独家解读 | 基于优化的对抗攻击:CW攻击的原理详解与代码解读

论文标题:Towards Evaluating the Robustness of Neural Networks
论文链接:https://arxiv.org/abs/1709.03842
作者:孙裕道
1. 引言
对抗攻击的方式主要分为三大类,第一种是基于梯度迭代的攻击方式比如FGSM,PGD,MIM;第二种是基于GAN 的攻击方式,比如AdvGAN,AdvGAN++,AdvFaces。还有一种攻击方式为基于优化的攻击方式,它的代表就是本文CW的攻击。CW攻击产生的对抗样本所加入的扰动,几乎是人眼察觉不出来的,反观,FGSM和PGD生成的对抗样本所生成的扰动比较糊,而且CW的攻击效果更加好,在加有蒸馏防御的分类模型中,CW攻击依然可以高效地攻击成功。
2. 论文的贡献
本文的贡献可以归结如下三点:
作者针对 , 和 三种距离度量引入到CW的攻击方式中。这三种度量方式的引入使得在较小的扰动下能够有较高的攻击准确率。
模型蒸馏是对抗样本的有效的防御手段,CW攻击可以攻破防御性蒸馏中模型,高置信度的使模型出现误分类。
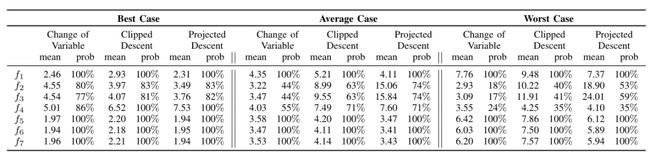
作者一共提出了7个优化目标,并系统地评估了目标函数的选择,目标函数的选择可以显著地影响攻击的效果,实验显示论文中的优化目标函数(6)是所有优化目标中效果最好的
3. 模型介绍
3.1 核心思想
CW是一种基于优化的攻击方式,它同时兼顾高攻击准去率和低对抗扰动的两个方面,达到真正意义上对抗样本的效果,即在模型分类出错的情况下,人眼不可查觉(FGSM,PGD攻击生成的图片非常模糊,人眼可以察觉到)。首先对抗样本需要用优化的参数来表示,其次在优化的过程中,需要达到两个目标,目标1 是对抗样本和对应的干净样本应该差距越小越好;目标2是对抗样本应该使得模型分类错,且错的那一类的概率越高越好。
3.2 原始形式
CW攻击依赖于对抗样本的初始优化形式,图像x寻找对抗样本的问题正式定义如下:
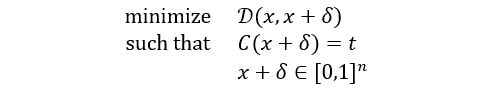
其中图像x是固定的,目标是找到最小化目标函数 δ 的对抗扰动 δ 。生成对抗样本核心是寻找对抗扰动,对抗扰动使得模型C 出现误分类。D是一些距离度量函数,它要么是 , ,要么是 。
3.3 目标函数
现有算法很难直接求解上述公式,因为约束 δ 是高度非线性的。因此,需要用更适合于优化的不同形式来表示它。作者定义了一系列的目标函数 ,使得 δ 时当且仅当 δ 。其中 有许多可能的选择分别如下:
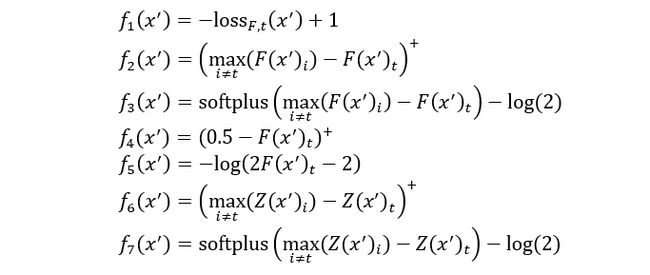 其中 是正确的分类, 是 的简写, , 是 的交叉熵损失。作者通过添加常量来调整上面的一些公式,目的是为了使函数符合论文中的定义。这样就可以将原始形式转换成可求解的新的优化形式如下:
其中 是正确的分类, 是 的简写, , 是 的交叉熵损失。作者通过添加常量来调整上面的一些公式,目的是为了使函数符合论文中的定义。这样就可以将原始形式转换成可求解的新的优化形式如下:
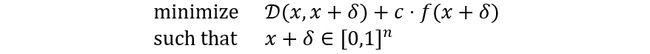
其中 是一个适当选择的常数。公式中的第一项为距离表示可以换成范数的形式为:
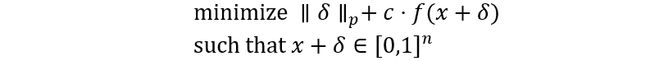
3.4 盒约束
为了保证修改得到一个有效的图像,需要对对抗扰动 δ 进行约束:其中对于所有 ,有 δ 。在本文中,引入了一个新的变量 ,用该变量来表示对抗扰动 δ ,公式为:
δ 由于 ,则有 δ 。可以认为这种方法是一种平滑的梯度下降的方法,消除了在极端区域中陷入平缓而梯度消失的问题。
3.5 攻击
给定 ,选择一个目标类 其中 ,优化的目标函数为:
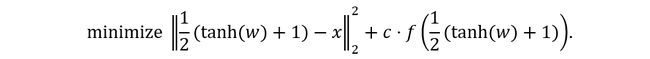
其中 的定义为:
![]()
这个 为最佳目标函数,通过调整 κ 来控制误分类发生的置信度。参数 κ 鼓励求解器找到对抗样本 ,该对抗样本将被分类为具有高可信度的 类。
3.6 攻击
距离度量不是完全可微的,标准梯度下降法也不能很好地解决这一问题。优化目标的形式为:
![]()
然而,梯度下降产生的结果很差。作者使用迭代攻击来解决这个问题,具体形式为:
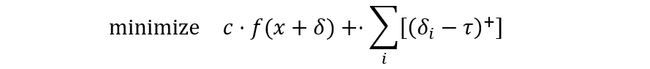
每次迭代后,对于任何的 ,有 δ τ ,作者将 τ 值减少为0.9;否则,终止搜索。
3.7 攻击
距离的度量是不可微的,因此不适合于梯度下降来优化参数。作者使用一个迭代算法,来识别出一些对分类器输出没有太大影响的像素。固定像素的集合在每次迭代中增长,该子集可以修改以生成对抗样本。计算 δ (目标函数的梯度),然后通过 δ 选择像素从而生成对抗样本。直观上 δ 表示的是当从干净样本转移到对抗样本上,可以从图像的第i 个像素中获得的f(⋅) 的减少量值。
4. 实验结果
下表显示的是七个目标函数对1000个随机样本进行评估的平均 偏差、标准差和成功概率(可以找到对抗样本的分数)。综合来看, 为目标函数时,在全部成功样本攻击的情况下,扰动量最小,所以本文中所用到的目标函数为 。
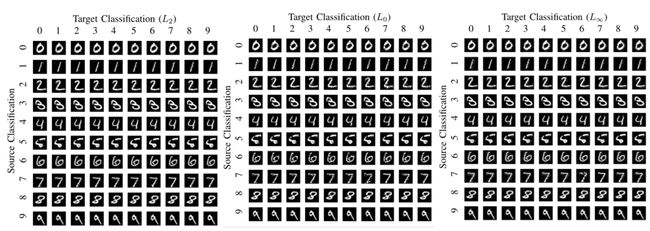
下图显示了三种范数攻击对MNIST分类模型进行的有目标攻击。可以发现几乎所有的攻击在视觉上都无法与原始数字区分开来。
下图为全黑图片和全白图片在MNIST分类模型中在三种范数下进行有目标攻击而生成的对应10个数字的对抗样本,可以发现在图片加的对抗扰动都非常小。
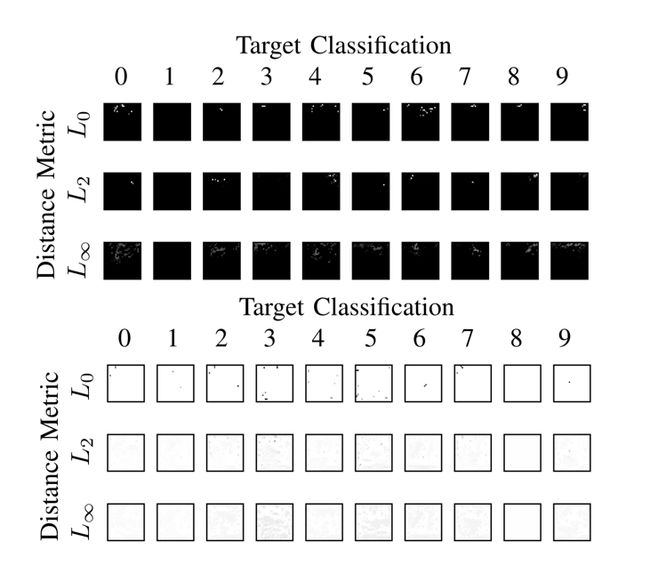
5. 总结交流
在该文中,作者引入三个不同的范数,攻击在保证高准确率攻击的前提下,加入的扰动也非常微小,以致于人眼不可察觉,而且作者直接评估安全模型的鲁棒性。相比于其它的攻击方式,CW攻击在mnist数据和ImageNet数据中攻击效果(攻击准确率和图片的结构化损失SSMI)最好,但是因为它的攻击是基于优化的方式,所以导致大量的时间消耗在参数更新上,不如其它的攻击方式来的快捷,所以在一些AI的对抗样本的竞赛上(天池对抗样本大赛),很少有用CW 攻击来生成对抗样本。
6. Reference
[1] CARLINI, N., MISHRA, P., VAIDYA, T., ZHANG, Y., SHERR, M., SHIELDS, C., WAGNER, D., AND ZHOU, W. Hidden voice commands. In 25th USENIX Security Symposium (USENIX Security 16), Austin, TX (2016).
[2] CHANDOLA, V., BANERJEE, A., AND KUMAR, V. Anomaly detection: A survey. ACM computing surveys (CSUR) 41, 3 (2009), 15.
[3] CLEVERT, D.-A., UNTERTHINER, T., AND HOCHREITER, S. Fast and accurate deep network learning by exponential linear units (ELUs). arXiv preprint arXiv:1511.07289 (2015).
[4] DAHL, G. E., STOKES, J. W., DENG, L., AND YU, D. Large-scale malware classification using random projections and neural networks. In 2013 IEEE International Conference on Acoustics, Speech and Signal Processing (2013), IEEE, pp. 3422–3426.
[5] DENG, J., DONG, W., SOCHER, R., LI, L.-J., LI, K., AND FEI-FEI, L. Imagenet: A large-scale hierarchical image database. In Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on (2009), IEEE, pp. 248–25
7. 代码解读
7.1 对抗样本库介绍
torchattacks是一个非常不错轻量级的对抗样本库,调用API方法很简单,本文中要解读的CW代码,就来自于torchattacks库中的源码。库中经典的对抗攻击方法有FGSM,BIM,RFGSM,CW,PGD,DeepFool等。下载命令:pip install torchattacks。
7.2 CW代码解读
CW攻击是一种优化方法,所以涉及到参数的训练。如下图所示,CW 类包含两个方法,一个是超参数的初始化,另一个是参数训练生成对抗样本。
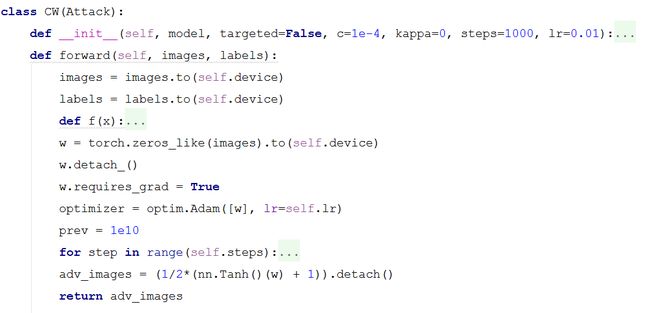
如下图源代码所示,__init__(self,model,targeted,c,kappa,steps,lr)为CW 攻击的超参数初始化,具体的参数如下:
model(nn.Module):待攻击的分类模型。
target(bool):对抗攻击的类型,分为有目标攻击和无目标攻击。
c(float):论文中目标函数 约束的超参数。
kappa(float):kappa参数为对抗攻击的置信度。
steps(int):steps为优化参数生成对抗样本的迭代次数。
lr(float):lr为优化器学习的学习率。

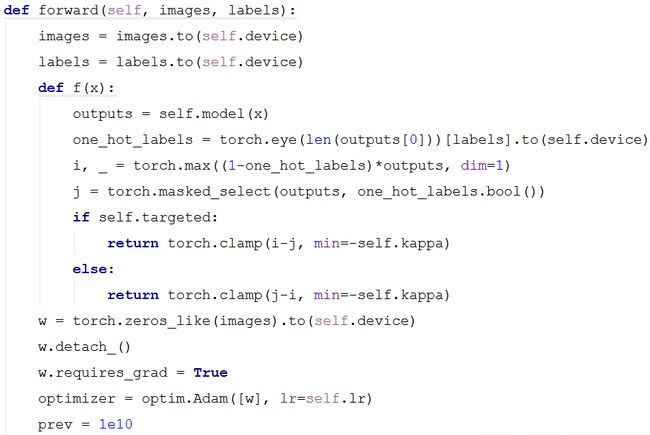
如下图源代码所示,源码中forward(self, images, labels)函数的功能是训练参数从而生成对抗样本,接受的参数为图片和标签,类型为torch.tensor。
images = images.to(self.device):将图片数据存放到cuda 中。
labels = labels.to(self.device):将标签数据存放到cuda 中。
源码中的 函数为论文中的提出的目标函数中第二项为
κ
其中, 表示的是分类模型输出的概率向量中第i类的概率分量。
outputs = self.model(x):表示模型输出的分类概率向量。
torch.eye(len(outputs[0]))[labels].to(self.device):表示真实的标签的one-hot编码的torch.tensor。
torch.max((1-one_hot_labels)*outputs, dim=1):表示分类模型输出的概率向量中第二大的分量的概率值。
torch.masked_select(outputs, one_hot_labels.bool()):表示分类模型输出的概率向量中最大的分量概率值。
torch.clamp(i-j, min=-self.kappa):表示最大概率分量和第二大概率分量的差值。
optimizer = optim.Adam([w], lr=self.lr):定义更新w参数的Adam 优化器。
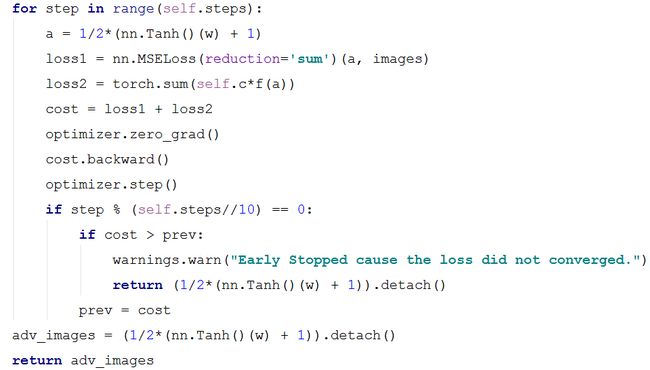
如下图源代码所示,为优化器优化参数的迭代过程,并且最终生成对抗样本。
a = 1/2*(nn.Tanh()(w) + 1):表示论文中的盒约束,并且公式为 ,其中a是由参数w表示的是对抗样本。
loss1 = nn.MSELoss(reduction=’sum’)(a, images):表示优化目标函数的第一项损失函数。
loss2 = torch.sum(self.c*f(a)):表示优化目标函数的第二项损失函数。
cost = loss1 + loss2:表示优化目标函数的损失函数。
adv_images = (1/2*(nn.Tanh()(w) + 1)).detach():表示最终生成的对抗样本。

中国人工智能大会


历史文章推荐
太牛逼了!一位中国博士把整个CNN都给可视化了,每个细节看的清清楚楚!
Nature发表牛津博士建议:我希望在读博士之初时就能知道的20件事
沈向洋、华刚:读科研论文的三个层次、四个阶段与十个问题
如何看待2021年秋招算法岗灰飞烟灭?
独家解读 | ExprGAN:基于强度可控的表情编辑
独家解读 | 矩阵视角下的BP算法
独家解读 | Capsule Network深度解读
独家解读 | Fisher信息度量下的对抗攻击
论文解读 | 知识图谱最新研究综述
你的毕业论文过了吗?《如何撰写毕业论文?》
卡尔曼滤波系列——经典卡尔曼滤波推导
一代传奇 SIFT 算法 专利到期!
人体姿态估计的过去,现在,未来
2018-2019年度 Top10 综述
给研究新生的建议,光看论文是学不好的,一定要看书,看书,看书!
分享、点赞、在看,给个三连击呗!