision VGG make_layers()
# https://github.com/pytorch/vision/blob/master/torchvision/models/vgg.py
def vgg(cfg, i, batch_norm=False):
'''
vgg的结构
cfg: vgg的结构
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
i: 3 输入图像通道数
batch_norm False
返回没有全连接层的vgg网络
'''
layers = []
in_channels = i
for v in cfg:
if v == 'M': #最大池化层 默认floor模式
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
elif v == 'C': #最大池化层 ceil模式 两种不同的maxpool方式 参考https://blog.csdn.net/GZHermit/article/details/79351803
layers += [nn.MaxPool2d(kernel_size=2, stride=2, ceil_mode=True)]
else:
# 卷积
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
pool5 = nn.MaxPool2d(kernel_size=3, stride=1, padding=1)
conv6 = nn.Conv2d(512, 1024, kernel_size=3, padding=6, dilation=6)
conv7 = nn.Conv2d(1024, 1024, kernel_size=1)
layers += [pool5, conv6,
nn.ReLU(inplace=True), conv7, nn.ReLU(inplace=True)]
return layers
def add_extras(cfg, i, batch_norm=False):
'''
vgg网络后面新增的额外层
:param cfg: '300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
:param i: 1024 输入通道数
:param batch_norm: flase
:return:
'''
# Extra layers added to VGG for feature scaling
layers = []
in_channels = i
flag = False #控制卷积核尺寸,一维数组选前一个数还是后一个数。在每次循环时flag都改变,导致网络的卷积核尺寸为1,3,1,3交替
# enumerate枚举 k为下标 v为值
for k, v in enumerate(cfg):
if in_channels != 'S':
if v == 'S':
layers += [nn.Conv2d(in_channels, cfg[k + 1],
kernel_size=(1, 3)[flag], stride=2, padding=1)]
else:
layers += [nn.Conv2d(in_channels, v, kernel_size=(1, 3)[flag])]
flag = not flag
in_channels = v
return layers
def multibox(vgg, extra_layers, cfg, num_classes):
'''
:param vgg: 没有全连接层的vgg网络
:param extra_layers: vgg网络后面新增的额外层
:param cfg: '300': [4, 6, 6, 6, 4, 4], 不同部分的feature map上一个网格预测多少框
:param num_classes: 20分类+1背景,共21类
:return:
'''
loc_layers = []
conf_layers = []
vgg_source = [21, -2]
for k, v in enumerate(vgg_source):
loc_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(vgg[v].out_channels,
cfg[k] * num_classes, kernel_size=3, padding=1)]
# [x::y] 从下标x开始,每隔y取值
for k, v in enumerate(extra_layers[1::2], 2):
loc_layers += [nn.Conv2d(v.out_channels, cfg[k]
* 4, kernel_size=3, padding=1)]
conf_layers += [nn.Conv2d(v.out_channels, cfg[k]
* num_classes, kernel_size=3, padding=1)]
#vgg 没有全连接层的vgg网络
# extra_layers vgg网络后面新增的额外层
# head_ :(loc_layers, conf_layers) 类似特征金字塔 不同层的特征图进行分类和回归
return vgg, extra_layers, (loc_layers, conf_layers)
base = {
'300': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'C', 512, 512, 512, 'M',
512, 512, 512],
'512': [],
}
extras = {
'300': [256, 'S', 512, 128, 'S', 256, 128, 256, 128, 256],
'512': [],
}
mbox = {
'300': [4, 6, 6, 6, 4, 4], # number of boxes per feature map location 不同部分的feature map上一个网格预测多少框
'512': [],
}
def build_ssd(phase, size=300, num_classes=21):
'''
新建SSD模型
'''
# 训练或测试
if phase != "test" and phase != "train":
print("ERROR: Phase: " + phase + " not recognized")
return
#当前SSD300只支持大小300×300的数据集训练
if size != 300:
print("ERROR: You specified size " + repr(size) + ". However, " +
"currently only SSD300 (size=300) is supported!")
return
#base_: vgg 没有全连接层的vgg网络
#extras_: extra_layers vgg网络后面新增的额外层
# head_ : (loc_layers, conf_layers) 类似特征金字塔 不同层的特征图进行分类和回归
base_, extras_, head_ = multibox(vgg(base[str(size)], 3),
add_extras(extras[str(size)], 1024),
mbox[str(size)], num_classes)
return SSD(phase, size, base_, extras_, head_, num_classes)