联合分析法(Python实现)
本文介绍联合分析法及如何用Python实现。
使用到的数据 链接:https://pan.baidu.com/s/1uOJpytFB_iHPHRG7F4-zJA
提取码:x5n4
简介:
联合分析法:是一种多元的统计分析方法,一般用于评估产品属性对消费者而言的效用大小。
基本假定:联合分析假定分析的对象如品牌、产品、商店等,是由一系列的基本特征(如:质 量、方便程度、价格)以及产品的专有特征(如电脑的 CPU 速度、硬盘容量等)所组成的;消费者的抉择过程是理性地考虑这些特征而进行的。
例如:一家手机厂商正在考虑开发新款手机,但不知道应该在哪些方面加强资金投入。因此手机厂商进行了一些调查研究。他们对附近的普通人群进行了调查,了解他们对手机的偏好。每个调查对象都随机抽取了5个可能的选项组合,并要求他们从 1 到 10 对这些选项组合进行评分。数据集中每个行对应测试的特征组合和评级。
【以下数据和字段仅示意】
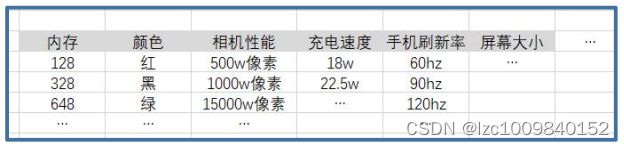
整理好数据(得到评分后):

最后经过联合分析,可得:

系数越大,评分越高。由数据可得,内存 648 和相机 15000w 像素对消费者来说最为重要(系数绝对值为1.2)【注意,系数看绝对值,负数绝对值较高的,也是重点关注的对象】
Python实现(Jupyter Notebook)
首先加载需要的包 (使用%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline读入数据
entertainment = pd.read_csv("entertainment.csv")检查是否含有空值
entertainment.isnull().values.any()查看一下数据:
entertainment结果如图:

可以查看一下数据的结构
entertainment.info()如图:
经过以上操作,我们发现,数据完整。(一般拿到的数据不会如此规整,需要自行整理,本文使用的数据已经整理好了)
接下来进行具体操作(多元线性回归,只不过我们用到的变量基本都是哑变量)
先在原数据的基础上得到哑变量(文本形式的数据可没办法回归)
df_entertainment = pd.get_dummies(entertainment, drop_first = True,
columns = ['live_science',
'live_nature',
'live_magic',
'dance_troupes',
'sing_styles',
'comedy_styles',
'show_length'])如图:
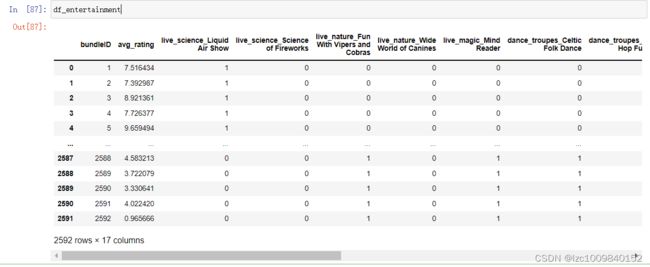
可以和上面的数据框对比一下,现在我们已经得到了想要的数据形式。
拿出X和y,进行回归吧!
X = df_entertainment[['live_science_Liquid Air Show', 'live_science_Science of Fireworks',
'live_nature_Fun With Vipers and Cobras', 'live_nature_Wide World of Canines',
'live_magic_Mind Reader',
'dance_troupes_Celtic Folk Dance', 'dance_troupes_Hip-Hop Fusion', 'dance_troupes_Salsa Vida',
'sing_styles_Italian Opera', 'sing_styles_Open Mic','sing_styles_Wiggles',
'comedy_styles_Open Mic','comedy_styles_Slapstick','show_length_20','show_length_30']]
y = df_entertainment['avg_rating']
from sklearn.linear_model import LinearRegression
from sklearn import metrics
regressor = LinearRegression()
regressor.fit(X, y)看一下我们的结果(即看系数)
coef_df = pd.DataFrame(regressor.coef_, X.columns, columns=['Coefficient'])
coef_df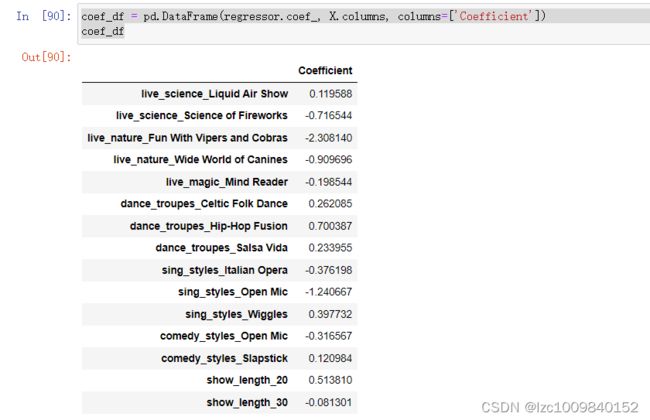
根据系数,我们可得到消费者最在乎哪些变量。
大功告成。
案例源于波士顿大学,感谢教授Page