(学习笔记)机器人自主导航从零开始第七步——TARE Planner自主探索算法
本文参考资料:
TARE Planner (cmu-exploration.com) https://www.cmu-exploration.com/tare-planner【泡泡前沿专栏•重磅】全网首发,CMU - LOAM 团队讲述最新自研全套开源自主导航算法(三)TARE自主探索算法 (qq.com)https://mp.weixin.qq.com/s?__biz=MzI5MTM1MTQwMw==&mid=2247525116&idx=1&sn=13bc5b107dec0908e11bf1dc1d045464&chksm=ec13dcf8db6455eed44d6361eae3615e669ec9db5c790b73e17961639c7518e44076fe9c7674&scene=178&cur_album_id=1954649120803995651#rd
https://www.cmu-exploration.com/tare-planner【泡泡前沿专栏•重磅】全网首发,CMU - LOAM 团队讲述最新自研全套开源自主导航算法(三)TARE自主探索算法 (qq.com)https://mp.weixin.qq.com/s?__biz=MzI5MTM1MTQwMw==&mid=2247525116&idx=1&sn=13bc5b107dec0908e11bf1dc1d045464&chksm=ec13dcf8db6455eed44d6361eae3615e669ec9db5c790b73e17961639c7518e44076fe9c7674&scene=178&cur_album_id=1954649120803995651#rd
前言
(以下转载自【泡泡机器人SLAM】微信公众号)
之前的文章中提到传统的探索算法大多利用Frontier作为引导,并采取贪心的策略(greedy strategy)。Frontier指的是已知地图的边界。当机器人朝着Frontier走,已知地图不断扩大,边界向外拓展,便产生了新的Frontier。由此循环往复,直到没有新的Frontier产生,意味着所有未知空间都已经被传感器覆盖,也意味着探索的完成。在二维环境中,这一方法足以应付大多数的探索问题。然而在三维环境中,由于环境遮挡和传感器本身的噪声,很容易在空间中产生很多“无效”的Frontier。这些Frontier并不能对探索起引导作用,反而容易使机器人执着于向它们移动而陷入困境。除此之外,由于计算资源的限制,大部分方法只能通过随机采样的方式在有限的范围之内生成路径。机器人每移动一段距离,算法便需要重新采样。而每次采样,算法都只能采用贪心策略来最大化短期的回报(Reward)。当算法只优化短期内的目标,比如朝着当前时刻最大的Frontier前进,机器人容易变得短视而忽略了长远的目标:使总体走过的路径最短。这样的结果是机器人容易重复走已经走过的路(如下图所示),使探索效率低下。另外,许多已有的算法需要维护一个全局的地图。这样随着机器人探索范围的扩大,算法的计算速度会因为需要维护更大的地图而变慢,最终导致机器人需要停下来等待计算结束才能继续移动。这样的时走时停更加降低了探索效率。

TARE算法
我们开源的TARE算法便旨在解决这些问题。贪心容易导致短视,一个自然的想法就是加入全局的引导。在我们的算法中,机器人最终执行的探索路径会在两个层面被优化:1. 在全局范围内,我们的算法会计算一条粗略的路径引导机器人行驶的大致方向,2. 在局部范围内,我们的算法则会寻找一条能让机器人的传感器完全覆盖局部探索区域的路线。这样在机器人探索的过程中,它行驶的路线会由于受到全局的引导而更具目的性,比如先探索完这个房间再探索下一个房间,而不是哪里的未知区域比较大就先去哪里。与此同时,粗略计算一条全局路径的所需的计算时间和资源会远远小于计算一条能完全覆盖局部区域的精细路线。这样我们能把主要的计算资源集中在距离机器人较近的空间之内,而不至于浪费在远处不确定性更大的地方。
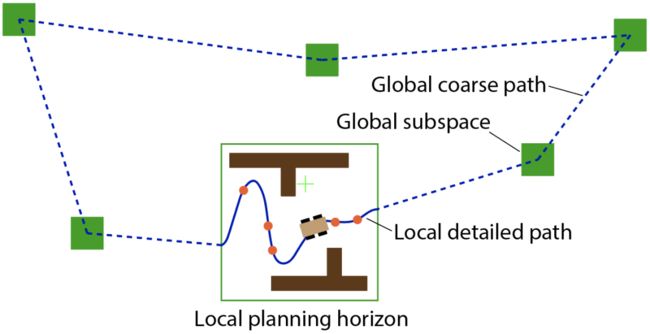
如上图所示,在一个局部区域内(绿色框),机器人会沿着一条由大量计算给出的“精细”路线行驶。而在这个区域之外,则是被一条由少量计算给出的“粗略”路径引导。
在机器人附近的局部区域之内,我们的算法会寻找一条能使传感器完全“覆盖”这一区域的最短路径。值得一提的是,与传统方法只用Frontier引导机器人探索不同,我们的算法还会使传感器最大化覆盖物体的表面(Surface Points)。这是因为我们不只希望对环境建立一个完整的地图,我们还希望保证地图的质量。当激光雷达或者相机被用于建图的时候,我们希望这样的传感器能从有限的角度和距离之内观测环境中的物体,这样才能保证传感器收集到高质量的数据,从而建出高质量的地图。我们的算法会在局部区域内通过循环采取视点(Viewpoint)的方式寻找能让传感器“看全,看好”的最短路径。如下图所示,蓝色曲线代表着这样一条轨迹。橙色圆圈表示采样得到的视点。红色的曲线代表物体表面需要被传感器“覆盖“ 的点。

由于采用了层级结构,我们的算法能在使用相似计算资源的情况下处理更大范围的环境,从而给出更接近最优解的路径。在每一个层级,我们都通过解旅行商问题(Traveling Salesman Problem)来计算路径,从而确定机器人探索目的地的先后顺序。同时,我们的算法还采用动态维护的思想来避免在环境变动不大的情况下重复计算相似的路径。在与其他前沿方法的比较当中,我们的算法既有着更高的探索效率,又有着更快的计算速度。
下面这表格中统计了五个环境中各算法的探索效率以及平均的规划时间,在所有的环境中,我们的算法都有着最高的探索效率。

下面图展示了在真机实验中各种算法的最终轨迹图,以及我们的算法最后探索完成后得到的完整地图。在实验中,只有我们的算法能将一个多层的停车场及与其相连的一个平台全部探索完。

用法
(以下翻译自TARE Planner (cmu-exploration.com))
该存储库已在Ubuntu 18.04中使用ROS Melodic和Ubuntu 20.04与ROS Noetic进行了测试。由于使用了Google OR-Tools库,该代码仅支持AMD64架构,目前无法在ARM计算机上编译。
要设置 TARE Planner,转到autonomous_exploration_development_environment文件夹下,并克隆存储库:
cd autonomous_exploration_development_environment
git clone https://github.com/caochao39/tare_planner.git在终端中,转到tare_planner文件夹并进行编译:
cd tare_planner
catkin_make要运行代码,请转到终端中的开发环境文件夹,关闭 ROS 工作区,然后启动:
cd ..
source devel/setup.sh
roslaunch vehicle_simulator system_garage.launch打开另一个终端,转到 TARE Planner 文件夹,对 ROS 工作区进行处理,然后启动:
cd autonomous_exploration_development_environment
cd tare_planner
source devel/setup.sh
roslaunch tare_planner explore_garage.launch现在,用户应该看到自主探索的实际效果:

要使用其他环境启动,请改用下面的命令行,并将下面命令中的"environment"替换为开发环境中的环境名称之一,即 'campus', 'indoor', 'garage', 'tunnel', 和 'forest'。
roslaunch vehicle_simulator system_environment.launch
roslaunch tare_planner explore_environment.launch