卷积神经网络处理MNIST数据集原理总结
卷积神经网络与MNIST数据集
- 相关学习链接在文中或文末放置
- 本文是在学习《数据挖掘》时,自学了解卷积神经网络的情况下,初学者查阅资料的总结
- 希望共同学习,提出建议,必虚心接受。
1.卷积神经网络是什么?
卷积神经网络是一种前馈神经网络,可以通过反向传播算法来优化结构,求解未知参数,常用于处理大型图片,包括卷积层和池化层。
一般有以下几步完成:
- 卷积层初步划分特征
- 池化层对卷积层的特征进行提取主要特征
- 全连接对于所有特征进行整合
- 产生分类器对图片进行测试与预测
在理解卷积神经网络的过程之前,需要明白:
机器对图片的识别过程:
对于一张图片,是由许多的像素点形成的,像素点里的数字代表颜色码,颜色码范围是[0,255],这样就构成了一个存储数字的矩阵,而机器在识别这张图片的过程,是将矩阵不断分割成小部分,将每一个小部分中的特征进行提取,最终汇总在一起,进行预测的。
2.mnist数据集:
这是:MNIST数据集的官方网站
MNIST手写数字数据库的训练集为60,000个示例,而测试集为10,000个示例。它是NIST可提供的更大集合的子集。这些数字已进行尺寸规格化,并在固定尺寸的图像中居中存储。
也可以参考一下:
这里-> MNIST 入门 | TensorFlow 官方文档中文版
关于tensor,即张量的理解,可以看这个,个人觉着有所受益:https://www.cnblogs.com/xiaoboge/p/9681229.html
图片数据将被解压成2维的tensor:[image index, pixel index] 其中每一项表示某一图片中特定像素的强度值, 范围从 [0, 255] 到 [-0.5, 0.5]。 "image index"代表数据集中图片的编号, 从0到数据集的上限值。"pixel index"代表该图片中像素点得个数, 从0到图片的像素上限值。
以train-*开头的文件中包括60000个样本,其中分割出55000个样本作为训练集,其余的5000个样本作为验证集。因为所有数据集中28x28像素的灰度图片的尺寸为784,所以训练集输出的tensor格式为[55000, 784]。
数字标签数据被解压称1维的tensor: [image index],它定义了每个样本数值的类别分类。对于训练集的标签来说,这个数据规模就是:[55000]。
卷积神经网络
1.卷积层:
原理:
以mnist数据集的图片为例:一张28*28,通道为1的图片(RGB的图片为3通道,黑白的为1)
定义一个卷积核,(卷积核相当于权重,也可以是filter,即过滤器等),其作用是才能够图像中提取一定的特征,卷积核与图片对应的数字矩阵进行一一相乘得到卷积层输出结果:
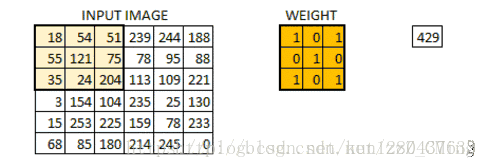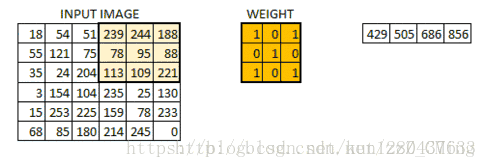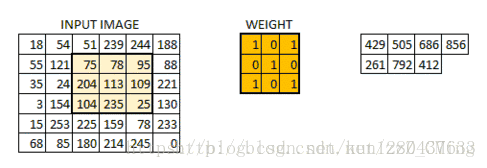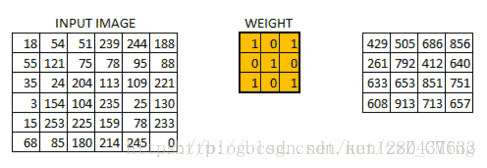
图片来源:https://blog.csdn.net/kun1280437633/article/details/80817129
卷积层的取值(也就是中间的这个filter可由函数随机生成,并逐步训练调整生成)
在这个过程中,涉及到一些知识点:
所有的像素点都会被这一过程覆盖到,最终生成卷积层的输出结果,图中滑动的正是filter,尺寸为3*3
通过这种过程,可以使得卷积层逐步得出层次越来越高的特征,图片的特征是经过不断压缩得到的,最终得出的特征有助于分类。
而机器通过不同的卷积核进行相互作用最后得出的卷积层输出结果,判断卷积核的取值,通过相互作用得出的最终结果的数值大小可以进行判断,比如:



图片来源于:https://blog.csdn.net/kun1280437633/article/details/80817129
图一中的卷积核,描述了一段曲线,用它来作用到图二中老鼠的屁股上的一段,可以明显看到,最终得出的数值大小与卷积核和图片相似度大的关系。
卷积层最终结果是得出更加能够表现图片特征的卷积核并得出输出结果(数值矩阵)。
相关计算与知识点:
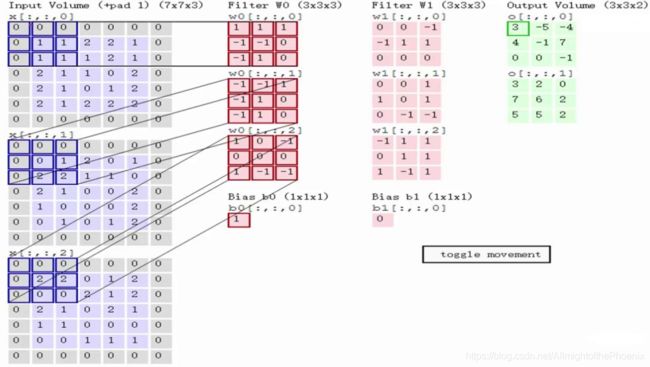

图片来源于:https://blog.csdn.net/weixin_42451919/article/details/81381294
- 卷积核在图片上的移动距离,即步长(stride),步长越小,明显可以看到,特征能够覆盖的越全面,所以得到的特征也就越多,但是效率就会越低,虽然如此,步长也不能过大,不能遗漏图片上的像素点并且会改变输出图像与原图像的大小一致。
- 在filter移动的过程中,边缘像素点会被覆盖到的次数会明显少于中间像素点 ,所以在图像周围加上一圈边界0,即(pad),加多少pad,一般为了维持输出图像与原图像大小不变,会将卷积过程中的padding参数设置为=same,也就是自动填充pad。
- 图一中卷积过程后的图像大小是由图二公式得出的,一般都是与原图像相同大小的。
- 权值共享:一张图像的一个位置被相同尺寸大小的filter扫描,权重是相同的。
卷积过程中的反向传播过程并不是十分了解 ,日后学习后增加。
2.池化层
池化层的输入即卷积层的输出结果(卷积层的输入与卷积核相互作用得出的数值矩阵)
池化就是卷积层得出的图像进行特征压缩,
常见的池化层形式:
- max-padding:选取指定区域中的最大值最后集合在一起表示整片区域
- mean-padding:选取指定区域中数值的平均值最后集合在一起来表示整片区域
例如:
图中的图像尺寸为4*4,步长为2,也就是扫描过得数值将不再扫描:
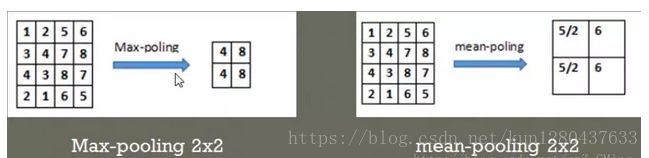
图片来源:https://blog.csdn.net/kun1280437633/article/details/80817129
3.全连接层:
卷积层与池化层的最终目的是为了提取特征并对图像进行压缩,全连接层则是为了生成分类器,完成最终输出。
将池化层的输出结果重新切割成向量,并乘上权重矩阵,加上偏置值,使用ReLU激活函数并使用梯度下降优化函数。
代码:
#http://yann.lecun.com/exdb/mnist/
# train-images-idx3-ubyte.gz #60000张训练集图片
# train-labels-idx1-ubyte.gz #60000张训练集图片对应的标签
# t10k-images-idx3-ubyte.gz #10000张测试集图片
# t10k-labels-idx1-ubyte.gz #10000张测试集图片对应的标签
#解压后得到:
# train-images-idx3-ubyte
# train-labels-idx1-ubyte
# t10k-images-idx3-ubyte
# t10k-labels-idx1-ubyte
import numpy as np
import matplotlib.pyplot as plt
# import tensorflow as tf
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import input_data
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
其中的
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
是用来代替import tensorflow as tf的,因为现在网上的一些教程大多使用的都是tensorflow1.0的版本,但是我们现在电脑里目前安装的一般都是2.0的版本。
mnist = input_data.read_data_sets("mnist_data/", one_hot=True)
input_data.py可以参考:https://blog.csdn.net/weixin_43159628/article/details/83241345
input_data.py文件是结合tensorflow用来下载并读取mnist数据集压缩包的函数,如果自己没有或者报错,需要自己在写。
# None表示张量的第一个维度可以是任意长度
input_x = tf.placeholder(tf.float32, [None, 28*28])/255 # 灰度值:0~255
output_y = tf.placeholder(tf.int32, [None, 10]) # 输出:10个数字的标签
input_x_images = tf.reshape(input_x, [-1, 28, 28, 1]) # 改变形状之后的输入
# 从测试数据集中选取3000个手写数字的图片和对应标签
test_x = mnist.test.images[:3000] # 图片
test_y = mnist.test.labels[:3000] # 标签
- 这里的input_x和output_y都是使用了占位符,等待数据传入一定的值之后进行运行
- shape=[None,784]是数据维度的大小,mnist中的图片都是28*28的大小,将二维数据转换成一维的长度为784的向量
# 构建卷积神经网络
# 第 1 层卷积
conv1 = tf.layers.conv2d(inputs=input_x_images, # 形状是[28, 28, 1]
filters=32, # 32个过滤器,输出的深度是32
kernel_size=[5, 5], # 过滤器在二维的大小是(5,5)
strides=1, # 步长是1
padding='same', # same表示输出的大小不变,因此需要在外围补0两圈
activation=tf.nn.relu # 激活函数是Relu
) # 形状[28, 28, 32]
# 第 1 层池化(亚采样)
pool1 = tf.layers.max_pooling2d(
inputs=conv1, # 形状[28, 28, 32]
pool_size=[2,2], # 过滤器在二维的大小是(2 * 2)
strides=2 # 步长是2
) # 形状[14, 14, 32]
# 第 2 层卷积
conv2 = tf.layers.conv2d(inputs=pool1, # 形状是[14, 14, 32]
filters=64, # 64个过滤器,输出的深度是64
kernel_size=[5, 5], # 过滤器在二维的大小是(5,5)
strides=1, # 步长是1
padding='same', # same表示输出的大小不变,因此需要在外围补0两圈
activation=tf.nn.relu # 激活函数是Relu
) # 形状[14, 14, 64]
# 第 2 层池化(亚采样)
pool2 = tf.layers.max_pooling2d(
inputs=conv2, # 形状[14, 14, 64]
pool_size=[2,2], # 过滤器在二维的大小是(2 * 2)
strides=2 # 步长是2
) # 形状[7, 7, 64]
layer是tensorflow的一个中层API
可以参考:https://www.w3cschool.cn/tensorflow_python/tensorflow_python-ycgz2v16.html
tf.layers.conv2d():
- filters:整数,输出空间的维数(即卷积中的滤波器数).
- kernel_size:2个整数的整数或元组/列表,指定2D卷积窗口的高度和宽度.可以是单个整数,以指定所有空间维度的相同值.
layers.max_pooling2d():
定义在:tensorflow/python/layers/pooling.py.
用于2D输入的最大池化层(例如图像)
- input
检索图层的输入张量.仅适用于图层只有一个输入的情况,即它是否连接到一个输入图层.返回:输入张量或输入张量列表. - pool_size:2个整数的整数或元组/列表:(pool_height,pool_width),用于指定池窗口的大小;可以是单个整数,以指定所有空间维度的相同值.
- strides:2个整数的整数或元组/列表,指定池操作的步幅;可以是单个整数,以指定所有空间维度的相同值.
# 平坦化(flat)
flat = tf.reshape(pool2, [-1, 7 * 7 * 64]) # 形状[7 * 7 * 64, ]
# 1024个神经元的全链接层
dense = tf.layers.dense(inputs=flat, units=1024, activation=tf.nn.relu)
# Dropout:丢弃50%,rate=0.5
dropout = tf.layers.dropout(inputs=dense, rate=0.5)
# 10个神经元的券链接层,这里不用激活函数来做非线性话了
logits = tf.layers.dense(inputs=dropout, units=10) # 输出。形状[1, 1, 10]
# 计算误差(计算Cross entropy(交叉熵),再用Softmax计算百分比概率)
loss = tf.losses.softmax_cross_entropy(onehot_labels=output_y, logits=logits)
# Adam 优化器来最小化误差,学习率0。001
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
- tf.reshape:给定tensor,这个操作返回一个张量,它与带有形状shape的tensor具有相同的值.如果shape的一个分量是特殊值-1,则计算该维度的大小,以使总大小保持不变.特别地情况为,一个[-1]维的shape变平成1维.至多能有一个shape的分量可以是-1.
- tf.layers.dropout:Dropout包括在每次更新期间随机将输入单位的分数rate设置为0,这有助于防止过度拟合(overfitting).保留的单位按比例1 / (1 - rate)进行缩放,以便在训练时间和推理时间内它们的总和不变
- tf.losses.softmax_cross_entropy:为了得到一张给定图片属于某个特定数字类的证据(evidence),我们对图片像素值进行加权求和。如果这个像素具有很强的证据说明这张图片不属于该类,那么相应的权值为负数,相反如果这个像素拥有有利的证据支持这张图片属于这个类,那么权值是正数。

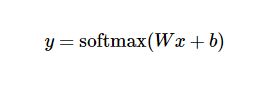
这个softmax函数可以参考文档中的讲解 - tf.train.AdamOptimizer:AdamOptimizer是TensorFlow中实现Adam算法的优化器。Adam即Adaptive Moment Estimation(自适应矩估计),是一个寻找全局最优点的优化算法,引入了二次梯度校正。Adam 算法相对于其它种类算法有一定的优越性,是比较常用的算法之一。关于Adam算法的理解
with tf.Session() as sess:
# 初始化全局和局部变量
init = tf.group(tf.global_variables_initializer(), tf.local_variables_initializer())
sess.run(init)
for i in range(20000):
batch = mnist.train.next_batch(50) # 从训练集中取下一个50个样本
train_loss, train_op_ = sess.run([loss, train_op], {input_x: batch[0], output_y: batch[1]})
if i % 100 == 0:
test_accuracy = sess.run(accuracy, {input_x: test_x, output_y: test_y})
print("Step=%d, Train loss=%.4f, [Test accuracy=%.2f]" % (i, train_loss, test_accuracy))
test_output = sess.run(logits, {input_x: test_x[:20]})
inferenced_y = np.argmax(test_output, 1)
print(inferenced_y, 'Inferenced numbers') # 推测的数字
print(np.argmax(test_y[:20], 1), 'Real numbers') # 真实的数字
mnist.train.next_batch可以从所有的训练数据中读取一小部分作为一个训练batch。
代码来源https://blog.csdn.net/zhaohaibo_/article/details/80634425
其他函数:
激活函数
激活函数(activation function)运行时激活神经网络中某一部分神经元,将激活神经元的信息输入到下一层神经网络中。神经网络之所以能处理非线性问题,这归功于激活函数的非线性表达能力。激活函数需要满足数据的输入和输出都是可微的,因为在进行反向传播的时候,需要对激活函数求导。
一些常用的激活函数如:sigmoid、tanh、relu、dropout等
例如我们经常使用的
- relu函数:
relu函数的定义:f(x)=max(x,0)
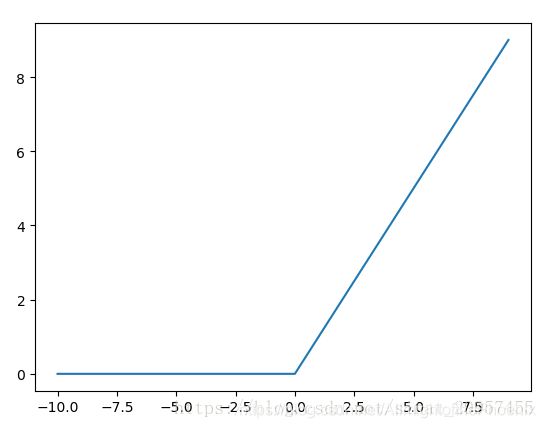
relu函数在x<0时,输出始终为0。由于x>0时,relu函数的导数为1,所以relu函数能够在x>0时保持梯度不断衰减,从而缓解梯度消失的问题,还能加快收敛速度,还能是神经网络具有稀疏性表达能力,这也是relu激活函数能够被使用在深层神经网络中的原因。由于当x<0时,relu函数的导数为0,导致对应的权重无法更新,这样的神经元被称为"神经元死亡"。
- dropout函数:
dropout函数会以一个概率为keep_prob来决定神经元是否被抑制。如果被抑制,该神经元输出为0,如果不被抑制则该神经元的输出为输入的1/keep_probbe倍,每个神经元是否会被抑制是相互独立的。神经元是否被抑制还可以通过调节noise_shape来调节,当noise_shape[i] == shape(x)[i],x中的元素是相互独立的。如果shape(x)=k,l,m,n,当noise_shape=[k,1,1,n],表示数据的个数与通道是相互独立的,但是与数据的行和列是有关联的,即要么都为0,要么都为输入的1/keep_prob倍。
本段来源:https://blog.csdn.net/sinat_29957455/article/details/81841278