抓住训练集中真正有用的样本,提升模型整体性能!
点击下面卡片,关注我呀,每天给你送来AI技术干货!
文 | Severus
编 | 小戏来自 | 夕小瑶的卖萌屋
在任务中寻找到真正有用的训练样本,可以说一直是机器学习研究者们共同的诉求。毕竟,找到了真正有用的训练样本,排除掉训练样本中的杂质,无论最终是提升训练模型的效率,还是提升了模型最终的测试性能,其意义都是非凡的。因此,相似的研究早在我们还要做特征工程的时期就已经层出不穷。
而到了 DNN 时代,在做任务的我们不需要人工特征工程了,DNN 模型直接用表示学习把“特征”安排的明明白白,数据就成了黑盒。不过,DNN 模型虽不可解释,但 DNN 模型的结果一定反映了数据的现象,所以充分利用DNN模型训练过程中的中间结果,也是可以得到有效的数据上的反映的,所谓“原汤化原食”的确是行之有效的思路。
今天要介绍的两篇工作,则是以上述思路出发,从两个不同的角度去提升模型的性能。[1]通过模型的中间结果,寻找出训练集中真正重要的样本,给模型训练,从而做到删减数据集之后,也能得到很好的测试精度;[2]通过反复训练模型表现很差的那一部分样本,从而提升模型的整体测试效果。
开局少一半数据,咱也依然能赢!
论文题目:
Deep Learning on a Data Diet: Finding Important Examples Early in Training
论文链接:
https://arxiv.org/abs/2107.07075
2018 年,Toneva et al.[3]从“遗忘”的角度去研究了数据的重要性。文中定义了“遗忘事件”,即在训练中某一个时刻,更新参数前原本预测正确的样本在更新参数后预测错误了,即认为发生了一次遗忘。作者据此定义了样本的“遗忘分数”,用于量化样本是否容易被遗忘。
由此,作者发现,一些很少被遗忘的样本对最终测试精度的影响也很小,反倒是容易被遗忘的那些样本会影响最终的评测效果。而通过这种方式,我们自然也能够通过遗忘分数去删减数据集,即留下那些容易被遗忘的数据,去掉那些不容易被遗忘的数据。
而由于这个方法需要在训练中收集到遗忘的统计数据,最终的遗忘分数往往需要在训练中后期计算完成。文章在 CIFAR-10 数据集上训练了 200 个 epoch,在第 25 个 epoch 的时候开始得到比较好的遗忘分数,第 75 个 epoch 开始遗忘分数趋于稳定。
本文作者希望,在训练早期,就可以确认数据的重要性,这样既可以大幅度减少模型训练时间和计算资源消耗,也可以对DNN模型的训练过程,及数据起到的作用等提供重要的见解。
同样,本文也想要找到训练集中“重要”的数据,这里对“重要”的定义是:训练样本对 Loss 减少的贡献,也就是说,在训练过程中,利用这个样本优化模型参数之后,其他样本计算得到的 Loss 减少的量。这个定义非常直观反映了这条样本的泛化能力,通过拟合这一条样本,模型能够从中得到多少帮助其拟合其他样本的信息。
那么,很直观的想法就是,直接求取一条样本计算得到的梯度的范数。由于现在 DNN 模型都是用梯度下降方法更新参数的,那么这个值可以直接反映出该条样本对模型参数权重的影响程度,这个影响程度我们就可以看作它对模型拟合其他样本的影响程度了。
样本重要程度的定义
在训练的 时刻,样本 的重要程度(GraNd)为:
其中,,也就是该时刻,样本 的 Loss 的梯度。
下面我们从数学角度论证一下:
在 时刻,Minibatch 中的样本 计算得到 Loss 的导数为:
根据链式法则,则:
而 是 时刻权重的变化,则有
而由于模型权重是由梯度下降更新的,则有:
从而,
那么实际上,我们需要理解,当从 中删除一条训练样本时,会怎样影响权重的变化?
设 ,对于所有样本 ,存在一个常数 ,使得:
证明:根据上面的式子,导出,代入,则令 ,结果成立。
当然这个式子在推导过程中是有不严谨的地方,例如代入等式之后,公因数是不能提取的,所以 值实际有问题,但不等式成立,这部分在撰写时尊重原作者。
训练样本的贡献由上式限定下来,由于常数 不受具体样本 影响,则只需要看样本的 Loss 的梯度的范数即可,也就是 GraNd 分数。(3)式表明,GraNd 分数较小的样本对模型区分其余样本的的影响是有限的,那么就可以根据训练样本 GraNd 分数的排名,去裁剪样本,越高的分数表明样本对 的影响越大。
对于任意输入 ,设 ,表示第 k 个 Logit 的梯度,根据链式法则,则 GraNd 分数可以写成如下形式:
当使用交叉熵loss时,有
当 与 Logits 之间大体正交,且与 Logits 和训练样本 之间有相似的大小时,则 GraNd 可以通过“错误向量”的范数近似计算。
此处定义训练样本 的 EL2N 分数(即错误向量)为 。
而实际上,作者也将本文给出的两种计算样本重要度的分数 GraNd 和 EL2N 与[3]的遗忘分数进行了比较,分析得出遗忘分数较高的样本,GraNd 分数也会较高,这样看来,二者所选择的重要样本其实也是类似的。
实验效果
在确定了计算重要程度的方法之后,作者直接在训练早期,分别计算遗忘分数、GraNd 及 EL2N ,然后利用计算的结果删减了数据集,之后训练模型,测试结果如下:

数据集和模型如上。其中,CIFAR10 保留了 50% 的数据,CINIC10 保留了 60% 的数据,CIFAR100 保留了75%的数据。可以看到,基本验证了作者在前文中的猜想:训练到中后期,通过三种计算方法裁剪数据的表现是各有优劣的,而 GraNd 和 EL2N 的确可以在训练早期就得到不错的结果。而且按上述比例裁剪了数据集之后,相比于使用所有的数据,测试精度损失的不是很大。
同时,作者也对比了分别使用 200 个 epoch 得到的遗忘分数,以及 20 个 epoch 得到的 GraNd 和 EL2N 计算样本重要性,以不同的比例裁剪数据后的测试结果:
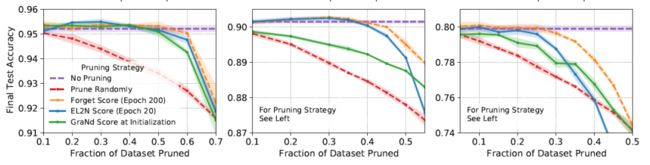
3个结果也分别是 CIFAR10 + ResNet18、CINIC10 + ResNet18 和 CIFAR100 + ResNet50。可以看到,首先相比于随机裁剪,的确三种裁剪方式都展现了相当的能力,甚至在裁剪数据比较少的时候,利用GraNd和遗忘分数裁剪后的数据训练,测试精度还超过了使用整个数据集训练,这里我猜测,在裁剪比例比较少的时候,被裁剪掉的数据主要是离群点,所以测试精度相比于全数据训练会稍高。
至此,作者提出的主要贡献,即在训练早期即可得到不错的样本重要度评估,以及利用它裁剪训练数据之后,依然能保持不错的测试精度都得到了验证,而在论文中,作者也展示了使用样本重要度可以做到其他的什么事情,以及利用一些补充实验从多种角度分析了两种计算重要程度的方法的性能,这里就不再赘述了,感兴趣的读者可以阅读原文。
所以无论是计算遗忘分数的方法,还是本文提出的 GraNd 和 EL2N,实际在固定任务场景之下,即固定分布、固定范围内是相当有价值的。
模型总出错怎么办?反复教它,直到它会
当我们训练好一个模型之后,在测试过程中,我们会发现,总是有一些“疑难杂症”一样的样本,怎么样训练都无法训练正确,而实际上,我们也知道,这些样本可能是训练样本中比较边缘的部分(假设训练集和测试集符合独立同分布假设,即所有测试样本均处于训练集的分布之中,如超出了训练集分布,则怎么也解决不了)。训练的过程则是模型不断拟合训练样本分布的过程,那么这种边缘的东西,则会成为模型的疑难杂症。
虽然机器学习研究中一直假设训练样本的分布就是真实数据的分布,可是我们也不得不承认,抽样空间和真实的空间就是存在分布上的偏差,怎么样都存在,这些“疑难杂症”的存在正是表明了训练集的分布和真实数据的分布存在的 Gap ,那么自然也就有了一个研究方向:在已有训练集上,找到拟合的分布最接近于真实数据分布的参数,即分布鲁棒性优化(Distributionally Robust Optimization, DRO),其基本思路是在训练过程中按照分布将训练样本分成若干组,最小化最差的组的 Loss,从而去提升模型的效果。
而本文作者提到,DRO 方法虽然是可行的,但是它要对训练样本分组,这个成本还是略大的,能不能不去对训练样本分组,而是找到验证集中那些比较差的样本,反反复复教给模型,从而让模型的效果更好呢?
问题定义
对于一个分类问题,输入为 ,类别标签 ,集合中有 n 个训练样本 ,目标是训练得到模型 。
在预定义好的组 之间评估模型的性能,每个训练样本 都属于组 ,分类器的最坏组错误的定义如下:
其中, 。
而训练样本中想得到这样的组成本还是比较大的,但是在测试期间,使用少量的 m 个验证集及在验证集上预定义的若干个组,得到较好的最差 case 集合,用于调整超参,优化模型。
而验证集的分组则是使用样本中本身存在的一些属性 与类别标签的关联来划分的,即 ,如下图中例子,分类水生鸟类和陆生鸟类,观察数据发现,图片的背景和标签存在相关关系,则分为4类:

JTT:训练两次就好了
本文给出的方法则是两阶段的方法:首先,我们都知道,统计模型更倾向于去学习简单的关联(例如在水上的水生鸟类,在陆地上的陆生鸟类),而复杂的关联(例如在水上的陆生鸟类,在陆地上的水生鸟类)学习的就比较差了,那么第一阶段,直接使用训练集训练一个识别模型,直接找到当前模型的“易错题集合”,即:
之后,则是增大“易错题集合”中样本的 Loss 权重,加强记忆,继续训练模型:
其中, 是一个超参数。方法非常直观,就是将易错组加强记忆一遍,最终得到一个不错的模型。
那么我们看一下最终的训练结果,作者在图像两个图像分类任务和两个 NLP 任务上分别尝试了效果,可以看到,在对比中情况较差的组的效果的确改善很多:
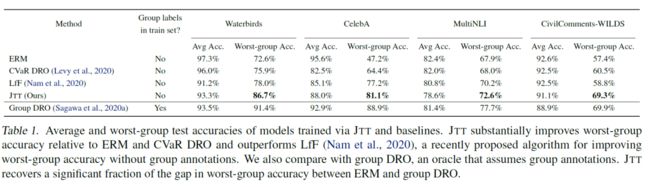
相比于要对整个训练集分组的 DRO 方法,这个方法的确成本上小了很多,且相比于其他类似的方法(论文中有简单介绍它所对比的几种方法),它的提升也相对比较高,可以说是比较符合直觉,且效果比较好的方法。这个方法与分组时所定义的属性(即 )非常相关,例如在水生鸟类和陆生鸟类分类中,使用了图片的背景,在照片男女性别分类中,使用了头发颜色;在 NLI 任务中,使用了文本中是否含有否定词语;在侮辱性评论分类任务中,使用了文本中是否含有性别描述词。

可以看出,虽然不需要使用模型去计算分组了,但也需要人为地根据数据分布来对原本数据进行归组,而如果归组出现问题,则我想对最终的效果影响也不会小。而且,模型去过度关注预测错误的样本,实际上对已经学到的正确的样本似乎也会造成一定的损失,上文中可以看到,相比于一般方法,4 种改善错误的方法在整体的精度上都有了一定的损失,而想得到均衡的效果,在划分集合上和超参 选择上都有很多的讲究。
而且,会不会所谓最差的集合中,实际上是存在部分错误,或者离群点的呢?过度去拟合它,是否造成了过拟合,或者引入了噪声呢?我们不得而知。
当然,文章中仍然有大量的对比分析及消融实验,本文也不再赘述。
这篇工作实际上是部分利用了人的先验知识,用更偏向直觉的方法,使用更简单的算法去解决分布鲁棒性优化(DRO)问题,其所关注也是模型的泛化能力。其基本动因就是,模型在某些样本上的效果非常差,则说明现在所拟合的分布是有偏的,那么就让模型的分布偏移,去包含那些相对“离群”的样本,但由于盘子也只有那么大,偏向了离群的样本,则也会舍去另一个边缘的样本。从最终结果上来看,虽然人为划分的最差集合上效果变好了,但整体上变差了,实际上个人认为也没有达到 DRO 想要达到的理想状态(实际上我们可以看到,发表于 ICLR2020 的 Group DRO的整体效果看上去也好得多)。
固定任务之下,似乎我们也只能使用这种权衡的方式来纠偏,而如果我们面向的是海量数据,则我们也会有更多的选择。
作者:Severus
Severus,在某厂工作的老程序员,主要从事自然语言理解方向,资深死宅,日常愤青,对个人觉得难以理解的同行工作都采取直接吐槽的态度。笔名取自哈利波特系列的斯内普教授,觉得自己也像他那么自闭、刻薄、阴阳怪气,也向往他为爱而伟大。
[1] Paul M, Ganguli S, Dziugaite G K. Deep Learning on a Data Diet: Finding Important Examples Early in Training[J]. arXiv preprint arXiv:2107.07075, 2021.
[2] Liu E Z, Haghgoo B, Chen A S, et al. Just Train Twice: Improving Group Robustness without Training Group Information[C]//International Conference on Machine Learning. PMLR, 2021: 6781-6792.
[3] Toneva M, Sordoni A, Combes R T, et al. An empirical study of example forgetting during deep neural network learning[J]. arXiv preprint arXiv:1812.05159, 2018.
