论文速读系列五:SASA、BtcDet、CG-SSD、Multi-view framework、Ret3D
以下内容是对专栏:https://www.zhihu.com/column/c_1370398704629858304的笔记记录
文章目录
- 1. SASA
- 2. BtcDet
- 3. CG-SSD
- 4. Multi-view framework
- 5. Ret3D
1. SASA
paper:《SASA: Semantics-Augmented Set Abstraction for Point-based 3D Object Detection》(2022AAAI)
结构图:
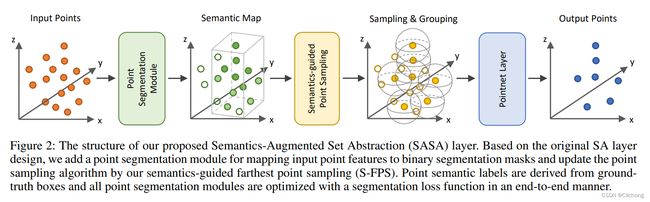
动机:
一般而言,SA模块先选择keypoints,再根据每个keypoints的周围点编码context representations。然而,在选择keypoints时,现有的采样策略通常以距离作为标准(如D-FPS、F-FPS),来选择较远的点来尽可能覆盖整个场景,但是这样会导致keypoints包含过多的背景点,从而导致pedestrian等点云数较少的object漏检。
通过引入point-wise语义信息,避免SA模块选择较多的背景点,提出了S-FPS采样策略。
思路:
1)基于已有的backbone,得到输入点云坐标X和特征F;
2)将特征F输入分割模块,得到每个点云的前景分割得分P;
3)利用点云坐标X和分割得分P,利用S-FPS采样K个keypoints。这里的是计算公式为: d i ^ = p i γ ⋅ d i \hat{d_i} = p_i^γ·d_i di^=piγ⋅di
4)对于每一个关键点,利用PointNet++提取高维特征,再将keypoints坐标和高维特征输入后续检测头,进行检测等任务。
具体的算法流程如下所示:

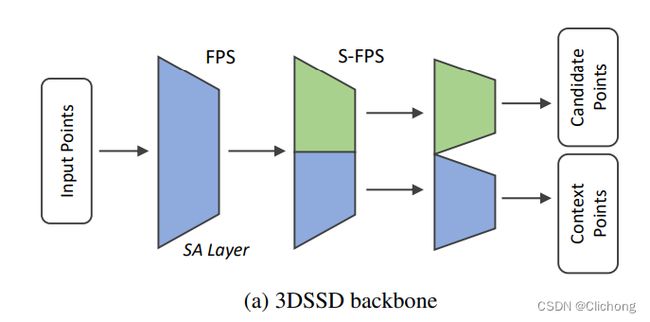
相比与D-FPS,这里的S-FPS其实本质是就是对距离进行分割置信度加权计算。将S-FPS移植在One-Stage上的思路大题与3D-SSD思路一致的,也是同时利用了两个采用方法。只不过是将F-FPS替换成了这里的S-FPS。对比3DSSD,将F-FPS换成S-FPS,在kitti数据集的moderate上获得2.3%的提升。
2. BtcDet
paper:《Behind the Curtain: Learning Occluded Shapes for 3D Object Detection》(2022AAAI)
结构图:
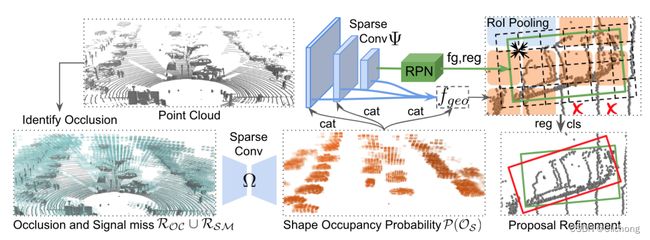
动机:
点云检测中存在遮挡问题,大致分为:1)外部遮挡;2)信号缺失;3)自我遮挡。遮挡问题会影响检测精度,为此作者希望通过对目标补全缺失形状信息来解决遮挡问题。
思路:预测RoI的形状占有率(shape occupancy OS ),将其整合到点云特征中再进行目标检测。
1)BtcDet 首先确定遮挡区域 R_{OC} 和信号缺失区域R_{SM} ,再通过shape occupancy 网络Ω 估计RoI的形状占有率 P(O_S) ;
2)BtcDet 再通过backbone提取点云特征,然后将上述估计的形状占有率 P(O_S) 与点云特征相连,送到RPN生成proposals;
3)利用局部几何特征 f_{geo} 与grid特征进行refinement。
BtcDet在kitti的精度上还不错,算是前列了。

3. CG-SSD
paper:《G-SSD: Corner Guided Single Stage 3D Object Detection from LiDAR Point Cloud》(2022ACM)
结构图:
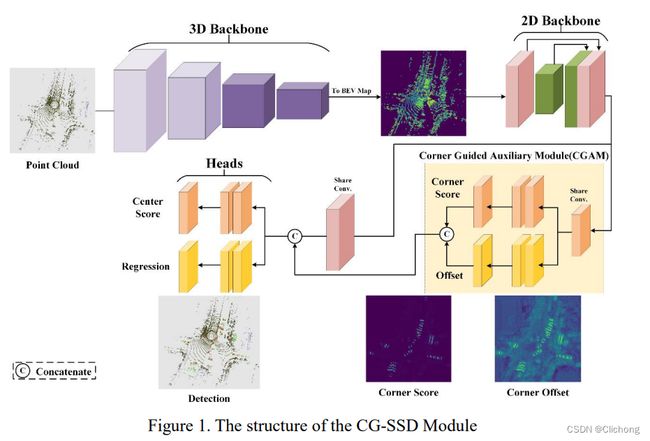
动机:
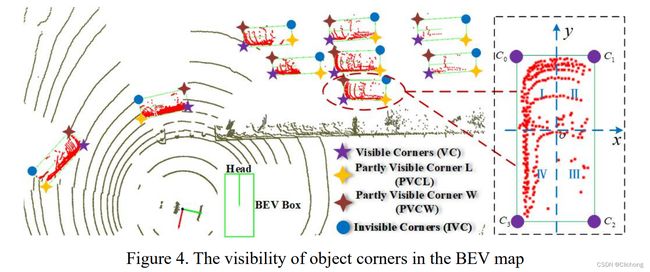
对于3D目标检测任务,目标中心点实际不存在点云数据,因此通过中心点来预测必然存在损失。相反,corner points 可以提供目标边界和尺寸信息。因此作者提出在BEV视图上,基于corner point(包括可见点和不可见点)预测目标bbox。corner附近存在很多目标点云,则corner的预测会相对准确。
思路:
1)voxelization(将点云分到规则的3D体素中) —> 3D feature learning(3D稀疏卷积提取特征) —> 2D feature learning(将3D体素特征投影到BEV视图,再进一步提取BEV特征)—> CGAM(利用辅助网络,提取corner points特征,cat到BEV特征上) —> detection head(分类和回归)
2)作者对corner point进一步细分,包括:visible corner(VC)、partly visible corner(PVCL、PVCW)和invisible corner(IVC)。首先,建立一个局部坐标系,将点云划分到4个象限,计算每个象限内点云的数量;对应点数最多的象限的点云为visible corner;与visible corner相对应象限的点为invisible corner;其他象限的点云为 partly visible corner。
3)这这里的CGAM模块会进行Classificatio loss以及Offset loss的计算。最终,score map(来自CGAN的classification task)、regression map(来自CGAM的regression task)以及BEV特征相连,一起送到detection head预测目标bbox。
paper长达27页,对于各个部分的结构讲述得非常详细了。在ONCE/Waymo数据集上进行测试,优于CenterPoint、PV-RCNN、PointPillars等算法。但是没有和一些新的SOTA算法比较。
4. Multi-view framework
paper:《A VERSATILE MULTI-VIEW FRAMEWORK FOR LIDAR-BASED3D OBJECT DETECTION WITH GUIDANCE FROM PANOPTICSEGMENTATION》(2022CVPR)
结构图:
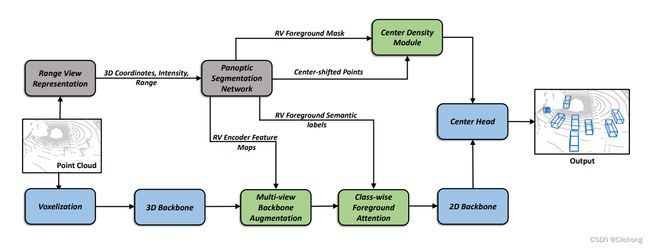
动机:
利用全景分割作为辅助任务来指导BEV检测网络学习。同时,不同视角(view)均存在缺点,这里设置多视图融合充分利用不同view信息的优势,来提升检测性能。体现联合训练带来的性能提升。
思路:
1)目标检测框架采用CenterPoint,利用CPSeg框架进行全景分割与目标检测减小联合训练。将panoptic segmentation encoder的RV feature augment到检测网络的backbone中。
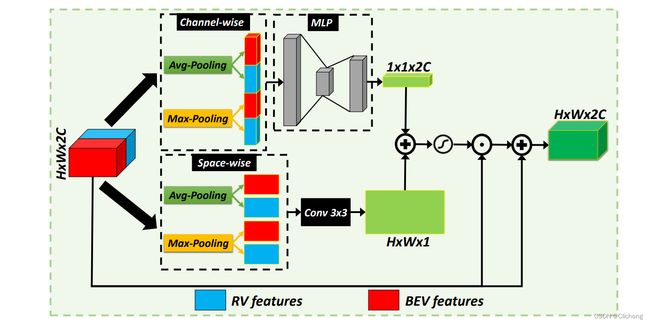
2)Attention-based RV-BEV Feature Weighting Module:类似CABM的attention机制,再通过channel attention + space attention的方式,weighting不同feature的重要性,融合RV-BEV feature。
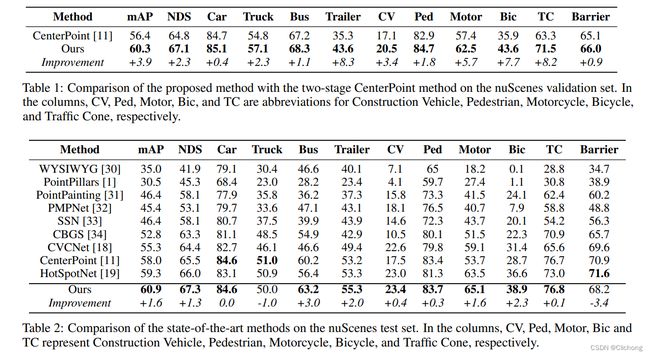
实验思路:
在某个算法baseline上测试,再与一些经典sota进行对比。随后再移植到一些其他的检点算法上查看效果进行消融实验。
5. Ret3D
paper:《Ret3D: Rethinking Object Relations for Efficient 3D Object Detection in Driving Scenes》(2022TPAMI)
结构图:
动机:
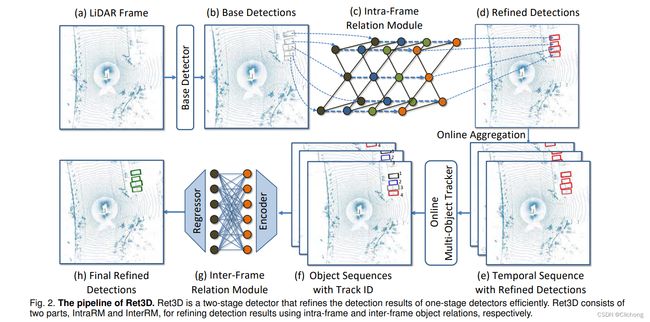
在2D目标检测中,有很多工作证明过目标间的关联性可以提升检测性能。同理,作者认为,在3D目标检测中,目标间的关联性也可以提升检测性能。然而,现有的lidar-based检测器却鲜有探索目标间的关联性,大多数检测器都是在特征层面隐式的研究目标关联性带来的影响。提出了作者研究2种关联性对3D目标检测的影响:intra-frame relations 和 inter-frame relations。
- intra-frame:对于同一帧点云,利用不同目标间的空间距离(预测的目标位置信息)作为先验知识,建立不同目标间的是sparse graph network,以避免冗余的计算;
- inter-frame:对于不同帧点云的同一目标,引入transformer,通过tracked sequences,建立相同目标、不同帧下特征间的关联性。
思路:
1)One-stage base detector:已有的一阶段3D检测器(SECOND和CenterPoint)。输入点云 P — 转化为voxel — 特征提取,得到map-view features B — 得到初步检测结果 D (包括目标中心位置、尺寸、朝向和速度,定义为basic features) + croped features O (依据目标位置从 B croped);
2)IntraRM:根据目标位置和base detector提取的特征,搭建sparse graph network,建立同一帧内、不同目标间的关联性,对特征进行refine;
3)InterRM:根据不同帧(之前的点云)得到的相同目标的特征,利用transformer建立不同帧之间、相同目标的关联性;
实验:
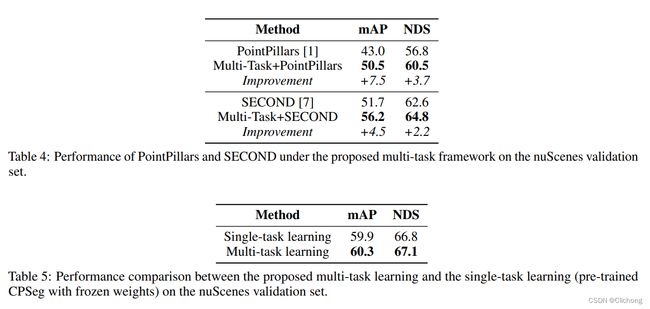
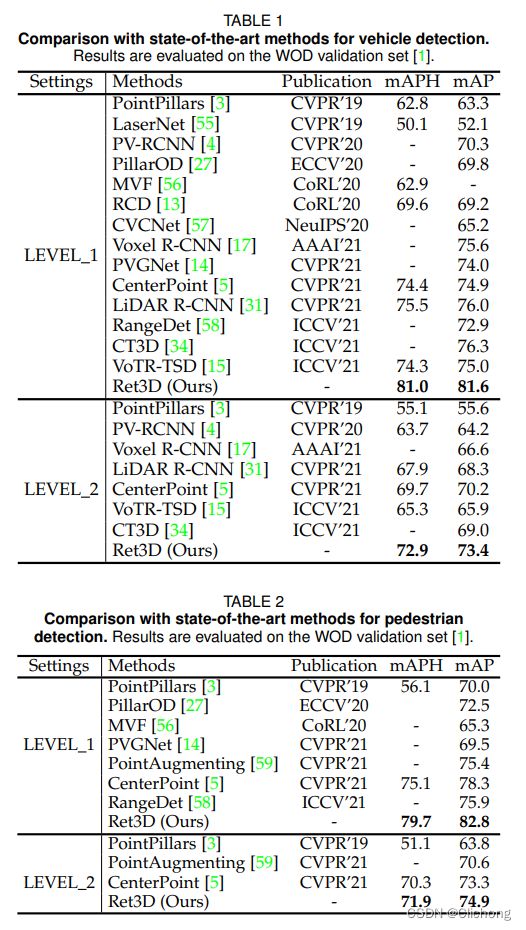
Ret3D选用SECOND和centerpoint作为baseline,在waymod数据集上进行训练和测试,取得了极大的性能提升(6+%)
参考资料:
1. 知乎专栏:3D检测与分割