论文浅尝 - WWW2020 | 从自然语言交互中提取开放意图
论文笔记整理:娄东方,浙江大学博士后,研究方向为事件抽取。

Vedula N, Lipka N, Maneriker P, et al. Open Intent Extraction from Natural Language Interactions[C]//Proceedings of The Web Conference 2020. 2020: 2009-2020.
来源:WWW2020
链接:
https://dl.acm.org/doi/abs/10.1145/3366423.3380268
近年来,NLU和语音识别方面的技术进步促进了聊天代理(Siri, Cortana, Alexa等)的繁荣。在人机交互过程中,代理机器人需要对用户语句进行解析和理解,尤其是确定用户所表达的意图。例如,从”Please make a 10:30 sharp appointment for a haircut”识别出意图” makinga haircut appointment”。考虑到交互过程中可能有新意图类型不断涌现,该场景下它实际是一个开放意图识别问题。
现有方法中,一般将交互文本中的意图识别视为多分类问题。它在封闭意图下表现较好,但不能识别新意图或训练过程中未见的意图;且现有数据中单个语句一般只包含一个意图,很难覆盖现实多意图情形。零样本学习通过学习新类别知识以构建相应分类器,但新类别必须明确定义并构建相应知识。其他一些方法只能判断是否包含新意图,但无法给出具体描述。
Motivation
1.开放意图识别关键在于构建一个统一的schema,它既能建模当前已知意图,也能刻画新的、未知的意图。本文提出的意图schema包括两部分:(1)Action, 明确意图、任务或动作的词语;(2)Object, 是指Action实施对象实体词。
例如,语句”Please make a 10:30 sharp appointment for a haircut”中,Action为“make”,Object为“appointment”。
2.直觉地,基于Action + Object的意图schema,可将开放意图识别形式化为序列标注问题。其中,标签集合包括Action, Object, None;且抽取的意图对必须同时包含Action和Object对象。
Model

Figure 1 开放意图抽取框架OPINE
如图1所示,本文提出的OPINE框架主要包括:对抗训练,Bi-LSTM语义编码,Multi-head attention机制,带约束的CRF,生成意图等。OPINE框架相对简洁,且在各阶段都进行了精细处理。具体如下,
(1)对抗训练
为提升整体模型的鲁棒性,该框架对输入embedding添加扰动,但不改变输出标签,进而使得模型对embedding的微小变动稳健。具体而言,
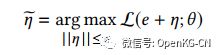
在训练过程中,给embedding添加最差情况下的干扰信号。并用一阶导数进行逼近,

最终损失函数为原始数据和对抗样本分别损失的加权平均。生成的对抗样本中,只保留与原始样本embedding高于某个阈值的数据。
(2) Bi-LSTM
利用Bi-LSTM捕捉上下文语义信息。
(3) Multi-head attention
应用transformer结构中的multi-head attention机制,学习长距离依赖关系。
(4) 带约束的CRF
CRF在序列标注任务中被广泛应用,因其具备标签序列依赖建模能力。意图schema对标签序列存在约束——必须同时包含Action和Object标签。本文提出两种方法将该约束融进来:a) 适应的beam search, 如果约束条件不满足,则取下一个最有可能的序列;b) 适应的Viterbi算法,将解码问题转化为整数线性优化问题,并将约束条件加进来。
(5) 生成意图
考虑到单个语句中可能存在多个意图,这需要我们对CRF层输出的标签进一步加工,从而得到Action-Object对。本文考虑两种方法:a) 基于距离的启发式拼装,将相距较近的Action-Object配对成一个完整意图;b) 基于MLP分类器,以候选Action-Object对的词向量和距离作为MLP的输入,分类判断是否构成意图对。
Experiment
本文作者构造一个意图抽取数据集(Stack Exchange data):总共75000个问题,其中25000个问题包含抽取的意图标注结果,另50000个问题基于Stanford CoreNLP依存分析工具解析得到verb-object关系。评估步骤:(1)、基于50000个问题的解析结果对BERT模型进行调整;(2)、基于25000个问题的标注数据进行精调、测试。评价指标包括:Action结果的P, R, F1; Object结果的P, R, F1;意图对Action-Object的P, R, F1;抽取意图向量表示(所有token的GloVe向量的平均)与标注意图向量表示的余弦相似度。

Figure 2 OPINE框架在Stack Exchange data上的表现
从图2可以看到,本文提出的OPINE相较于现有SRL、依存分析等更优,抽取意图的相似度提升超过0.1。

Figure 3 OPINE在domain adaption中的表现。“+td”表示测试domain在训练过程可见,“-td”表示测试domain在测试过程中不可见
图3显示OPNIE具备较强的可迁移性,新domain情形较现有domain的表现下降幅度都在5%以下。

Figure 4 OPINE在SNIPS和ATIS上的表现
本文提出的抽取式开放意图识别框架OPINE在图4中得到充分证明,基于这种思路可学到语言的底层信息,模型具备很强的迁移性。具体而言,OPINE + classifier指基于Stack Exchange data训练的模型获取编码,给定SNIPS和ATIS的意图类别数,OPINE + classifier基于层次聚类获得最终预测标签(完全的domain迁移),在两个数据集下取得了与封闭意图识别SOTA相当的结果。具体聚类效果图如图5所示。

Figure 5 OPINE + classifier在SNIPS数据上的聚类结果
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。