各类注意力机制的介绍 (Intra & Inter & Soft & Hard & Global & Local Attention)
前言
注意力机制最早出现于论文《Neural Machine Translation by Jointly Learning to Align and Translate》 中。
传统神经机器翻译(Neural Machine Translation, NMT)模型普遍采用 encoder-decoder 结构,且 encoder 和 decoder 一般为 RNN 网络(如 LSTM、GRU 等)。在这些模型中,encoder 需要将长度不固定的 source sentence 内的信息压缩成单个定长的向量(也就是最后那个 token 对应的 hidden state),然后,decoder 根据 encoder 得出的这一向量进行计算(翻译),得到一个长度也不固定的 target sentence。
这些模型的问题在于,不管 source sentence 的长度为多少,encoder 都将其编码成一个定长的向量,而定长的向量能保存的信息量总是有限的,所以,当 source sentence 较长时,定长向量是不足以概况其所有重要信息的,这势必会影响 decoder 的输出效果。
为了应对这个问题,上述论文提出了 注意力机制,通过注意力机制,decoder 在每次计算输出前都可访问 source sentence 中每个 token 对应的 hidden state,并给各个 hidden state 计算出对应的 attention weight,随后将各 hidden state 与其对应的 attention weight 的乘积再求和得来的 context vector 作为 decoder 的输入。
值得注意的是,decoder 的每个时间步都需重新计算一个 attention weight,所以每个时间步的 context vector 都不一样,这与传统方法中仅使用 source sentence 中最后一个 token 的 hidden state 作为固定的 context vector 不同,它不要求将 source sentence 编码成单个向量,这样的优点在于,decoder 在计算输出时可以有侧重地利用 source sentence 中的信息,把“注意力”放在最有利于当前正确输出的信息上。
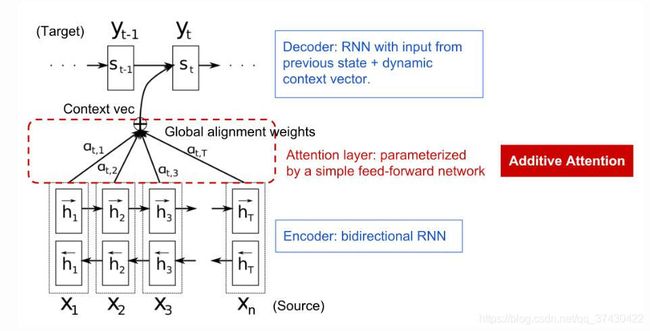
图 1:Attention (图源:Attention? Attention!)
近些年来,注意力机制在神经网络中得到了及其广泛的应用,而《Attention Is All You Need》这篇论文出现更是让其大放异彩。发展至今,注意力机制的种类也逐渐丰富。本文将简单介绍一下不同种类的注意力机制。
定义
根据 《Neural Machine Translation by Jointly Learning to Align and Translate》,注意力机制的定义如下(为了简洁,本文以源句和目标句分别代替 source sentence 和 target sentence):
给定一个长度为 n n n 的源句 x \mathbf{x} x,目标是输出一个长度为 m m m 的目标句 y \mathbf{y} y,用 h i \mathbf{h}_i hi 表示 Encoder 在各个 token 上的隐藏状态, i = 1 , … , n i = 1,\dots,n i=1,…,n.
如图 1, Decoder 在时间步 t t t 上的隐藏状态 s t = f ( s t − 1 , y t − 1 , c t ) \mathbf{s}_t = f(\mathbf{s}_{t-1},\mathbf{y}_{t-1},\mathbf{c}_t) st=f(st−1,yt−1,ct), t = 1 , … , m t = 1, \dots, m t=1,…,m.
其中, c t \mathbf{c}_t ct,名为 context vector,是源句所有隐藏状态 h i \mathbf{h}_i hi 的 加权平均,其计算方式为:
c t = ∑ i = 1 n α t , i h i α t , i = align ( y t , x i ) = exp ( score ( s t − 1 , h i ) ) ∑ j = 1 n exp ( score ( s t − 1 , h j ) ) (1) \begin{aligned} \mathbf{c}_t &= \sum_{i=1}^{n} \alpha_{t,i} \mathbf{h}_i \tag{1}\\ \alpha_{t,i} &= \text{align}(\mathbf{y}_t, \mathbf{x}_i) \\ &= \frac{\text{exp}(\text{score}(\mathbf{s}_{t-1}, \mathbf{h}_i))}{\sum_{j=1}^{n} \text{exp}(\text{score}(\mathbf{s}_{t-1}, \mathbf{h}_j))} \end{aligned} ctαt,i=i=1∑nαt,ihi=align(yt,xi)=∑j=1nexp(score(st−1,hj))exp(score(st−1,hi))(1)
以上计算 context vector 的过程就是使用注意力机制的过程,注意力权重 α t , i \alpha_{t,i} αt,i 用于衡量源句中第 i i i 个 token 与 Decoder 的第 t t t 个输出之间的 对齐程度。计算 α t , i \alpha_{t,i} αt,i 时使用了 softmax 函数,故 α t , i ∈ ( 0 , 1 ) \alpha_{t,i} \in (0,1) αt,i∈(0,1),其值越大说明 h i \mathbf{h}_i hi 对 Decoder 目前的输出越重要。
上述公式中的 score 函数可以有不同的形式,不同的 score 函数对应着不同的注意力种类,详情请看下一节。
Score Functions
借用博客 Attention? Attention! 中对各论文中出现的 score functions 的总结:

图 2:Alignment score functions (图源:Attention? Attention!)
对于 Scaled Dot-Product Attention 的由来也可查看下我的另一篇博客。
接下来的章节介绍更加宽泛的注意力种类。
Intra Attention 与 Inter Attention
Intra-attention 也称为 self-attention,其将一个句子的不同位置相互联系起来以计算该句子的特征表达,论文《Attention Is All You Need》提出的 Transformer 就是使用包含 self-attention 模块的编码器来替代 RNN 对句子进行编码的。
inter-attention 一般用于 encoder-decoder 模型结构中,其实,在本文的“定义”那一节中描述的注意力机制就属于 inter-attention,如其名,不同于 self-attention 只关注于单个句子,inter-attention 是跨越两个句子的 attention,decoder 正是通过 inter-attention 从 encoder 那选取最有利的信息。
如图 3 所示,self-attention 和 inter-attention 一样,可以使用几乎所有上一节中的 score functions,只是在 self-attention 中需要使用源句替换目标句。

图 3:Summary of broader categories of attention mechanisms (图源:Attention? Attention!)
Global Attention 与 Local Attention
Global-attention 和 local-attention 之间的分类与 intra-attention 和 inter-attention 之间的分类不相关,如一种属于 global attention 的注意力机制也可以属于 intra-attention 或 inter-attention.
根据论文 《Neural Machine Translation by Jointly Learning to Align and Translate》,global-attention 在计算 context vector 时会将源句中的所有位置的 token 都纳入考虑范围,而 local-attention 仅考虑部分位置上的 token.
那 local-attention 是如何决定哪些位置需要被考虑的呢?一种方法是,设置一个超参 m m m,对于的时间步 t t t,计算 context vector 时仅考虑源句 [ t − m , t + m ] [t - m, t + m] [t−m,t+m] 位置上的 token;在另一种方法中,对于的时间步 t t t,计算 context vector 时则考虑源句 [ p t − m , p t + m ] [p_t - m, p_t + m] [pt−m,pt+m] 位置上的 token,这里的 p t p_t pt 是通过神经网络模块计算出来的,不是固定的,并且该模块可在训练阶段得到优化。详情可查阅上述论文。
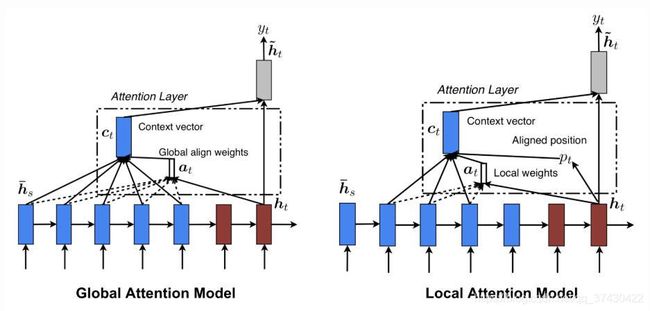
图 4:Global and local attention (图源:Attention? Attention!)
Soft Attention 与 Hard Attention
Soft-attention 与 hard-attention 提出于论文 《Show, Attend and Tell: Neural Image CaptionGeneration with Visual Attention》中。
若一注意力机制能跟随神经网络模型再梯度后向传播中得到优化的话,那么该注意力机制就属于 soft-attention,反之则属于 hard-attention.
Soft-attention 类似于 global-attention,也是会考虑所有的源信息(这里的信息指的是图像),这两种注意力机制的优点是:包含它们的模型能可微分的(说明可以通过梯度后向传播进行优化);缺点是:当源句子过长(或图像的分块数较多)时,需要大量的计算资源。
Hard-attention 和 local-attention 一样,也是仅选取部分源信息,只是 hard-attention 对部分源信息的选取方式是不可微的,所以它无法跟随模型得到优化。Local-attention 也可以说是 hard-attention 与 soft-attention 的混合产物。
总结
本文主要介绍了广泛应用于 NLP 的注意力机制,给出了粗略的定义,并讨论了不同角度下注意力机制的种类。
参考源
- Weng, Lilian. “Attention? Attention!” 2018.
- Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. “Neural machine translation by jointly learning to align and translate.” ICLR 2015.
- Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Yoshua Bengio. “Show, attend and tell: Neural image caption generation with visual attention.” ICML, 2015.
- Ashish Vaswani, et al. “Attention is all you need.” NIPS 2017.