R语言:商业数据分析实例(3)【ets指数平滑法,时间序列】
适用于初学者。内容包括ets指数平滑法模型的使用。【概念稍难,但使用和操作并不复杂】
使用到的数据:链接:https://pan.baidu.com/s/1yhzQSdquizLayXamM0wygg
提取码:3b7i
前言:指数平滑法
指数平滑又称为指数修匀,是一种重要的时间序列预测法。指数平滑法实质上是将历史数据进行加权平均作为未来时刻的预测结果。其加权系数是呈几何级数衰减,时间期数愈近的数据,权数越大,由于加权系数符合指数规律,又具有指数平滑的功能,故称为指数平滑。
指数平滑模型包括:
- 一次指数平滑法针对没有趋势和季节性的序列
- 二次指数平滑法针对有趋势但没有季节性的序列
- 三次指数平滑法针对有趋势也有季节性的序列(“Holt-Winters”有时特指三次指数平滑法)
例:一次指数平滑公式 (无趋势无季节性):
![]()
- St :第t期的预测值
- yt :第t期的实际值
- St-1:第t-1期的预测值
- a:平滑常数,其取值范围为[0,1]
若将其展开:![]()
显然,越近的实际值有越大的权重,加权系数符合指数规律。
同时,模型对于趋势和季节的影响,又分为:
- 加法模型:Y=T+S+I,认为数据的发展趋势是相互叠加的结果
- 乘法模型:Y=T*S*I,认为数据的发展趋势是相互综合的结果
【趋势(Trend),季节变化(Season),不规则波动(Irregular)】
案例简介
用到的数据共4张表(cvs格式),为2003-2019年美国纽约市房地产交易数据。
NYC_HISTORICAL包含:交易ID,社区ID,地址,建筑类型,时间,价格,面积等;
BOROUGH包含:BOROUGH_ID和BOROUG名称;
BUILDING_CLASS包含:建筑ID和建筑类型等;
NEIGHBORHOOD 包含:街道ID和BOROUGH_ID等;
本案例需要根据ID整合数据,从中提取目标信息。
本章目标
对所选社区(例中选择ID:29)的住宅房地产销售总额进行时间序列分析。
任务1:以从2009年开始的数据来开发您的模型。对未来8个季度的销售额进行预测。
- 确定使用的模型类型(加法或乘法)
- 确定模型是否考虑趋势和季节性
- 显示了未来8个季度的预测数字和置信区间。
开始:载入所需的包,并设置工作地址
library(lubridate)
library(tidyverse)
library(forecast)
setwd("C:/Users/10098/Desktop/AD571/571,A34")读取所有csv文件。第四个NYC_HISTORICAL较大(150M),且用分号隔开,故用csv2读取
BOROUGH <- read.csv("BOROUGH.csv", header=TRUE)
BUILDING_CLASS <- read.csv("BUILDING_CLASS.csv", header=TRUE)
NEIGHBORHOOD <- read.csv("NEIGHBORHOOD.csv", header=TRUE)
NYC_HISTORICAL <- read_csv2("NYC_HISTORICAL.csv") 利用year,quarter提出年份和季度(为了之后整理为时间序列)
将各表数据整合(这里处理时,删去了价格和面积为0的交易,实际操作中应根据业务需求决定)
NYC_HISTORICAL <- mutate(NYC_HISTORICAL, Y = year(SALE_DATE), Q = quarter(SALE_DATE))
NEIGHBORHOOD <- left_join(NEIGHBORHOOD,BOROUGH, by = 'BOROUGH_ID')
df <- NYC_HISTORICAL %>%
left_join(BUILDING_CLASS, by = c('BUILDING_CLASS_FINAL_ROLL' = 'BUILDING_CODE_ID')) %>%
left_join(NEIGHBORHOOD, by = 'NEIGHBORHOOD_ID') %>%
select(NEIGHBORHOOD_ID, SALE_DATE,SALE_PRICE,GROSS_SQUARE_FEET,TYPE,Y, Q) %>%
filter(NEIGHBORHOOD_ID =='29') %>%
filter(TYPE == 'RESIDENTIAL') %>%
subset(SALE_PRICE != 0) %>%
subset(GROSS_SQUARE_FEET != 0) %>%
subset(Y >= 2009) %>%
group_by(Y) %>%
na.omit() 按照年份和季度group,得到销售价格
df_2 <- df %>%
group_by(Y, Q) %>%
summarise(sum(SALE_PRICE))
将其整理为时间序列:
ts_data <- ts(df_2[,3], start=c(2009,1), end=c(2019, 4), frequency=4)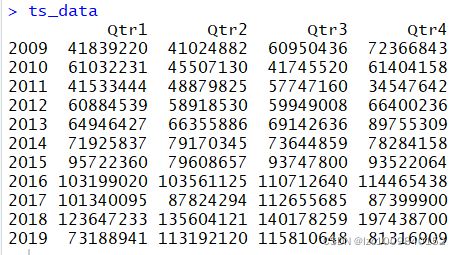
这里查看一下数据,有个基本的印象:
plot(ts_data)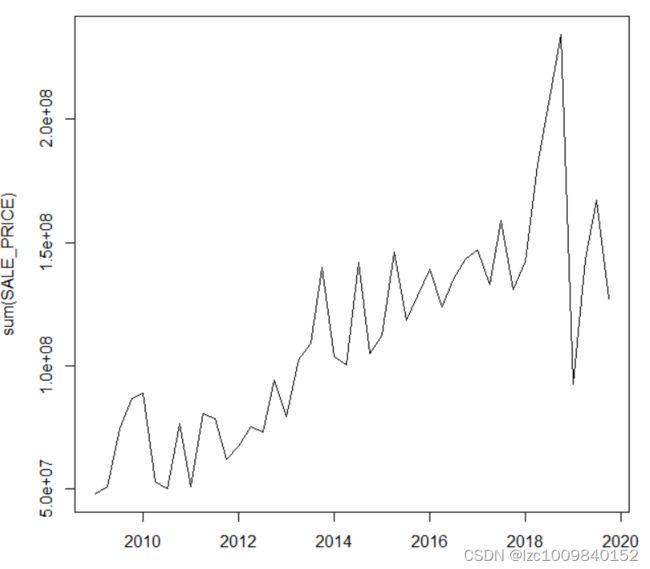
按照图,直觉上是有有趋势但没有季节性的序列。
建立指数平滑法模型,model参数输入‘zzz’,表示全部自动选择。
- 第一个字母表示误差类型(“A”、“M”或“Z”)
- 第二个字母表示趋势类型(“N”、“A”、“M”或“Z”)
- 第三个字母表示季节类型(“N”、“A”、“M”或“Z”)
“N”=无,“A”=加法,“M”=乘法,“Z”=自动选择。
例如,“ANN”是具有加性误差的简单指数平滑,“MAM”是具有乘性误差的乘性 Holt-Winters 方法
这里输入‘zzz’,全部自动选择。
model <- ets(y = ts_data, model = 'ZZZ')
summary(model)
结果显示:ETS(M,A,N),表明推荐使用‘MAN’,即具有乘性误差,加性有趋势但没有季节性
因此,使用推荐的‘MAN’,接下来预测未来8个季度:
model2 <- ets(y = ts_data, model = 'MAN')
fit <- predict(model2, 8)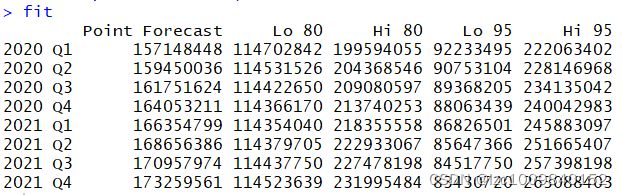
预测结果在第一列,后面几列分别是80%和95%的置信区间。
可视化一下预测结果:
plot(fit)
lines(ts_data, col = 'red')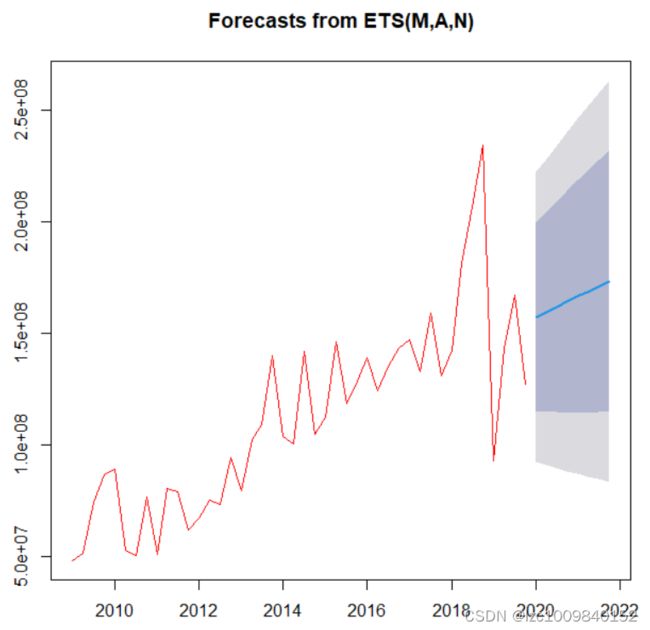
大功告成!
案例源于波士顿大学,感谢教授Tara Kelly
Reference:
指数平滑法模型理论概述 - 知乎 (zhihu.com)
时间序列分析之指数平滑法(holt-winters及代码) - 知乎 (zhihu.com)
时间序列分析预测实战之指数平滑法 - 知乎 (zhihu.com)