TACL 2022 | GAL:合成文本在自然语言处理任务中的应用

©PaperWeekly 原创 · 作者 | 何玄黎
单位 | 伦敦大学学院(UCL)
研究方向 | 自然语言处理

论文标题:
Generate, Annotate, and Learn: NLP with Synthetic Text
收录会议:
TACL 2022
论文链接:
https://arxiv.org/abs/2106.06168
博客链接:
https://synthetic-text.github.io/

研究背景
未标记文本数据在自然语言处理任务上发挥着极其重要的作用。首先,预训练语言模型的成功主要归功于大量的未标注文本数据。其次,如果我们手上有大量任务相关的未标记数据,我们就可以利用这些数据来提升自训练(self-training)和知识蒸馏 (knowledge distillation)的效果。
但是在某一个指定任务上,未标注的数据通常是难以获取。该问题在某些自然语言处理任务上尤为突出,比如,文本相似度判断(text similarity),自然语言推断任务(natural language inference)。因为此类任务需要对一组文本之间的关系进行判别,所以它们的数据格式相较于单文本分类问题更为复杂。因此,很难采用传统信息检索的方式从互联网上获得此类任务的未标注数据。
此前的一些工作研究发现,通过微调 GPT2,即可生成一些任务相关的带标注合成文本(labelled synthetic text)。这些合成的标注数据可以提升常识推理 (Yang et al. 2020)和小样本文本分类任务 (Kumar et al. 2020)的性能。Ravuri et al. (2019)发现,即使带标注合成图片的质量在自动化评价指标上已经很接近真实的图片,但是和没用使用任何合成图片的图片分类模型比较,使用带标注合成图片的模型的准确度反而降低了。
同时,Kumar et al.(2020)也发现,带标注合成文本的语义信息和标注存在不一致的现象。除此以外,不少同期工作(Yang et al. 2020,Vu et al. 2021)也发现,合成数据可以大大提升各类自然语言处理任务的性能。但是这些方法都涉及到较为复杂的数据工程,比如,数据过滤,标注数据重标注等等。
鉴于以上问题,我们提出一套更简洁和通用的框架:generate, annotate and learn(GAL)。我们的实验结果显示,GAL 可以显著提升知识蒸馏,自训练和小样本学习在文本任务上的性能,并且在 GLUE benchmark 的知识蒸馏赛道上可以打败最先进的基线方法。

模型介绍
2.1 未标注合成文本在自训练和知识蒸馏的应用
如图 1 所示,我们首先对任意 BERT-family 模型在指定的下游任务上进行微调,即可得到一个老师模型。接下来,我们拿掉下游数据的标签,然后在 GPT2 上对这些去标签的数据进行微调,从而得到一个专注特定任务的文本生成器。于是,我们就可以使用该文本生成器产生大量的未标注合成文本。最后我们就可以用老师模型,原始的标注数据和未标注合成文本来进行自训练和知识蒸馏。
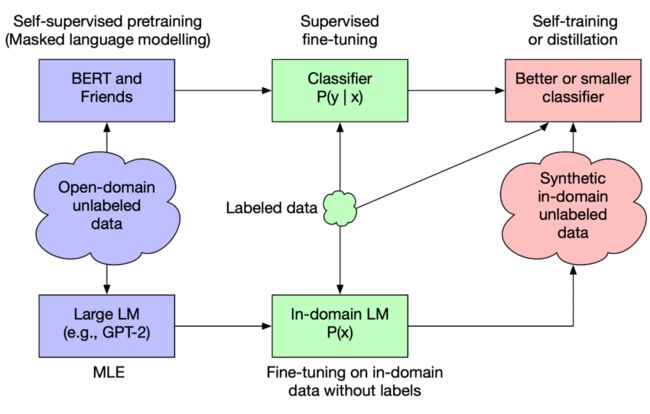
▲ 图1. GAL在自训练和知识蒸馏机制下的概览
2.2 合成文本在基于提示的小样本学习的应用
鉴于其媲美传统监督学习的效果,基于提示的小样本学习(prompt-based few-shot learning)收获了大量的关注 (Brown et al. 2020)。因此,我们也把目光转向如何使用合成文本来提升基于提示的小样本学习的性能。
如图2所示,对于某一个指定的下游任务,我们首先将 K 个标记的文本数据放在一起,从而组成一个提示语。然后将该提示语作为输入提供给大语言模型,并让其生成一条合成文本及其对应的标签。我们重复此操作 N 次,即可得到 N 条标记的合成文本。最后,我们将 K 个原始的标记文本数据和 N 个合成的标记文本数据组成新的提示语,并将此提示语用于小样本学习。
▲ 图2. GAL在基于提示的小样本学习下的概览

实验结果
3.1 知识蒸馏
对于知识蒸馏,我们使用 GLUE benchmark 来验证 GAL 的性能。我们使用 RoBERTa-large 和 DistilRoBERTa 分别作为老师模型和学生模型。如表 1 所示,相较于只使用原有训练数据的知识蒸馏方法,包括 BERT-Theseus(Xu et al., 2020),BERT-PKD(Sun et al., 2019),tinyBERT(Jiao et al., 2019))和 DistilRoBERTa + KD(standard KD),GAL 在所有的任务上,都存在显著的性能提升。
为了验证使用专注特定任务的文本生成器的功效,我们同时将 GAL 和其他数据增强的方法对比。相较于 MATE-KD(Rashid et al., 2021),DistilRoBERTa + WS(word substitution)以及 DistilRoBERTa + RT(round-trip translation),在使用同样数量的未标注合成文本的情况下,GAL 在 GLUE benchmark 的平均性能上也是大幅领先此类数据增强的方法,并在 GLUE benchmark leaderboard 上取得 6 层模型的最好成绩。
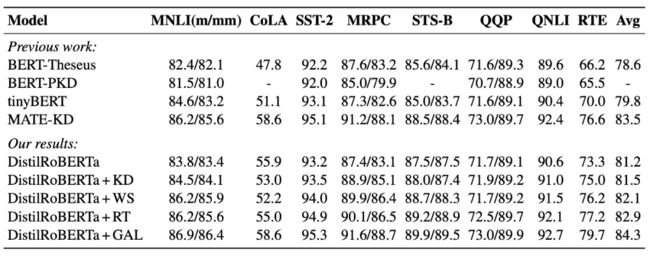
3.1 知识蒸馏
我们同样使用 GLUE benchmark 来验证 GAL 在自训练方法上的性能。自训练的老师模型和学生模型均为 RoBERTa-large。如表 2 所示,首先,相较于 RoBERTa-large,GAL 在各项任务上均有一定层度的性能提升。但是相较于其他更好的预训练模型,GAL 的性能还有待进一步提升。同时 GAL 对于其他预训练模型的帮助还有待进一步验证。
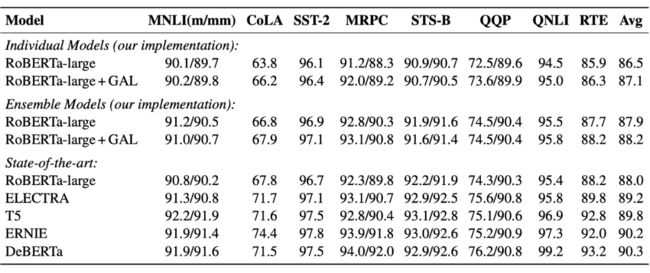
▲ 表2. 自训练机制下的GAL和其他预训练基线方法的比较
3.3 基于提示的小样本学习
鉴于计算资源的限制,在基于提示的小样本学习上,我们采用 GPT-J 来验证 GAL 的性能。K 和 N 分别为 4 和 12。如表 3 所示,虽然对比使用原始数据的 16-shot,GAL 依然存在性能上的差距。但是相较于 4-shot 和 8-shot,使用合成数据后,GAL 可以有效提升 4-shot 的性能,使其可以超越 8-shot 的性能,并且大幅度弥补了 4-shot 和 16-shot 之间的差距。
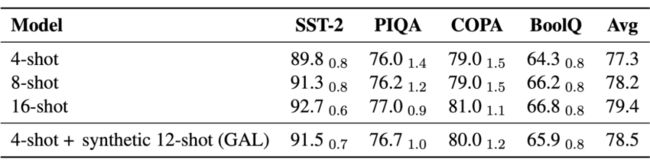
▲ 表3. GAL在基于提示的小样本学习下,同4-shot, 8-shot和16-shot基线方法的比较
3.4 未标注合成文本和标注合成文本的对比
如前文所述,标注合成数据存在一些缺陷。为了验证使用未标注合成文本的益处,我们将其与标注合成文本进行比较。如表 4 所示,在自训练的场景下,GAL(未标注合成文本)在多个下游任务上的性能都远超标注合成文本。同时如果我们拿掉标注合成文本的标签,并使用 GAL 重新标注。
此时,标注合成文本的性能和 GAL 基本一致。因此我们认为,合成文本在生成时是否标注不是一个重要的影响因素。只要我们使用老师模型对合成文本进行标注,即可获益于自训练机制。另外我们也对此现象进行了理论分析,感兴趣的读者可以查看原文了解细节。

▲ 表4. 基线和不同合成文本生成模式的比较。标签依赖的语言模型(Class-conditional LM)生成的合成文本是带有标注的,无依赖的语言模型(Unconditional LM)生成的合成文本是不带有标注的。GAL指代我们使用老师模型对合成文本进行标注。

结论
本文提出了一种新的框架:GAL,即通过生成大量和任务相关的合成文本,从而提升多种机器学习方法的性能,包括知识蒸馏, 自训练和基于提示的小样本学习。

参考文献
[1] Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. 2019. Tinybert: Distilling bert for natural language understanding
[2] Suman Ravuri and Oriol Vinyals. 2019. Classification accuracy score for conditional generative models. Advances in Neural Information Processing Systems
[3] Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter
[4] Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. 2019. Patient knowledge distillation for bert model compression. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing
[5] Varun Kumar, Ashutosh Choudhary, and Eunah Cho. 2020. Data augmentation using pretrained transformer models
[6] Yiben Yang, Chaitanya Malaviya, Jared Fernandez, Swabha Swayamdipta, Ronan Le Bras, JiPing Wang, Chandra Bhagavatula, Yejin Choi, and Doug Downey. 2020. G-daug: Generative data augmentation for commonsense reasoning
[7] Canwen Xu, Wangchunshu Zhou, Tao Ge, Furu Wei, and Ming Zhou. 2020. Bert-of-theseus: Compressing bert by progressive module replacing. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing
[8] Ahmad Rashid, Vasileios Lioutas, and Mehdi Rezagholizadeh. 2021. Mate-kd: Masked adversarial text, a companion to knowledge distillation
[9] Tu Vu, Minh-Thang Luong, Quoc Le, Grady Simon, and Mohit Iyyer. 2021. Strata: Selftraining with task augmentation for better fewshot learning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing,
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
投稿通道:
• 投稿邮箱:[email protected]
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
