MySQL事务、MySQL索引、MySQL索引数据结构详解
事务
DDL : 操作表,库 DCL : 授权 DML : 增删改数据 DQL : 查询
TCL : 数据库事务语言
#前期准备
CREATE TABLE account( #账户
id INT PRIMARY KEY AUTO_INCREMENT ,
username VARCHAR(32) ,
money INT
);
INSERT INTO account VALUES(NULL , ‘jack’ , ‘1000’);
INSERT INTO account VALUES(NULL , ‘rose’ , ‘1000’);
#案例:jack转账给rose 100块钱
UPDATE account SET money = money - 100 WHERE username = ‘jack’;
#程序出问题了没有能够执行到第二句 报错,宕机 死机 主板烧了 磁盘坏了
UPDATE account SET money = money + 100 WHERE username = ‘rose’;
SELECT * FROM account;
问题: 如何保证两条sql要一起执行
事务: 将多个逻辑操作合并成一个单元 , 要么全部成功 要么全部失败
事务应用场景
操作事务
经典:转账‘批量删除、批量增加、批量修改……
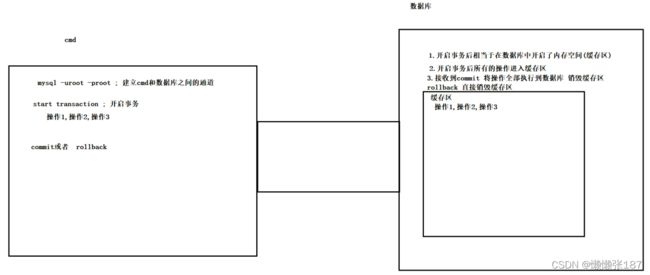
操作事务 使用cmd操作
自动
数据库有自动事务的
show variables 展示环境变量 commit 提交
SHOW VARIABLES LIKE ‘%commit%’;
#auto_commit = on 默认值 表示自动提交事务打开
#其实我们操作的每一句sql 都是有事务 而这个事务每次执行sql 自动执行 自动提交。
![]()
set autocommit = 1; 等效自动事务打开
手动
set autocommit = 0; 自动事务 关闭
使用cmd 可以进行数据库的操作 但是此时操作的是缓存 并没有提交事务
输入commit ; 提交事务 将数据的更新真正的传输给数据库
rollback 回滚 表示当前此事务失效 删除缓存
set autocommit = 0; 表示 全局变量修改了 而我们的数据库操作 可能十个操作只有一个要手动操作事务
开启一次性事务 当前事务只在当前操作有效 不能修改全局变量
start transaction; 开启一次性事务
操作…
输入commit 或者 rollback的时候 当前事务才算是结束。
事务的原理
回滚点
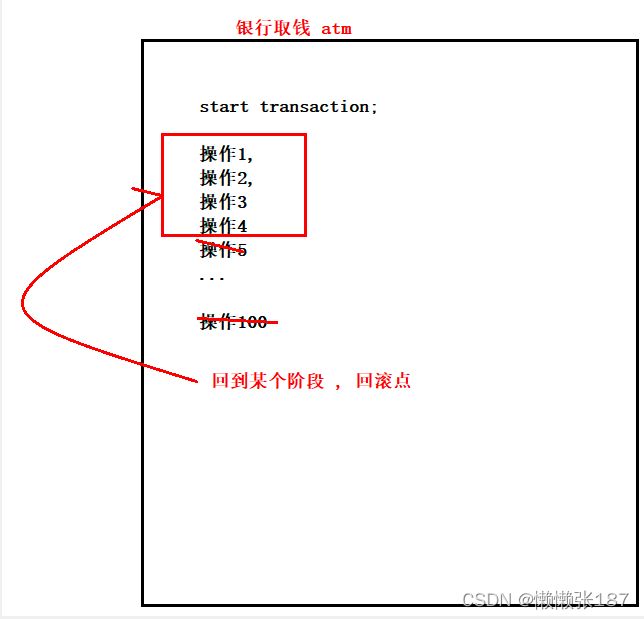
语法: savepoint 回滚点的命名
commit 全部成功 ( 当前所操作的位置 如果已经回滚到某个时间段了 那么提交的必然是这个时间段的数据)
rollback 全部失败
rollback to 回滚点的名称
事务的特性(重点)
ACID:
四大特性
A:原子性,事务是最小单位不可再分割(atomicity)
C:一致性,事务的前后保持一致(consistency)
I:隔离性,多事务之间应该产生隔离,数据之间不应该相互干扰。(isolation).
比如A正在从一张银行卡中取钱,在A取钱的过程结束前,B不能向这张卡转账。
隔离性必然产生隔离的问题(多事务之间的)
D:持久性,事务是不可逆的。(Durability)
隔离问题
(至少有2个事务以上才会有隔离问题)
1、脏读:事务A读取了事务B更新的数据,然后B回滚操作,那么A读取到的数据是脏数据
2、不可重复读:事务 A 多次读取同一数据,事务 B 在事务A多次读取的过程中,对数据作了更新并提交,导致事务A多次读取同一数据时,结果 不一致。
3、幻读:系统管理员A将数据库中所有学生的成绩从具体分数改为ABCDE等级,但是系统管理员B就在这个时候插入了一条具体分数的记录,当系统管理员A改结束后发现还有一条记录没有改过来,就好像发生了幻觉一样,这就叫幻读。
解决方案(隔离级别)
四种解决方案:
1.读未提交: read uncommitted : 不解决任何问题 (不可能用)
2.读已提交: read committed : 解决脏读问题 , 不能解决不可重复读和幻读的问题(oracle 的默认隔离级别)
3.可重复读: repeatable read : 解决脏读和不可重复读问题 , 不能解决幻读问题 (mysql 默认的隔离级别)
4.串行化: serializable :解决所有问题 只有一个事务 (不可能用)
安全级别 1< 2< 3< 4
性能角度 1>2>3>4
一般情况下使用数据库默认即可(现实开发中 追求 性能和安全并行 , 允许存在一定的误差)
MySQL索引
什么是索引
在现实生活中,我们经常去图书馆查阅图书。
现在我们将所有图书杂乱无章的摆放在一起,那么找一本书就像大海捞针一样效率非常低。
如果我们按分类整理排序后,根据类别去找对应的图书那么效率就很高了。其实这个整理排序的过程就是索引。

MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度。
索引的优势与劣势
优势
① 类似大学图书馆建书目索引,提高数据检索的效率,降低数据库的 IO 成本。
② 通过索引列对数据进行排序,降低数据排序的成本,降低 CPU 的消耗。
劣势
① 实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占用空间的
② 虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段,都会调整因为更新所带来的键值变化后的索引信息。(删除数据后 id要不要往前补充)
索引分类和语法
单列索引(给一列字段增加索引) id
组合索引(给多列字段加索引) id+name
分类
- 普通索引:仅加速查询
- 唯一索引:加速查询 + 列值唯一(可以有null) 唯一约束
- 主键索引:加速查询 + 列值唯一(不可以有null)+ 表中只有一个 , 主键约束
- 组合(联合)索引:多列值组成一个索引,注意:最左匹配原则
- 全文索引:索引类型为FULLTEXT。可以在varchar、char,text类型上创建。
创建索引
index 索引
① 直接创建(普通、唯一)
--创建主键索引
primary key 创建表的时候就有
-- 创建普通索引
create index 索引名 on 表名(列名);
-- 创建唯一索引
create unique index 索引名 on 表名(列名);
-- 创建普通组合索引
create index 索引名 on 表名(列名1,列名2....);
-- 创建唯一组合索引
create unique index 索引名 on 表名(列名1,列名2...);
##############################################################################
create table student(
id int,
username varchar(32),
age int,
primary key(id), -- 主键
unique(username), -- 唯一
index(age) -- 普通
);

修改表时指定索引
alter table 表名 add 修改表 增加..
-- 添加一个主键,这意味着索引值必须是唯一的,且不能为NULL
alter table 表名 add primary key(id);
-- 添加唯一索引(除了NULL外,NULL可能会出现多次)
alter table 表名 add unique(列名); -- 索引名就是列名
-- 添加普通索引,索引值可以出现多次。
alter table 表名 add index(列名);-- 索引名就是列名
删除索引
-- 直接删除
drop index 索引名 on 表名;
-- 修改表时删除 【掌握】
alter table 表名 drop index 索引名;
########################################################
CREATE DATABASE web04;
USE web04;
-- 创建表指定索引
CREATE TABLE student(
id INT,
username VARCHAR(32),
age INT,
PRIMARY KEY(id),
UNIQUE(username),
INDEX(age)
);
-- 删除age索引
ALTER TABLE student DROP INDEX age;
索引创建原则
1. 在经常需要 搜索 的列上建索引,这样会大大加快查找速度、
2. 在经常需要 连接(外键) 的列上建索引,可以加快连接的速度。
3. 在经常需要 排序 的列上建索引,因为索引已经是排过序的,这样一来可以利用索引的排序,加快排序查询速度。
* 注意:
那是不是在数据库表字段中尽量多建索引呢?肯定是不是的。因为索引的建立和维护都是需要耗时的
创建表时需要通过数据库去维护索引,添加记录、更新、修改时,也需要更新索引,会间接影响数据库的效率。
索引失效(重要)
-
模糊匹配查询 通配符字符串 %多个任意字符(索引注意 最左匹配原则)
% 所有 相当于整个表( 全表查询 ) 全表扫描
select * from user where username like ‘%jack123456’; -
尽量避免使用or or的条件如果没有索引 采用全表扫描 (如果要使用 or 多个条件必须有都有索引)
select * from user where username like ‘jack123456%’ or password=‘e10adc3949ba59abbe56e057f20f883e’; -
在有索引的列上进行计算会导致索引失效
select * from user where id + 1 =123456; -
使用is null 或者is not null 导致索引失效
select * from user where username is not null; -
使用!= 或者 <> 导致索引失效
select * from user where id != 1; -
尽量不使用not in语法
select * from user where id not in (1,2,3); -
尽量省略隐式或者显示类型转换
使用cast函数可以将数据强转类型 . 数据库本身是存在 数据库自动类型强转
select * from user where username =12345;
索引的数据结构
介绍
我们知道索引是为了帮助MySQL高效获取排好序的数据结构
索引=排序后的数据结构
为什么使用索引以后我们查询的效率会快很多呢?
我们知道在没有索引的情况下我们执行一条sql语句,那么是表进行全局遍历,磁盘寻址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。
select * from user where col1=6;
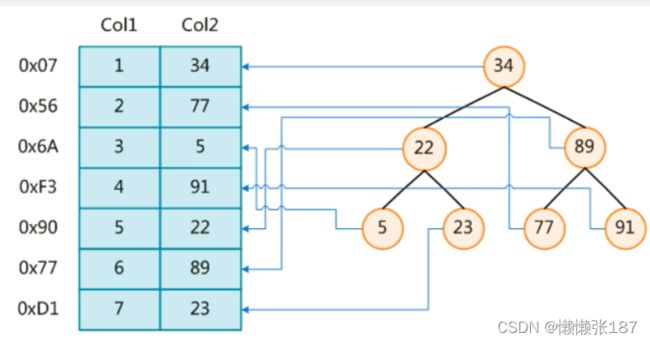
为了加快的查找效率,可以维护一个上图右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找快速获取到相应数据。
select * from user where col2=89;
索引数据结构
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html 数据结构的网站
数组
链表
- 二叉树 左边子节点比父节点小,右边子节点比父节点大 每一个父节点有两个子节点
- 红黑树(平衡二叉树) 左旋和右旋实现自平衡, 数据添加-> 平衡左右两边的节点
- B-Tree (多路搜索平衡树) : 完全二叉树 , 实现整体树的自平衡 减少树的高度
- B+Tree【MySQL使用】
- Hash 散列: 查询速度 I(O) 无延迟 , hash(hash碰撞) key是唯一的, 只能根据key获得value 解决不了范围查询的问题
- JDK1.7 (数组+链表)
- JDK1.8 (数组+红黑树) 如果链表长度《=8
叶子节点 : 最后一层子节点 数据存储在叶子节点
非叶子节点: 中间 存储是索引+指针
MySQL中的B+Tree
MySQL数据库默认一次读取一页的大小(4个磁盘块) mysql 默认将一级节点加载到内存
一般来说 超过千万级数据 采取分库分表。
-- 查看mysql索引节点大小
show global status like 'innodb_page_size';
MySQL中的 B+Tree 索引结构示意图:
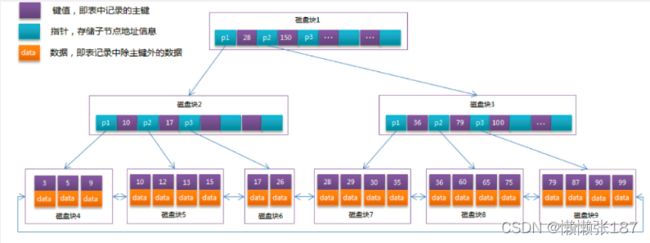
数据库的存储引擎
MySQL存储引擎的不同,那么索引文件保存的方式也有所不同,常见的有二种存储引擎MyISAM和InnoDB。
MyISAM
5.5之后的mysql 默认使用的都是 InnonDB引擎
MySQL5.5版本之前默认的存储引擎,不支持事务
CREATE TABLE myisam_tab(
id INT,
username VARCHAR(32)
)ENGINE = MYISAM;
它的索引文件和数据文件是分离的(非聚簇索引)

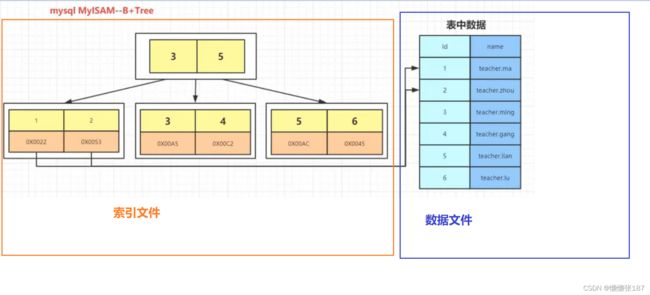
InnoDB
MySQL5.5版本之后默认的存储引擎,支持事务
CREATE TABLE innodb_tab(
id INT,
username VARCHAR(32)
)ENGINE = INNODB;
它的索引和数据在同一个文件中(聚簇索引)

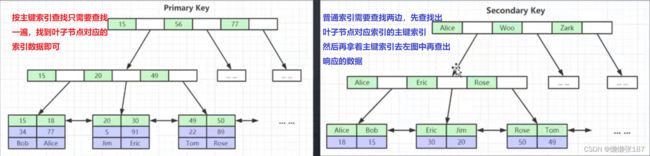
MyISAM和InnoDB的区别
- MyISM索引类型是非聚簇索引InnoDB为聚簇索引
- MyISAM不支持事务InnoDB支持事务
- MyISAM支持表锁InnoDB也支持
- MyISAM不支持行锁InnoDB支持
- MyISAM不支持外键InnoDB支持
- 二者都支持全文索引
- MyISAM查询效率更快,InnoDB增删改效率更高