【ClickHouse】查看数据库容量和表大小的方法(system.parts各种操作方法)
文章目录
- 1.概述
本文为博主九师兄(QQ:541711153 欢迎来探讨技术)原创文章,未经允许博主不允许转载。
1.概述
转载:【ClickHouse】查看数据库容量和表大小的方法(system.parts各种操作方法)
clickhouse有system.parts系统表记录表相关元数据,可以通过该表对clickhouse上所有表进行查询表大小、行数等操作。
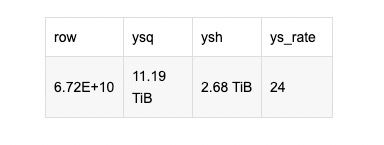
1.查看数据库容量
select
sum(rows) as row,--总行数
formatReadableSize(sum(data_uncompressed_bytes)) as ysq,--原始大小
formatReadableSize(sum(data_compressed_bytes)) as ysh,--压缩大小
round(sum(data_compressed_bytes) / sum(data_uncompressed_bytes) * 100, 0) ys_rate--压缩率
from system.parts
结果:
2.查看表的各个指标
select database,
table,
sum(bytes) as size,
sum(rows) as rows,
min(min_date) as min_date,
max(max_date) as max_date,
sum(bytes_on_disk) as bytes_on_disk,
sum(data_uncompressed_bytes) as data_uncompressed_bytes,
sum(data_compressed_bytes) as data_compressed_bytes,
(data_compressed_bytes / data_uncompressed_bytes) * 100 as compress_rate,
max_date - min_date as days,
size / (max_date - min_date) as avgDaySize
from system.parts
where active
and database = 'database'
and table = 'tablename'
group by database, table
结果为:这种结果显示的大小size是字节,我们如何转换为常见的MB和GB呢?

select
database,
table,
formatReadableSize(size) as size,
formatReadableSize(bytes_on_disk) as bytes_on_disk,
formatReadableSize(data_uncompressed_bytes) as data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) as data_compressed_bytes,
compress_rate,
rows,
days,
formatReadableSize(avgDaySize) as avgDaySize
from
(
select
database,
table,
sum(bytes) as size,
sum(rows) as rows,
min(min_date) as min_date,
max(max_date) as max_date,
sum(bytes_on_disk) as bytes_on_disk,
sum(data_uncompressed_bytes) as data_uncompressed_bytes,
sum(data_compressed_bytes) as data_compressed_bytes,
(data_compressed_bytes / data_uncompressed_bytes) * 100 as compress_rate,
max_date - min_date as days,
size / (max_date - min_date) as avgDaySize
from system.parts
where active
and database = 'database'
and table = 'tablename'
group by
database,
table
)
结果:这就转换为常见的单位了:

上面过程可以看到,最终都用表进行了聚合,为什么会这样呢?
以一个简单的例子来看,我们最常见的是查看表分区,下面来看下不进行聚合的结果:
select partition
from system.parts
where active
and database = 'database'
and table = 'tablename'
结果为:这是因为在CH中,和我们hive表不一样,hive表一个分区只会有一条记录,但CH不是,每个分区分为了不同的marks
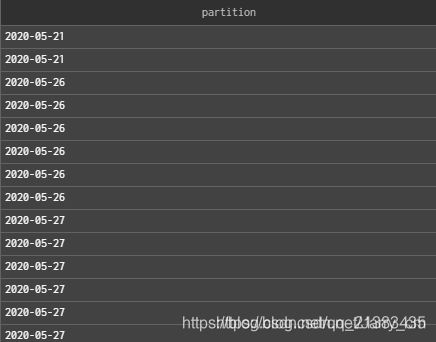
因此,我们要实现和hive一样查分区的功能时,要对表进行聚合查看。
3.跟踪分区
SELECT database,
table,
count() AS parts,
uniq(partition) AS partitions,
sum(marks) AS marks,
sum(rows) AS rows,
formatReadableSize(sum(data_compressed_bytes)) AS compressed,
formatReadableSize(sum(data_uncompressed_bytes)) AS uncompressed,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100.,2) AS percentage
FROM system.parts
WHERE active
and database = 'database'
and table = 'tablename'
GROUP BY database, table
结果为:

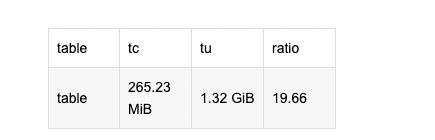
4.检查数据大小
SELECT table,
formatReadableSize(sum(data_compressed_bytes)) AS tc,
formatReadableSize(sum(data_uncompressed_bytes)) AS tu,
round((sum(data_compressed_bytes) / sum(data_uncompressed_bytes)) * 100,2) AS ratio
FROM system.columns
WHERE database = 'database'
and table = 'table'
GROUP BY table
ORDER BY sum(data_compressed_bytes) ASC
结果:
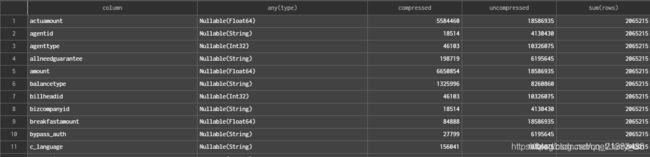
5.查看表中列的数据大小
SELECT column,
any(type),
sum(column_data_compressed_bytes) AS compressed,
sum(column_data_uncompressed_bytes) AS uncompressed,
sum(rows)
FROM system.parts_columns
WHERE database = 'database'
and table = 'table'
AND active
GROUP BY column
ORDER BY column ASC
结果:
以上就是对表和库的一些基本操作了。